Zero-Inflated Logistic Regression Models with Shared Design: Identifiability, Existence of Estimates, and a Relabeling Rule
Pith reviewed 2026-05-10 00:10 UTC · model grok-4.3
The pith
Zero-inflated logistic regression with shared design is identifiable up to exchange symmetry of its two component parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
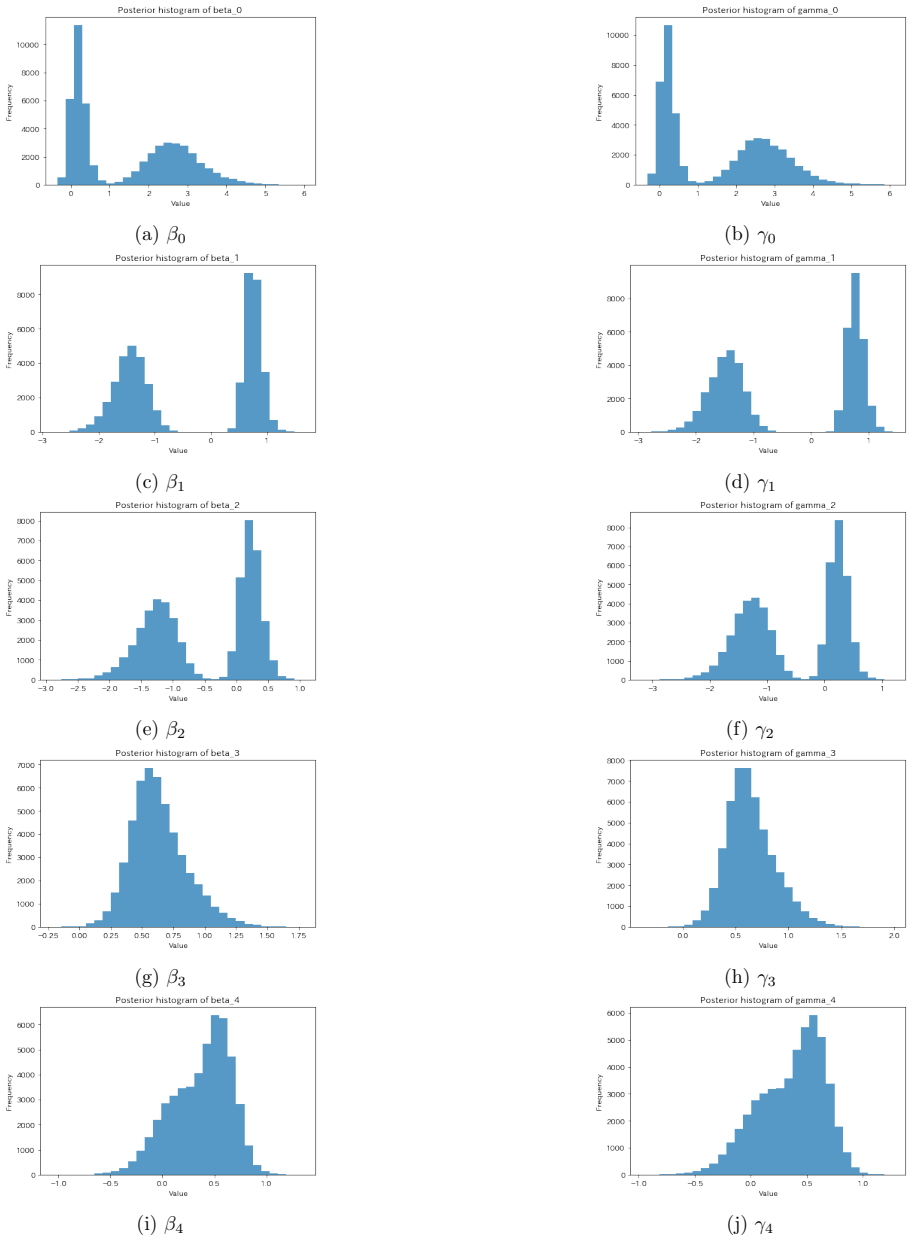
Under the shared-design setting the zero-inflated logistic regression model is identifiable up to exchange symmetry of the parameters for the two components, and the expected log-likelihood has a unique maximizer on the resulting quotient space. Sufficient conditions are established for existence of the maximum likelihood estimate. The posterior bimodality is examined with a Pólya-Gamma Gibbs sampler augmented by replica exchange, and a relabeling rule is proposed to select a single ordered parameter pair.
What carries the argument
The quotient space formed by identifying pairs of regression parameters that differ only by exchange of the two mixture components.
If this is right
- Ignoring the zero-inflation mechanism produces a sign reversal in the pseudo-true value of the regression coefficient.
- The maximum likelihood estimate exists once the stated sufficient conditions on the design matrix and response probabilities hold.
- The relabeling rule recovers a unique ordered parameter estimate from the bimodal posterior produced by the Pólya-Gamma sampler.
- The procedure is shown to work in simulation studies and on self-reported diabetes data.
Where Pith is reading between the lines
- In routine analysis the relabeling step should be applied automatically so that reported coefficients are comparable across studies.
- The symmetry argument may extend directly to other zero-inflated generalized linear models that share the same covariate matrix.
- When even one covariate is allowed to differ between the two components, the model regains ordinary pointwise identifiability.
- The sign-flip result implies that naive logistic regression on excess-zero data can systematically mis-state the direction of an effect.
Load-bearing premise
The latent mixture correctly captures the zero-inflation mechanism and the shared design matrix supplies no information that distinguishes the two components.
What would settle it
A concrete dataset in which the likelihood surface contains modes whose parameter values are not interchangeable by swapping the two components would falsify the claimed identifiability up to symmetry.
Figures








read the original abstract
The zero-inflated logistic regression model accommodates binary responses with excess zeros, which often arise from a latent mixture of susceptible and insusceptible subpopulations or asymmetric misclassification of the response. The model has two components: regression for the binary response and a latent binary indicator for the zero-inflation state. In applied settings, it is common to use the same design matrix for both components if there is no prior knowledge. However, this shared-design specification lacks guaranteed identifiability of the regression parameters, as established in prior works. This paper investigates the theoretical properties of the zero-inflated logistic regression model under the shared-design setting and computational methods for applications. First, to motivate the use of the zero-inflated model, we prove that ignoring the zero-inflation mechanism can lead to a sign flip in the pseudo-true coefficient value relative to the true value. We then establish sufficient conditions for the existence of the maximum likelihood estimate. As a main result, we establish that the model under the shared-design setting is identifiable up to exchange symmetry of the parameters for two components and that the expected log-likelihood has a unique maximizer on the resulting quotient space. The posterior bimodality is examined using a P\'olya-Gamma Gibbs sampler with replica exchange. Finally, we propose a simple relabeling rule to select a single ordered parameter pair, and evaluate its performance through simulation studies and an application to self-reported diabetes data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies zero-inflated logistic regression models with a shared design matrix for the response and zero-inflation components. It demonstrates that ignoring zero-inflation can lead to sign reversal in the pseudo-true parameters. Sufficient conditions are derived for the existence of the MLE. The main theoretical contribution is proving identifiability up to exchange symmetry of the two component parameters and the uniqueness of the maximizer of the expected log-likelihood on the quotient space. A relabeling rule is introduced to handle label switching, with validation through Pólya-Gamma Gibbs sampling with replica exchange, simulation studies, and an application to self-reported diabetes data.
Significance. This manuscript addresses a practically relevant issue in statistical modeling by providing theoretical guarantees for identifiability and estimation in zero-inflated logistic regression under the shared-design specification, which is frequently employed when covariate information does not distinguish the components. The proofs for sign reversal upon misspecification, MLE existence, and the unique maximizer on the quotient space, combined with the proposed relabeling rule, offer both foundational insights and practical tools. The analytical validation of the relabeling rule and its empirical performance in simulations and real data enhance the paper's utility for researchers working with mixture models and excess zero data. These contributions are likely to influence both theoretical developments and applied work in the field.
minor comments (4)
- §2: The derivation of the sign reversal in the pseudo-true coefficient could benefit from an explicit statement of the conditions under which the flip occurs, to make the motivational result more precise.
- §4: In the statement of the identifiability result, the definition of the quotient space under exchange symmetry should be accompanied by a brief remark on how the metric or distance is defined to ensure uniqueness.
- Simulation studies: The performance metrics for the relabeling rule in the simulations (e.g., bias, coverage) should be tabulated for different sample sizes to allow clearer assessment of finite-sample behavior.
- Figure 2: The plot illustrating posterior bimodality would be improved by adding annotations that label the two modes corresponding to the exchange-symmetric parameter pairs.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our manuscript, the accurate summary of its contributions on identifiability up to exchange symmetry, uniqueness of the maximizer on the quotient space, and the relabeling rule, and the recommendation for minor revision. No specific major comments were provided in the report.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper derives identifiability up to exchange symmetry, existence of the MLE, and a relabeling rule as theoretical properties of the zero-inflated logistic likelihood under shared design. These rest on explicit sufficient conditions on the design matrix and parameter space, plus direct analysis of the expected log-likelihood on the quotient space. No step reduces a claimed result to a fitted parameter, self-referential definition, or load-bearing self-citation chain; the central results are self-contained population-level statements independent of any particular data fit or prior author result invoked as an unverified axiom.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard regularity conditions for logistic regression likelihood and maximum likelihood estimation
Reference graph
Works this paper leans on
-
[1]
Albert, A. and Anderson, J. A. (1984). On the existence of maximum likelihood estimates in logistic regression models.Biometrika, 71(1):1–10
work page 1984
-
[2]
Arthur, D. and Vassilvitskii, S. (2007). K-means++: The advantages of careful seeding.Pro- ceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms. Society for Industrial and Applied Mathematics, 8:1027–1035
work page 2007
-
[3]
Bootkrajang, J. and Kab´ an, A. (2012). Label-noise robust logistic regression and its applications. InJoint European Conference on Machine Learning and Knowledge Discovery in Databases, pages 143–158. Springer
work page 2012
-
[4]
Bootkrajang, J. and Kab´ an, A. (2013). Classification of mislabelled microarrays using robust sparse logistic regression.Bioinformatics, 29(7):870–877. Centers for Disease Control and Prevention (CDC) (2017–2018). National Center for Health Statistics (NCHS). National Health and Nutrition Examination Survey Data. Hyattsville, MD: U.S. Department of Healt...
work page 2013
-
[5]
Diop, A., Diop, A., and Dupuy, J.-F. (2011). Maximum likelihood estimation in the logistic regression model with a cure fraction.Electronic Journal of Statistics, 5:460–483. Fr¨ uhwirth-Schnatter, S. (2006).Finite Mixture and Markov Switching Models. Springer, New York
work page 2011
-
[6]
Fujisawa, H. and Eguchi, S. (2008). Robust parameter estimation with a small bias against heavy contamination.Journal of Multivariate Analysis, 99(9):2053–2081
work page 2008
-
[7]
Hall, D. B. (2000). Zero-inflated poisson and binomial regression with random effects: A case study.Biometrics, 56(4):1030–1039
work page 2000
-
[8]
Hung, H., Jou, Z.-Y., and Huang, S.-Y. (2018). Robust mislabel logistic regression without modeling mislabel probabilities.Biometrics, 74(1):145–154
work page 2018
-
[9]
Komori, O., Eguchi, S., Ikeda, S., Okamura, H., Ichinokawa, M., and Nakayama, S. (2016). An asymmetric logistic regression model for ecological data.Methods in Ecology and Evolution, 7(2):249–260
work page 2016
-
[10]
Nagelkerke, N. and Fidler, V. (2015). Estimating a logistic discrimination functions when one of the training samples is subject to misclassification: A maximum likelihood approach.PLoS One, 10(10):e0140718
work page 2015
-
[11]
Polson, N. G., Scott, J. G., and Windle, J. (2013). Bayesian inference for logistic mod- els using p´ olya–gamma latent variables.Journal of the American Statistical Association, 108(504):1339–1349
work page 2013
-
[12]
Silvapulle, M. J. (1981). On the existence of maximum likelihood estimators for the binomial response models.Journal of the Royal Statistical Society: Series B, 43(3):310–313
work page 1981
-
[13]
Swendsen, R. H. and Wang, J.-S. (1986). Replica Monte Carlo simulation of spin-glasses.Physical Review Letters, 57(21):2607
work page 1986
-
[14]
Teicher, H. (1963). Identifiability of finite mixtures.The Annals of Mathematical Statistics, 34(4):1265–1269
work page 1963
-
[15]
Wainer, H., Bradlow, E. T., and Wang, X. (2007).Testlet Response Theory and Its Applications. Cambridge University Press. 34
work page 2007
-
[16]
Yakowitz, S. J. and Spragins, J. D. (1968). On the identifiability of finite mixtures.The Annals of Mathematical Statistics, 39(1):209–214. 35
work page 1968
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.