Recognition: unknown
What People See (and Miss) About Generative AI Risks: Perceptions of Failures, Risks, and Who Should Address Them
Pith reviewed 2026-05-08 10:35 UTC · model grok-4.3
The pith
A survey instrument grounded in real incidents effectively measures how people perceive generative AI risks and responsibilities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
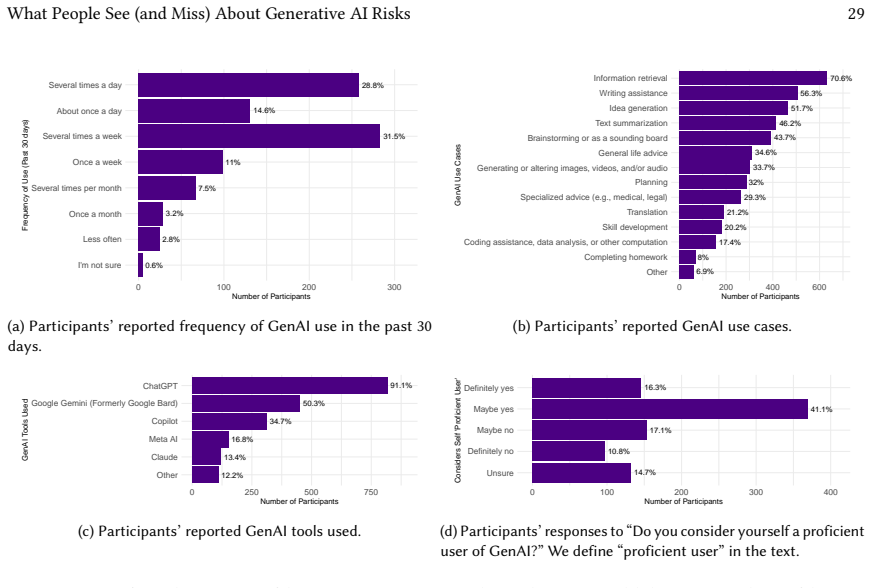
The authors created a survey instrument validated by eight experts and administered to 960 U.S. participants that assesses awareness of generative AI failure modes, associated risks, and stakeholder responsibilities using scenarios based on publicly reported incidents and a taxonomy of sociotechnical breakdowns. Results indicate the instrument effectively evaluates risk awareness in people's current contexts of use while remaining extensible to future contexts. The work concludes that AI literacy and governance efforts should align with how individuals encounter and reason about generative AI in everyday life.
What carries the argument
The validated survey instrument structured around scenarios from publicly reported incidents and a taxonomy of GenAI failure modes, used to measure awareness, risk perceptions, and views on responsibilities.
If this is right
- AI literacy tools and interventions can be designed using data collected by this instrument to match actual public perceptions.
- Governance approaches for generative AI should consider how people reason about risks in everyday contexts rather than abstract lists.
- The instrument offers a repeatable method to track shifts in perceptions as new generative AI uses develop.
- Understanding public views on stakeholder responsibilities can inform policy choices about accountability for AI harms.
Where Pith is reading between the lines
- The instrument could be adapted to measure awareness gaps for specific failure modes and guide targeted education efforts.
- Similar scenario-based surveys might apply to public perceptions of other AI systems beyond generative tools.
- If governance incorporates these measured perceptions, it may produce policies that better match user expectations and reduce mistrust.
Load-bearing premise
The taxonomy of failure modes drawn from public incidents fully covers the risks people face in daily use, and self-reported survey answers from a U.S. sample accurately reflect broader awareness and perceptions.
What would settle it
Re-running the survey with a non-U.S. sample or after major new incident types emerge and obtaining substantially different awareness levels or responsibility views would challenge the claims of effectiveness and extensibility.
Figures




read the original abstract
Despite growing concerns about the risks of Generative AI (GenAI), there is limited understanding of public perceptions of these risks and their associated failure modes -- defined as recurring patterns of sociotechnical breakdown across the GenAI lifecycle that contribute to risks of real-world harm. To address this gap, we present a survey instrument, validated with eight subject matter experts and deployed on a sample of 960 U.S.-based participants, to assess awareness and perceptions of GenAI's failure modes, their associated risks, and stakeholder responsibilities to address them. To support realism and content validity, our instrument is structured around scenarios grounded in publicly reported incidents and a taxonomy of GenAI's failure modes. Findings suggest that our instrument is (1) effective for assessing risk awareness and perceptions in a way that is grounded in people's current contexts of use, yet is extensible to new contexts that will inevitably arise; and (2) potentially useful for informing the design of AI literacy tools and interventions. We argue for AI literacy and governance approaches that align with how people encounter and reason about GenAI in everyday life.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a survey instrument to assess public awareness and perceptions of Generative AI (GenAI) failure modes—defined as recurring sociotechnical breakdowns—along with associated risks and stakeholder responsibilities. The instrument is built around scenarios drawn from publicly reported incidents and a taxonomy of failure modes, validated by eight subject matter experts, and deployed to a sample of 960 U.S. participants. The authors conclude that the instrument is effective for capturing risk awareness in current contexts of use, remains extensible to future contexts, and can inform the design of AI literacy tools and interventions, advocating for literacy and governance approaches aligned with everyday user reasoning.
Significance. If the validation and deployment findings hold, the work provides a practical, scenario-grounded tool for HCI researchers to study public perceptions of GenAI risks. Strengths include the use of real-world incident-derived scenarios for ecological validity, expert validation with eight SMEs, and deployment on a sizable U.S. sample of 960 participants. This supports the development of literacy interventions that match how users actually encounter and reason about GenAI, addressing a gap in understanding perceptions beyond abstract concerns.
major comments (2)
- [Abstract and Results] The abstract and results sections provide no statistical results, error bars, reliability metrics (e.g., Cronbach's alpha), or details on how the 960-participant deployment demonstrates effectiveness or content validity of the instrument. This leaves the central claim that the instrument is 'effective' only partially evidenced, despite the expert validation and sample size.
- [§3] §3 (Taxonomy and Scenario Construction): The assumption that the taxonomy derived from publicly reported incidents comprehensively captures risks people encounter in everyday use is load-bearing for the instrument's grounding and extensibility claims, yet the manuscript offers no evidence or testing that it covers unreported or emerging failure modes beyond the initial incidents.
minor comments (2)
- [Discussion] The discussion of generalizability could more explicitly note limitations of the U.S.-only sample when claiming broader applicability for AI literacy tools.
- [Appendix] Some scenario descriptions in the instrument appendix could benefit from clearer mapping to specific taxonomy categories to aid replicability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the recommendation for minor revision. We appreciate the opportunity to strengthen the evidence presented for the survey instrument and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract and Results] The abstract and results sections provide no statistical results, error bars, reliability metrics (e.g., Cronbach's alpha), or details on how the 960-participant deployment demonstrates effectiveness or content validity of the instrument. This leaves the central claim that the instrument is 'effective' only partially evidenced, despite the expert validation and sample size.
Authors: We agree that the abstract and results would benefit from additional quantitative details to more fully substantiate the effectiveness claim. In the revised manuscript, we will expand the results section to include reliability metrics such as Cronbach's alpha for the relevant scales, key descriptive statistics from the 960 participants (means, standard deviations), and appropriate error bars or confidence intervals. We will also add explicit discussion of how the deployment data, alongside the eight-SME validation, supports content validity and demonstrates the instrument's utility for capturing perceptions grounded in current use contexts. revision: yes
-
Referee: [§3] §3 (Taxonomy and Scenario Construction): The assumption that the taxonomy derived from publicly reported incidents comprehensively captures risks people encounter in everyday use is load-bearing for the instrument's grounding and extensibility claims, yet the manuscript offers no evidence or testing that it covers unreported or emerging failure modes beyond the initial incidents.
Authors: We acknowledge that the taxonomy is constructed from publicly reported incidents and does not include direct evidence or testing for coverage of unreported or emerging failure modes. The approach prioritizes ecological validity through real-world grounding and SME validation rather than claiming exhaustiveness. We will revise §3 to explicitly state this scope and limitation, while clarifying that extensibility is supported by the modular scenario structure, which permits incorporation of new incidents. We do not provide testing for unreported modes, as this would require a separate, ongoing monitoring study beyond the current scope. revision: partial
Circularity Check
No significant circularity in empirical survey study
full rationale
This is a purely empirical HCI perception study with no mathematical derivations, equations, fitted parameters, or self-referential constructs. The taxonomy derives from publicly reported incidents, the instrument is validated by external experts, and claims rest on survey data from a U.S. sample. No load-bearing step reduces by construction to prior inputs or self-citations; the design is standard and self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The taxonomy of GenAI failure modes based on publicly reported incidents is comprehensive for current contexts of use.
- domain assumption Self-reported perceptions from the U.S. sample reflect genuine awareness and reasoning about risks.
Reference graph
Works this paper leans on
-
[1]
Sayre, Ushnish Sengupta, Arthit Suriyawongkul, Ruby Thelot, Sofia Vei, and Laura Waltersdorfer
Gavin Abercrombie, Djalel Benbouzid, Paolo Giudici, Delaram Golpayegani, Julio Hernandez, Pierre Noro, Harshvardhan Pandit, Eva Paraschou, Charlie Pownall, Jyoti Prajapati, Mark A. Sayre, Ushnish Sengupta, Arthit Suriyawongkul, Ruby Thelot, Sofia Vei, and Laura Waltersdorfer. [n. d.]. AIAAIC - AIAAIC Repository. https://www.aiaaic.org/aiaaic-repository
-
[2]
Sayre, Ushnish Sengupta, Arthit Suriyawongkul, Ruby Thelot, Sofia Vei, and Laura Waltersdorfer
Gavin Abercrombie, Djalel Benbouzid, Paolo Giudici, Delaram Golpayegani, Julio Hernandez, Pierre Noro, Harshvardhan Pandit, Eva Paraschou, Charlie Pownall, Jyoti Prajapati, Mark A. Sayre, Ushnish Sengupta, Arthit Suriyawongkul, Ruby Thelot, Sofia Vei, and Laura Waltersdorfer. 2024. A Collaborative, Human-Centred Taxonomy of AI, Algorithmic, and Automation...
-
[3]
Desiree Abrokwa, Shruti Das, Omer Akgul, and Michelle L. Mazurek. 2021. Comparing security and privacy attitudes among U.S. users of different smartphone and smart-speaker platforms. InProceedings of the Seventeenth USENIX Conference on Usable Privacy and Security (SOUPS’21). USENIX Association, USA, Article 8, 20 pages
2021
-
[4]
Nazanin Andalibi and Alexis Shore Ingber. 2025. Public Perceptions About Emotion AI Use Across Contexts in the United States. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems (CHI ’25). Association for Computing Machinery, New York, NY, USA, Article 525, 16 pages. doi:10.1145/3706598.3713501
-
[5]
Ravinithesh Annapureddy, Alessandro Fornaroli, and Daniel Gatica-Perez. 2025. Generative AI Literacy: Twelve Defining Competencies. 6, 1 (2025), 13:1–13:21. doi:10.1145/3685680
-
[6]
Mark Blythe. 2014. Research through design fiction: narrative in real and imaginary abstracts. InProceedings of the SIGCHI Conference on Human Factors in Computing Systems(Toronto, Ontario, Canada)(CHI ’14). Association for Computing Machinery, New York, NY, USA, 703–712. doi:10.1145/2556288.2557098
-
[7]
Bransford, Ann L
John D. Bransford, Ann L. Brown, and Rodney R. Cocking. 2000.How Experts Differ from Novices. National Academy Press, 31–50
2000
-
[8]
Violation of my body:
Natalie Grace Brigham, Miranda Wei, Tadayoshi Kohno, and Elissa M. Redmiles. 2024. "Violation of my body:" Perceptions of AI-generated non-consensual (intimate) imagery. InTwentieth Symposium on Usable Privacy and Security (SOUPS 2024). USENIX Association, Philadelphia, PA, 373–392. https://www.usenix.org/conference/soups2024/presentation/brigham
2024
-
[9]
Torsten Brinda, Ira Diethelm, Rainer Gemulla, Ralf Romeike, Johannes Schöning, and Carsten Schulte. 2016. Dagstuhl-Erklärung: Bildung in der digitalen vernetzten Welt. doi:10.13140/RG.2.1.3957.2245
-
[10]
Stephen Cave, Kate Coughlan, and Kanta Dihal. 2019. "Scary Robots": Examining Public Responses to AI. InProceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society(Honolulu, HI, USA)(AIES ’19). Association for Computing Machinery, New York, NY, USA, 331–337. doi:10.1145/3306618.3314232
-
[11]
2018.Portrayals and perceptions of AI and why they matter
Stephen Cave, Claire Craig, Kanta Dihal, Sarah Dillon, Jessica Montgomery, Beth Singler, and Lindsay Taylor. 2018.Portrayals and perceptions of AI and why they matter. The Royal Society. doi:10.17863/CAM.34502
-
[12]
Ching Sing Chai, Xingwei Wang, and Chang Xu. 2020. An extended theory of planned behavior for the modelling of Chinese secondary school students’ intention to learn artificial intelligence.Mathematics8, 11 (2020), 2089
2020
-
[13]
Michelene T. H. Chi, Paul J. Feltovich, and Robert Glaser. 1981. Categorization and Representation of Physics Problems by Experts and Novices. Cognitive Science5, 2 (1981), 121–152. doi:10.1207/s15516709cog0502_2
-
[14]
Thomas K F Chiu, Zubair Ahmad, Murod Ismailov, and Ismaila Temitayo Sanusi. 2024. What are artificial intelligence literacy and competency? A comprehensive framework to support them.Comput. Educ. Open6, 100171 (June 2024), 100171
2024
-
[15]
Yun Dai, Ching-Sing Chai, Pei-Yi Lin, Morris Siu-Yung Jong, Yanmei Guo, and Jianjun Qin. 2020. Promoting students’ well-being by developing their readiness for the artificial intelligence age.Sustainability12, 16 (2020), 6597
2020
-
[16]
Prabu David, Hyesun Choung, and John S. Seberger. 2024. Who is responsible? US Public perceptions of AI governance through the lenses of trust and ethics.Public Understanding of Science33, 5 (2024), 654–672. doi:10.1177/09636625231224592 PMID: 38326971
-
[17]
George Denison. 2023. LLM use in research: A study into mitigation strategies. https://www.prolific.com/resources/llm-use-in-research-a-study- into-mitigation-strategies
2023
-
[18]
Ira Diethelm. 2022. Digital Education and Informatics – You can’t have One without the Other. InProceedings of the 17th Workshop in Primary and Secondary Computing Education(Morschach, Switzerland)(WiPSCE ’22). Association for Computing Machinery, New York, NY, USA, Article 2, 2 pages. doi:10.1145/3556787.3556790
-
[19]
Andrés Domínguez Hernández, Shyam Krishna, Antonella Maia Perini, Michael Katell, SJ Bennett, Ann Borda, Youmna Hashem, Semeli Hadjiloizou, Sabeehah Mahomed, Smera Jayadeva, Mhairi Aitken, and David Leslie. 2024. Mapping the individual, social and biospheric impacts of Foundation Models. InProceedings of the 2024 ACM Conference on Fairness, Accountability...
-
[20]
Lilian Edwards and Michael Veale. 2017. Slave to the Algorithm? Why a ’Right to an Explanation’ Is Probably Not the Remedy You Are Looking For. Duke Law & Technology Review(2017)
2017
-
[21]
Lance Eliot. 2024. As Generative AI Models Get Bigger And Better The Reliability Veers Straight Off A Cliff — Or Maybe That’s A Mirage.Forbes (2024). https://www.forbes.com/sites/lanceeliot/2024/11/06/as-generative-ai-models-get-bigger-and-better-the-reliability-veers-straight-off-a- cliff---or-maybe-thats-a-mirage/ Published November 6, 2024
2024
-
[22]
Xianzhe Fan, Qing Xiao, Xuhui Zhou, Jiaxin Pei, Maarten Sap, Zhicong Lu, and Hong Shen. 2025. User-Driven Value Alignment: Understanding Users’ Perceptions and Strategies for Addressing Biased and Discriminatory Statements in AI Companions. InProceedings of the 2025 CHI Manuscript submitted to ACM 18 Li et al. Conference on Human Factors in Computing Syst...
-
[23]
Alejandra Gómez Ortega, Hosana Morales Ornelas, and Uğur Genç. 2025. Surrendering to Powerlesness: Governing Personal Data Flows in Generative AI. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems (CHI ’25). Association for Computing Machinery, New York, NY, USA, Article 232, 18 pages. doi:10.1145/3706598.3713504
-
[24]
Xiaoyan Gong, Ying Tang, Xiwei Liu, Sifeng Jing, Wei Cui, Joleen Liang, and Fei-Yue Wang. 2020. K-9 artificial intelligence education in Qingdao: Issues, challenges and suggestions. In2020 IEEE international Conference on networking, Sensing and control (ICNSC). IEEE, 1–6
2020
-
[25]
Nora Graves, Vitus Larrieu, Yingyue Trace Zhang, Joanne Peng, Varun Nagaraj Rao, Yuhan Liu, and Andrés Monroy-Hernández. 2025. GPTFootprint: Increasing Consumer Awareness of the Environmental Impacts of LLMs. InProceedings of the Extended Abstracts of the CHI Conference on Human Factors in Computing Systems (CHI EA ’25). Association for Computing Machiner...
-
[26]
Xingjian (Lance) Gu and Barbara J. Ericson. 2025. AI Literacy in K-12 and Higher Education in the Wake of Generative AI: An Integrative Review. In Proceedings of the 2025 ACM Conference on International Computing Education Research V.1 (ICER ’25). Association for Computing Machinery, New York, NY, USA, 125–140. doi:10.1145/3702652.3744217
-
[27]
Wiebke Hutiri, Orestis Papakyriakopoulos, and Alice Xiang. 2024. Not my voice! a taxonomy of ethical and safety harms of speech generators. In Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency. 359–376
2024
-
[28]
Anna Jobin, Marcello Ienca, and Effy Vayena. 2019. The global landscape of AI ethics guidelines. 1, 9 (2019), 389–399. doi:10.1038/s42256-019-0088-2
-
[29]
Kowe Kadoma, Danaé Metaxa, and Mor Naaman. 2025. Generative AI and Perceptual Harms: Who’s Suspected of using LLMs?. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems (CHI ’25). Association for Computing Machinery, New York, NY, USA, Article 861, 17 pages. doi:10.1145/3706598.3713897
-
[30]
Martin Kandlhofer, Gerald Steinbauer, Sabine Hirschmugl-Gaisch, and Petra Huber. 2016. Artificial intelligence and computer science in education: From kindergarten to university . In2016 IEEE Frontiers in Education Conference (FIE). IEEE Computer Society, Los Alamitos, CA, USA, 1–9. doi:10.1109/FIE.2016.7757570
-
[31]
Magnus Høholt Kaspersen, Karl-Emil Kjær Bilstrup, and Marianne Graves Petersen. 2021. The machine learning machine: A tangible user interface for teaching machine learning. InProceedings of the fifteenth international conference on tangible, embedded, and embodied interaction. 1–12
2021
-
[32]
Patrick Gage Kelley, Yongwei Yang, Courtney Heldreth, Christopher Moessner, Aaron Sedley, Andreas Kramm, David T. Newman, and Allison Woodruff. 2021. Exciting, Useful, Worrying, Futuristic: Public Perception of Artificial Intelligence in 8 Countries. InProceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society(Virtual Event, USA)(AIES ’21). As...
-
[33]
Soojong Kim, Poong Oh, and Joomi Lee. 2024. Algorithmic gender bias: investigating perceptions of discrimination in automated decision-making. Behaviour & Information Technology43, 16 (2024), 4208–4221. arXiv:https://doi.org/10.1080/0144929X.2024.2306484 doi:10.1080/0144929X.2024. 2306484
-
[34]
Jamie Lee, Kyuha Jung, Erin Gregg Newman, Emilie Chow, and Yunan Chen. 2025. Understanding Adolescents’ Perceptions of Benefits and Risks in Health AI Technologies through Design Fiction. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems (CHI ’25). Association for Computing Machinery, New York, NY, USA, Article 311, 20 pages. ...
-
[35]
Mo Jones-Jang
Sangwon Lee, Myojung Chung, Nuri Kim, and S. Mo Jones-Jang. 2024. Public Perceptions of ChatGPT: Exploring How Nonexperts Evaluate Its Risks and Benefits.Technology, Mind, and Behavior5, 4: Winter 2024 (oct 21 2024). https://tmb.apaopen.org/pub/ki45ziga
2024
-
[36]
Megan Li, Wendy Bickersteth, Ningjing Tang, Jason Hong, Lorrie Cranor, Hong Shen, and Hoda Heidari. 2025. A Closer Look at the Existing Risks of Generative AI: Mapping the Who, What, and How of Real-World Incidents. arXiv:2505.22073 [cs.CY] https://arxiv.org/abs/2505.22073
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Gabriel Lima, Nina Grgić-Hlača, and Meeyoung Cha. 2021. Human perceptions on moral responsibility of AI: A case study in AI-assisted bail decision-making. InProceedings of the 2021 CHI conference on human factors in computing systems. 1–17
2021
-
[38]
Gabriel Lima, Nina Grgić-Hlača, and Elissa M Redmiles. 2025. Public Opinions About Copyright for AI-Generated Art: The Role of Egocentricity, Competition, and Experience. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems. 1–32
2025
-
[39]
Gabriel Lima, Nina Grgić-Hlača, and Meeyoung Cha. 2023. Blaming Humans and Machines: What Shapes People’s Reactions to Algorithmic Harm. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems(Hamburg, Germany)(CHI ’23). Association for Computing Machinery, New York, NY, USA, Article 372, 26 pages. doi:10.1145/3544548.3580953
-
[40]
Gabriel Lima, Nina Grgić-Hlača, Markus Langer, and Yixin Zou. 2025. Lay Perceptions of Algorithmic Discrimination in the Context of Systemic Injustice. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems (CHI ’25). Association for Computing Machinery, New York, NY, USA, Article 1114, 30 pages. doi:10.1145/3706598.3713536
-
[41]
Pei-Yi Lin, Ching-Sing Chai, Morris Siu-Yung Jong, Yun Dai, Yanmei Guo, and Jianjun Qin. 2021. Modeling the structural relationship among primary students’ motivation to learn artificial intelligence.Computers and Education: Artificial Intelligence2 (2021), 100006
2021
-
[42]
Duri Long and Brian Magerko. 2020. What is AI Literacy? Competencies and Design Considerations. InProceedings of the 2020 CHI Conference on Human Factors in Computing Systems(Honolulu, HI, USA)(CHI ’20). Association for Computing Machinery, New York, NY, USA, 1–16. doi:10.1145/3313831.3376727
-
[43]
Qianou Ma, Anika Jain, Jini Kim, Megan Chai, and Geoff Kaufman. 2025. ImaginAItion: Promoting Generative AI Literacy Through Game-Based Learning. InProceedings of the Extended Abstracts of the CHI Conference on Human Factors in Computing Systems (CHI EA ’25). Association for Manuscript submitted to ACM What People See (and Miss) About Generative AI Risks ...
-
[44]
Rongjun Ma, Caterina Maidhof, Juan Carlos Carrillo, Janne Lindqvist, and Jose Such. 2025. Privacy Perceptions of Custom GPTs by Users and Creators. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems (CHI ’25). Association for Computing Machinery, New York, NY, USA, Article 237, 18 pages. doi:10.1145/3706598.3713540
-
[45]
2025.34% of U.S
Olivia Sidoti {and} Colleen McClain. 2025.34% of U.S. adults have used ChatGPT, about double the share in 2023. https://www.pewresearch.org/short- reads/2025/06/25/34-of-us-adults-have-used-chatgpt-about-double-the-share-in-2023/
2025
-
[46]
Sean McGregor. [n. d.]. Preventing Repeated Real World AI Failures by Cataloging Incidents: The AI Incident Database. https://incidentdatabase.ai/
-
[47]
Meredith Ringel Morris and Jed R. Brubaker. 2025. Generative Ghosts: Anticipating Benefits and Risks of AI Afterlives. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems (CHI ’25). Association for Computing Machinery, New York, NY, USA, Article 536, 14 pages. doi:10.1145/3706598.3713758
-
[48]
Jimin Mun, Wei Bin Au Yeong, Wesley Hanwen Deng, Jana Schaich Borg, and Maarten Sap. 2025. Why (Not) Use AI? Analyzing People’s Reasoning and Conditions for AI Acceptability.Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society8, 2 (Oct. 2025), 1771–1784. doi:10.1609/aies.v8i2.36673
- [49]
-
[50]
Devesh Narayanan, Mahak Nagpal, Jack McGuire, Shane Schweitzer, and David De Cremer. 2024. Fairness Perceptions of Artificial Intelligence: A Re- view and Path Forward.International Journal of Human–Computer Interaction40, 1 (2024), 4–23. arXiv:https://doi.org/10.1080/10447318.2023.2210890 doi:10.1080/10447318.2023.2210890
-
[51]
Davy Tsz Kit Ng, Jac Ka Lok Leung, Samuel Kai Wah Chu, and Maggie Shen Qiao. 2021. Conceptualizing AI literacy: An exploratory review. Computers and Education: Artificial Intelligence2 (2021), 100041. doi:10.1016/j.caeai.2021.100041
-
[52]
Tina Nguyen. 2025. AI super PACs, the hottest investment in tech. https://www.theverge.com/regulator-newsletter/766105/ai-super-pac-tech- investments
2025
-
[53]
NIST. 2023. Artificial intelligence risk management framework (AI RMF 1.0).National Institute of Standards and Technology(2023), 100–1
2023
-
[54]
Jonas Oppenlaender, Johanna Silvennoinen, Ville Paananen, and Aku Visuri. 2023. Perceptions and Realities of Text-to-Image Generation. In26th International Academic Mindtrek Conference (Mindtrek ’23). ACM, 279–288. doi:10.1145/3616961.3616978
-
[55]
The Collective Intelligence Project. 2023. Participatory AI Risk Prioritization: Alignment Assembly Report.Alignment Assembly Report(2023)
2023
-
[56]
Zachery Quince and Sasha Nikolic. 2025. Student identification of the social, economic and environmental implications of using Generative Artificial Intelligence (GenAI): identifying student ethical awareness of ChatGPT from a scaffolded multi-stage assessment.European journal of engineering education(2025), 1–20
2025
-
[57]
Irene Rae. 2024. The Effects of Perceived AI Use On Content Perceptions. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems(Honolulu, HI, USA)(CHI ’24). Association for Computing Machinery, New York, NY, USA, Article 978, 14 pages. doi:10.1145/3613904.3642076
-
[58]
Elizabeth Kumar, Aaron Horowitz, and Andrew D
Inioluwa Deborah Raji, I. Elizabeth Kumar, Aaron Horowitz, and Andrew Selbst. 2022. The Fallacy of AI Functionality. InProceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency(Seoul, Republic of Korea)(FAccT ’22). Association for Computing Machinery, New York, NY, USA, 959–972. doi:10.1145/3531146.3533158
-
[59]
Juan David Rodríguez-García, Jesús Moreno-León, Marcos Román-González, and Gregorio Robles. 2021. Evaluation of an online intervention to teach artificial intelligence with learningml to 10-16-year-old students. InProceedings of the 52nd ACM technical symposium on computer science education. 177–183
2021
-
[60]
Renee Shelby, Shalaleh Rismani, Kathryn Henne, AJung Moon, Negar Rostamzadeh, Paul Nicholas, N’Mah Yilla-Akbari, Jess Gallegos, Andrew Smart, Emilio Garcia, and Gurleen Virk. 2023. Sociotechnical Harms of Algorithmic Systems: Scoping a Taxonomy for Harm Reduction. InProceedings of the 2023 AAAI/ACM Conference on AI, Ethics, and Society(Montréal, QC, Canad...
-
[61]
The AI risk repository: A meta-review, database, and taxonomy of risks from artificial intelligence
Peter Slattery, Alexander K. Saeri, Emily A. C. Grundy, Jess Graham, Michael Noetel, Risto Uuk, James Dao, Soroush Pour, Stephen Casper, and Neil Thompson. 2025. The AI Risk Repository: A Comprehensive Meta-Review, Database, and Taxonomy of Risks From Artificial Intelligence. arXiv:2408.12622 [cs.AI] https://arxiv.org/abs/2408.12622
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [62]
-
[63]
Stefan Strauß. 2021. "Don’t let me be misunderstood": Critical AI literacy for the constructive use of AI technology.TATuP - Zeitschrift für Technikfolgenabschätzung in Theorie und Praxis / Journal for Technology Assessment in Theory and Practice30, 3 (2021), 44–49. doi:10.14512/tatup.30.3.44
-
[64]
Northup, Kenneth Holstein, Haiyi Zhu, Hoda Heidari, and Hong Shen
Ningjing Tang, Jiayin Zhi, Tzu-Sheng Kuo, Calla Kainaroi, Jeremy J. Northup, Kenneth Holstein, Haiyi Zhu, Hoda Heidari, and Hong Shen. 2024. AI Failure Cards: Understanding and Supporting Grassroots Efforts to Mitigate AI Failures in Homeless Services. InProceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency(Rio de Janeiro, B...
-
[65]
Catherine Thorbecke. 2023. AI tools make things up a lot, and that’s a huge problem.CNN(2023). https://edition.cnn.com/2023/08/29/tech/ai- chatbot-hallucinations/index.html Published 2:35 PM EDT, Tue August 29, 2023
2023
-
[66]
Jan Tolsdorf, Monica Kodwani, Junho Eum, Mahmood Sharif, and Adam J Aviv. 2025. Safety Perceptions of Generative AI Conversational Agents: Uncovering Perceptual Differences in Trust, Risk, and Fairness. In21st Symposium on Usable Privacy and Security. Manuscript submitted to ACM 20 Li et al
2025
-
[67]
David Touretzky, Christina Gardner-McCune, Fred Martin, and Deborah Seehorn. 2019. Envisioning AI for K-12: what should every child know about AI?. InProceedings of the Thirty-Third AAAI Conference on Artificial Intelligence and Thirty-First Innovative Applications of Artificial Intelligence Conference and Ninth AAAI Symposium on Educational Advances in A...
-
[68]
Xiaoyu Wan, Xiaofei Zhou, Zaiqiao Ye, Chase K Mortensen, and Zhen Bai. 2020. SmileyCluster: supporting accessible machine learning in K-12 scientific discovery. InProceedings of the interaction design and children conference. 23–35
2020
-
[69]
Chaofan Wang, Samuel Kernan Freire, Mo Zhang, Jing Wei, Jorge Goncalves, Vassilis Kostakos, Alessandro Bozzon, and Evangelos Niforatos. 2025. Safeguarding Crowdsourcing Surveys from ChatGPT through Prompt Injection.Proc. ACM Hum.-Comput. Interact.9, 7, Article CSCW322 (Oct. 2025), 29 pages. doi:10.1145/3757503
-
[70]
Trevor Watkins. 2020. Cosmology of artificial intelligence project: Libraries, makerspaces, community and AI literacy.AI Matters5, 4 (2020), 14–17
2020
-
[71]
Laura Weidinger, Maribeth Rauh, Nahema Marchal, Arianna Manzini, Lisa Anne Hendricks, Juan Mateos-Garcia, Stevie Bergman, Jackie Kay, Conor Griffin, Ben Bariach, Iason Gabriel, Verena Rieser, and William Isaac. 2023. Sociotechnical Safety Evaluation of Generative AI Systems. http://arxiv.org/abs/2310.11986 arXiv:2310.11986 [cs]
- [72]
-
[73]
Shixian Xie, John Zimmerman, and Motahhare Eslami. 2025. Exploring What People Need to Know to be AI Literate: Tailoring for a Diversity of AI Roles and Responsibilities. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems (CHI ’25). Association for Computing Machinery, New York, NY, USA, Article 1018, 16 pages. doi:10.1145/3706...
-
[74]
Chien Wen (Tina) Yuan, Nanyi Bi, Ya-Fang Lin, and Yuen-Hsien Tseng. 2023. Contextualizing User Perceptions about Biases for Human-Centered Explainable Artificial Intelligence. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems(Hamburg, Germany)(CHI ’23). Association for Computing Machinery, New York, NY, USA, Article 248, 15 pa...
-
[75]
Mireia Yurrita, Tim Draws, Agathe Balayn, Dave Murray-Rust, Nava Tintarev, and Alessandro Bozzon. 2023. Disentangling Fairness Perceptions in Algorithmic Decision-Making: the Effects of Explanations, Human Oversight, and Contestability. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems(Hamburg, Germany)(CHI ’23). Association f...
- [76]
-
[77]
Jonathan Zong and J. Nathan Matias. 2024. Data Refusal from Below: A Framework for Understanding, Evaluating, and Envisioning Refusal as Design.ACM J. Responsib. Comput.1, 1, Article 10 (March 2024), 23 pages. doi:10.1145/3630107 A Expert Validation Worksheet Questions with standard bullets were single-select; those with squares allowed for multiple selec...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.