Density-valued VAR Models with Latent Factors
Pith reviewed 2026-05-07 15:55 UTC · model grok-4.3
The pith
A latent-factor density VAR decomposes common trends from directed regional dynamics in viral load distributions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By representing regional density functions of Ct values through B-spline mixtures and applying a generalized logit transform, the transformed series are modeled as a VAR process with latent factors; this allows the idiosyncratic component to reveal directed edges via one-sided tests under false discovery rate control, yielding a network of predictive relations from the northern region toward southeastern metropolitan areas in the adjusted sample.
What carries the argument
The latent-factor-augmented density-valued VAR, which decomposes the dynamics of transformed density weights into common latent factors capturing strong shared movements and an idiosyncratic VAR component that isolates directed predictive relations.
Load-bearing premise
That dropping the first six months of data and using a weak prior on the densities isolates genuine directed predictive relations instead of introducing selection effects or prior-driven artifacts.
What would settle it
Observing the same north-to-southeast directed network when the full sample is used without exclusion, or when the density prior is strengthened, would falsify the interpretation that the network reflects true idiosyncratic dynamics.
Figures




read the original abstract
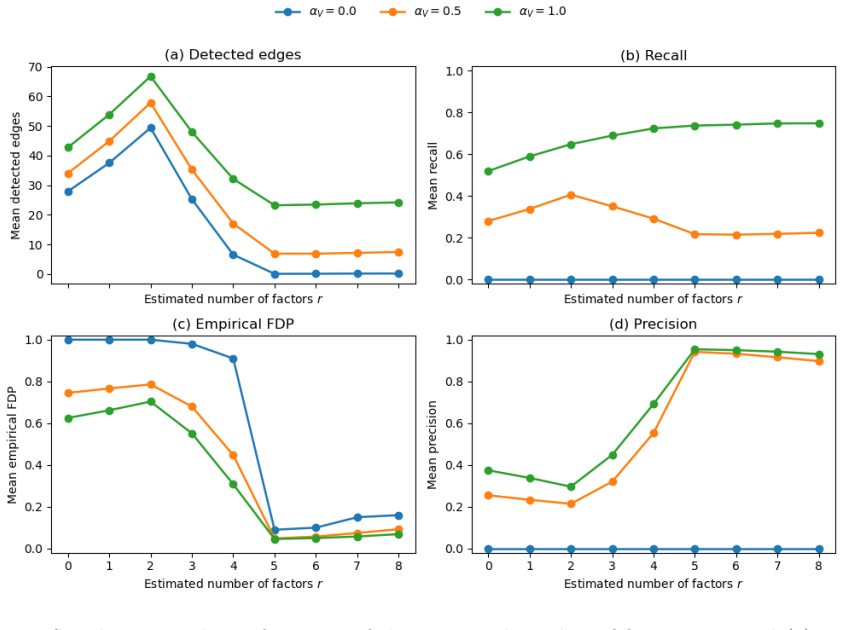
We propose a density-valued vector autoregressive model with latent factors for multivariate time series of density functions. Motivated by weekly regional distributions of SARS-CoV-2 cycle threshold (Ct) values in Brazil, we study their distributional dynamics across regions. The Ct value is the number of amplification cycles required for the viral signal to cross a detection threshold (lower Ct values correspond to higher viral load). We estimate each regional density by a B-spline mixture, mapping the mixture weights to a Euclidean space by a generalized logit transform equipped with an isometric inner product, and model the transformed series by a cross-regional VAR with latent factors. This decomposition allows for the separation between strong common movements and directed idiosyncratic dynamics. Directed edges are identified from the idiosyncratic VAR component using one-sided tests with Benjamini--Yekutieli false discovery rate control. Simulations show that increasing the number of estimated factors does not mechanically eliminate genuine idiosyncratic dependence; rather, it mainly removes spuriously detected edges driven by common factor movements. In the real-world data application, the full sample yields only a weak directed network, whereas a substantial network emerges once the first six months are excluded and the density prior is kept weak. The estimated links suggest directed predictive relations from the northern region toward southeastern metropolitan areas.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a density-valued VAR model with latent factors for multivariate time series of density functions. Densities are estimated via B-spline mixtures, mapped to Euclidean space through a generalized logit transform with isometric inner product, and modeled via a cross-regional VAR that decomposes common factor movements from idiosyncratic dynamics. Directed edges are recovered from the idiosyncratic component via one-sided tests with Benjamini-Yekutieli FDR control. Simulations demonstrate that additional factors primarily eliminate spurious common-factor edges without removing genuine idiosyncratic dependence. In the SARS-CoV-2 Ct-value application to Brazilian regions, the full sample yields only a weak network, while a substantial directed network (northern to southeastern regions) appears after excluding the first six months and using a weak density prior.
Significance. If the central decomposition and edge-identification procedure are robust, the framework offers a principled way to separate global trends from region-specific predictive relations in distributional time series, with clear relevance to epidemiological monitoring and other density-valued data. The simulation evidence that factor augmentation removes spurious rather than genuine edges is a concrete methodological strength that supports the separation claim.
major comments (2)
- [real-world data application] Real-world data application (abstract and §5): the reported directed network from northern to southeastern regions is obtained only after excluding the first six months of data and retaining a weak density prior; the manuscript provides no pre-specified justification for these choices, and the simulations in §4 do not examine sensitivity to sample truncation or prior strength. Because the full-sample result is described as weak, these two post-estimation decisions are load-bearing for the empirical claim.
- [§4] §4 (simulations): while the reported experiments correctly show that increasing the number of latent factors removes spurious common-factor edges without eliminating genuine idiosyncratic dependence, they do not include robustness checks for the exact sample-truncation and prior-strength choices that drive the empirical network. This leaves open whether the separation result generalizes to the data-dependent decisions used in the application.
minor comments (3)
- [model description] The description of the generalized logit transform and isometric inner product would benefit from an explicit statement of the dimension of the transformed space and how the B-spline knot placement is chosen.
- [estimation] It is unclear how the number of latent factors is selected in the real-data analysis; a data-driven criterion or cross-validation procedure should be stated.
- [abstract and application] The abstract and application section should report the total number of regions, the exact time span, and the number of weekly observations to allow readers to assess the scale of the network.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and constructive suggestions. We address the major comments point by point below, proposing revisions to enhance the robustness and transparency of our analysis.
read point-by-point responses
-
Referee: [real-world data application] Real-world data application (abstract and §5): the reported directed network from northern to southeastern regions is obtained only after excluding the first six months of data and retaining a weak density prior; the manuscript provides no pre-specified justification for these choices, and the simulations in §4 do not examine sensitivity to sample truncation or prior strength. Because the full-sample result is described as weak, these two post-estimation decisions are load-bearing for the empirical claim.
Authors: We agree that the empirical network is sensitive to these choices and that pre-specification would have been preferable. The exclusion of the initial six months was motivated by the documented ramp-up in SARS-CoV-2 testing capacity in Brazil during early 2020, which likely introduced noise and bias into the Ct-value distributions. The weak density prior was selected to minimize shrinkage and allow the data to inform the density shapes more directly. In the revised manuscript, we will explicitly state these motivations in §5 with supporting references to the epidemiological literature on early-pandemic data quality. Additionally, we will conduct and report sensitivity analyses by varying the truncation point (e.g., excluding 3, 6, or 9 months) and prior strength, presenting the resulting networks and discussing stability. We will also update the simulation section to include scenarios with truncated samples and varying priors to assess the robustness of the factor decomposition. revision: yes
-
Referee: [§4] §4 (simulations): while the reported experiments correctly show that increasing the number of latent factors removes spurious common-factor edges without eliminating genuine idiosyncratic dependence, they do not include robustness checks for the exact sample-truncation and prior-strength choices that drive the empirical network. This leaves open whether the separation result generalizes to the data-dependent decisions used in the application.
Authors: We acknowledge this limitation in the current simulation design. While the existing simulations demonstrate the core property of the factor-augmented model, they do not directly replicate the data-dependent decisions from the application. In the revision, we will extend §4 with additional simulation experiments that incorporate sample truncation and different prior strengths in the density estimation step. These will evaluate whether the separation of common and idiosyncratic components remains reliable under conditions mimicking the real-data choices, thereby addressing the generalizability concern. revision: yes
Circularity Check
No circularity detected in model derivation or empirical claims
full rationale
The paper defines a density-valued VAR with latent factors via explicit steps: B-spline mixture estimation of regional densities, generalized logit transform to Euclidean space, cross-regional VAR decomposition into common factors plus idiosyncratic component, and one-sided tests on the idiosyncratic VAR for directed edges. These steps are constructed forward from the data and model assumptions without any quoted equation reducing the reported directed network (or its north-to-southeast pattern) back to a fitted parameter or prior choice by definition. Simulations are used only to verify that factor count removes spurious common-factor edges rather than genuine idiosyncratic ones, which is an independent check. The reported sensitivity to excluding the first six months and prior strength is presented as an empirical observation, not a load-bearing derivation step or self-citation chain. No self-citations, uniqueness theorems, or ansatzes are invoked to force the central result.
Axiom & Free-Parameter Ledger
free parameters (3)
- number of latent factors
- B-spline mixture parameters
- density prior strength
axioms (2)
- domain assumption The generalized logit transform equipped with an isometric inner product maps density mixture weights to a Euclidean space suitable for standard VAR modeling.
- domain assumption The time series of transformed densities can be decomposed into common latent factor movements plus idiosyncratic directed dynamics.
Reference graph
Works this paper leans on
-
[1]
Baggio, S., L’Huillier, A. G., Yerly, S., Bellon, M., Wagner, N., Rohr, M., Huttner, B., Blanchard- Rohner, G., Loevy, N., Kaiser, L., and Gervaix, A. (2021). Severe acute respiratory syndrome coronavirus 2 (sars-cov-2) viral load in the upper respiratory tract of children and adults with early acute coronavirus disease 2019 (covid-19).Clinical Infectious...
work page 2021
-
[2]
Bai, J. (2009). Panel data models with interactive fixed effects.Econometrica, 77(4):1229–1279. Bai, J. and Ng, S. (2002). Determining the number of factors in approximate factor models. Econometrica, 70(1):191–221. Banho, C. A., Sacchetto, L., Campos, G. R. F., et al. (2022). Impact of sars-cov-2 gamma lin- eage introduction and covid-19 vaccination on t...
work page 2009
-
[3]
Stock, J. H. and Watson, M. W. (2002). Macroeconomic forecasting using diffusion indexes.Journal of Business & Economic Statistics, 20(2):147–162. van den Boogaart, K. G., Egozcue, J. J., and Pawlowsky-Glahn, V. (2010). Bayes linear spaces. SORT–Statistics and Operations Research Transactions, 34(2):201–222. van der Vaart, A. W. (1998).Asymptotic Statisti...
work page 2002
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.