Meta-Analysis Without Normality: Estimating the True Effect Distribution with Penalized Gaussian Mixtures
Pith reviewed 2026-05-07 05:54 UTC · model grok-4.3
The pith
Penalized Gaussian mixtures recover the full distribution of true effects in meta-analysis without assuming normality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the Penalized Gaussian Mixture (PGM) framework recovers the probability density function of true effects in random-effects meta-analysis without enforcing a rigid parametric shape such as normality. It adapts to skewed and multimodal distributions while reducing to the normal case when supported by the data. A simulation study shows that in large, highly heterogeneous meta-analyses, PGM yields substantially more accurate estimates of tail probabilities and the density function than standard methods when normality is violated, without substantially compromising efficiency under normality. An empirical application illustrates its practical utility for moving beyond简单的
What carries the argument
The Penalized Gaussian Mixture (PGM) model, which represents the distribution of true effects as a finite mixture of Gaussians equipped with a penalty term to control the number of components and recover the underlying density from observed study estimates.
If this is right
- Researchers obtain more accurate probabilities for effects exceeding policy-relevant thresholds in heterogeneous collections of studies.
- The method detects multimodality or skewness that signals the presence of distinct subgroups or asymmetric impacts.
- In large datasets the approach maintains statistical efficiency comparable to normal assumptions while handling violations of that assumption.
- Applications such as environmental education data allow fuller characterization of how effects vary across real-world conditions.
- Simple summary statistics become insufficient; full density estimation reveals the actual shape of the evidence base.
Where Pith is reading between the lines
- The same penalized mixture structure could be applied to random-effects models in other domains such as ecology or clinical trials to capture non-normal heterogeneity without new software.
- Sensitivity checks over penalty strength and component count would become a routine reporting step to guard against under- or over-fitting the effect distribution.
- If PGM estimates prove stable across repeated analyses of the same topic, they could replace normality as the default in meta-analysis software packages.
- Direct comparison with fully nonparametric density estimators on the same simulated and real datasets would clarify whether the Gaussian mixture restriction limits flexibility in extreme cases.
Load-bearing premise
A penalized finite Gaussian mixture can recover the true underlying effect distribution from observed study estimates without the choice of penalty or number of components introducing bias or failing to capture important features.
What would settle it
Generate data from a known bimodal or heavily skewed true effect distribution in a large heterogeneous meta-analysis setting, then compare the PGM estimated tail probabilities and density against the known ground truth and against estimates from a standard normal random-effects model; if PGM shows no substantial accuracy gain, the claim does not hold.
Figures


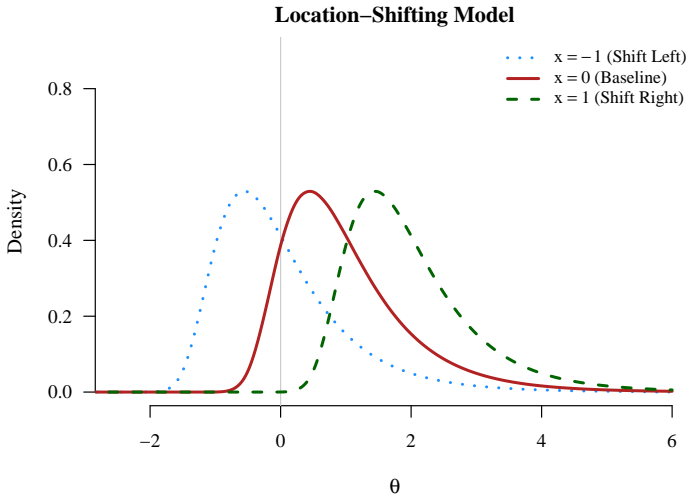









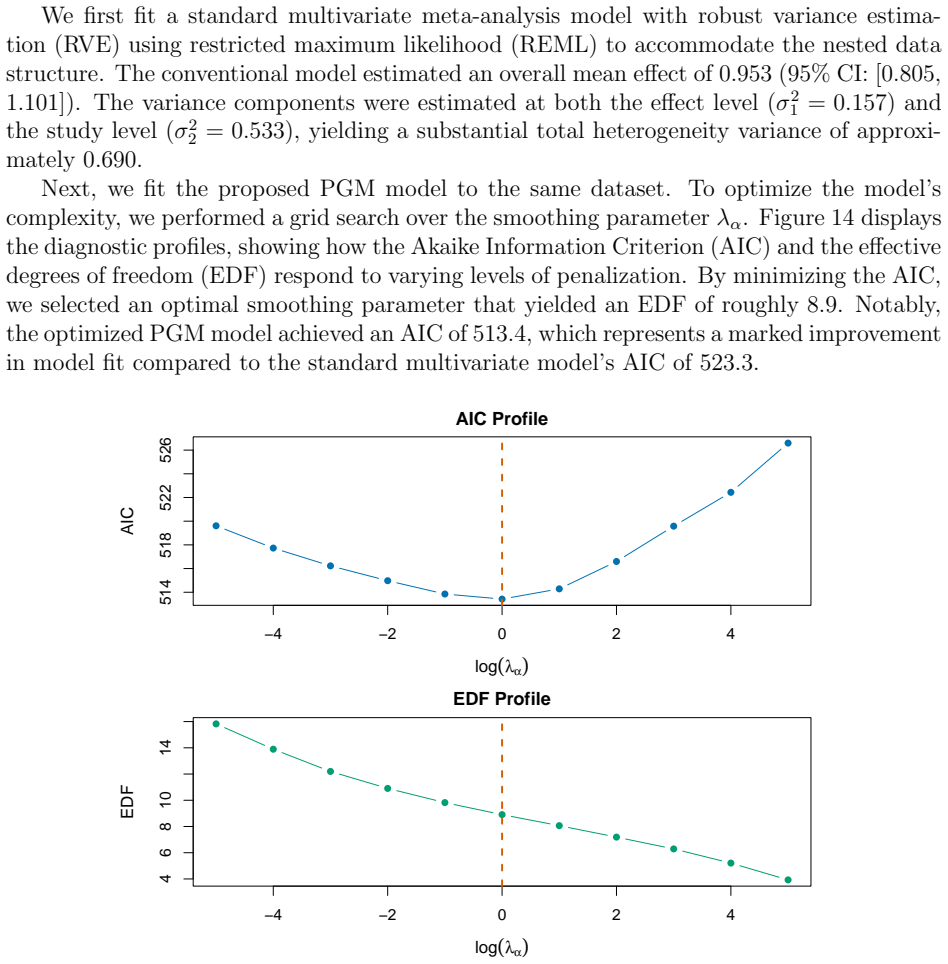



read the original abstract
Standard random-effects meta-analysis relies heavily on the assumption that the underlying true effects are normally distributed. In the social sciences, where evidence synthesis increasingly involves large, highly heterogeneous datasets, this assumption is often restrictive and unjustified. Misspecification of the random-effects distribution prevents the detection of asymmetry or multimodality, potentially leading to erroneous conclusions regarding the prevalence of adverse effects or the existence of specific subgroups. This paper introduces a Penalized Gaussian Mixture (PGM) framework designed to recover the entire probability density function of true effects without enforcing a rigid parametric shape. The method adapts to different non-normal scenarios, including skewed and multimodal distributions, while reducing to the normal case when supported by the data. A simulation study demonstrates that in large, highly heterogeneous meta-analyses, PGM yields substantially more accurate estimates of tail probabilities and the density function than standard methods when normality is violated, without substantially compromising efficiency under normality. An empirical application to environmental education data illustrates the practical utility of the method. The proposed framework provides researchers with a robust tool to move beyond simple summary statistics and characterize the complex nature of the true effect distribution in the real world.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a Penalized Gaussian Mixture (PGM) framework for estimating the distribution of true effects in random-effects meta-analysis without assuming normality. The method uses a penalized finite mixture of Gaussians to flexibly recover the full density f(θ) from observed y_i ~ N(θ_i, s_i²), reducing to the normal model when the data support it. A simulation study is used to demonstrate improved accuracy in tail probabilities and density estimation under non-normal (skewed or multimodal) true distributions in large heterogeneous settings, with little efficiency loss under normality, plus an empirical illustration on environmental education data.
Significance. If the central recovery claim holds under realistic conditions, the work addresses a genuine limitation of standard meta-analysis in heterogeneous fields such as the social sciences, where detecting asymmetry or multimodality can matter for policy conclusions. The simulation-based evidence for gains in tail and density estimation, together with the automatic reduction to normality, would make PGM a practical extension beyond mean-variance summaries.
major comments (2)
- [Simulation Study] Simulation Study section: the reported advantages in tail-probability and density estimation rest on the specific rule used to select the penalty strength and the number of components K. The manuscript must state this rule explicitly (cross-validation, information criterion, or fixed grid) and include sensitivity checks across plausible values; without them the gains cannot be separated from possible tuning bias on the same DGPs used for evaluation.
- [Method] Method section, around the penalized likelihood: because the problem is heteroscedastic deconvolution, an overly strong penalty can flatten skewness or multimodality while an overly weak one can fit noise in the s_i. The paper should supply either theoretical bias bounds or additional simulation scenarios that vary the penalty over a wide range and report the resulting bias in tail quantiles and mode recovery.
minor comments (2)
- [Abstract] Abstract: the phrase 'substantially more accurate' should be accompanied by concrete numerical summaries (e.g., relative MSE or integrated squared error ratios) from the simulation tables rather than qualitative language.
- [Introduction] The manuscript would benefit from a short discussion of related nonparametric or mixture-based meta-analysis methods already in the literature, to clarify the precise incremental contribution of the penalization scheme.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and describe the revisions we will implement.
read point-by-point responses
-
Referee: [Simulation Study] Simulation Study section: the reported advantages in tail-probability and density estimation rest on the specific rule used to select the penalty strength and the number of components K. The manuscript must state this rule explicitly (cross-validation, information criterion, or fixed grid) and include sensitivity checks across plausible values; without them the gains cannot be separated from possible tuning bias on the same DGPs used for evaluation.
Authors: We agree that the selection rule for the penalty strength and K must be stated explicitly and that sensitivity checks are needed. In the revised manuscript we will add a clear description of the selection procedure in the Methods section. We will also expand the Simulation Study with a new subsection that varies both the penalty and K over a grid of plausible values and reports the resulting tail-probability and density-estimation errors. These checks will confirm that the reported gains are not artifacts of a single tuning choice. revision: yes
-
Referee: [Method] Method section, around the penalized likelihood: because the problem is heteroscedastic deconvolution, an overly strong penalty can flatten skewness or multimodality while an overly weak one can fit noise in the s_i. The paper should supply either theoretical bias bounds or additional simulation scenarios that vary the penalty over a wide range and report the resulting bias in tail quantiles and mode recovery.
Authors: We acknowledge the referee's concern about penalty sensitivity in the heteroscedastic setting. Deriving non-asymptotic bias bounds for the penalized mixture estimator is technically involved and lies outside the primary scope of this applied methodological paper. We will instead add simulation scenarios that sweep the penalty parameter over a wide range (from near-zero to strongly penalizing) and report bias in tail quantiles together with mode-recovery accuracy under skewed and multimodal true distributions. These results will be placed in the Simulation Study section. revision: partial
- Deriving theoretical bias bounds for the penalized Gaussian-mixture estimator in the heteroscedastic deconvolution problem.
Circularity Check
No significant circularity: PGM is a direct penalized likelihood estimator validated by independent simulations
full rationale
The paper defines the Penalized Gaussian Mixture estimator directly from the heteroscedastic model y_i ~ N(θ_i, s_i²) with θ_i drawn from an unknown density f, using a finite Gaussian mixture representation of f plus a penalty term on the mixture weights or parameters. This is a standard nonparametric deconvolution approach adapted to meta-analysis; the estimator equations do not presuppose the performance metrics or tail probabilities that are later evaluated. Simulations generate data from known non-normal DGPs, apply PGM, and compare recovered densities/tails to the known truth, providing external validation rather than reducing to quantities defined solely by the fitted parameters. No load-bearing self-citations, uniqueness theorems from prior author work, or ansatzes smuggled via citation appear in the derivation chain. The reduction to the normal case under data support is an explicit design feature of the penalty, not a circular redefinition.
Axiom & Free-Parameter Ledger
free parameters (2)
- penalty strength
- number of mixture components
axioms (2)
- domain assumption True effects can be well-approximated by a finite mixture of Gaussians
- domain assumption Penalized likelihood yields stable density estimates in meta-analytic settings
Reference graph
Works this paper leans on
-
[1]
Borenstein, M., Higgins, J. P. T., Hedges, L. V., & Rothstein, H. R. (2017). Basics of meta-analysis: I^2 is not an absolute measure of heterogeneity. Research Synthesis Methods, 8(1), 5--18
work page 2017
-
[2]
DerSimonian, R., & Laird, N. (1986). Meta-analysis in clinical trials. Controlled Clinical Trials, 7(3), 177--188
work page 1986
-
[3]
Eilers, P. H. C., & Marx, B. D. (1996). Flexible smoothing with B-splines and penalties. Statistical Science, 11(2), 89--121
work page 1996
-
[4]
Geyer, C. J. (2026). trust: Trust Region Optimization. R package. https://cran.r-project.org/web/packages/trust/index.html
work page 2026
-
[5]
Ghidey, W., Lesaffre, E., & Eilers, P. (2004). Smooth random effects distribution in a linear mixed model. Biometrics, 60(4), 945--953
work page 2004
-
[6]
Glass, G. V. (1976). Primary, secondary, and meta-analysis of research. Educational Researcher, 5(10), 3--8
work page 1976
-
[7]
Hardy, R. J., & Thompson, S. G. (1996). A likelihood approach to meta-analysis with random effects. Statistics in Medicine, 15(6), 619--629
work page 1996
-
[8]
Hedges, L. V., & Olkin, I. (1985). Statistical methods for meta-analysis. Academic Press
work page 1985
-
[9]
Kom \'a rek, A., & Lesaffre, E. (2008). Generalized linear mixed models with a penalized Gaussian mixture normal random effects distribution. Computational Statistics & Data Analysis, 52(7), 3441--3458
work page 2008
-
[10]
Kontopantelis, E., & Reeves, D. (2010). Performance of statistical methods for meta-analysis when true study effects are non-normally distributed: A simulation study. Statistical Methods in Medical Research, 21(4), 409--426
work page 2010
-
[11]
Mathur, M. B., & VanderWeele, T. J. (2019). New metrics for meta-analyses of heterogeneous effects. Statistics in Medicine, 38(8), 1336--1342
work page 2019
-
[12]
H., Metelli, S., & Chaimani, A
Panagiotopoulou, K., Evrenoglou, T., Schmid, C. H., Metelli, S., & Chaimani, A. (2025). Meta-analysis models relaxing the random-effects normality assumption: Methodological systematic review and simulation study. BMC Medical Research Methodology, 25, 231
work page 2025
-
[13]
Riley, R. D., Higgins, J. P., & Deeks, J. J. (2011). Interpretation of random effects meta-analyses. BMJ, 342, d549
work page 2011
-
[14]
Van de Wetering, J., Leijten, P., Spitzer, J., & Thomaes, S. (2022). Does environmental education benefit environmental outcomes in children and adolescents? A meta-analysis. Journal of Environmental Psychology, 81, 101782
work page 2022
-
[15]
Varin, C., Reid, N., & Firth, D. (2011). An overview of composite likelihood methods. Statistica Sinica, 21(1), 5--42
work page 2011
-
[16]
A., Jackson, D., Viechtbauer, W., Bender, R., Bowden, J., Knapp, G., Kuss, O., Higgins, J
Veroniki, A. A., Jackson, D., Viechtbauer, W., Bender, R., Bowden, J., Knapp, G., Kuss, O., Higgins, J. P., Langan, D., & Salanti, G. (2016). Methods to estimate the between-study variance and its uncertainty in meta-analysis. Research Synthesis Methods, 7(1), 55--79
work page 2016
-
[17]
Viechtbauer, W. (2010). Conducting meta-analyses in R with the metafor package. Journal of Statistical Software, 36(3), 1--48
work page 2010
-
[18]
Wu, W., Duan, J., Reed, W. R., & Tipton, E. (2025). What can we learn from 1,000 meta-analyses across 10 different disciplines? Research Synthesis Methods, 1--34
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.