Fast Semiparametric Density Regression with Weight-localized Predictive Recursion
Pith reviewed 2026-05-08 19:28 UTC · model grok-4.3
The pith
Weight-localized predictive recursion estimates how mixing densities change with covariates and yields consistent estimators for unmixed parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
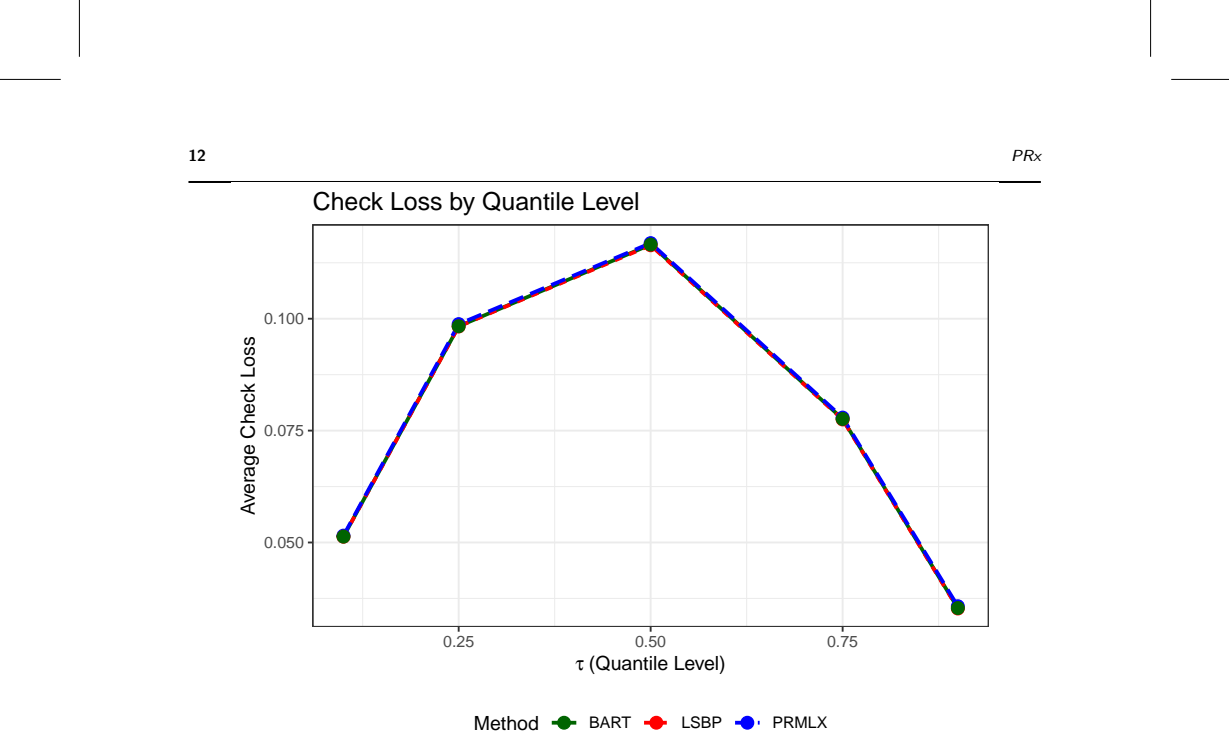
Predictive recursion is extended to the regression setting through PRx, which combines kernel-based weight localization with the original recursive scheme. Exactly as in ordinary PR, the algorithm produces the PRMLx likelihood score whose maximizer is a consistent estimator for unmixed parameters. PRx produces conditional density estimates competitive with established Bayesian procedures at a fraction of the computational cost.
What carries the argument
PRx, the predictive recursion algorithm localized by kernel weights on covariates, which enables recursive updating for mixing densities that depend on observed predictors.
If this is right
- The algorithm scales linearly in sample size and covariate dimension.
- Computations finish in seconds to minutes where MCMC competitors require hours.
- Conditional density estimates compete with established Bayesian procedures.
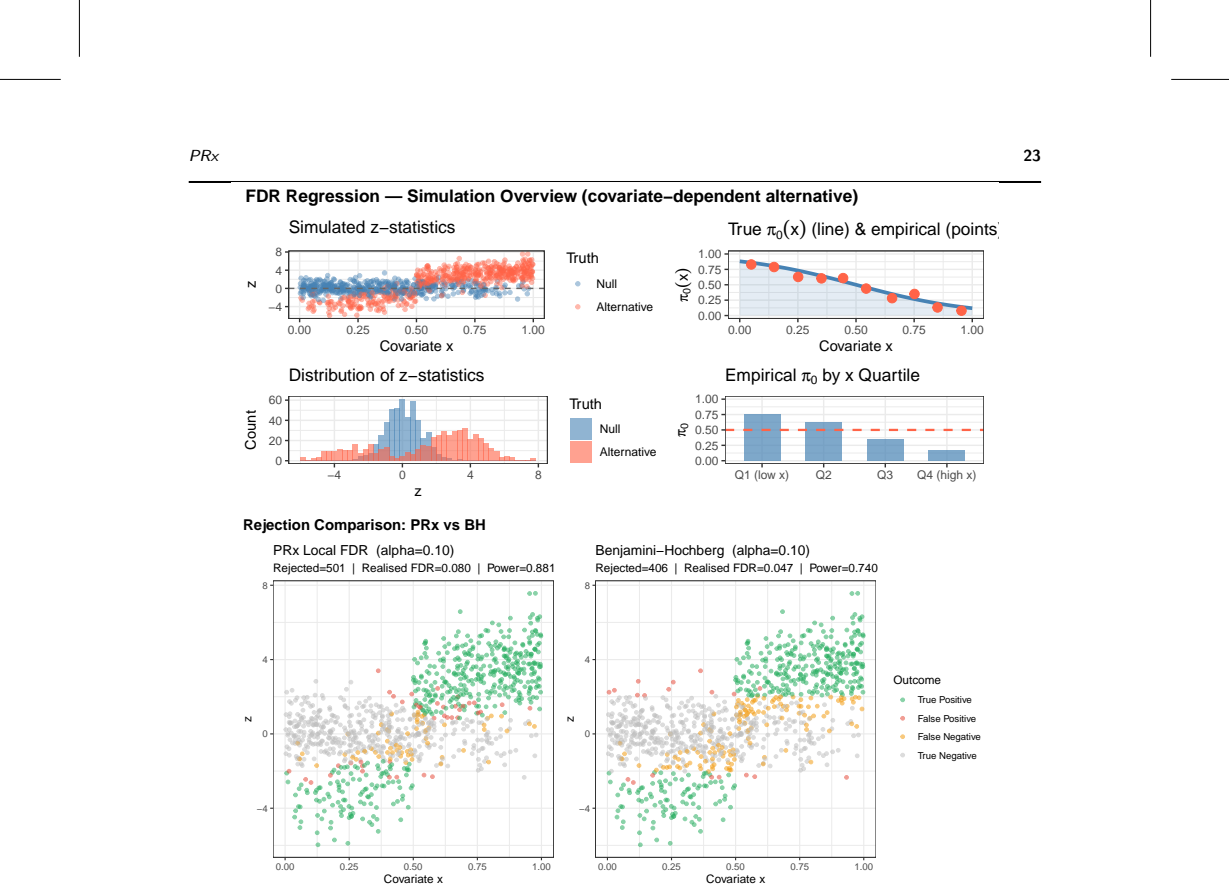
- The method adapts directly to Bayesian model comparison and covariate-dependent multiple testing.
Where Pith is reading between the lines
- PRx could support real-time analysis of streaming regression data where full Bayesian updates are too slow.
- The same localization idea might transfer to other recursive estimators for semiparametric problems.
- High-dimensional covariates would likely require bandwidth selection rules that preserve the linear scaling and consistency.
- Direct comparison with non-kernel localization schemes could test whether the kernel choice is essential for the observed performance.
Load-bearing premise
Kernel-based weight localization captures the smooth covariate dependence of the mixing density without substantial bias or problem-specific tuning that affects consistency.
What would settle it
A simulation or dataset in which the true mixing density varies non-smoothly or abruptly with the covariate, where PRx estimates fail to approach the true conditional densities or the PRMLx maximizer shows inconsistency.
Figures




read the original abstract
Predictive recursion (PR) is a fast algorithm for nonparametric estimation of a mixing density, with connections to sequential Bayesian updating under a Dirichlet process prior and rigorous frequentist consistency guarantees. Extending PR to the regression setting, where one seeks to estimate how a mixing density varies with covariate, is nontrivial: dependent Dirichlet process priors, the natural Bayesian generalization, gives no simple recursive updating formula. We introduce PRx, which overcomes this challenge through combining kernel-based weight localization with the recursive scheme of the original PR algorithm. The algorithm scales linearly in sample size and covariate dimension, completing in seconds to minutes where MCMC-based competitors require hours. Exactly as with ordinary PR, the algorithm produces as a byproduct a likelihood score, the PRMLx, whose maximizer is shown to be a consistent estimator for unmixed parameters. In simulations and case studies PRx produces conditional density estimates competitive with established Bayesian procedures at a fraction of the computational cost, and can also be adapted for a wide range of statistical applications including Bayesian model comparison and covariate-dependent multiple testing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PRx, an extension of predictive recursion (PR) to semiparametric density regression via kernel-based weight localization. This preserves the linear scaling and recursive structure of standard PR while enabling estimation of covariate-dependent mixing densities. The manuscript asserts that the maximizer of the derived PRMLx score is consistent for unmixed parameters, and reports that PRx yields conditional density estimates competitive with Bayesian MCMC methods at substantially lower computational cost in simulations and case studies, with extensions to model comparison and multiple testing.
Significance. If the consistency result holds and the empirical comparisons are robust, the work offers a valuable fast alternative to dependent Dirichlet process models for density regression. The linear-time complexity, byproduct likelihood score, and adaptability to other tasks are clear strengths. The approach builds directly on established PR theory without introducing circularity, providing a practical tool for large-scale semiparametric problems.
major comments (2)
- [Abstract and Theory] The abstract asserts consistency of the PRMLx maximizer and competitive simulation performance, but the provided description lacks details on the full derivation, error bounds, or how kernel localization preserves the original PR guarantees without introducing bias that affects the unmixed parameter consistency. A dedicated theory section with explicit proof sketch or key steps would be needed to substantiate the central claim.
- [Simulations] Simulations and case studies: The claim of competitive performance at a fraction of the computational cost requires explicit reporting of all tuning parameters (e.g., kernel bandwidth selection, number of PR iterations) and whether they were chosen via cross-validation or fixed a priori; unstated problem-specific tuning could affect both the fairness of comparisons and the practical advantage.
minor comments (2)
- [Methods] Notation for the weight-localized recursion (PRx) and PRMLx score should be introduced with a clear algorithmic pseudocode box early in the methods section to improve readability.
- [Simulations] The abstract mentions 'seconds to minutes' runtime; including a table with exact timings, sample sizes, and dimensions for PRx versus MCMC competitors would strengthen the computational claims.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review, as well as the positive assessment of the work's significance. We address each major comment below and have revised the manuscript to incorporate the requested clarifications and details.
read point-by-point responses
-
Referee: [Abstract and Theory] The abstract asserts consistency of the PRMLx maximizer and competitive simulation performance, but the provided description lacks details on the full derivation, error bounds, or how kernel localization preserves the original PR guarantees without introducing bias that affects the unmixed parameter consistency. A dedicated theory section with explicit proof sketch or key steps would be needed to substantiate the central claim.
Authors: We agree that the original manuscript would benefit from a more explicit theoretical exposition. While the consistency of the PRMLx maximizer for unmixed parameters is stated and follows from the original PR theory, the main text provided only a high-level argument. In the revised version we have added a dedicated Section 3 ('Theoretical Properties') containing a proof sketch. The sketch shows that, under standard conditions on the kernel (e.g., compact support or Gaussian with bandwidth h_n = o(1) and n h_n^d → ∞), the localization bias vanishes asymptotically for the unmixed parameters, thereby preserving the original PR consistency guarantees. Full error bounds and technical lemmas appear in the supplementary material, with explicit cross-references in the main text. The abstract has been updated to direct readers to this section. revision: yes
-
Referee: [Simulations] Simulations and case studies: The claim of competitive performance at a fraction of the computational cost requires explicit reporting of all tuning parameters (e.g., kernel bandwidth selection, number of PR iterations) and whether they were chosen via cross-validation or fixed a priori; unstated problem-specific tuning could affect both the fairness of comparisons and the practical advantage.
Authors: We acknowledge that the original submission did not fully document the tuning procedures. In the revision we have inserted a new 'Implementation and Tuning Details' subsection within the Simulations section. This subsection explicitly states: (i) kernel bandwidths were chosen by 5-fold cross-validation on the PRMLx score for each simulation replicate; (ii) the number of PR iterations was fixed at 1000 after verifying convergence of the recursive updates; (iii) the kernel was Gaussian with fixed localization scale. A summary table now lists all tuning choices for every experiment, together with a statement that the full code (including cross-validation routines) is available in the supplementary repository. These additions ensure reproducibility and allow readers to assess the fairness of the reported computational comparisons. revision: yes
Circularity Check
No significant circularity; derivation extends prior guarantees independently
full rationale
The paper introduces PRx by combining kernel weight localization with the recursive structure of original predictive recursion (PR). It explicitly relies on the established frequentist consistency guarantees of standard PR from prior literature rather than re-deriving them. The new consistency result for the maximizer of PRMLx is stated as a shown property of the extension, without evidence in the abstract or description that it reduces by construction to a fitted input, self-definition, or unverified self-citation chain. The computational and empirical claims are presented as direct consequences of the algorithmic design, not tautological renamings. This is a standard, non-circular extension of an externally validated method.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Mixing density varies smoothly with covariate
invented entities (1)
-
PRx algorithm
no independent evidence
Lean theorems connected to this paper
-
Cost.FunctionalEquation (J(x)=½(x+x⁻¹)−1)washburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
K_i(x) = ∫ f(θ|x) log(f(θ|x)/f_i(θ|x)) μ(dθ)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Tokdar and Ryan Martin and Jayanta K
Surya T. Tokdar and Ryan Martin and Jayanta K. Ghosh , journal =. Consistency of a Recursive Estimate of Mixing Distributions , urldate =
-
[2]
Practical nonparametric and semiparametric Bayesian statistics , pages=
Nonparametric Bayes methods using predictive updating , author=. Practical nonparametric and semiparametric Bayesian statistics , pages=. 1998 , publisher=
work page 1998
-
[3]
Asymptotic properties of predictive recursion: robustness and rate of convergence , author=
-
[4]
Semiparametric inference in mixture models with predictive recursion marginal likelihood , author=. Biometrika , volume=. 2011 , publisher=
work page 2011
-
[5]
Journal of the American Statistical Association , volume=
Joint estimation of quantile planes over arbitrary predictor spaces , author=. Journal of the American Statistical Association , volume=. 2017 , publisher=
work page 2017
-
[6]
The Review of Financial Studies , volume=
The role of proxy advisory firms: Evidence from a regression-discontinuity design , author=. The Review of Financial Studies , volume=. 2016 , publisher=
work page 2016
-
[7]
European Corporate Governance Institute--Finance Working Paper , number=
Why do investors vote against corporate directors? , author=. European Corporate Governance Institute--Finance Working Paper , number=
-
[8]
The quarterly journal of economics , volume=
Corporate governance and equity prices , author=. The quarterly journal of economics , volume=. 2003 , publisher=
work page 2003
-
[9]
On a nonparametric recursive estimator of the mixing distribution , author=. Sankhy. 2002 , publisher=
work page 2002
-
[10]
Journal of Statistical Planning and Inference , volume=
Tractable Bayesian density regression via logit stick-breaking priors , author=. Journal of Statistical Planning and Inference , volume=. 2021 , publisher=
work page 2021
-
[11]
Journal of the American Statistical Association , volume=
Adaptive conditional distribution estimation with Bayesian decision tree ensembles , author=. Journal of the American Statistical Association , volume=. 2023 , publisher=
work page 2023
-
[12]
A nonparametric empirical Bayes framework for large-scale multiple testing , author=. Biostatistics , volume=. 2012 , publisher=
work page 2012
-
[13]
Journal of the american statistical association , volume=
False discovery rate regression: an application to neural synchrony detection in primary visual cortex , author=. Journal of the american statistical association , volume=. 2015 , publisher=
work page 2015
-
[14]
Communications in Statistics-Theory and Methods , volume=
Asymptotically optimal nonparametric empirical Bayes via predictive recursion , author=. Communications in Statistics-Theory and Methods , volume=. 2015 , publisher=
work page 2015
-
[15]
Journal of Computational and Graphical statistics , volume=
Approximate Dirichlet process computing in finite normal mixtures: smoothing and prior information , author=. Journal of Computational and Graphical statistics , volume=. 2002 , publisher=
work page 2002
-
[16]
The Annals of Probability , pages=
The two-parameter Poisson-Dirichlet distribution derived from a stable subordinator , author=. The Annals of Probability , pages=. 1997 , publisher=
work page 1997
-
[17]
The annals of statistics , pages=
A Bayesian analysis of some nonparametric problems , author=. The annals of statistics , pages=. 1973 , publisher=
work page 1973
-
[18]
Journal of computational neuroscience , pages=
Spike count analysis for multiplexing inference (SCAMPI) , author=. Journal of computational neuroscience , pages=. 2026 , publisher=
work page 2026
-
[19]
Computational Statistics & Data Analysis , volume=
A mixture model approach for the analysis of microarray gene expression data , author=. Computational Statistics & Data Analysis , volume=. 2002 , publisher=
work page 2002
-
[20]
Image and Vision Computing , volume=
A mixture model for representing shape variation , author=. Image and Vision Computing , volume=. 1999 , publisher=
work page 1999
-
[21]
The Annals of Mathematical Statistics , pages=
Consistency of the maximum likelihood estimator in the presence of infinitely many incidental parameters , author=. The Annals of Mathematical Statistics , pages=. 1956 , publisher=
work page 1956
-
[22]
arXiv preprint arXiv:1206.5278 , year=
Fast nonparametric conditional density estimation , author=. arXiv preprint arXiv:1206.5278 , year=
-
[23]
Statistica Neerlandica , volume=
On conditional density estimation , author=. Statistica Neerlandica , volume=. 2003 , publisher=
work page 2003
-
[24]
Simultaneous linear quantile regression: A semiparametric bayesian approach , author=. Bayesian Analysis , volume=
-
[25]
Journal of the American Statistical Association , volume=
Oracle and adaptive compound decision rules for false discovery rate control , author=. Journal of the American Statistical Association , volume=. 2007 , publisher=
work page 2007
-
[26]
Anytime-valid and asymptotically efficient inference driven by predictive recursion , author=. Biometrika , volume=. 2025 , publisher=
work page 2025
-
[27]
Optimal post-selection inference for sparse signals: a nonparametric empirical Bayes approach , author=. Biometrika , volume=. 2022 , publisher=
work page 2022
-
[28]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
Quasi-Bayes properties of a procedure for sequential learning in mixture models , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 2020 , publisher=
work page 2020
-
[29]
Introduction to the Special Issue on Contemporary
Clarke, Bertrand and Rigo, Pietro , journal=. Introduction to the Special Issue on Contemporary. 2025 , publisher=
work page 2025
-
[30]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
Martingale posterior distributions , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 2023 , publisher=
work page 2023
-
[31]
ASA proceedings of the section on Bayesian statistical science , volume=
Dependent nonparametric processes , author=. ASA proceedings of the section on Bayesian statistical science , volume=. 1999 , organization=
work page 1999
-
[32]
Technical Report, Department of Statistics, The Ohio State University , year=
Dependent dirichlet processes , author=. Technical Report, Department of Statistics, The Ohio State University , year=
-
[33]
The dependent Dirichlet process and related models , author=. Statistical Science , volume=. 2022 , publisher=
work page 2022
-
[34]
Journal of the american statistical association , volume=
Bayesian density estimation and inference using mixtures , author=. Journal of the american statistical association , volume=. 1995 , publisher=
work page 1995
- [35]
-
[36]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
Covariate powered cross-weighted multiple testing , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 2021 , publisher=
work page 2021
-
[37]
Microarrays, empirical Bayes and the two-groups model , author=
-
[38]
Size, power and false discovery rates , author=
-
[39]
Journal of multivariate analysis , volume=
Posterior consistency in conditional distribution estimation , author=. Journal of multivariate analysis , volume=. 2013 , publisher=
work page 2013
-
[40]
Bayesian Analysis (Online) , volume=
Nonparametric Bayesian models through probit stick-breaking processes , author=. Bayesian Analysis (Online) , volume=
- [41]
-
[42]
A fast non-reversible sampler for
Ascolani, Filippo and Zanella, Giacomo , journal=. A fast non-reversible sampler for
-
[43]
Statistics and computing , volume=
Sampling from Dirichlet process mixture models with unknown concentration parameter: mixing issues in large data implementations , author=. Statistics and computing , volume=. 2015 , publisher=
work page 2015
-
[44]
Bayesian Density Regression with Logistic Gaussian Process and Subspace Projection , author=. Bayesian Analysis , volume=
-
[45]
Journal of the Royal statistical society: series B (Methodological) , volume=
Controlling the false discovery rate: a practical and powerful approach to multiple testing , author=. Journal of the Royal statistical society: series B (Methodological) , volume=. 1995 , publisher=
work page 1995
- [46]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.