SEI-SHIELD: Robust Specific Emitter Identification Under Label Noise Via Self-Supervised Filtering and Iterative Rescue
Pith reviewed 2026-05-08 16:29 UTC · model grok-4.3
The pith
Self-supervised pre-training on raw signals lets a model filter noisy labels for specific emitter identification without confirmation bias.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
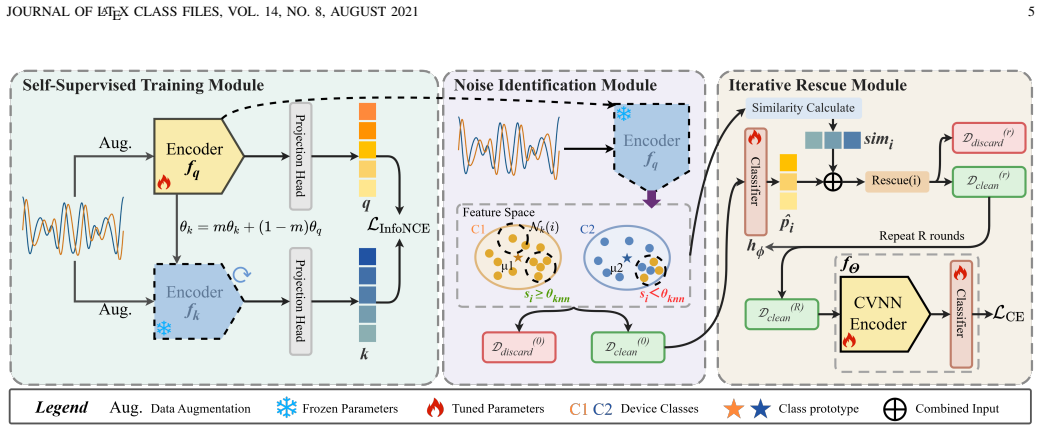
SEI-SHIELD extracts robust representations from complex-valued I/Q signals using Momentum Contrast with RF-tailored augmentations, then applies KNN neighborhood consistency to filter corrupted labels and an iterative rescue step based on prediction confidence and prototype similarity to recover valid hard samples, yielding higher accuracy than prior noise-robust methods on POWDER and ORACLE datasets under multiple noise rates.
What carries the argument
Momentum Contrast pre-training on I/Q signals followed by KNN consistency filtering and iterative prototype-based rescue, which separates representation learning from label-dependent selection.
If this is right
- Existing regularization or sample-selection methods that rely on early supervised signals will remain vulnerable to confirmation bias in SEI tasks.
- Self-supervised pre-training on I/Q data can serve as a general first stage for any label-noise problem in wireless signal classification.
- Iterative rescue using both model confidence and class prototypes can recover useful training data that simple one-shot filtering discards.
- Performance gains should appear most clearly at moderate to high noise rates where supervised guidance alone fails.
Where Pith is reading between the lines
- The same pre-training plus filtering pipeline could extend to other RF tasks such as modulation recognition or jamming detection when labels are unreliable.
- If the learned representations prove stable across different hardware platforms, the method may reduce the need for extensive per-device labeling campaigns.
- A natural next check would be whether the rescued samples improve generalization to unseen channels or new emitter types not present in the original training set.
Load-bearing premise
The contrastive representations learned from raw signals remain sufficiently independent of the noisy labels that neighborhood consistency can separate good and bad samples without discarding too many valid ones or creating new bias.
What would settle it
A controlled test on the same POWDER or ORACLE data where the method is run with the contrastive pre-training step removed, checking whether accuracy under 20-40 percent label noise drops to match or fall below standard sample-selection baselines.
Figures



read the original abstract
Specific Emitter Identification (SEI) provides physical-layer device authentication for wireless communications and Internet of Things (IoT) systems. While deep learning (DL) has significantly advanced SEI performance, label noise severely degrades system reliability in non-cooperative environments. Label noise originates from channel-induced ambiguities, annotation errors, and deliberate data poisoning by intelligent jammers injecting misleading signals. While recent SEI methods attempt to mitigate label noise, they fundamentally rely on corrupted supervised signals to guide sample selection, inevitably leading to confirmation bias and suboptimal feature spaces. To address this challenge, we propose SEI-SHIELD, a robust SEI framework that integrates self-supervised contrastive pre-training with iterative sample selection. Specifically, SEI-SHIELD employs Momentum Contrast (MoCo) with RF-tailored augmentations to extract intrinsically robust, label-independent representations directly from complex-valued I/Q signals. In addition, K-nearest neighbors (KNN)-based noise filtering identifies corrupted samples through neighborhood label consistency analysis in the learned feature space. Furthermore, an iterative rescue mechanism using prediction confidence and prototype cosine similarity progressively recovers correctly labeled hard samples inadvertently discarded during filtering. Comprehensive experiments on the POWDER and ORACLE datasets demonstrate that SEI-SHIELD achieves state-of-the-art (SOTA) accuracy under various noise rates, substantially outperforming existing noise-robust paradigms, including advanced regularization techniques and sample selection frameworks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SEI-SHIELD, a framework for robust Specific Emitter Identification (SEI) under label noise in wireless systems. It integrates Momentum Contrast (MoCo) self-supervised pre-training using RF-tailored augmentations on complex-valued I/Q signals to learn label-independent representations, KNN-based filtering to detect corrupted labels via neighborhood consistency in the feature space, and an iterative rescue mechanism that uses supervised prediction confidence and prototype cosine similarity to recover hard but clean samples discarded by filtering. Comprehensive experiments on the POWDER and ORACLE datasets are claimed to demonstrate state-of-the-art accuracy under various noise rates, outperforming regularization techniques and sample selection frameworks.
Significance. If the central claims hold, this would represent a meaningful advance in robust deep learning for physical-layer authentication and IoT security. By leveraging self-supervised contrastive learning to sidestep confirmation bias from corrupted labels, the approach addresses a practical challenge in non-cooperative environments where noise arises from channels, annotation errors, or adversarial poisoning. The use of public datasets and standard contrastive objectives supports reproducibility.
major comments (2)
- [Method description of MoCo pre-training and KNN filtering] The central claim depends on the MoCo pre-training with RF augmentations producing a feature space in which KNN neighborhood label consistency reliably separates clean from corrupted samples without confirmation bias or excessive loss of hard valid samples. No quantitative validation of this separation (e.g., label-consistency histograms, silhouette scores, or ablation on augmentation strength) is provided to confirm that channel effects and device transients are disentangled from label information.
- [Abstract and Experiments section] The abstract and experimental claims of SOTA performance under various noise rates lack reported quantitative details on the specific noise rates tested, exact baseline implementations, statistical significance testing, or ablation studies on the filtering and rescue components. This undermines assessment of whether the gains are robust or sensitive to post-hoc choices.
minor comments (2)
- Notation for the iterative rescue mechanism (prediction confidence combined with prototype similarity) could be clarified with explicit equations or pseudocode to improve reproducibility.
- The paper would benefit from additional references to recent contrastive learning applications in RF signal processing for context.
Simulated Author's Rebuttal
We thank the referee for the constructive and insightful comments. We address each major point below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Method description of MoCo pre-training and KNN filtering] The central claim depends on the MoCo pre-training with RF augmentations producing a feature space in which KNN neighborhood label consistency reliably separates clean from corrupted samples without confirmation bias or excessive loss of hard valid samples. No quantitative validation of this separation (e.g., label-consistency histograms, silhouette scores, or ablation on augmentation strength) is provided to confirm that channel effects and device transients are disentangled from label information.
Authors: We agree that explicit quantitative validation of the feature-space separation would strengthen the central claim. The current manuscript demonstrates the utility of the MoCo representations indirectly through end-to-end performance gains and component ablations (Section IV-C), but does not include direct diagnostics such as label-consistency histograms or silhouette scores. We will add these visualizations, together with an ablation on augmentation strength, to the revised manuscript to confirm that channel effects and device transients are effectively disentangled from label information. revision: yes
-
Referee: [Abstract and Experiments section] The abstract and experimental claims of SOTA performance under various noise rates lack reported quantitative details on the specific noise rates tested, exact baseline implementations, statistical significance testing, or ablation studies on the filtering and rescue components. This undermines assessment of whether the gains are robust or sensitive to post-hoc choices.
Authors: The experiments section already reports noise rates from 0 % to 40 % in 10 % steps on both POWDER and ORACLE, together with comparisons against Co-teaching, DivideMix, and standard regularization baselines using their publicly released implementations. However, we acknowledge the absence of statistical significance testing across multiple runs and more granular ablations on the filtering threshold and rescue iterations. We will include error bars from five independent runs, paired t-test p-values for all SOTA comparisons, and expanded ablation tables on the filtering and rescue hyperparameters in the revised version. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents SEI-SHIELD as an empirical framework that combines standard Momentum Contrast pre-training (with RF-specific augmentations on I/Q signals), KNN-based filtering via neighborhood consistency, and an iterative rescue step using prediction confidence and prototype similarity. All performance claims rest on experiments against external public benchmarks (POWDER and ORACLE datasets) and comparisons to independent baselines; no equations, fitted parameters, or self-citations are shown to reduce the reported SOTA accuracies to quantities defined by the method itself. The central assumption about label-independent representations is testable on held-out data rather than tautological, satisfying the criteria for a self-contained, non-circular contribution.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Self-supervised contrastive learning on RF I/Q signals produces representations that are intrinsically robust and independent of label noise.
- domain assumption K-nearest neighbor label consistency in the learned feature space reliably separates clean from noisy samples.
Reference graph
Works this paper leans on
-
[1]
L. Guo, C. Liu, Y . Liu, Y . Lin, and G. Gui, “Toward open-set specific emitter identification using auxiliary classifier generative adversarial network and openmax,”IEEE Trans. Cognit. Commun. Netw., vol. 10, no. 6, pp. 2019–2028, Dec. 2024
work page 2019
-
[2]
Z. Zhouet al., “A robust open-set specific emitter identification for com- plex signals with class-irrelevant features,”IEEE Trans. Inf. Forensics Security, vol. 20, pp. 6058–6073, 2025
work page 2025
-
[3]
Y . Zhang, Z. Zhou, Y . Cao, G. Li, and X. Li, “Mamc—optimal on accuracy and efficiency for automatic modulation classification with extended signal length,”IEEE Commun. Lett., vol. 28, no. 12, pp. 2864– 2868, Dec 2024
work page 2024
-
[4]
J. Zhang, Y . Liu, G. Ding, B. Tang, and Y . Chen, “Adaptive decomposi- tion and extraction network of individual fingerprint features for specific emitter identification,”IEEE Trans. Inf. Forensics Security, vol. 19, pp. 8515–8528, 2024
work page 2024
-
[5]
A new method for specific emitter identification with results on real radar measurements,
G. Gok, Y . K. Alp, and O. Arikan, “A new method for specific emitter identification with results on real radar measurements,”IEEE Trans. Inf. Forensics Security, vol. 15, pp. 3335–3346, 2020
work page 2020
-
[7]
C. Liuet al., “Overcoming data limitations: A few-shot specific emitter identification method using self-supervised learning and adversarial augmentation,”IEEE Trans. Inf. Forensics Security, vol. 19, pp. 500– 513, 2024
work page 2024
-
[8]
Few-shot specific emitter identification via deep metric ensemble learning,
Y . Wang, G. Gui, Y . Lin, H.-C. Wu, C. Yuen, and F. Adachi, “Few-shot specific emitter identification via deep metric ensemble learning,”IEEE Internet Things J., vol. 9, no. 24, pp. 24 980–24 994, Dec. 2022
work page 2022
-
[9]
Understand- ing deep learning requires rethinking generalization,
C. Zhang, S. Bengio, M. Hardt, B. Recht, and O. Vinyals, “Understand- ing deep learning requires rethinking generalization,” inProc. Int. Conf. Learn. Represent., 2017
work page 2017
-
[10]
An efficient two-stage machine unlearning framework for poisoned specific emitter identification,
X. Li, C. Liu, S. Sun, Z. Zhou, Y . Zhang, and G. Li, “An efficient two-stage machine unlearning framework for poisoned specific emitter identification,”IEEE Internet Things J., vol. 12, no. 17, pp. 36 662– 36 673, Sep. 2025
work page 2025
-
[11]
W. Liet al., “Slpa: Single-line pixel attack on specific emitter identi- fication using time-frequency spectrogram,”IEEE Trans. Veh. Technol., vol. 73, no. 10, pp. 15 763–15 767, Oct. 2024
work page 2024
-
[12]
Robust specific emitter identification with sample selection and regularization under label noise,
M. Taoet al., “Robust specific emitter identification with sample selection and regularization under label noise,”IEEE Internet Things J., vol. 11, no. 24, pp. 40 702–40 713, Dec. 2024
work page 2024
-
[13]
L. Qiwanget al., “Robust specific emitter identification under label noise and quantity limitations in intelligent transportation systems,”IEEE Trans. Intell. Transp. Syst., vol. 26, no. 12, pp. 21 622–21 634, Dec. 2025
work page 2025
-
[14]
Co-teaching: Robust training of deep neural networks with extremely noisy labels,
B. Hanet al., “Co-teaching: Robust training of deep neural networks with extremely noisy labels,” inProc. Int. Conf. Neural Inf. Process. Syst., 2018, pp. 8536–8546
work page 2018
-
[15]
Unsupervised label noise modeling and loss correction,
E. Arazo, D. Ortego, P. Albert, N. O’Connor, and K. McGuinness, “Unsupervised label noise modeling and loss correction,” inProc. Int. Conf. Mach. Learn., 2019, pp. 312–321
work page 2019
-
[16]
A closer look at memorization in deep networks,
D. Arpitet al., “A closer look at memorization in deep networks,” in Proc. Int. Conf. Mach. Learn., 2017, pp. 233–242
work page 2017
-
[17]
Momentum contrast for unsupervised visual representation learning,
K. He, H. Fan, Y . Wu, S. Xie, and R. Girshick, “Momentum contrast for unsupervised visual representation learning,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit., 2020, pp. 9726–9735
work page 2020
-
[18]
A simple framework for contrastive learning of visual representations,
T. Chen, S. Kornblith, M. Norouzi, and G. Hinton, “A simple framework for contrastive learning of visual representations,” inProc. Int. Conf. Mach. Learn., 2020, pp. 1597–1607
work page 2020
-
[19]
Selective-supervised contrastive learning with noisy labels,
S. Li, X. Xia, S. Ge, and T. Liu, “Selective-supervised contrastive learning with noisy labels,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit., 2022, pp. 316–325
work page 2022
-
[20]
D. Bahri, H. Jiang, and M. Gupta, “Deep k-nn for noisy labels,” inProc. 37th Int. Conf. Mach. Learn., vol. 1, Jul. 2020, pp. 540–550
work page 2020
-
[21]
Prototypical networks for few-shot learning,
J. Snell, K. Swersky, and R. Zemel, “Prototypical networks for few-shot learning,”Proc. Adv. Neural Inf. Process. Syst., vol. 30, 2017
work page 2017
-
[22]
Convolutional radio modula- tion recognition networks,
T. J. O’Shea, J. Corgan, and T. C. Clancy, “Convolutional radio modula- tion recognition networks,” inProc. Int. Conf. Eng. Appl. Neural Netw., 2016, pp. 213–226
work page 2016
-
[23]
Deep learning for rf device fingerprinting in cognitive communication networks,
K. Merchant, S. Revay, G. Stantchev, and B. Nousain, “Deep learning for rf device fingerprinting in cognitive communication networks,”IEEE J. Sel. Topics Signal Process., vol. 12, no. 1, pp. 160–167, Feb. 2018
work page 2018
-
[24]
Oracle: Optimized radio classification through convo- lutional neural networks,
K. Sankhe, M. Belgiovine, F. Zhou, S. Riyaz, S. Ioannidis, and K. Chowdhury, “Oracle: Optimized radio classification through convo- lutional neural networks,” inProc. IEEE Conf. Comput. Commun., Apr. 2019, pp. 370–378
work page 2019
-
[25]
Exposing the fingerprint: Dissecting the impact of the wireless channel on radio fingerprinting,
A. Al-Shawabkaet al., “Exposing the fingerprint: Dissecting the impact of the wireless channel on radio fingerprinting,” inProc. IEEE INFO- COM Conf. Comput. Commun., May. 2020, pp. 646–655
work page 2020
-
[26]
Towards scalable and channel-robust radio frequency fingerprint identification for lora,
G. Shen, J. Zhang, A. Marshall, and J. R. Cavallaro, “Towards scalable and channel-robust radio frequency fingerprint identification for lora,” IEEE Trans. Inf. Forensics Security, vol. 17, pp. 774–787, 2022
work page 2022
-
[27]
Y . Wang, G. Gui, H. Gacanin, T. Ohtsuki, O. A. Dobre, and H. V . Poor, “An efficient specific emitter identification method based on complex- valued neural networks and network compression,”IEEE J. Sel. Areas Commun., vol. 39, no. 8, pp. 2305–2317, Aug. 2021
work page 2021
-
[28]
E. Malach and S. Shalev-Shwartz, “Decoupling” when to update” from” how to update”,”Proc. NeurIPS, pp. 960–970, 2017
work page 2017
-
[29]
Mentornet: Learning data-driven curriculum for very deep neural networks on corrupted labels,
L. Jiang, Z. Zhou, T. Leung, L.-J. Li, and L. Fei-Fei, “Mentornet: Learning data-driven curriculum for very deep neural networks on corrupted labels,” inProc. Annu. Int. Conf. Mach. Learn., 2018, pp. 2304–2313
work page 2018
-
[30]
Robust loss functions under label noise for deep neural networks,
A. Ghosh, H. Kumar, and P. S. Sastry, “Robust loss functions under label noise for deep neural networks,” inProc. AAAI, 2017, pp. 1919–1925
work page 2017
-
[31]
Generalized cross entropy loss for training deep neural networks with noisy labels,
Z. Zhang and M. Sabuncu, “Generalized cross entropy loss for training deep neural networks with noisy labels,”Proc. Adv. Neural Inf. Process. Syst., pp. 8792–8802, 2018
work page 2018
-
[32]
Rethinking the inception architecture for computer vision,
C. Szegedy, V . Vanhoucke, S. Ioffe, J. Shlens, and Z. Wojna, “Rethinking the inception architecture for computer vision,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun 2016, pp. 2818–2826
work page 2016
-
[33]
mixup: Beyond empirical risk minimization,
H. Zhang, M. Cisse, Y . N. Dauphin, and D. Lopez-Paz, “mixup: Beyond empirical risk minimization,” inProc. Int. Conf. Learn. Represent., 2017, pp. 1–13
work page 2017
-
[34]
Dividemix: Learning with noisy labels as semi-supervised learning
J. Li, R. Socher, and S. C. Hoi, “Dividemix: Learning with noisy labels as semi-supervised learning,”arXiv preprint arXiv:2002.07394, 2020
-
[35]
Confident learning: Estimating uncertainty in dataset labels,
C. Northcutt, L. Jiang, and I. Chuang, “Confident learning: Estimating uncertainty in dataset labels,”J. Artif. Intell. Res., vol. 70, pp. 1373– 1411, 2021
work page 2021
-
[36]
Uni- con: Combating label noise through uniform selection and contrastive learning,
N. Karim, M. N. Rizve, N. Rahnavard, A. Mian, and M. Shah, “Uni- con: Combating label noise through uniform selection and contrastive learning,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit., 2022, pp. 9666–9676
work page 2022
-
[37]
Representation Learning with Contrastive Predictive Coding
A. v. d. Oord, Y . Li, and O. Vinyals, “Representation learning with contrastive predictive coding,”arXiv preprint arXiv:1807.03748, 2018
work page internal anchor Pith review arXiv 2018
-
[38]
Trust in 5g open rans through machine learning: Rf fingerprinting on the powder pawr platform,
G. Reus-Muns, D. Jaisinghani, K. Sankhe, and K. R. Chowdhury, “Trust in 5g open rans through machine learning: Rf fingerprinting on the powder pawr platform,” inProc. IEEE Glob. Commun. Conf., 2020, pp. 1–6. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 14 VII. BIOGRAPHYSECTION If you have an EPS/PDF photo (graphicx package needed), extra brac...
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.