Recognition: unknown
TokenStack: A Heterogeneous HBM-PIM Architecture and Runtime for Efficient LLM Inference
Pith reviewed 2026-05-08 04:39 UTC · model grok-4.3
The pith
TokenStack's heterogeneous HBM-PIM stacks separate dense storage from compute layers to accelerate only the hot KV blocks in LLM decode.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TokenStack proposes a vertically heterogeneous HBM-PIM architecture that splits each stack into dense capacity layers and PIM-enabled compute layers, using the logic base die as a stack-local controller for cross-layer DMA, layered address translation, attention-side gather/broadcast, and inline quantization. On top of this hardware, topology-aware KV placement, workload-aware eviction, and bounded replication keep hot KV blocks near PIM compute while moving colder state to dense layers, all without host-side intervention.
What carries the argument
Vertically heterogeneous HBM-PIM stack with dense capacity layers and PIM-enabled compute layers, managed by a logic base die controller that performs local data movement and coordination.
If this is right
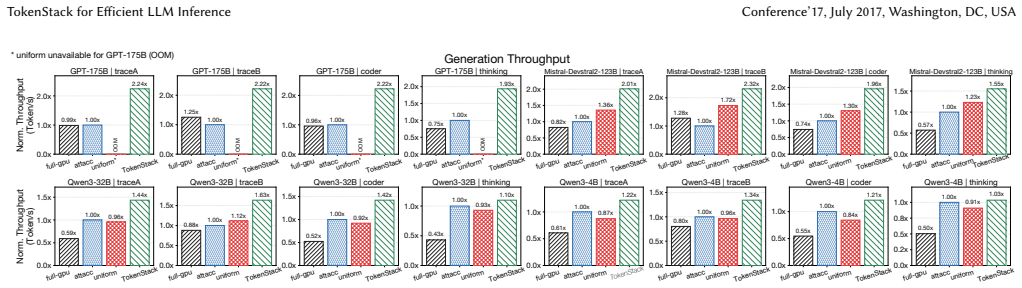
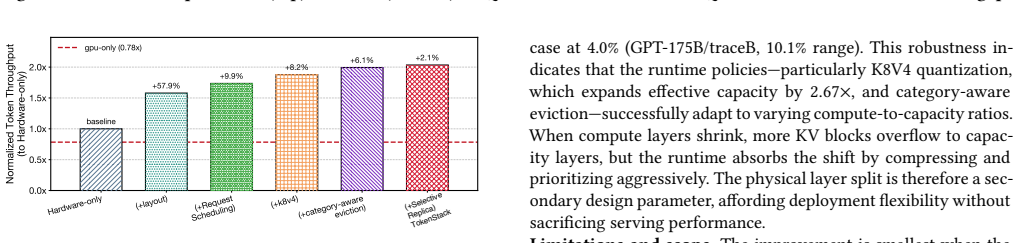
- Geometric-mean token throughput rises 1.62x over AttAcc across production traces of four models.
- SLO-compliant serving capacity increases by 1.70x while per-token energy falls 30-47%.
- HBM bandwidth remains available for GPU-visible dense layers instead of being consumed by uniform PIM logic.
- Cross-layer data movement occurs entirely inside the stack, eliminating host PCIe and scheduling overhead for KV migration.
Where Pith is reading between the lines
- The same dense-versus-PIM layering could be applied to other memory-capacity-bound stages such as embedding tables or large activation buffers.
- If hot-block fractions prove more variable across models than the evaluated traces suggest, dynamic layer allocation at boot time would become necessary.
- Local base-die control opens the possibility of tighter co-scheduling between PIM attention and GPU matrix units on the same package.
Load-bearing premise
Only a small fraction of KV blocks are hot enough to benefit from PIM compute, and the rest can be moved to dense layers with low overhead using workload-aware eviction and bounded replication without host intervention.
What would settle it
A workload in which most KV blocks show similarly high access frequencies would cause migration costs to dominate, erasing the reported throughput and energy gains.
Figures










read the original abstract
Large language model (LLM) serving is now limited by the key-value (KV) cache. During decode, each new token rereads prior KV state, so attention becomes a bandwidth- and capacity-heavy memory task. HBM-PIM helps by moving attention closer to memory, but current stack organizations still waste resources. In practice, only hot KV blocks benefit from near-memory compute. Weights, activations, and cold KV mainly need dense storage and GPU-visible bandwidth. A uniform HBM-PIM stack makes all layers pay for PIM logic, while a dedicated-PIM design such as AttAcc recovers capacity but shrinks the HBM bandwidth left for GPU-side work. We propose TokenStack, a vertically heterogeneous HBM-PIM architecture for KV-centric LLM serving that leverages HBM4's logic-die substrate. TokenStack separates each stack into dense capacity layers and PIM-enabled compute layers, then uses the logic base die as a stack-local control point that manages cross-layer movement without host-side overhead. The base-die controller handles cross-layer DMA, layered address translation, attention-side gather/broadcast coordination, and inline quantization during migration. On top of this hardware, TokenStack uses topology-aware KV placement, workload-aware eviction, and bounded replication to keep hot KV near PIM compute while moving colder state to dense layers. Using production-derived traces across four models, completed multi-QPS runs show that TokenStack increases geometric-mean token throughput by 1.62x and SLO-compliant serving capacity by 1.70x over AttAcc, and reduces per-token energy by 30-47%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes TokenStack, a vertically heterogeneous HBM-PIM architecture for KV-cache-centric LLM inference. It partitions each HBM stack into dense capacity layers and PIM-enabled compute layers, using the logic base die as a local controller for cross-layer DMA, address translation, gather/broadcast, and inline quantization. A runtime layer applies topology-aware KV placement, workload-aware eviction, and bounded replication to keep hot KV blocks near PIM compute. Trace-driven multi-QPS simulations across four production-derived workloads report 1.62× geometric-mean token throughput, 1.70× SLO-compliant serving capacity, and 30–47% per-token energy reduction relative to AttAcc.
Significance. If the reported gains are substantiated, the work offers a practical path to improve memory hierarchy efficiency for decode-bound LLM serving without the capacity or bandwidth penalties of uniform PIM or dedicated-PIM designs. The use of production traces and multi-QPS simulation methodology is a strength that grounds the claims in realistic serving conditions.
major comments (1)
- Evaluation section: The 1.62× throughput and 1.70× capacity claims rest on the assumption that only a small fraction of KV blocks are sufficiently hot to benefit from PIM compute and that workload-aware eviction plus bounded replication can maintain high PIM hit rates with negligible cross-layer traffic. No quantitative results are supplied on observed hot-block fractions, migration frequency per token, PIM hit rates, or base-die controller overhead under the multi-QPS loads. These metrics are load-bearing for the central performance argument; without them the advantage over AttAcc cannot be fully assessed.
minor comments (1)
- Abstract: The four models used in the evaluation are not named; adding their identities (and a brief characterization of their KV-cache behavior) would improve reproducibility and context.
Simulated Author's Rebuttal
We thank the referee for their constructive review and for recognizing the strengths of our production-trace-driven evaluation methodology. We address the major comment below and will revise the manuscript accordingly to strengthen the evaluation section.
read point-by-point responses
-
Referee: Evaluation section: The 1.62× throughput and 1.70× capacity claims rest on the assumption that only a small fraction of KV blocks are sufficiently hot to benefit from PIM compute and that workload-aware eviction plus bounded replication can maintain high PIM hit rates with negligible cross-layer traffic. No quantitative results are supplied on observed hot-block fractions, migration frequency per token, PIM hit rates, or base-die controller overhead under the multi-QPS loads. These metrics are load-bearing for the central performance argument; without them the advantage over AttAcc cannot be fully assessed.
Authors: We agree that these supporting metrics are important for fully validating the central claims. While the current manuscript emphasizes end-to-end results, we will revise the evaluation section to include a new subsection with the requested quantitative data extracted from the same multi-QPS simulations. Specifically, we will report observed hot-block fractions, migration frequency per token, PIM hit rates, and base-die controller overhead, confirming that cross-layer traffic remains negligible and that the workload-aware policies maintain high PIM utilization. This addition will directly address the concern and allow readers to assess the advantage over AttAcc. revision: yes
Circularity Check
No circularity: performance claims are empirical simulation outputs on external traces
full rationale
The paper proposes a heterogeneous HBM-PIM architecture and runtime, then reports throughput, capacity, and energy gains as direct outputs of multi-QPS simulation runs driven by production-derived traces across four models. These metrics are not derived from internal equations, fitted parameters renamed as predictions, or self-citation chains; they are measured results on independent external workloads. No load-bearing step in the provided description reduces by construction to its own inputs, self-definitions, or ansatzes smuggled via prior work. The evaluation remains falsifiable against the cited traces.
Axiom & Free-Parameter Ledger
axioms (2)
- ad hoc to paper Only hot KV blocks benefit from near-memory compute while weights, activations, and cold KV mainly require dense storage and GPU-visible bandwidth
- domain assumption HBM4 logic-die substrate can serve as a stack-local control point for cross-layer DMA and attention coordination without host overhead
invented entities (2)
-
Vertically heterogeneous HBM-PIM stack with dense capacity layers and PIM-enabled compute layers
no independent evidence
-
Logic base die controller
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Junwhan Ahn, Sungpack Hong, Sungjoo Yoo, Onur Mutlu, and Kiyoung Choi
-
[2]
In2015 ACM/IEEE 42nd Annual International Symposium on Computer Ar- chitecture (ISCA)
A scalable processing-in-memory accelerator for parallel graph process- ing. In2015 ACM/IEEE 42nd Annual International Symposium on Computer Ar- chitecture (ISCA). 105–117. https://doi.org/10.1145/2749469.2750386
-
[3]
Kahng, Naveen Muralimanohar, Ali Shafiee, and Vaishnav Srinivas
Rajeev Balasubramonian, Andrew B. Kahng, Naveen Muralimanohar, Ali Shafiee, and Vaishnav Srinivas. 2017. CACTI 7: New Tools for Interconnect Ex- ploration in Innovative Off-Chip Memories.ACM Trans. Archit. Code Optim.14, 2, Article 14 (June 2017), 25 pages. https://doi.org/10.1145/3085572
-
[4]
Guohao Dai, Tianhao Huang, Yuze Chi, Jishen Zhao, Guangyu Sun, Yongpan Liu, Yu Wang, Yuan Xie, and Huazhong Yang. 2019. GraphH: A Processing-in- Memory Architecture for Large-Scale Graph Processing.IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems38, 4 (2019), 640–653. https://doi.org/10.1109/TCAD.2018.2821565
- [5]
-
[6]
Alexandar Devic, Siddhartha Balakrishna Rai, Anand Sivasubramaniam, Ameen Akel, Sean Eilert, and Justin Eno. 2022. To PIM or not for emerging general purpose processing in DDR memory systems. InProceedings of the 49th Annual International Symposium on Computer Architecture(New York, New York)(ISCA ’22). Association for Computing Machinery, New York, NY, U...
-
[7]
Zehao Fan, Yunzhen Liu, Garrett Gagnon, Zhenyu Liu, Yayue Hou, Hadjer Benmeziane, Kaoutar El Maghraoui, and Liu Liu. 2026. STARC: Selective To- ken Access with Remapping and Clustering for Efficient LLM Decoding on PIM Systems. InProceedings of the 31st ACM International Conference on Archi- tectural Support for Programming Languages and Operating Systems...
-
[8]
Bin Gao, Zhuomin He, Puru Sharma, Qingxuan Kang, Djordje Jevdjic, Junbo Deng, Xingkun Yang, Zhou Yu, and Pengfei Zuo. 2024. Cost-Efficient Large Language Model Serving for Multi-turn Conversations with CachedAttention. In2024 USENIX Annual Technical Conference (USENIX ATC 24). USENIX Asso- ciation, Santa Clara, CA, 111–126. https://www.usenix.org/conferen...
2024
-
[9]
Christina Giannoula, Ivan Fernandez, Juan Gómez Luna, Nectarios Koziris, Geor- gios Goumas, and Onur Mutlu. 2022. SparseP: Towards Efficient Sparse Ma- trix Vector Multiplication on Real Processing-In-Memory Architectures.Proc. ACM Meas. Anal. Comput. Syst.6, 1, Article 21 (Feb. 2022), 49 pages. https: //doi.org/10.1145/3508041
-
[10]
In Gim, Guojun Chen, Seung-seob Lee, Nikhil Sarda, Anurag Khan- delwal, and Lin Zhong. 2024. Prompt Cache: Modular Attention Reuse for Low-Latency Inference. InProceedings of Machine Learning and Systems, P. Gibbons, G. Pekhimenko, and C. De Sa (Eds.), Vol. 6. 325–338. https://proceedings.mlsys.org/paper_files/paper/2024/file/ a66caa1703fe34705a4368c3014c...
2024
-
[11]
2025.PIM Is All You Need: A CXL-Enabled GPU-Free System for Large Language Model Inference
Yufeng Gu, Alireza Khadem, Sumanth Umesh, Ning Liang, Xavier Servot, Onur Mutlu, Ravi Iyer, and Reetuparna Das. 2025.PIM Is All You Need: A CXL-Enabled GPU-Free System for Large Language Model Inference. Association for Comput- ing Machinery, New York, NY, USA, 862–881. https://doi.org/10.1145/3676641. 3716267
- [12]
-
[13]
Guseul Heo, Sangyeop Lee, Jaehong Cho, Hyunmin Choi, Sanghyeon Lee, Hyungkyu Ham, Gwangsun Kim, Divya Mahajan, and Jongse Park. 2024. Ne- uPIMs: NPU-PIM Heterogeneous Acceleration for Batched LLM Inferencing. InProceedings of the 29th ACM International Conference on Architectural Sup- port for Programming Languages and Operating Systems, Volume 3(La Jolla...
-
[14]
Mahoney, Yakun Sophia Shao, Kurt Keutzer, and Amir Gholami
Coleman Hooper, Sehoon Kim, Hiva Mohammadzadeh, Michael W. Mahoney, Yakun Sophia Shao, Kurt Keutzer, and Amir Gholami. 2024. KVQuant: Towards 10 Million Context Length LLM Inference with KV Cache Quantization. InAd- vances in Neural Information Processing Systems (NeurIPS)
2024
- [15]
-
[16]
Mohsen Imani, Saransh Gupta, Yeseong Kim, and Tajana Rosing. 2019. FloatPIM: In-Memory Acceleration of Deep Neural Network Training with High Precision. In2019 ACM/IEEE 46th Annual International Symposium on Computer Architec- ture (ISCA). 802–815
2019
-
[17]
Je-Woo Jang, Junyong Oh, Youngbae Kong, Jae-Youn Hong, Sung-Hyuk Cho, Jeongyeol Lee, Hoeseok Yang, and Joon-Sung Yang. 2025. Accelerating Re- trieval Augmented Language Model via PIM and PNM Integration. InProceed- ings of the 58th IEEE/ACM International Symposium on Microarchitecture (MI- CRO ’25). Association for Computing Machinery, New York, NY, USA, ...
-
[18]
JEDEC. 2025. High Bandwidth Memory (HBM4) DRAM. https://www.jedec. org/standards-documents/docs/jesd270-4a
2025
-
[19]
Liu Ke, Udit Gupta, Benjamin Youngjae Cho, David Brooks, Vikas Chandra, Utku Diril, Amin Firoozshahian, Kim Hazelwood, Bill Jia, Hsien-Hsin S. Lee, Meng Li, Bert Maher, Dheevatsa Mudigere, Maxim Naumov, Martin Schatz, Mikhail Smelyanskiy, Xiaodong Wang, Brandon Reagen, Carole-Jean Wu, Mark Hemp- stead, and Xuan Zhang. 2020. RecNMP: Accelerating Personaliz...
-
[20]
Liu Ke, Xuan Zhang, Jinin So, Jong-Geon Lee, Shin-Haeng Kang, Sukhan Lee, Songyi Han, YeonGon Cho, Jin Hyun Kim, Yongsuk Kwon, KyungSoo Kim, Jin Jung, Ilkwon Yun, Sung Joo Park, Hyunsun Park, Joonho Song, Jeonghyeon Cho, Kyomin Sohn, Nam Sung Kim, and Hsien-Hsin S. Lee. 2022. Near-Memory Pro- cessing in Action: Accelerating Personalized Recommendation Wit...
-
[21]
Duckhwan Kim, Jaeha Kung, Sek Chai, Sudhakar Yalamanchili, and Saibal Mukhopadhyay. 2016. Neurocube: A Programmable Digital Neuromorphic Ar- chitecture with High-Density 3D Memory. In2016 ACM/IEEE 43rd Annual Inter- national Symposium on Computer Architecture (ISCA). 380–392. https://doi.org/ 10.1109/ISCA.2016.41
-
[22]
Jin Hyun Kim, Yuhwan Ro, Jinin So, Sukhan Lee, Shin-haeng Kang, YeonGon Cho, Hyeonsu Kim, Byeongho Kim, Kyungsoo Kim, Sangsoo Park, Jin-Seong Kim, Sanghoon Cha, Won-Jo Lee, Jin Jung, Jong-Geon Lee, Jieun Lee, JoonHo Song, Seungwon Lee, Jeonghyeon Cho, Jaehoon Yu, and Kyomin Sohn. 2023. Samsung PIM/PNM for Transfmer Based AI : Energy Efficiency on PIM/PNM ...
- [23]
-
[24]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. 2023. Efficient Mem- ory Management for Large Language Model Serving with PagedAttention. In Proceedings of the 29th Symposium on Operating Systems Principles(Koblenz, Ger- many)(SOSP ’23). Association for Computing Machinery, New Yo...
-
[25]
Youngeun Kwon, Yunjae Lee, and Minsoo Rhu. 2019. TensorDIMM: A Practi- cal Near-Memory Processing Architecture for Embeddings and Tensor Oper- ations in Deep Learning. InProceedings of the 52nd Annual IEEE/ACM Inter- national Symposium on Microarchitecture(Columbus, OH, USA)(MICRO ’52). Association for Computing Machinery, New York, NY, USA, 740–753. http...
-
[26]
Yongkee Kwon, Kornijcuk Vladimir, Nahsung Kim, Woojae Shin, Jongsoon Won, Minkyu Lee, Hyunha Joo, Haerang Choi, Guhyun Kim, Byeongju An, Jeongbin Kim, Jaewook Lee, Ilkon Kim, Jaehan Park, Chanwook Park, Yosub Song, Byeongsu Yang, Hyungdeok Lee, Seho Kim, Daehan Kwon, Seongju Lee, Kyuyoung Kim, Sanghoon Oh, Joonhong Park, Gimoon Hong, Dongyoon Ka, Kyudong ...
-
[27]
Young-Cheon Kwon, Suk Han Lee, Jaehoon Lee, Sang-Hyuk Kwon, Je Min Ryu, Jong-Pil Son, O Seongil, Hak-Soo Yu, Haesuk Lee, Soo Young Kim, Youngmin Cho, Jin Guk Kim, Jongyoon Choi, Hyun-Sung Shin, Jin Kim, BengSeng Phuah, HyoungMin Kim, Myeong Jun Song, Ahn Choi, Daeho Kim, SooYoung Kim, Eun- Bong Kim, David Wang, Shinhaeng Kang, Yuhwan Ro, Seungwoo Seo, Joo...
-
[28]
S. Lee et al. 2022. A 192-Gb 12-High 896-GB/s HBM3 DRAM with a TSV Auto- Calibration Scheme and Machine-Learning-Based Layout Optimization. InProc. IEEE International Solid-State Circuits Conference (ISSCC). 176–178. https://doi. org/10.1109/ISSCC42614.2022.9731562
-
[29]
Cong Li, Zhe Zhou, Yang Wang, Fan Yang, Ting Cao, Mao Yang, Yun Liang, and Guangyu Sun. 2024. PIM-DL: Expanding the Applicability of Commod- ity DRAM-PIMs for Deep Learning via Algorithm-System Co-Optimization. In Proceedings of the 29th ACM International Conference on Architectural Support 13 Conference’17, July 2017, Washington, DC, USA Zhuoran Li, Zhuo...
-
[30]
Cong Li, Zhe Zhou, Size Zheng, Jiaxi Zhang, Yun Liang, and Guangyu Sun
-
[31]
SpecPIM: Accelerating Speculative Inference on PIM-Enabled System via Architecture-Dataflow Co-Exploration. InProceedings of the 29th ACM In- ternational Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3(La Jolla, CA, USA)(ASPLOS ’24). Association for Computing Machinery, New York, NY, USA, 950–965. https://doi....
-
[32]
Haifeng Liu, Long Zheng, Yu Huang, Chaoqiang Liu, Xiangyu Ye, Jingrui Yuan, Xiaofei Liao, Hai Jin, and Jingling Xue. 2023. Accelerating Personalized Recom- mendation with Cross-level Near-Memory Processing. InProceedings of the 50th Annual International Symposium on Computer Architecture(Orlando, FL, USA) (ISCA ’23). Association for Computing Machinery, N...
-
[33]
Liu Liu, Jilan Lin, Zheng Qu, Yufei Ding, and Yuan Xie. 2021. ENMC: Ex- treme Near-Memory Classification via Approximate Screening. InMICRO-54: 54th Annual IEEE/ACM International Symposium on Microarchitecture(Virtual Event, Greece)(MICRO ’21). Association for Computing Machinery, New York, NY, USA, 1309–1322. https://doi.org/10.1145/3466752.3480090
- [34]
- [35]
-
[36]
Zirui Liu, Jiayi Yuan, Hongye Jin, Shaochen Zhong, Zhaozhuo Xu, Vladimir Braverman, Beidi Chen, and Xia Hu. 2024. KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache. InProceedings of the 41st International Confer- ence on Machine Learning (ICML)
2024
-
[37]
Nisa Bostancı, Ataberk Olgun, A
Haocong Luo, Yahya Can Tuğrul, F. Nisa Bostancı, Ataberk Olgun, A. Giray Yağlıkçı, and Onur Mutlu. 2024. Ramulator 2.0: A Modern, Modular, and Exten- sible DRAM Simulator.IEEE Computer Architecture Letters23, 1 (2024), 112–116. https://doi.org/10.1109/LCA.2023.3333759
-
[38]
Jaehyun Park, Jaewan Choi, Kwanhee Kyung, Michael Jaemin Kim, Yongsuk Kwon, Nam Sung Kim, and Jung Ho Ahn. 2024. AttAcc! Unleashing the Power of PIM for Batched Transformer-based Generative Model Inference. InProceed- ings of the 29th ACM International Conference on Architectural Support for Pro- gramming Languages and Operating Systems, Volume 2(La Jolla...
-
[39]
Ruoyu Qin, Zheming Li, Weiran He, Jialei Cui, Feng Ren, Mingxing Zhang, Yong- wei Wu, Weimin Zheng, and Xinran Xu. 2025. MOONCAKE: trading more stor- age for less computation — a KVCache-centric architecture for serving LLM chat- bot. InProceedings of the 23rd USENIX Conference on File and Storage Technolo- gies(Santa Clara, CA, USA)(FAST ’25). USENIX Ass...
2025
-
[40]
Minseok Seo, Xuan Truong Nguyen, Seok Joong Hwang, Yongkee Kwon, Guhyun Kim, Chanwook Park, Ilkon Kim, Jaehan Park, Jeongbin Kim, Woojae Shin, Jongsoon Won, Haerang Choi, Kyuyoung Kim, Daehan Kwon, Chunseok Jeong, Sangheon Lee, Yongseok Choi, Wooseok Byun, Seungcheol Baek, Hyuk- Jae Lee, and John Kim. 2024. IANUS: Integrated Accelerator based on NPU-PIM U...
-
[41]
Linghao Song, Youwei Zhuo, Xuehai Qian, Hai Li, and Yiran Chen. 2018. GraphR: Accelerating Graph Processing Using ReRAM. In2018 IEEE International Sym- posium on High Performance Computer Architecture (HPCA). 531–543. https: //doi.org/10.1109/HPCA.2018.00052
-
[42]
Boyu Tian, Qihang Chen, and Mingyu Gao. 2023. ABNDP: Co-optimizing Data Access and Load Balance in Near-Data Processing. InProceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3(Vancouver, BC, Canada)(ASP- LOS 2023). Association for Computing Machinery, New York, NY, USA, 3–1...
-
[43]
Boyu Tian, Yiwei Li, Li Jiang, Shuangyu Cai, and Mingyu Gao. 2024. NDPBridge: Enabling Cross-Bank Coordination in Near-DRAM-Bank Processing Architec- tures. In2024 ACM/IEEE 51st Annual International Symposium on Computer Ar- chitecture (ISCA). 628–643. https://doi.org/10.1109/ISCA59077.2024.00052
-
[44]
Jiahao Wang, Jinbo Han, Xingda Wei, Sijie Shen, Dingyan Zhang, Chenguang Fang, Rong Chen, Wenyuan Yu, and Haibo Chen. 2025. KVCache Cache in the Wild: Characterizing and Optimizing KVCache Cache at a Large Cloud Provider. InProceedings of the 2025 USENIX Annual Technical Conference. USENIX Associ- ation, 465–480. https://www.usenix.org/conference/atc25/pr...
2025
-
[45]
Sungmin Yun, Kwanhee Kyung, Juhwan Cho, Jaewan Choi, Jongmin Kim, Byeongho Kim, Sukhan Lee, Kyomin Sohn, and Jung Ho Ahn. 2024. Duplex: A Device for Large Language Models with Mixture of Experts, Grouped Query Attention, and Continuous Batching. arXiv:2409.01141 [cs.AR] https://arxiv. org/abs/2409.01141
-
[46]
Mingxing Zhang, Youwei Zhuo, Chao Wang, Mingyu Gao, Yongwei Wu, Kang Chen, Christos Kozyrakis, and Xuehai Qian. 2018. GraphP: Reducing Com- munication for PIM-Based Graph Processing with Efficient Data Partition. In 2018 IEEE International Symposium on High Performance Computer Architecture (HPCA). 544–557. https://doi.org/10.1109/HPCA.2018.00053
-
[47]
Lui, and Haibo Chen
Yanqi Zhang, Yuwei Hu, Runyuan Zhao, John C.S. Lui, and Haibo Chen. 2025. DiffKV: Differentiated Memory Management for Large Language Models with Parallel KV Compaction. InProceedings of the 19th USENIX Symposium on Oper- ating Systems Design and Implementation (OSDI). USENIX Association
2025
-
[48]
Minxuan Zhou, Weihong Xu, Jaeyoung Kang, and Tajana Rosing. 2022. Tran- sPIM: A Memory-based Acceleration via Software-Hardware Co-Design for Transformer. In2022 IEEE International Symposium on High-Performance Com- puter Architecture (HPCA). 1071–1085. https://doi.org/10.1109/HPCA53966.2022. 00082
- [49]
-
[50]
Youwei Zhuo, Jingji Chen, Gengyu Rao, Qinyi Luo, Yanzhi Wang, Hailong Yang, Depei Qian, and Xuehai Qian. 2021. Distributed Graph Processing System and Processing-in-memory Architecture with Precise Loop-carried Dependency Guarantee.ACM Trans. Comput. Syst.37, 1–4, Article 5 (July 2021), 37 pages. https://doi.org/10.1145/3453681
-
[51]
Youwei Zhuo, Chao Wang, Mingxing Zhang, Rui Wang, Dimin Niu, Yanzhi Wang, and Xuehai Qian. 2019. GraphQ: Scalable PIM-Based Graph Processing. In Proceedings of the 52nd Annual IEEE/ACM International Symposium on Microar- chitecture(Columbus, OH, USA)(MICRO ’52). Association for Computing Ma- chinery, New York, NY, USA, 712–725. https://doi.org/10.1145/335...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.