Learning a Contracting KKL-observer with Local Optimal Guarantees
Pith reviewed 2026-05-14 18:57 UTC · model grok-4.3
The pith
Neural networks learn KKL observers that stay globally contracting yet locally match the minimum-energy estimator.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A condition is derived on the latent dynamics such that the KKL observer locally mimics the behavior of a Minimum Energy Estimator. Deep learning is then used to approximate the KKL transformation and the latent dynamics with neural network architectures that structurally enforce the contraction property, yielding both global stability and local optimality.
What carries the argument
Contracting neural network architectures that structurally enforce contraction while approximating the KKL immersion map and latent dynamics.
If this is right
- The resulting observer guarantees global asymptotic stability through enforced contraction.
- Local error dynamics replicate those of the Mortensen observer near the true state.
- Estimation accuracy holds under combined state and measurement noise on standard nonlinear benchmarks.
- The method applies to nonlinear systems for which a qualifying latent dynamics can be found.
Where Pith is reading between the lines
- The same contraction-enforcing training could be tried with other immersion-based observer families beyond KKL.
- Lightweight versions of the networks might allow embedded real-time implementation on resource-limited hardware.
- Validation on physical plants with model mismatch would test whether the local optimality survives unmodeled effects.
Load-bearing premise
A suitable latent dynamics satisfying the local-optimality condition exists for the target system and neural networks with contraction-enforcing architectures can accurately approximate the required maps.
What would settle it
A simulation in which the learned observer's estimate deviates from the true minimum-energy estimate inside a neighborhood of the origin or fails to converge under added state and measurement noise.
Figures



read the original abstract
The Kazantzis-Kravaris-Luenberger (KKL) observer provides a general framework for nonlinear state estimation by immersing the system dynamics into a stable linear or nonlinear latent dynamics. However, the performance of KKL observers relies heavily on the specific choice of these latent dynamics, which is often heuristic. This paper proposes a methodology to learn a KKL observer that combines global stability guarantees with local optimality. We derive a condition on the latent dynamics such that the observer locally mimics the behavior of a Minimum Energy Estimator (Mortensen observer). We then employ Deep Learning to approximate the KKL transformation and the latent dynamics, using neural network architectures that structurally enforce the contraction property. The proposed strategy is validated through numerical simulations on nonlinear benchmarks, demonstrating a good performance in the presence of state and measurement noise.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a learning-based KKL observer design that derives a condition on the latent dynamics so the observer locally mimics the first-order behavior of the Mortensen minimum-energy estimator, then approximates both the immersion map and latent dynamics by neural networks whose architectures structurally enforce contraction, thereby combining global stability with local optimality; the approach is illustrated on nonlinear benchmark systems subject to state and measurement noise.
Significance. If the approximation errors can be shown not to destroy the local-optimality condition, the work would supply a principled, data-driven route to tune KKL observers for performance while retaining rigorous contraction-based stability, addressing a long-standing heuristic choice in nonlinear observer design.
major comments (2)
- [Section 3] The central construction (Section 3) derives a PDE-like condition that the latent vector field must satisfy for the KKL observer to reproduce the first-order behavior of the Mortensen estimator. Because both the immersion and the latent dynamics are replaced by neural networks, the learned pair satisfies the condition only up to approximation error; no a-priori bound on the residual is supplied, nor is it shown that the contraction architecture preserves the required Lie-derivative identities.
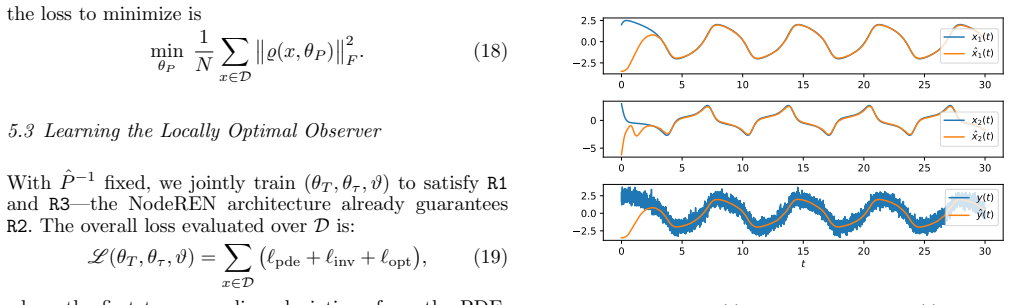
- [Section 5] Table 1 and the numerical examples (Section 5) report good empirical performance under noise, yet provide no quantitative metric (e.g., local linearization error or distance to the true Mortensen trajectory near the origin) that would confirm the local-optimality claim survives the neural-network approximation.
minor comments (2)
- [Abstract] The abstract states the main claims but contains no equations or quantitative performance figures; adding a brief statement of the derived condition and a representative error metric would improve readability.
- [Section 2] Notation for the contraction metric and the neural-network parameterizations is introduced without a consolidated table; a short notation summary would help readers track the structural enforcement arguments.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment below and will revise the manuscript accordingly to strengthen the theoretical and empirical support for the local-optimality claim.
read point-by-point responses
-
Referee: [Section 3] The central construction (Section 3) derives a PDE-like condition that the latent vector field must satisfy for the KKL observer to reproduce the first-order behavior of the Mortensen estimator. Because both the immersion and the latent dynamics are replaced by neural networks, the learned pair satisfies the condition only up to approximation error; no a-priori bound on the residual is supplied, nor is it shown that the contraction architecture preserves the required Lie-derivative identities.
Authors: We agree that the neural-network approximations satisfy the derived PDE-like condition only up to a nonzero residual and that the original manuscript did not supply an a-priori bound. The contraction architecture guarantees global stability of the observer error independently of approximation quality, because the latent vector field remains strictly contracting by construction. To address the local-optimality concern, the revised Section 3 will include an explicit residual bound derived from the universal approximation theorem on compact sets together with the Lipschitz constants of the system vector field and output map. We will also clarify that the architecture enforces contraction but does not automatically preserve the Lie-derivative identities; these identities are enforced by the training loss, and the same approximation argument yields a bound on the resulting Lie-derivative residual. revision: yes
-
Referee: [Section 5] Table 1 and the numerical examples (Section 5) report good empirical performance under noise, yet provide no quantitative metric (e.g., local linearization error or distance to the true Mortensen trajectory near the origin) that would confirm the local-optimality claim survives the neural-network approximation.
Authors: We concur that a direct quantitative metric is needed to confirm that local optimality survives the approximation. In the revised Section 5 we will add the local linearization error, defined as the Frobenius norm between the Jacobian of the learned observer at the origin and the corresponding Jacobian of the Mortensen estimator. For the benchmark systems we will also report the integrated state-estimation error over small neighborhoods of the origin, comparing the learned observer against a numerically integrated Mortensen trajectory. These new metrics will be included in an extended Table 1 and in additional plots. revision: yes
Circularity Check
Local optimality condition derived from external Mortensen estimator; contraction enforced structurally by NN architecture
full rationale
The central derivation produces a condition on latent dynamics so that the KKL observer locally reproduces first-order behavior of the independent Mortensen minimum-energy estimator. This condition is not defined in terms of the paper's own fitted quantities. Neural-network architectures are chosen to enforce contraction by construction rather than by fitting parameters that would render subsequent predictions tautological. No self-citation chain is load-bearing for the uniqueness or existence of the immersion, and the approximation error is treated as an empirical matter rather than claimed to vanish by definition. The result therefore remains self-contained against external benchmarks and receives only a minor self-citation penalty.
Axiom & Free-Parameter Ledger
free parameters (1)
- Neural network weights and biases
axioms (2)
- domain assumption The nonlinear system admits a KKL immersion into contracting latent dynamics.
- domain assumption The derived condition on latent dynamics ensures local equivalence to the Mortensen minimum-energy estimator.
Reference graph
Works this paper leans on
-
[1]
Andrieu, V. and Praly, L. (2006). On the existence of a Kazantzis–Kravaris/Luenberger observer.SIAM Journal on Control and Optimization, 45(2), 432–456. Beik Mohammadi, H., Hauberg, S., Arvanitidis, G.,
work page 2006
-
[2]
Figueroa, N., Neumann, G., and Rozo, L. (2024). Neural contractive dynamical systems. InICLR, 49097–49120
work page 2024
-
[3]
Bernard, P., Andrieu, V., and Astolfi, D. (2022). Observer design for continuous-time dynamical systems.Annual Reviews in Control, 53, 224–248
work page 2022
-
[4]
Brivadis, L., Andrieu, V., Bernard, P., and Serres, U. (2023). Further remarks on KKL observers.Systems & Control Letters, 172, 105429
work page 2023
-
[5]
Buisson-Fenet, M., Bahr, L., Morgenthaler, V., and Di Meglio, F. (2023). Towards gain tuning for numerical KKL observers.IFAC-PapersOnLine, 56(2), 4061–4067
work page 2023
-
[6]
Forgione, M. and Piga, D. (2021). dynonet: A neural network architecture for learning dynamical systems. International Journal of Adaptive Control and Signal Processing, 35(4), 612–626
work page 2021
-
[7]
Gu, A., Goel, K., and R´ e, C. (2022). Efficiently modeling long sequences with structured state spaces. InInterna- tional Conference on Learning Representations, 1–27
work page 2022
-
[8]
Martinelli, D., Galimberti, C.L., Manchester, I.R., Furi- eri, L., and Ferrari-Trecate, G. (2023). Unconstrained parametrization of dissipative and contracting neural or- dinary differential equations. In62nd IEEE Conference on Decision and Control, 3043–3048
work page 2023
-
[9]
Miao, K. and Gatsis, K. (2023). Learning robust state observers using neural ODEs. InLearning for Dynamics and Control Conference, 208–219. PMLR
work page 2023
-
[10]
Mortensen, R.E. (1968). Maximum-likelihood recursive nonlinear filtering.Journal of Optimization Theory and Applications, 2(6), 386–394
work page 1968
-
[11]
Niazi, M.U.B., Cao, J., Sun, X., Das, A., and Johansson, K.H. (2022). Learning-based design of Luenberger ob- servers for autonomous nonlinear systems. InAmerican Control Conference
work page 2022
-
[12]
Praly, L. (2024). On the existence of KKL observers with nonlinear contracting dynamics.IFAC-PapersOnLine, 58(21), 262–267
work page 2024
-
[13]
Peralez, J. and Nadri, M. (2021). Deep learning-based Luenberger observer design for discrete-time nonlinear systems. In60th IEEE Conference on Decision and Control, 4370–4375
work page 2021
-
[14]
Peralez, J. and Nadri, M. (2024). Deep model-free KKL observer: A switching approach. In6th Annual Learning for Dynamics & Control Conference, 929–940. PMLR
work page 2024
-
[15]
Ramos, L.d.C., Di Meglio, F., Morgenthaler, V., da Silva, L.F.F., and Bernard, P. (2020). Numerical design of Luenberger observers for nonlinear systems. In59th IEEE Conference on Decision and Control, 5435–5442
work page 2020
-
[16]
Revay, M., Wang, R., and Manchester, I.R. (2023). Re- current equilibrium networks: Flexible dynamic models with guaranteed stability and robustness.IEEE Trans. Autom. Control, 69(5), 2855–2870
work page 2023
-
[17]
Sanfelice, R.G. and Praly, L. (2015). Solution of a riccati equation for the design of an observer contracting a riemannian distance. In54th IEEE Conference on Decision and Control, 4996–5001. IEEE
work page 2015
-
[18]
Zakwan, M., Xu, L., and Ferrari-Trecate, G. (2022). Ro- bust classification using contractive Hamiltonian neural ODEs.IEEE Control Systems Letters, 7, 145–150. Appendix A. REVIEW OF THE LINEAR CASE It is instructive to instantiate the proposed framework for a linear system ˙x=Ax, y=Cx. Consistent with Section 4, letP≻0 be the steady-state information matr...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.