Decision-Level Fusion for Robust Wearable Affect Recognition
Pith reviewed 2026-06-30 19:38 UTC · model grok-4.3
The pith
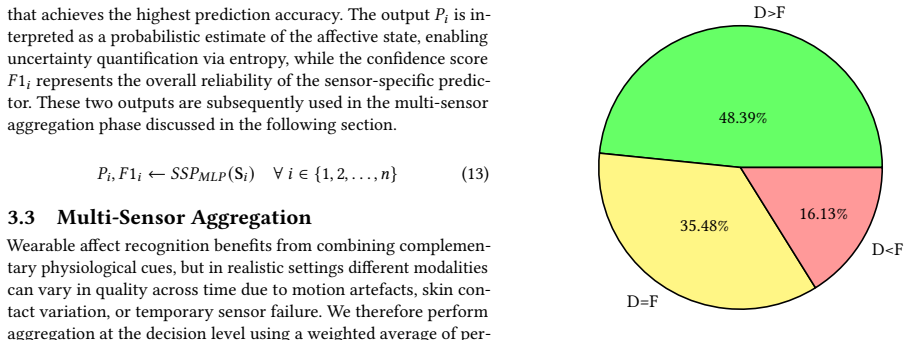
Decision-level aggregation weighted by predictive uncertainty outperforms feature-level fusion 48 percent of the time on WESAD.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
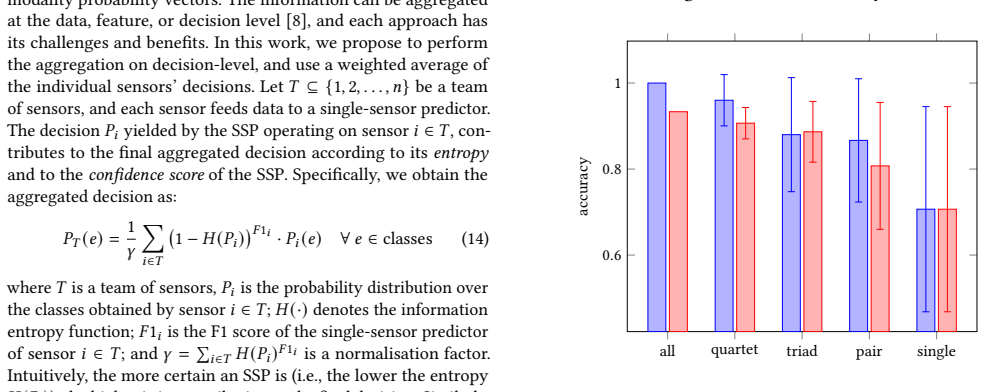
The paper claims that a non-stationary pipeline using FBSE with EWT for mode-wise transient descriptors, followed by decision-level aggregation of per-modality predictors weighted by predictive uncertainty and modality reliability, yields decision-level aggregation that is approximately 84 percent of the time at least as good as feature-level aggregation and approximately 48 percent of the time strictly better on WESAD for three-class affect recognition using ECG, EDA, BVP, EMG, and ACC signals.
What carries the argument
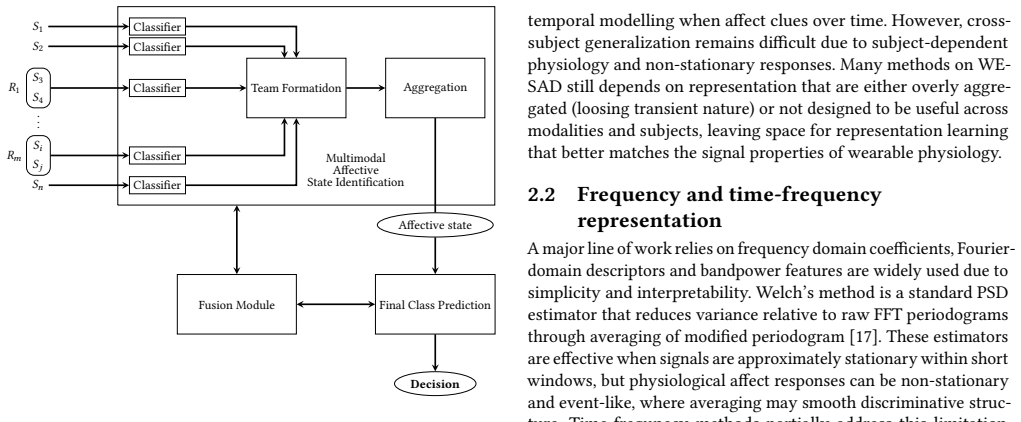
Decision-level aggregation weighted by predictive uncertainty and modality reliability from per-modality predictors, which combines outputs after separate classification instead of early feature fusion.
If this is right
- The method improves robustness under heterogeneous and partially reliable sensing conditions typical of real wearable deployments.
- Weighting by uncertainty allows the system to downplay modalities affected by artifacts or sensor failure.
- FBSE-EWT feature extraction captures short-lived discriminative patterns that fixed spectral methods like FFT bandpower tend to oversmooth.
- The approach supports applications in preventive care and stress-aware interventions where sensor reliability varies.
Where Pith is reading between the lines
- The same weighting principle could be tested on other multimodal physiological tasks such as sleep staging or emotion detection in different populations.
- If uncertainty estimates prove stable, the framework might support online modality dropout when a sensor becomes completely unreliable.
- Larger cohorts would allow checking whether the performance gains hold when the per-modality models are trained on more diverse data.
Load-bearing premise
Predictive uncertainty and modality reliability can be estimated reliably enough from the per-modality predictors to produce stable weights without introducing selection bias or overfitting on the small 15-subject WESAD cohort.
What would settle it
A replication on an independent dataset with more subjects in which feature-level fusion is strictly better than the weighted decision-level method in more than 52 percent of trials would falsify the robustness advantage.
Figures
read the original abstract
Automatic recognition of affective state from wearable physiology has clear societal impact for public health, preventive care, and stress-aware interventions, but real deployments require robustness to non-stationary dynamics, artefacts, and missing sensors. We study this problem on WESAD, using baseline, stress, and amusement conditions, where common fixed-basis spectral features such as FFT bandpower and Welch PSD can oversmooth short-lived discriminative patterns. We propose a non-stationary pipeline that combines Fourier-Bessel Series Expansion (FBSE) with EWT data-driven spectral segmentation to extract mode-wise transient descriptors. For multimodal integration, we adopt decision-level aggregation over per-modality predictors and weight each modality by predictive uncertainty and modality reliability. Results on WESAD, using 15 subjects and ECG, EDA, BVP, EMG, and ACC signals across three classes, indicate that decision-level aggregation is approximately 84 percent of the time at least as good as feature-level aggregation, and approximately 48 percent of the time strictly better, suggesting improved robustness under heterogeneous and partially reliable sensing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a non-stationary feature extraction pipeline combining Fourier-Bessel Series Expansion (FBSE) with Empirical Wavelet Transform (EWT) for transient descriptors from ECG, EDA, BVP, EMG, and ACC signals on the WESAD dataset (baseline/stress/amusement classes). It advocates decision-level fusion of per-modality predictors, with weights derived from predictive uncertainty and modality reliability, and reports that this yields performance at least as good as feature-level fusion in ~84% of cases and strictly better in ~48% of cases across 15 subjects.
Significance. If the robustness advantage is confirmed under proper statistical controls, the decision-level weighting scheme could improve reliability of wearable affect recognition in deployments with heterogeneous sensor quality or partial failures. The data-driven spectral segmentation addresses a plausible limitation of fixed-basis features like FFT/Welch PSD.
major comments (3)
- Abstract: the central claim that decision-level aggregation is 'approximately 84 percent of the time at least as good' and '48 percent of the time strictly better' is presented as aggregate percentages with no error bars, confidence intervals, statistical tests, or subject-wise breakdowns, leaving the robustness conclusion unsupported on a 15-subject cohort.
- Abstract / Methods (weighting procedure): no description is given of how predictive uncertainty or modality reliability are computed, whether the weights are obtained via cross-validation, or whether they are fixed globally versus recomputed per subject/fold; without this, the reported superiority rates cannot be distinguished from potential overfitting or selection bias on the small sample.
- Evaluation: the comparison to feature-level aggregation lacks a null-model baseline (e.g., uniform weights or random weighting) and any leave-one-subject-out or per-subject performance tables, so it is impossible to determine whether the 48%/84% figures exceed what would be expected from noise in uncertainty estimates alone.
minor comments (1)
- Abstract: specify the exact train/test protocol and number of folds used to generate the reported percentages.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive suggestions. We address each of the major comments below and have made revisions to the manuscript to incorporate the feedback where appropriate.
read point-by-point responses
-
Referee: Abstract: the central claim that decision-level aggregation is 'approximately 84 percent of the time at least as good' and '48 percent of the time strictly better' is presented as aggregate percentages with no error bars, confidence intervals, statistical tests, or subject-wise breakdowns, leaving the robustness conclusion unsupported on a 15-subject cohort.
Authors: We agree that providing statistical support for the aggregate percentages would strengthen the abstract. In the revised version, we have included subject-wise breakdowns of the performance comparisons, along with bootstrap confidence intervals for the 84% and 48% figures. We have also added a paired statistical test (McNemar's test) across subjects to assess whether the observed superiority rates are significant. revision: yes
-
Referee: Abstract / Methods (weighting procedure): no description is given of how predictive uncertainty or modality reliability are computed, whether the weights are obtained via cross-validation, or whether they are fixed globally versus recomputed per subject/fold; without this, the reported superiority rates cannot be distinguished from potential overfitting or selection bias on the small sample.
Authors: The methods section of the manuscript describes the weighting as based on predictive uncertainty (entropy of the softmax outputs) and modality reliability (per-modality validation F1-score). Weights are recomputed for each subject using the training folds in a leave-one-subject-out scheme. However, we acknowledge the abstract lacked this detail. We have revised the abstract to briefly summarize the weighting computation and cross-validation approach. revision: yes
-
Referee: Evaluation: the comparison to feature-level aggregation lacks a null-model baseline (e.g., uniform weights or random weighting) and any leave-one-subject-out or per-subject performance tables, so it is impossible to determine whether the 48%/84% figures exceed what would be expected from noise in uncertainty estimates alone.
Authors: We agree that null baselines and detailed per-subject results would improve the evaluation. We have added a comparison against uniform weighting and random weighting as null models in the results section. Additionally, we now provide per-subject performance tables and leave-one-subject-out results in the main text and supplementary material to allow assessment of variability. revision: yes
Circularity Check
No circularity: empirical comparison on public dataset
full rationale
The paper reports direct empirical results from experiments on the public WESAD dataset (15 subjects, multiple modalities, three classes). The 84% and 48% figures are outcome statistics from comparing decision-level vs. feature-level aggregation; they are not fitted parameters, not derived by construction from the weights, and not justified via self-citation chains. The pipeline (FBSE + EWT + uncertainty-weighted fusion) is presented as a proposed method whose performance is measured externally against the dataset, satisfying the self-contained benchmark criterion.
Axiom & Free-Parameter Ledger
free parameters (1)
- modality reliability and uncertainty weights
axioms (1)
- domain assumption WESAD 15-subject recordings with baseline/stress/amusement labels are representative of non-stationary wearable dynamics and missing-sensor scenarios
Reference graph
Works this paper leans on
-
[1]
Jose Ignacio Aizpurua, Victoria M Catterson, Brian G Stewart, Stephen DJ McArthur, Brandon Lambert, and James G Cross. 2018. Uncertainty-aware fusion of probabilistic classifiers for improved transformer diagnostics.IEEE Transactions on Systems, Man, and Cybernetics: Systems51, 1 (2018), 621–633
2018
-
[2]
Jont B Allen and Lawrence R Rabiner. 2005. A unified approach to short-time Fourier analysis and synthesis.Proc. IEEE65, 11 (2005), 1558–1564
2005
-
[3]
Değer Ayata, Yusuf Yaslan, and Mustafa E Kamasak. 2020. Emotion recognition from multimodal physiological signals for emotion aware healthcare systems. Journal of Medical and Biological Engineering40, 2 (2020), 149–157
2020
-
[4]
Tadas Baltrušaitis, Chaitanya Ahuja, and Louis-Philippe Morency. 2018. Multi- modal machine learning: A survey and taxonomy.IEEE transactions on pattern analysis and machine intelligence41, 2 (2018), 423–443
2018
-
[5]
Jing Chen, Bin Hu, Lixin Xu, Philip Moore, and Yun Su. 2015. Feature-level fusion of multimodal physiological signals for emotion recognition. In2015 IEEE International Conference on Bioinformatics and Biomedicine (BIBM). IEEE, 395–399
2015
-
[6]
Konstantin Dragomiretskiy and Dominique Zosso. 2013. Variational mode de- composition.IEEE transactions on signal processing62, 3 (2013), 531–544
2013
-
[7]
Jerome Gilles. 2013. Empirical wavelet transform.IEEE transactions on signal processing61, 16 (2013), 3999–4010
2013
-
[8]
Raffaele Gravina, Parastoo Alinia, Hassan Ghasemzadeh, and Giancarlo Fortino
-
[9]
Multi-sensor fusion in body sensor networks: State-of-the-art and research challenges.Information Fusion35 (2017), 68–80
2017
-
[10]
Jennifer A Healey and Rosalind W Picard. 2005. Detecting stress during real- world driving tasks using physiological sensors.IEEE Transactions on intelligent transportation systems6, 2 (2005), 156–166
2005
-
[11]
Norden E Huang, Zheng Shen, Steven R Long, Manli C Wu, Hsing H Shih, Quanan Zheng, Nai-Chyuan Yen, Chi Chao Tung, and Henry H Liu. 1998. The empirical mode decomposition and the Hilbert spectrum for nonlinear and non- stationary time series analysis.Proceedings of the Royal Society of London. Series A: mathematical, physical and engineering sciences454, 1...
1998
-
[12]
Sylvia D Kreibig. 2010. Autonomic nervous system activity in emotion: A review. Biological psychology84, 3 (2010), 394–421
2010
-
[13]
Stephane G Mallat. 1989. Multifrequency channel decompositions of images and wavelet models.IEEE Transactions on Acoustics, speech, and signal processing37, 12 (1989), 2091–2110
1989
-
[14]
2000.Affective computing
Rosalind W Picard. 2000.Affective computing. MIT press
2000
-
[15]
Philip Schmidt, Attila Reiss, Robert Duerichen, Claus Marberger, and Kristof Van Laerhoven. 2018. Introducing wesad, a multimodal dataset for wearable stress and affect detection. InProceedings of the 20th ACM international conference on multimodal interaction. 400–408
2018
-
[16]
Ritu Tanwar, Orchid Chetia Phukan, Ghanapriya Singh, Pankaj Kumar Pal, and Sanju Tiwari. 2024. Attention based hybrid deep learning model for wearable based stress recognition.Engineering Applications of Artificial Intelligence127 (2024), 107391
2024
-
[17]
Zhiguang Wang and Tim Oates. 2015. Imaging time-series to improve classifica- tion and imputation.arXiv preprint arXiv:1506.00327(2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[18]
Peter Welch. 2003. The use of fast Fourier transform for the estimation of power spectra: A method based on time averaging over short, modified periodograms. IEEE Transactions on audio and electroacoustics15, 2 (2003), 70–73
2003
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.