{μ}-ORCA: Optimizing Acceleration for Microsecond-Scale Deep Neural Network Inference on ACAP
Pith reviewed 2026-05-19 21:49 UTC · model grok-4.3
The pith
μ-ORCA achieves 0.93 μs DNN inference latency on ACAP by direct AIE array communication
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
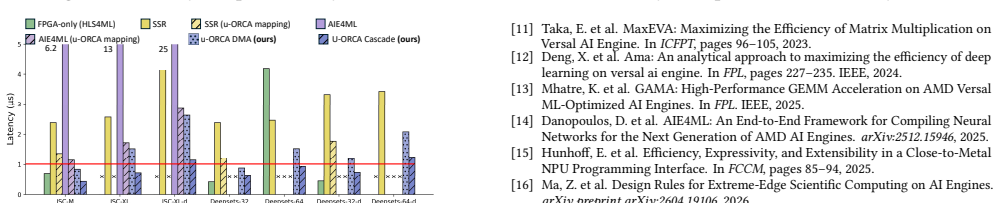
μ-ORCA enables direct inter-layer communication between DNN layers on the AIE array instead of using shared memory tiles or FPGA fabric, applies a 512-bit/cycle cascade connection instead of a 32-bit/cycle DMA connection, provides an overhead-aware performance model that adapts to different NN layer sizes, and conducts design space exploration to optimize end-to-end latency for MLP and DeepSets models with non-MM kernels including bias, ReLU, and global aggregation on AIE, achieving average latency reduction of >1.70× and >1.83× compared with different state-of-the-art ACAP frameworks and 0.93 μs latency for a 6-layer real-world DeepSets model on the AMD ACAP VEK280 platform.
What carries the argument
Direct inter-layer communication on the AIE array with 512-bit/cycle cascade connections that bypass shared memory and DMA for reduced latency in small models.
Load-bearing premise
Direct inter-layer communication on the AIE array can be realized with negligible additional synchronization or routing overhead for the small problem sizes typical of jet-tagging models.
What would settle it
A test run on the VEK280 platform where the 6-layer DeepSets model using μ-ORCA's direct communication method exhibits latency above 1 μs due to unaccounted synchronization costs.
Figures







read the original abstract
Heterogeneous reconfigurable platforms with tensor cores, such as AMD ACAP, are increasingly adopted for deep neural network (DNN) inference due to their high throughput and flexibility. However, their suitability for microsecond-scale inference on small problem sizes remains underexplored. In jet-tagging applications in high-energy physics, inefficient on-chip communication and large inter-layer latency prevent existing frameworks from meeting the 1-{\mu}s latency budget. Moreover, hardware overheads such as synchronization and VLIW processor prologue are often overlooked, making it infeasible to optimize accelerators correctly. To address these problems, we propose {\mu}-ORCA, a customized heterogeneous accelerator framework for ultra-low-latency model inference. {\mu}-ORCA enables direct inter-layer communication between DNN layers on the AIE array, instead of using shared memory tiles or FPGA fabric. Moreover, a 512-bit/cycle cascade connection is applied instead of a 32-bit/cycle DMA connection. {\mu}-ORCA also provides an overhead-aware performance model that adapts to different NN layer sizes, and conducts design space exploration to optimize end-to-end latency. {\mu}-ORCA supports MLP and DeepSets models with non-MM kernels, including bias, ReLU, and global aggregation on AIE. We evaluate {\mu}-ORCA on the AMD ACAP VEK280 platform. Experimental results show that {\mu}-ORCA achieves average latency reduction of >1.70$\times$ and >1.83$\times$ compared with different state-of-the-art ACAP frameworks, and achieves 0.93 {\mu}s latency for a 6-layer real-world DeepSets model, satisfying the latency budget. We open source {\mu}-ORCA at https://github.com/arc-research-lab/u-ORCA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes μ-ORCA, a customized heterogeneous accelerator framework for ultra-low-latency DNN inference on AMD ACAP platforms. It enables direct inter-layer communication on the AIE array using 512-bit/cycle cascade connections rather than shared memory or DMA, provides an overhead-aware performance model that adapts to different layer sizes for design space exploration, and supports MLP and DeepSets models including non-MM kernels like bias, ReLU, and global aggregation. Evaluation on the VEK280 platform shows that μ-ORCA achieves 0.93 μs latency for a 6-layer real-world DeepSets model, meeting the 1-μs budget, along with average latency reductions of over 1.70× and 1.83× compared to state-of-the-art ACAP frameworks.
Significance. This work addresses an important gap in deploying DNNs for microsecond-scale inference on reconfigurable hardware, particularly for high-energy physics applications such as jet tagging. The hardware measurements on real ACAP hardware provide concrete evidence for the latency claims, and the open-sourcing of the implementation is a strength that supports reproducibility. The overhead-aware model is a useful contribution for accurate performance estimation in accelerator design.
major comments (1)
- Framework design and evaluation sections: the 0.93 μs latency claim and reported speedups rest on direct AIE-array inter-layer communication (via 512-bit/cycle cascade) incurring negligible synchronization/routing overhead for the small problem sizes typical of jet-tagging models. No ablation isolating the communication method, no per-component latency breakdown, and no explicit validation of the overhead-aware model predictions against measured overheads are described, leaving this assumption as the least-secured link.
minor comments (2)
- Abstract: the specific state-of-the-art ACAP frameworks used for the >1.70× and >1.83× comparisons should be named or cited for better context.
- Notation and figures: ensure consistent use of terms such as 'cascade connection' versus 'DMA connection' across text and diagrams.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the work's significance, hardware evaluation, and open-sourcing. We address the single major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [—] Framework design and evaluation sections: the 0.93 μs latency claim and reported speedups rest on direct AIE-array inter-layer communication (via 512-bit/cycle cascade) incurring negligible synchronization/routing overhead for the small problem sizes typical of jet-tagging models. No ablation isolating the communication method, no per-component latency breakdown, and no explicit validation of the overhead-aware model predictions against measured overheads are described, leaving this assumption as the least-secured link.
Authors: We appreciate the referee highlighting this point. The overhead-aware performance model explicitly incorporates synchronization, routing, and VLIW prologue costs and is calibrated using hardware measurements on the VEK280 for the evaluated layer sizes; the reported 0.93 μs end-to-end latency and speedups are obtained from direct hardware timing rather than model predictions alone. For the small problem sizes characteristic of jet-tagging models, the 512-bit/cycle AIE cascade connections are architecturally designed to incur lower overhead than DMA or shared-memory alternatives, consistent with AMD AIE documentation. Nevertheless, we agree that an explicit ablation isolating the cascade communication method, a per-component latency breakdown, and direct validation plots of model-predicted versus measured overheads would strengthen the presentation. We will add these elements to the revised manuscript, including a table or figure showing component-wise timings and a comparison of end-to-end latency with and without direct cascade links where implementation constraints allow. revision: yes
Circularity Check
No significant circularity; latency claims derive from hardware execution
full rationale
The paper's central claims (0.93 μs latency for the 6-layer DeepSets model and >1.70×/>1.83× speedups) are obtained from direct physical measurements on the AMD ACAP VEK280 platform after implementing the accelerator. The overhead-aware performance model is used only for design-space exploration to select configurations; the reported end-to-end numbers are not produced by that model or by any fitted parameter renamed as a prediction. No self-definitional equations, load-bearing self-citations, or ansatz smuggling appear in the derivation of the final results, which remain externally falsifiable via the open-sourced code and real hardware.
Axiom & Free-Parameter Ledger
free parameters (1)
- layer-size adaptation parameters
axioms (1)
- domain assumption Direct inter-layer communication via 512-bit cascade on AIE array incurs negligible extra overhead compared with DMA for the target small problem sizes.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
µ-ORCA enables direct inter-layer communication between DNN layers on the AIE array... a 512-bit/cycle cascade connection is applied instead of a 32-bit/cycle DMA connection... overhead-aware performance model that adapts to different NN layer sizes
-
IndisputableMonolith/Foundation/DimensionForcing.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We evaluate µ-ORCA on the AMD ACAP VEK280 platform... achieves 0.93 µs latency for a 6-layer real-world DeepSets model
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.