Argo: Efficient Importance Labeling for Enterprise Email Systems
Pith reviewed 2026-05-22 08:46 UTC · model grok-4.3
The pith
Argo's profiler identifies labeling schemes that cut inference costs by 148-167X while preserving near-GPT quality for enterprise email.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Argo constructs a profiler to search the space of possible labeling schemes for cost-efficient options that approach the quality of GPT-4.1, then applies these at scale using on-demand provisioning to manage variable loads. The result is practical large-scale context-aware labeling without the prohibitive costs of full-scale LLM inference.
What carries the argument
The profiler, which searches the cost-quality trade-off space to identify efficient labeling alternatives to full GPT-4.1 models.
Load-bearing premise
Cheaper labeling schemes found by the profiler will deliver nearly the same quality as GPT-4.1 when applied to actual enterprise email data and distributions.
What would settle it
Testing the Argo-chosen schemes on a large, private enterprise email corpus and finding that labeling accuracy falls significantly below GPT-4.1 levels.
Figures







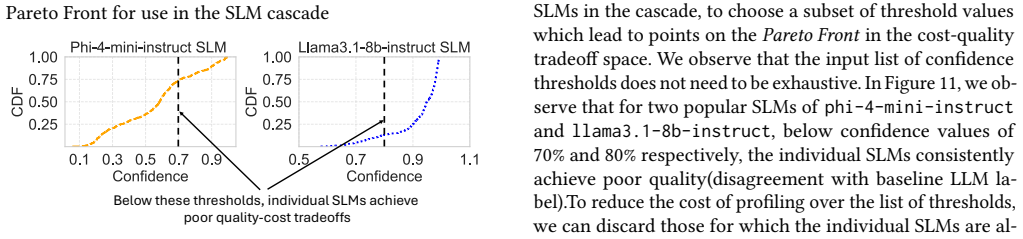



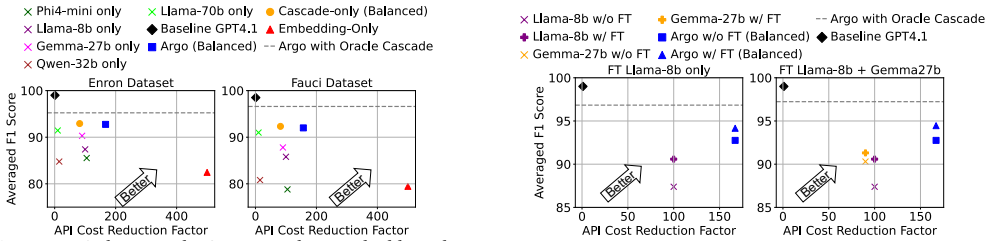

read the original abstract
Email importance labeling has long been a critical yet challenging problem for businesses and individuals. Traditional approaches; such as keyword matching, user-defined rules, and sender-based heuristics; demand extensive manual feature engineering and fail to scale effectively or generalize. Recent advances in large language models (LLMs) demonstrate strong potential and a natural fit for this task, offering deep contextual understanding and superior labeling quality. However, using LLM models like GPT-4.1 at enterprise email volumes incurs prohibitive computational costs and hinders real-world deployment. We explore the trade-off space of using alternative labeling schemes as opposed to GPT4.1 scale LLMs, with the goal of achieving near GPT level labeling quality with significantly lower cost. We develop Argo, an enterprise email labeling framework, where we construct a profiler to efficiently search the cost quality trade-off space of labeling and identify cost-efficient alternatives to labeling emails. Additionally, we design an on-demand provisioning scheme to intelligently scale Argo with real time load, to minimize cost increases during peak load inference. Over 3 open-source email datasets, Argo achieves 148-167X inference cost reduction with negligible quality degradation and 20-640000X lower profiling costs, making large-scale, context-aware email labeling practical for enterprises.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Argo, an enterprise email labeling framework that constructs a profiler to search the cost-quality trade-off space among labeling schemes and designs an on-demand provisioning scheme to scale inference under real-time load. The central empirical claim is that, over three open-source email datasets, Argo delivers 148-167X inference cost reduction relative to GPT-4.1 with negligible quality degradation and 20-640000X lower profiling costs, thereby making large-scale context-aware email importance labeling practical.
Significance. If the reported cost-quality trade-offs hold under enterprise conditions, the work would remove a major computational barrier to deploying LLM-based contextual labeling at business scale. The profiler-plus-provisioning design directly targets the inference-cost bottleneck that currently prevents adoption of high-quality models for high-volume email streams.
major comments (1)
- [Abstract] Abstract: All quantitative results (148-167X inference reduction, negligible quality loss, 20-640000X profiling-cost savings) are reported exclusively on three open-source email datasets. Enterprise email differs systematically in volume, thread length, sender diversity, privacy constraints, and content distribution. No domain-shift experiments, ablation on enterprise-like characteristics, or representativeness argument is supplied to show that the profiler-selected cheaper schemes retain near-GPT fidelity when these distributional differences are present. This extrapolation is load-bearing for the central deployment claim.
minor comments (2)
- [Abstract] Abstract: punctuation is inconsistent ('Traditional approaches; such as keyword matching, user-defined rules, and sender-based heuristics; demand'). Replace the semicolons with commas or restructure the sentence for readability.
- [Abstract] Abstract: model name alternates between 'GPT-4.1' and 'GPT4.1'. Standardize throughout the manuscript.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the work's significance. We address the major comment on generalizability to enterprise settings below.
read point-by-point responses
-
Referee: [Abstract] Abstract: All quantitative results (148-167X inference reduction, negligible quality loss, 20-640000X profiling-cost savings) are reported exclusively on three open-source email datasets. Enterprise email differs systematically in volume, thread length, sender diversity, privacy constraints, and content distribution. No domain-shift experiments, ablation on enterprise-like characteristics, or representativeness argument is supplied to show that the profiler-selected cheaper schemes retain near-GPT fidelity when these distributional differences are present. This extrapolation is load-bearing for the central deployment claim.
Authors: We acknowledge that all reported numbers come from the three open-source datasets and that no direct domain-shift experiments on enterprise data are included. Enterprise email does differ in the ways noted, and we cannot perform experiments on proprietary enterprise corpora due to privacy constraints. However, the profiler is explicitly designed to be run on whatever target distribution is available, empirically locating the cost-quality frontier for that specific data rather than assuming a fixed scheme. The Enron, Avocado, and third dataset already contain substantial variation in thread structure, sender diversity, and topical content. In the revision we will add an explicit representativeness discussion comparing key statistics of these datasets to published enterprise email characterizations, plus a limitations paragraph on the extrapolation. We believe this addresses the concern without overclaiming while preserving the central methodological contribution. revision: partial
Circularity Check
No circularity: empirical profiler results on open-source datasets
full rationale
The paper describes an empirical systems framework that constructs a profiler to search labeling cost-quality trade-offs and reports measured speedups on three open-source email datasets. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or described approach. The central claims rest on direct experimental measurements rather than any reduction to inputs by construction, satisfying the self-contained benchmark criterion.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Argo ... construct a profiler to efficiently search the cost-quality trade-off space of labeling and identify cost-efficient alternatives
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Argo achieves 148-167X inference cost reduction with negligible quality degradation
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Alibaba/Qwen Team. Qwen2.5 32b instruct. https://huggingface.co/Q wen/Qwen2.5-32B-Instruct, 2025. SLM, 20×cheaper
work page 2025
-
[2]
Work hard, play hard: Email classification on the avocado and enron corpora
Sakhar Alkhereyf and Owen Rambow. Work hard, play hard: Email classification on the avocado and enron corpora. InProceedings of TextGraphs-11: the Workshop on Graph-based Methods for Natural Lan- guage Processing, pages 57–65. Association for Computational Linguis- tics, 2017
work page 2017
-
[3]
Show emails from vip senders in mail on mac
Apple. Show emails from vip senders in mail on mac. https://support.ap ple.com/guide/mail/show-emails-from-vip-senders-mail40589/mac. Accessed: 2025-12-08
work page 2025
-
[4]
Summarize notifications and reduce interruptions with apple intelligence on iphone
Apple Support. Summarize notifications and reduce interruptions with apple intelligence on iphone. https://support.apple.com/is- is/guide/iphone/iph1fbe7d2b9/ios, 2025. Accessed December 8, 2025
work page 2025
-
[5]
Yogesh Balaji, Rama Chellappa, and Soheil Feizi. Normalized wasser- stein distance for mixture distributions with applications in adversarial learning and domain adaptation, 2019
work page 2019
-
[6]
Automatic categorization of email into folders: Bench- mark experiments on enron and sri corpora
Ron Bekkerman. Automatic categorization of email into folders: Bench- mark experiments on enron and sri corpora
-
[7]
Supervised learning of universal sentence representa- tions from natural language inference data
Alexis Conneau, Douwe Kiela, Holger Schwenk, Loïc Barrault, and Antoine Bordes. Supervised learning of universal sentence representa- tions from natural language inference data. In Martha Palmer, Rebecca Hwa, and Sebastian Riedel, editors,Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pages 670–680, Copenhagen, Den...
work page 2017
-
[8]
DeepSeek AI. Deepseek distilled models. https://huggingface.co /deepseek-ai, 2024. Distilled variants including DeepSeek-LLM and R1-Distill
work page 2024
-
[9]
Hierarchical attention networks for email classification
Sheng Deng, Wei Wang, and Jian Sun. Hierarchical attention networks for email classification. InAAAI Conference on Artificial Intelligence, 2018
work page 2018
-
[10]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding.Proceedings of NAACL, 2019
work page 2019
-
[11]
Dujian Ding, Ankur Mallick, Chi Wang, Robert Sim, Subhabrata Mukherjee, Victor Ruhle, Laks V. S. Lakshmanan, and Ahmed Hassan Awadallah. Hybrid llm: Cost-efficient and quality-aware query routing, 2024
work page 2024
-
[12]
Nicolas Ducheneaut and Victoria Bellotti. E-mail as habitat: an explo- ration of embedded personal information management.Interactions, 8(5):30–38, September 2001
work page 2001
- [13]
-
[14]
William Falcon and the PyTorch Lightning Team. Pytorch lightning. https://github.com/Lightning-AI/pytorch-lightning, 2025. Version 2.5.4 (accessed 2025-12-09)
work page 2025
-
[15]
Federal Energy Regulatory Commission. Enron email dataset. https: //www.cs.cmu.edu/~enron/, 2004. Accessed 2025-12-09
work page 2004
-
[16]
Google DeepMind. Gemma 3 27b it. https://huggingface.co/google/ge mma-3-27b-it, 2025. SLM, 90×cheaper
work page 2025
-
[17]
Recipient recommendation in enterprises using communication graphs and email content
David Graus, David van Dijk, Manos Tsagkias, Wouter Weerkamp, and Maarten de Rijke. Recipient recommendation in enterprises using communication graphs and email content. InProceedings of the 37th International ACM SIGIR Conference on Research & Development in Information Retrieval, SIGIR ’14, page 1079–1082, New York, NY, USA,
-
[19]
Language model cascades: Token-level uncertainty and beyond
Neha Gupta, Harikrishna Narasimhan, Wittawat Jitkrittum, Ankit Singh Rawat, Aditya Krishna Menon, and Sanjiv Kumar. Language model cascades: Token-level uncertainty and beyond. In B. Kim, Y. Yue, S. Chaudhuri, K. Fragkiadaki, M. Khan, and Y. Sun, editors,International Conference on Representation Learning, volume 2024, pages 4147–4180, 2024
work page 2024
-
[20]
Haibo He and Edwardo A. Garcia. Learning from imbalanced data. IEEE Trans. on Knowl. and Data Eng., 21(9):1263–1284, September 2009
work page 2009
-
[21]
Yifei He, Haoxiang Wang, Bo Li, and Han Zhao. Gradual domain adap- tation: Theory and algorithms.Journal of Machine Learning Research, 25(361):1–40, 2024
work page 2024
-
[22]
Kevin Hsieh, Ganesh Ananthanarayanan, Peter Bodik, Shivaram Venkataraman, Paramvir Bahl, Matthai Philipose, Phillip B. Gibbons, and Onur Mutlu. Focus: Querying large video datasets with low la- tency and low cost. In13th USENIX Symposium on Operating Systems Design and Implementation (OSDI 18), pages 269–286, Carlsbad, CA, October 2018. USENIX Association
work page 2018
-
[23]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adapta- tion of large language models. InProceedings of the 10th International Conference on Learning Representations (ICLR), 2022
work page 2022
-
[24]
Routerbench: A benchmark for multi-llm routing system, 2024
Qitian Jason Hu, Jacob Bieker, Xiuyu Li, Nan Jiang, Benjamin Keigwin, Gaurav Ranganath, Kurt Keutzer, and Shriyash Kaustubh Upadhyay. Routerbench: A benchmark for multi-llm routing system, 2024
work page 2024
-
[25]
Chameleon: scalable adaptation of video analytics
Junchen Jiang, Ganesh Ananthanarayanan, Peter Bodik, Siddhartha Sen, and Ion Stoica. Chameleon: scalable adaptation of video analytics. InProceedings of the 2018 Conference of the ACM Special Interest Group on Data Communication, SIGCOMM ’18, page 253–266, New York, NY, USA, 2018. Association for Computing Machinery
work page 2018
-
[26]
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization.International Conference on Learning Representations (ICLR), 2015
work page 2015
-
[27]
Email classification with co-training
Svetlana Kiritchenko and Stan Matwin. Email classification with co-training. InProceedings of the 2011 Conference of the Center for Ad- vanced Studies on Collaborative Research, CASCON ’11, page 301–312, USA, 2011. IBM Corp
work page 2011
-
[28]
The enron corpus: A new dataset for email classification research
Bryan Klimt and Yiming Yang. The enron corpus: A new dataset for email classification research. InEuropean Conference on Machine Learning (ECML), 2004
work page 2004
-
[29]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles (SOSP), 2023
work page 2023
-
[30]
Detecting emails containing requests for action
Andrew Lampert, Robert Dale, and Cecile Paris. Detecting emails containing requests for action. InHuman Language Technologies: The 2010 Annual Conference of the North American Chapter of the Association 13 for Computational Linguistics, pages 984–992, 2010
work page 2010
-
[31]
Zhang, Shuyi Wang, Ziang Tang, Fang Han, Zohaib Hassan, Jianqiao Zheng, and Avinash Changrani
Xunzhuo Liu, Huamin Chen, Samzong Lu, Yossi Ovadia, Guohong Wen, Hao Wu, Zhengda Tan, Jintao Zhang, Senan Zedan, Yehudit Kerido, Liav Weiss, Haichen Zhang, Bishen Yu, Asaad Balum, Noa Limoy, Abdallah Samara, Baofa Fan, Brent Salisbury, Ryan Cook, Zhijie Wang, Qiping Pan, Rehan Khan, Avishek Goswami, Houston H. Zhang, Shuyi Wang, Ziang Tang, Fang Han, Zoha...
work page 2026
-
[32]
Decoupled weight decay regulariza- tion
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regulariza- tion. InInternational Conference on Learning Representations, 2019
work page 2019
-
[33]
Zhenyan Lu, Xiang Li, Dongqi Cai, Rongjie Yi, Fangming Liu, Wei Liu, Jian Luan, Xiwen Zhang, Nicholas D. Lane, and Mengwei Xu. Demys- tifying small language models for edge deployment. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Proceedings of the 63rd Annual Meeting of the Association for Computational Linguist...
work page 2025
-
[34]
Wendy E. Mackay. More than just a communication system: Diversity in the use of electronic mail. InProceedings of the ACM Conference on Computer-Supported Cooperative Work (CSCW), pages 344–353. ACM, 1988
work page 1988
-
[35]
Topic and role discovery in social networks with experiments on enron and academic email.J
Andrew McCallum, Xuerui Wang, and Andrés Corrada-Emmanuel. Topic and role discovery in social networks with experiments on enron and academic email.J. Artif. Int. Res., 30(1):249–272, October 2007
work page 2007
-
[36]
Meta AI. Llama 3.1 8b instruct. https://huggingf ace.co/meta- llama/Llama-3.1-8B-Instruct, 2025. SLM, 100×cheaper
work page 2025
-
[37]
Meta AI. Llama 3.3 70b instruct. https://huggingf ace.co/meta- llama/Llama-3.3-70B-Instruct, 2025. SLM, 10×cheaper
work page 2025
-
[38]
Microsoft. What is focused inbox? https://support.microsoft.com/en- us/office/what-is-focused-inbox-16b24373-dfa9-4139-ab19-08aa75 3a6055. Accessed: 2025-12-08
work page 2025
-
[39]
Microsoft. Phi-4-mini-instruct. https://huggingface.co/microsoft/phi- 4-mini-instruct, 2025. SLM, 105×cheaper
work page 2025
-
[40]
Microsoft Learn. What is azure ai foundry? https://learn.microsoft.co m/en-us/azure/ai-foundry/what-is-azure-ai-foundry, 2025. Accessed December 9, 2025
work page 2025
-
[41]
Mistral AI. Mistral 7b instruct. https://huggingface.co/mistralai/Mistr al-7B-Instruct-v0.2, 2024. Open-weight 7B instruction-tuned model
work page 2024
-
[42]
Towards mod- eling legitimate and unsolicited email traffic using social network properties
Farnaz Moradi, Tomas Olovsson, and Philippas Tsigas. Towards mod- eling legitimate and unsolicited email traffic using social network properties. InProceedings of the Fifth Workshop on Social Network Sys- tems, SNS ’12, New York, NY, USA, 2012. Association for Computing Machinery
work page 2012
-
[43]
Efficient large-scale language model training on gpu clusters
Deepak Narayanan et al. Efficient large-scale language model training on gpu clusters. InUSENIX OSDI, 2021
work page 2021
-
[44]
Isaac Ong, Amjad Almahairi, Vincent Wu, Wei-Lin Chiang, Tian- hao Wu, Joseph E. Gonzalez, M. Waleed Kadous, and Ion Stoica. Routellm: Learning to route llms with preference data.arXiv preprint arXiv:2406.11635, 2024
-
[45]
Onnx: Open neural network exchange
ONNX Community. Onnx: Open neural network exchange. https: //onnx.ai, 2025. Accessed 2025-12-09
work page 2025
-
[46]
OpenAI. Openai api. https://openai.com/blog/openai-api/, 2020. Accessed December 9, 2025
work page 2020
-
[47]
Openai api pricing — text token costs
OpenAI. Openai api pricing — text token costs. https://platform.ope nai.com/docs/pricing, 2025. Accessed December 9, 2025
work page 2025
-
[48]
OpenAI. text-embedding-3-large. https://platform.openai.com/docs /models, 2025. Embedding model, 100×cheaper
work page 2025
- [49]
-
[50]
Pytorch: An imperative style, high-performance deep learning library
Adam Paszke, Sam Gross, Soumith Chintala, Gregory Chanan, Edward Yang, Zachary DeVito, Zeming Lin, Alban Desmaison, Luca Antiga, and Adam Lerer. Pytorch: An imperative style, high-performance deep learning library. InAdvances in Neural Information Processing Systems 32 (NeurIPS 2019), 2019
work page 2019
-
[51]
Sentence-BERT: Sentence embed- dings using Siamese BERT-networks
Nils Reimers and Iryna Gurevych. Sentence-BERT: Sentence embed- dings using Siamese BERT-networks. In Kentaro Inui, Jing Jiang, Vincent Ng, and Xiaojun Wan, editors,Proceedings of the 2019 Confer- ence on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP- IJCNLP), pages 3982–3...
work page 2019
-
[52]
The enron email dataset: Database schema and brief statistical report
Jigar Shetty and Jafar Adibi. The enron email dataset: Database schema and brief statistical report. InInformation Retrieval Research, 2004
work page 2004
-
[53]
Learning with weak supervision for email intent detection
Kai Shu, Subhabrata Mukherjee, Guoqing Zheng, Ahmed Hassan Awadallah, Milad Shokouhi, and Susan Dumais. Learning with weak supervision for email intent detection. InProceedings of the 43rd In- ternational ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’20, page 1051–1060, New York, NY, USA,
-
[54]
Association for Computing Machinery
-
[55]
Leslie N Smith. Cyclical learning rates for training neural net- works.2017 IEEE Winter Conference on Applications of Computer Vision (W ACV), pages 464–472, 2017
work page 2017
-
[56]
Semantic agree- ment enables efficient open-ended LLM cascades
Duncan Soiffer, Steven Kolawole, and Virginia Smith. Semantic agree- ment enables efficient open-ended LLM cascades. In Saloni Potdar, Lina Rojas-Barahona, and Sebastien Montella, editors,Proceedings of the 2025 Conference on Empirical Methods in Natural Language Process- ing: Industry Track, pages 2499–2537, Suzhou (China), November 2025. Association for...
work page 2025
-
[57]
Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. Dropout: A simple way to prevent neural networks from overfitting.Journal of Machine Learning Research, 15(1):1929–1958, 2014
work page 1929
-
[58]
Computerworld Staff. Is your gmail inbox setup slowing you down? https://www.computerworld.com/article/3511582/is-your-gmail- inbox-setup-slowing-you-down.html. Accessed: 2025-12-08
-
[59]
Gmail categories and inbox tabs
Jesicca Stockett. Gmail categories and inbox tabs. https://swatkb.atlas sian.net/wiki/spaces/GA/pages/19661188/Gmail+Categories+and+In box+Tabs. Accessed: 2025-12-08
-
[60]
Energy and policy considerations for deep learning in nlp
Emma Strubell, Ananya Ganesh, and Andrew McCallum. Energy and policy considerations for deep learning in nlp. InACL, 2019
work page 2019
-
[61]
Line: Large-scale information network embedding
Jian Tang, Meng Qu, Mingzhe Wang, Ming Zhang, Jun Yan, and Qiaozhu Mei. Line: Large-scale information network embedding. In Proceedings of the 24th International Conference on World Wide Web, WWW ’15, page 1067–1077, Republic and Canton of Geneva, CHE,
-
[62]
International World Wide Web Conferences Steering Committee
-
[63]
U.S. Department of State. Hillary clinton email archive. https://wikile aks.org/clinton-emails/, 2016. FOIA Release; Accessed 2025-12-09
work page 2016
-
[64]
Improving text embeddings with large language models
Liang Wang, Nan Yang, Xiaolong Huang, Linjun Yang, Rangan Ma- jumder, and Furu Wei. Improving text embeddings with large language models. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors, Proceedings of the 62nd Annual Meeting of the Association for Computa- tional Linguistics (Volume 1: Long Papers), pages 11897–11916, Bangkok, Thailand, August ...
work page 2024
-
[65]
Context-aware intent identification in email conversa- tions
Wei Wang, Saghar Hosseini, Ahmed Awadallah, Paul Bennett, and Chris Quirk. Context-aware intent identification in email conversa- tions. InProceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 1209–1218. ACM, 2019
work page 2019
-
[66]
Email overload: exploring per- sonal information management of email
Steve Whittaker and Candace Sidner. Email overload: exploring per- sonal information management of email. InProceedings of the SIGCHI Conference on Human Factors in Computing Systems, CHI ’96, page 276–283, New York, NY, USA, 1996. Association for Computing Ma- chinery
work page 1996
-
[67]
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Syl- vain Gugger, Mariama Drame, Quentin Lhoest, and Alexander M. Rush. 14 Transformers: State-of-th...
work page 2020
-
[68]
MadEye: Boosting live video analytics accuracy with adaptive camera configurations
Mike Wong, Murali Ramanujam, Guha Balakrishnan, and Ravi Ne- travali. MadEye: Boosting live video analytics accuracy with adaptive camera configurations. In21st USENIX Symposium on Networked Sys- tems Design and Implementation (NSDI 24), pages 549–568, Santa Clara, CA, April 2024. USENIX Association
work page 2024
-
[69]
Charac- terizing and predicting enterprise email reply behavior
Liu Yang, Susan Dumais, Paul Bennett, and Ahmed Awadallah. Charac- terizing and predicting enterprise email reply behavior. InProceedings of the 40th International ACM SIGIR Conference on Research and Devel- opment in Information Retrieval, pages 505–514. ACM, 2017
work page 2017
-
[70]
Hierarchical attention networks for document classifi- cation
Zichao Yang, Diyi Yang, Chris Dyer, Xiaodong He, Alex Smola, and Eduard Hovy. Hierarchical attention networks for document classifi- cation. InNAACL, 2016
work page 2016
-
[71]
Haoyu Zhang, Ganesh Ananthanarayanan, Peter Bodik, Matthai Phili- pose, Paramvir Bahl, and Michael J. Freedman. Live video analytics at scale with approximation and Delay-Tolerance. In14th USENIX Symposium on Networked Systems Design and Implementation (NSDI 17), pages 377–392, Boston, MA, March 2017. USENIX Association
work page 2017
-
[72]
Rui Zhang and Chen Li. Email reply and importance prediction using pre-trained language models.Information Processing and Management, 2021. 15
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.