Bridging the Cold-Start Gap: LLM-Powered Synthetic Data Generation for Natural Language Search at Airbnb
Pith reviewed 2026-05-22 07:59 UTC · model grok-4.3
The pith
Seed-guided LLM synthesis matches real user query lengths and attributes closely enough to train and evaluate natural language search models from the first day.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
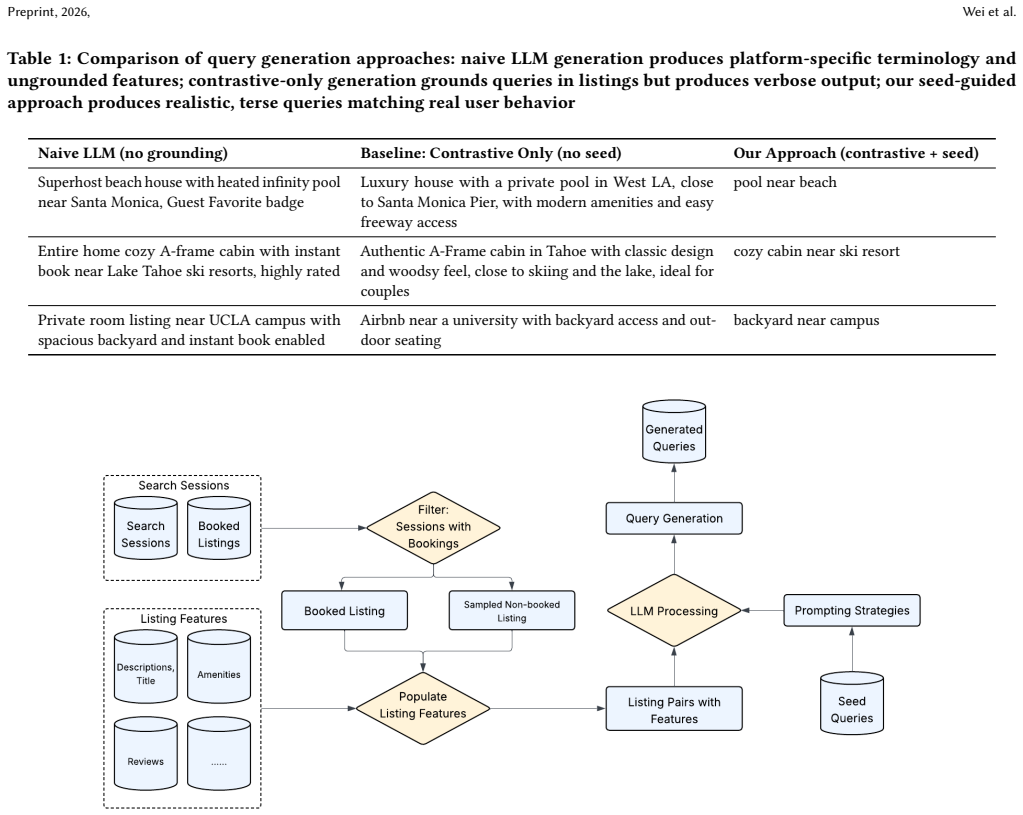
A seed-guided contrastive approach that feeds booking-session pairs and user-research queries into LLMs generates synthetic queries and labels whose length and attribute distributions are far closer to real users than either a no-seed contrastive baseline or an InPars-style baseline, while also creating more discriminative evaluation examples for ranking models.
What carries the argument
Seed-guided contrastive query generation that blends booking-session pairs with user-research seeds, paired with contrastive label generation and virtual-judge labeling.
If this is right
- Production pipelines can generate fresh synthetic examples every day to support embedding retrieval and ranking evaluation.
- The same seeded data enables a gradual shift from cold-start training to warm-start training as real queries arrive.
- Harder synthetic evaluation sets give clearer signals for iterative model improvement than easier no-seed sets.
Where Pith is reading between the lines
- The same seeding strategy could be tested on other search or recommendation platforms that face similar initial-data shortages.
- Reducing the influence of the seeds over time as real data accumulates might further tighten the match to live user behavior.
- The method could shorten the time between feature launch and usable model performance in additional domains that rely on natural language input.
Load-bearing premise
That queries and labels produced by the LLM, even when guided by booking sessions and research seeds, will match the behavior of real users once the live system receives actual queries.
What would settle it
A side-by-side comparison of length and attribute distributions between the synthetic queries and the first large batch of real user queries collected after deployment, showing substantially higher KL divergence than the reported 0.66 and 0.04 values.
Figures


read the original abstract
Deploying natural language search systems presents a critical cold-start challenge: no real user queries to learn linguistic patterns, and no relevance labels to train ranking models. We present a framework for generating synthetic queries and labels using large language models (LLMs), powering model training and evaluation for Airbnb's natural language search. For query generation, we combine contrastive listing pairs from booking sessions with seed queries from user research to balance realism and diversity, enabling a cold-to-warm start transition as real user data becomes available. For label generation, we introduce contrastive generation that produces topicality labels by construction, and Virtual Judge (VJ) labeling for broader coverage. We compare our approach against a no-seed contrastive baseline and an InPars-style baseline. For query length, the InPars baseline produces verbose queries with KL divergence of 12.03 vs. real users; our seed-guided approach achieves 0.66, a 7.5x improvement. For attribute type distributions, our approach achieves the lowest KL divergence (0.04), outperforming even seed queries (0.09). Experiments show our approach produces harder evaluation examples than the no-seed baseline (79% vs. 97% pairwise accuracy), providing discriminative signal for model improvement. We deploy production pipelines generating synthetic examples daily for embedding-based retrieval and ranking evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes an LLM-powered framework to generate synthetic queries and relevance labels for natural language search systems facing cold-start conditions, as at Airbnb. Query generation combines contrastive listing pairs from booking sessions with user-research seed queries to improve realism and diversity. Label generation uses contrastive methods to produce topicality labels by construction and Virtual Judge (VJ) labeling for broader coverage. The authors compare their seed-guided approach against a no-seed contrastive baseline and an InPars-style baseline, reporting a KL divergence of 0.66 on query length (7.5x better than InPars' 12.03), 0.04 on attribute distributions, and harder evaluation examples (79% pairwise accuracy vs. 97% for the no-seed baseline). They also describe deploying production pipelines that generate synthetic examples daily for embedding-based retrieval and ranking evaluation.
Significance. If the synthetic data generalizes to live user queries, the work offers a practical, deployable solution for cold-start challenges in industry IR systems, with clear quantitative gains in distribution matching over strong baselines. The production deployment and focus on both query generation and labeling are practical strengths that could influence synthetic-data practices in search.
major comments (1)
- [Experiments / Evaluation] The central claim that the seed-guided synthetic data bridges the cold-start gap for retrieval and ranking rests on the assumption that distribution-matched synthetic queries and labels will improve models on real user queries. However, the manuscript reports no downstream experiment that trains an embedding retriever or ranker on the generated data and measures recall, NDCG, or click-through metrics on a held-out set of real post-deployment queries (or any A/B test in production). The reported KL divergences and pairwise accuracies are computed only against real-user reference distributions on the synthetic set itself.
minor comments (2)
- [Abstract] The abstract introduces 'Virtual Judge (VJ) labeling' without a one-sentence definition; a brief parenthetical explanation on first use would aid readers.
- [Methods] Clarify the exact difference in prompt construction or sampling between the 'seed-guided' method and the 'no-seed contrastive baseline' so that the 79% vs. 97% pairwise accuracy gap can be reproduced from the description alone.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the practical strengths of our work and for the constructive feedback on evaluation. We address the major comment below, clarifying the scope of our contributions while committing to revisions that strengthen the manuscript.
read point-by-point responses
-
Referee: [Experiments / Evaluation] The central claim that the seed-guided synthetic data bridges the cold-start gap for retrieval and ranking rests on the assumption that distribution-matched synthetic queries and labels will improve models on real user queries. However, the manuscript reports no downstream experiment that trains an embedding retriever or ranker on the generated data and measures recall, NDCG, or click-through metrics on a held-out set of real post-deployment queries (or any A/B test in production). The reported KL divergences and pairwise accuracies are computed only against real-user reference distributions on the synthetic set itself.
Authors: We appreciate this observation and agree that direct downstream experiments—training an embedding retriever or ranker on the synthetic data and measuring recall, NDCG, or click-through rate on held-out real post-deployment queries—would provide stronger evidence for the framework's impact. Our current evaluation deliberately focuses on the fidelity of the generated data through distribution-matching metrics (KL divergence on query length and attribute distributions) and the discriminative power of the resulting evaluation sets (pairwise accuracy of 79% vs. 97% for the no-seed baseline). These proxies are standard in synthetic-data-for-IR literature and demonstrate that the seed-guided approach produces more realistic and harder examples than the InPars-style and no-seed baselines. The manuscript also reports the production deployment of daily synthetic-data pipelines for embedding-based retrieval and ranking evaluation, which supports iterative model improvement as real queries accumulate during the cold-to-warm transition. We will revise the manuscript to (1) explicitly state the scope of our claims, (2) add a dedicated limitations paragraph acknowledging the absence of end-to-end retrieval/ranking results on real queries, and (3) outline concrete plans for future A/B testing and offline evaluation once sufficient post-deployment real query data is available. This partial revision will address the referee's concern without changing the core technical contributions. revision: partial
Circularity Check
No circularity: empirical distribution matching against external references
full rationale
The manuscript reports direct empirical comparisons of generated query statistics (KL divergence on length and attribute distributions) to real-user reference distributions and to external baselines (InPars, no-seed contrastive). These measurements are computed on the outputs of the LLM generation process versus independent real data; they do not reduce to any parameter fitted inside the paper, nor to a self-defined quantity. No equations, uniqueness theorems, self-citations, or ansatzes are invoked to support the core claims. The 'by construction' phrasing for topicality labels is a definitional statement about the generation method itself and is not presented as a derived prediction. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs prompted with booking-session contrastive pairs and user-research seeds will produce query distributions close to real users.
invented entities (1)
-
Virtual Judge (VJ) labeling
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We combine contrastive listing pairs from booking sessions with seed queries from user research... KL divergence of 0.66 on query length... 0.04 on attribute distributions
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
contrastive generation that produces topicality labels by construction
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Omar Alonso, Daniel E. Rose, and Benjamin Stewart. 2008. Crowdsourcing for Relevance Evaluation. InACM SIGIR Forum, Vol. 42. 9–15
work page 2008
- [2]
-
[3]
Zhuyun Dai, Vincent Y Zhao, Ji Ma, Yi Luan, Jianmo Ni, Jing Lu, Anton Baber, Kelvin Lee, and Yi Lu. 2023. Promptagator: Few-shot Dense Retrieval From 8 Examples. InInternational Conference on Learning Representations
work page 2023
-
[4]
Feng, Varun Gangal, Jason Wei, Sarath Chandar, Soroush Vosoughi, Teruko Mitamura, and Eduard Hovy
Steven Y. Feng, Varun Gangal, Jason Wei, Sarath Chandar, Soroush Vosoughi, Teruko Mitamura, and Eduard Hovy. 2021. A Survey of Data Augmentation Approaches for NLP. InFindings of the Association for Computational Linguistics: ACL-IJCNLP 2021. 968–988
work page 2021
-
[5]
Albert Gatt and Emiel Krahmer. 2018. Survey of the State of the Art in Natural Language Generation: Core Tasks, Applications and Evaluation.Journal of Artificial Intelligence Research61 (2018), 65–170
work page 2018
-
[6]
Mihajlo Grbovic and Haibin Cheng. 2018. Real-time Personalization using Em- beddings for Search Ranking at Airbnb. InProceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 311–320
work page 2018
-
[7]
Malay Haldar, Mustafa Abdool, Prashant Ramanathan, Tao Xu, Shulin Yang, Huizhong Duan, Qing Zhang, Nick Barrow-Williams, Bradley C. Turnbull, Bren- dan M. Collins, and Thomas Legrand. 2019. Applying Deep Learning to Airbnb Search. InProceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 1927–1935
work page 2019
-
[8]
Malay Haldar, Daochen Zha, Huiji Gao, Liwei He, and Sanjeev Katariya. 2025. Beyond Pairwise Learning-To-Rank At Airbnb. InProceedings of the 34th ACM International Conference on Information and Knowledge Management. 5707–5714
work page 2025
-
[9]
Malay Haldar, Hongwei Zhang, Kedar Bellare, Sherry Chen, Soumyadip Banerjee, Xiaotang Wang, Mustafa Abdool, Huiji Gao, Pavan Tapadia, Liwei He, and Sanjeev Katariya. 2024. Learning to Rank for Maps at Airbnb. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 5061–5069
work page 2024
-
[10]
Gautier Izacard, Mathilde Caron, Lucas Hosseini, Sebastian Rber, Edouard Grave, Armand Joulin, and Gabriel Synnaeve. 2022. Unsupervised Dense Information Retrieval with Contrastive Learning. InTransactions on Machine Learning Re- search
work page 2022
-
[11]
Vitor Jeronymo, Luiz Bonifacio, Hugo Abonizio, Marzieh Fadaee, Roberto Lotufo, Jakub Zavrel, and Rodrigo Nogueira. 2023. InPars-v2: Large Language Models as Efficient Dataset Generators for Information Retrieval. InProceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2299–2303
work page 2023
-
[12]
Yannis Kalantidis, Mert Bulent Sariyildiz, Noe Pion, Philippe Weinzaepfel, and Diane Larlus. 2020. Hard Negative Mixing for Contrastive Learning. InAdvances in Neural Information Processing Systems, Vol. 33. 21798–21809
work page 2020
-
[13]
Mihir Kale and Abhinav Rastogi. 2020. Text-to-Text Pre-Training for Data-to-Text Tasks. InProceedings of the 13th International Conference on Natural Language Generation. 97–102
work page 2020
-
[14]
Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense Passage Retrieval for Open- Domain Question Answering. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. 6769–6781
work page 2020
-
[15]
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. 2023. G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2511–2522
work page 2023
-
[16]
Ji Ma, Ivan Korotkov, Yinfei Yang, Keith Hall, and Ryan McDonald. 2021. Zero-shot Neural Passage Retrieval via Domain-targeted Synthetic Question Generation. 8 Bridging the Cold-Start Gap: LLM-Powered Synthetic Data Generation for Natural Language Search at Airbnb Preprint, 2026, InProceedings of the 16th Conference of the European Chapter of the Associat...
work page 2021
- [17]
-
[18]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. 2020. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer.Journal of Machine Learning Research21, 140 (2020), 1–67
work page 2020
-
[19]
Joshua Robinson, Ching-Yao Chuang, Suvrit Sra, and Stefanie Jegelka. 2021. Contrastive Learning with Hard Negative Samples. InInternational Conference on Learning Representations
work page 2021
-
[20]
Timo Schick and Hinrich Schütze. 2021. Generating Datasets with Pretrained Language Models. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 6943–6951
work page 2021
- [21]
-
[22]
Nandan Thakur, Nils Reimers, Andreas Rücklé, Abhishek Srivastava, and Iryna Gurevych. 2021. BEIR: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models. InThirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track
work page 2021
-
[23]
Shuohang Wang, Yang Liu, Yichong Xu, Chenguang Zhu, and Michael Zeng. 2021. Want To Reduce Labeling Cost? GPT-3 Can Help.Findings of the Association for Computational Linguistics: EMNLP 2021(2021), 4195–4205
work page 2021
-
[24]
Self-Instruct: Aligning Language Models with Self-Generated Instructions
Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Daniel Khashabi, and Hannaneh Hajishirzi. 2023. Self-Instruct: Aligning Language Models with Self-Generated Instructions.arXiv preprint arXiv:2212.10560(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
Jason Wei and Kai Zou. 2019. EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks.Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing(2019), 6382– 6388
work page 2019
-
[26]
Lee Xiong, Chenyan Xiong, Ye Li, Kwok-Fung Tang, Jialin Liu, Paul Bennett, Junaid Ahmed, and Arnold Overwijk. 2021. Approximate Nearest Neighbor Neg- ative Contrastive Learning for Dense Text Retrieval. InInternational Conference on Learning Representations
work page 2021
-
[27]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, et al . 2023. Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena. InAdvances in Neural Information Processing Systems, Vol. 36. A Query Length Distribution Figure 3 shows word count distributions across all four datasets...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.