Conceptual Schema Inference for Tabular Datasets using Large Language Models
Pith reviewed 2026-05-25 04:44 UTC · model grok-4.3
The pith
Two LLM methods infer conceptual schemas of entity types, attributes and relationships from raw tables using only headers and cell values.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
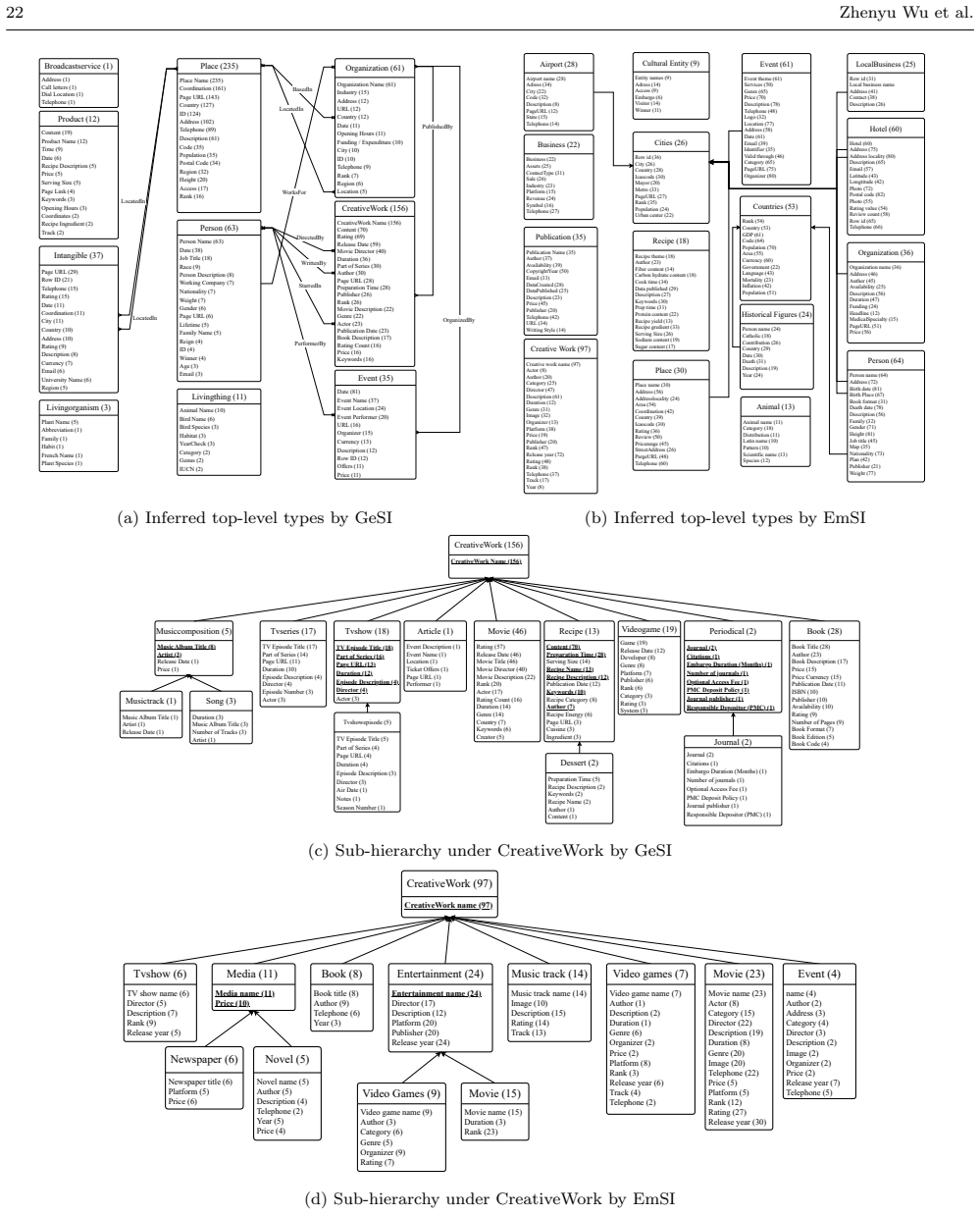
GeSI and EmSI are two large-language-model techniques that derive conceptual schemas directly from raw tables by inferring hierarchical entity types and attributes from column headers and cell values, with GeSI using generative models to integrate types into a global schema that also records relationships and EmSI using embeddings to group tables and construct hierarchies from shared attribute patterns.
What carries the argument
GeSI and EmSI: the generative-LLM and embedding-based LLM methods that turn table-level and column-level semantics into hierarchical entity types, attributes and inter-type relationships.
If this is right
- Conceptual schemas can be produced scalably for large heterogeneous repositories.
- Inferred schemas exhibit measurable conciseness and structural quality.
- Relationships across entity types are captured without manual intervention.
- End-to-end schema inference becomes feasible for web tables and open data portals.
Where Pith is reading between the lines
- The inferred schemas could serve as metadata that improves search and integration across data lakes.
- The grouping and generation steps might be combined with existing dataset-discovery tools to reduce manual curation.
- Accuracy of extracted relationships could rise further if the same models receive modest additional context from related tables.
- The same column-semantics approach may extend to other semi-structured formats that contain attribute-like fields.
Load-bearing premise
Large language models can reliably extract accurate hierarchical entity types, attributes and inter-type relationships solely from column headers and cell values without domain-specific fine-tuning or additional context.
What would settle it
A benchmark collection of tables supplied with expert ground-truth schemas on which either method produces entity-type hierarchies or relationships that show low overlap with the ground truth.
Figures









read the original abstract
Large collections of tabular data from data lakes, web tables and open data portals often originate from heterogeneous sources, leading to representational inconsistencies. Understanding and organizing such repositories therefore remains a major challenge. While prior work has primarily focused on dataset discovery and exploration, this paper addresses the complementary problem of conceptual schema inference: automatically deriving a conceptual schema that captures entity types, attributes and inter-type relationships directly from raw tables. We propose two large language model (LLM)-based approaches that use only column headers and cell values: GeSI uses generative LLMs to infer hierarchical types and their attributes from table- and column-level semantics, and to integrate them into a global schema that also captures relationships across types; EmSI employs LLM-based table embeddings to group tables by column-level semantics, infer attributes within each group, and construct hierarchical structures from shared attribute patterns. Finally, we report an experimental analysis demonstrating the effectiveness of our approaches in terms of the conciseness and structural quality of the inferred schema components, their scalability to large repositories, and a case study illustrating end-to-end schema inference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes two LLM-based methods for conceptual schema inference from heterogeneous tabular data in data lakes: GeSI, which uses generative prompting to derive hierarchical entity types, attributes, and cross-type relationships from column headers and cell values, and EmSI, which uses LLM embeddings to group tables by semantics, infer attributes, and build hierarchies from shared patterns. The central claim is that these zero-shot approaches produce concise, high-quality schemas scalably, supported by experimental analysis and a case study.
Significance. If the results hold with proper validation, the work addresses a practically important gap in data integration by automating conceptual schema extraction without domain ontologies or labeled data. Strengths include the dual-method design (generative vs. embedding) and focus on scalability to large repositories. However, the zero-shot reliance on LLMs without explicit consistency mechanisms limits immediate impact until robustness is demonstrated.
major comments (3)
- [Abstract / Methods] Abstract and Methods (inferred §3): The description of both GeSI and EmSI states that schemas are inferred 'directly from raw tables' using only headers and cell values, but provides no automated validation, majority voting, or post-processing to enforce invariants on hierarchies or relationships. This is load-bearing for the accuracy claim, as LLMs are known to produce inconsistent or spurious structures without such checks.
- [Experimental analysis] Experimental analysis (inferred §4): The abstract claims effectiveness on 'conciseness and structural quality' and scalability, but no specific metrics (e.g., precision/recall against ground truth, inter-annotator agreement, or comparison to baselines like rule-based or supervised schema inference), error analysis, or dataset details are visible. This undermines assessment of whether reported quality reflects reliable extraction or prompt artifacts.
- [Case study] Case study (inferred §5): The end-to-end illustration is presented as supporting evidence, but without quantitative comparison to manual schemas or discussion of failure modes (e.g., misaligned attributes across tables), it does not sufficiently address the central assumption of reliable extraction.
minor comments (2)
- [Introduction] Clarify notation for 'hierarchical types' and 'shared attribute patterns' early in the paper to avoid ambiguity between GeSI and EmSI outputs.
- [Related Work] Add references to prior LLM hallucination mitigation techniques in schema-related tasks (e.g., from NLP or data integration literature) to contextualize the approach.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major point below, indicating planned revisions to strengthen the presentation of our zero-shot LLM-based methods for conceptual schema inference.
read point-by-point responses
-
Referee: [Abstract / Methods] Abstract and Methods (inferred §3): The description of both GeSI and EmSI states that schemas are inferred 'directly from raw tables' using only headers and cell values, but provides no automated validation, majority voting, or post-processing to enforce invariants on hierarchies or relationships. This is load-bearing for the accuracy claim, as LLMs are known to produce inconsistent or spurious structures without such checks.
Authors: We acknowledge that our zero-shot design, which relies directly on LLM inference from headers and cell values without explicit consistency enforcement, leaves open the possibility of inconsistent hierarchies or relationships. This is a valid concern given known LLM behaviors. In the revised manuscript we will expand the Methods section to discuss this limitation explicitly and introduce lightweight post-processing (e.g., attribute-overlap-based deduplication of entity types and simple relationship validation) while preserving the zero-shot character of the core approaches. revision: yes
-
Referee: [Experimental analysis] Experimental analysis (inferred §4): The abstract claims effectiveness on 'conciseness and structural quality' and scalability, but no specific metrics (e.g., precision/recall against ground truth, inter-annotator agreement, or comparison to baselines like rule-based or supervised schema inference), error analysis, or dataset details are visible. This undermines assessment of whether reported quality reflects reliable extraction or prompt artifacts.
Authors: Section 4 reports dataset details (heterogeneous sources from data lakes and open portals) together with task-specific metrics: conciseness via counts of unique entity types/attributes, structural quality via hierarchy depth and cross-type relationship coverage, and scalability via runtime scaling experiments. Ground-truth schemas are rarely available at scale for such repositories, which is why we did not report precision/recall. We agree that adding an error analysis, inter-annotator agreement on a sampled subset, and comparisons against simple rule-based baselines would improve transparency; these will be included in the revision. revision: yes
-
Referee: [Case study] Case study (inferred §5): The end-to-end illustration is presented as supporting evidence, but without quantitative comparison to manual schemas or discussion of failure modes (e.g., misaligned attributes across tables), it does not sufficiently address the central assumption of reliable extraction.
Authors: The case study is intended as a qualitative demonstration of the full pipeline. We agree that quantitative comparison against manually constructed schemas on a limited scale and explicit discussion of observed failure modes (such as attribute misalignment) would provide stronger support. The revised §5 will incorporate these elements. revision: yes
Circularity Check
No circularity: empirical LLM method proposal with independent evaluation
full rationale
The paper proposes two LLM-based methods (GeSI and EmSI) for conceptual schema inference from tabular data using only headers and cell values. No equations, fitted parameters, derivations, or predictions are described that could reduce to inputs by construction. Claims rest on experimental analysis of conciseness, structural quality, and scalability, which is external validation rather than self-referential. No self-citation load-bearing steps, uniqueness theorems, or ansatzes appear in the abstract or method outline. The work is self-contained as an empirical proposal.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large language models can accurately capture entity types, attributes, and relationships from column headers and cell values alone
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.