XL-HD: Extended Learning in Hyperdimensional Computing via Deterministic Projections for In-Memory Accelerators
Pith reviewed 2026-06-30 00:16 UTC · model grok-4.3
The pith
XL-HD replaces random vectors in hyperdimensional computing with deterministic Sobol projections and real-valued prototype optimization before binarization to support efficient binary inference on in-memory hardware.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
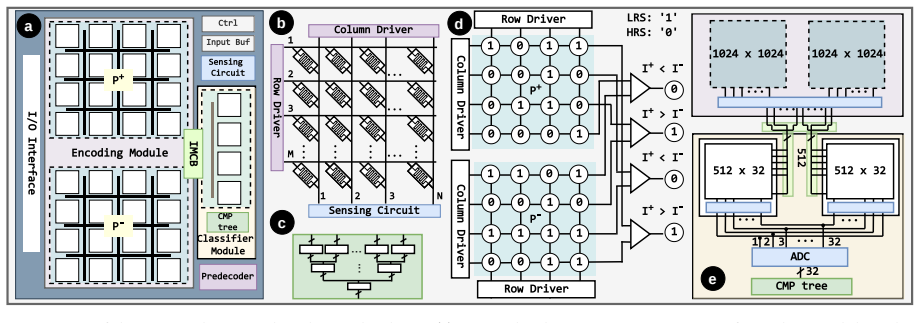
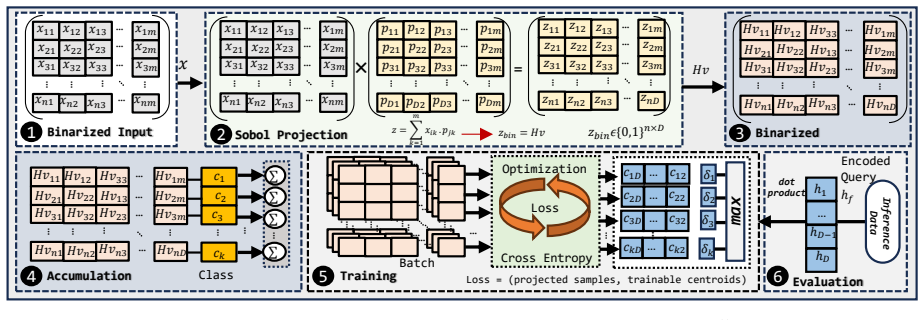
XL-HD is a deterministic projection-based fully learnable HDC framework that uses a fixed Sobol sequence to project binary inputs, optimizes class prototypes in real-valued space, and binarizes them afterward, thereby extending learning beyond conventional HDC while enabling a binary dot-product inference pipeline that is ideal for in-memory computing hardware such as ReRAM crossbars.
What carries the argument
Deterministic projection via a fixed Sobol sequence paired with real-valued prototype optimization followed by binarization, which together extend learning and produce a binary dot-product pipeline.
If this is right
- The method supports an entirely binary dot-product inference pipeline suited to ReRAM crossbars.
- Competitive accuracy is achieved on MNIST, UCIHAR, and ISOLET without large dimensionality or heuristic updates.
- The inference engine occupies 0.395 mm² area and consumes 0.40 μJ per single-cycle inference.
- Learning is extended beyond symbolic binding and pseudo-random vectors in HDC.
Where Pith is reading between the lines
- If Sobol projections preserve enough structure, the same deterministic replacement could be applied to other vector-symbolic architectures that currently rely on random vectors.
- Tuning the real-to-binary transition per dataset or hardware might yield additional energy reductions not explored in the current experiments.
- Testing the binarized pipeline on larger or more varied edge tasks would clarify whether the accuracy preservation generalizes beyond the three reported datasets.
Load-bearing premise
Optimizing prototypes in real-valued space and then binarizing them preserves accuracy when the resulting vectors are used in the binary dot-product pipeline on the tested datasets and hardware constraints.
What would settle it
A substantial accuracy drop below the reported competitive levels on MNIST, UCIHAR, or ISOLET when the binarized prototypes are applied in the binary dot-product inference pipeline would show the central claim does not hold.
Figures

read the original abstract
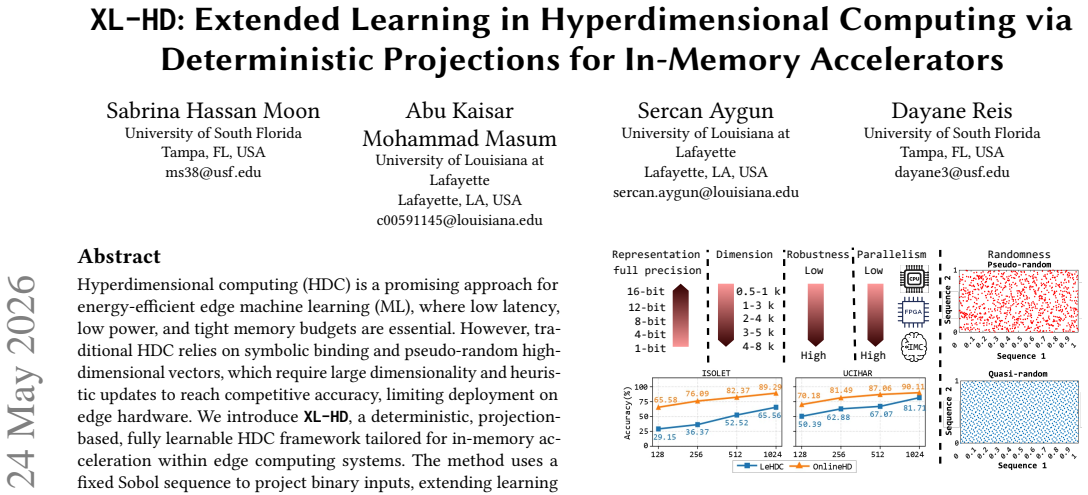
Hyperdimensional computing (HDC) is a promising approach for energy-efficient edge machine learning (ML), where low latency, low power, and tight memory budgets are essential. However, traditional HDC relies on symbolic binding and pseudo-random high-dimensional vectors, which require large dimensionality and heuristic updates to reach competitive accuracy, limiting deployment on edge hardware. We introduce XL-HD, a deterministic, projection-based, fully learnable HDC framework tailored for in-memory acceleration within edge computing systems. The method uses a fixed Sobol sequence to project binary inputs, extending learning beyond conventional HDC. During training, class prototypes are optimized in real-valued space and later binarized, enabling an entirely binary dot-product inference pipeline ideal for IMC hardware such as ReRAM crossbars. XL-HD achieves competitive accuracy on MNIST, UCIHAR, and ISOLET while maintaining a compact IMC-based inference engine with $0.395 \ \text{mm}^2$ area and only $0.40 \ \mu\text{J}$ per single-cycle inference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces XL-HD, a deterministic projection-based fully learnable HDC framework for in-memory accelerators. It employs a fixed Sobol sequence to project binary inputs, optimizes class prototypes in real-valued space during training, and binarizes them to enable an entirely binary dot-product inference pipeline suitable for IMC hardware such as ReRAM crossbars. The work claims competitive accuracy on MNIST, UCIHAR, and ISOLET while reporting a compact inference engine with 0.395 mm² area and 0.40 μJ per single-cycle inference.
Significance. If the binarization step preserves accuracy as claimed, the approach could meaningfully advance energy-efficient edge ML by extending learnable HDC to IMC-compatible binary pipelines without relying on large dimensionality or heuristic updates typical of traditional HDC. The deterministic projections and real-to-binary optimization represent a targeted contribution for hardware-constrained deployment if the accuracy transfer is demonstrated.
major comments (2)
- [Abstract] Abstract: the central claim of competitive accuracy on MNIST/UCIHAR/ISOLET under the deployed binary dot-product pipeline rests on the unverified assumption that real-valued prototype optimization followed by binarization preserves performance; no pre/post-binarization accuracy numbers, ablation studies, or binarization rule (threshold, scaling, etc.) are supplied, rendering the accuracy and hardware-compatibility claims unverifiable from the given information.
- [Abstract] Abstract: competitive accuracy is asserted without any baselines, error bars, dataset splits, or exclusion rules, which is load-bearing for the accuracy claim and prevents assessment of whether the reported results are meaningful relative to prior HDC or ML methods.
Simulated Author's Rebuttal
Thank you for the constructive feedback on the abstract and verifiability of our claims. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of competitive accuracy on MNIST/UCIHAR/ISOLET under the deployed binary dot-product pipeline rests on the unverified assumption that real-valued prototype optimization followed by binarization preserves performance; no pre/post-binarization accuracy numbers, ablation studies, or binarization rule (threshold, scaling, etc.) are supplied, rendering the accuracy and hardware-compatibility claims unverifiable from the given information.
Authors: We agree the abstract omits explicit pre/post-binarization numbers and the precise rule. The full manuscript (Section 3.2) specifies real-valued prototype optimization followed by sign-based binarization to enable binary dot-products, but does not report the requested ablations or paired accuracies. We will add a results table with pre- and post-binarization accuracies on all three datasets plus an ablation on the binarization threshold, and update the abstract to reference these findings. revision: yes
-
Referee: [Abstract] Abstract: competitive accuracy is asserted without any baselines, error bars, dataset splits, or exclusion rules, which is load-bearing for the accuracy claim and prevents assessment of whether the reported results are meaningful relative to prior HDC or ML methods.
Authors: The manuscript body (Table II and Section 4) already presents comparisons against prior HDC and ML baselines (e.g., SVM, MLP, and recent HDC variants), reports mean accuracies with standard deviations over five runs, and uses standard dataset splits (60k/10k for MNIST, 70/30 for UCIHAR, etc.). The abstract, however, does not cite these. We will revise the abstract to include concrete accuracy figures and a brief reference to the baselines while retaining the hardware metrics. revision: partial
Circularity Check
No significant circularity; abstract contains no equations or load-bearing derivations
full rationale
The provided abstract describes an optimization-then-binarization procedure for prototypes and reports empirical accuracy/hardware results, but supplies no equations, self-citations, or derivation steps that could be inspected for reduction to inputs by construction. No fitted-input-called-prediction, self-definitional, or uniqueness-imported patterns are visible. The reader's note that no equations appear confirms the derivation chain cannot be walked; the default non-circular finding applies.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Kaushik Roy, Indranil Chakraborty, Mustafa Ali, Aayush Ankit, and Amogh Agrawal. 2020. In-memory computing in emerging memory technologies for machine learning: an overview. In2020 57th ACM/IEEE Design Automation Conference (DAC). IEEE, 1–6
2020
-
[2]
Denis Kleyko, Dmitri Rachkovskij, Evgeny Osipov, and Abbas Rahimi. 2023. A survey on hyperdimensional computing aka vector symbolic architectures, part ii: applications, cognitive models, and challenges. 55, 9. doi:10.1145/3558000
-
[3]
Hassan Najafi, and Mohsen Imani
Sercan Aygun, Mehran Shoushtari Moghadam, M. Hassan Najafi, and Mohsen Imani. 2023. Learning from hypervectors: a survey on hypervector encoding. (2023). https://arxiv.org/abs/2308.00685 arXiv: 2308.00685[cs.LG]
-
[4]
Hassan Najafi, Dayane Reis, and Sercan 6 Aygun
Abu Kaisar Mohammad Masum, Mehran Shoushtari Moghadam, Sabrina Has- san Moon, Ahmed Mamdouh, M. Hassan Najafi, Dayane Reis, and Sercan 6 Aygun. 2025. Late breaking results: on-the-fly hadamard hypervector process- ing for efficient hyperdimensional computing. InProceedings of the 62nd Design Automation Conference (DAC’25). (June 2025)
2025
-
[5]
Abbas Rahimi, Pentti Kanerva, and Jan M Rabaey. 2016. A robust and energy- efficient classifier using brain-inspired hyperdimensional computing. InISLPED, 64–69
2016
-
[6]
Alejandro Hernández-Cano, Namiko Matsumoto, Eric Ping, and Mohsen Imani
-
[7]
In2021 Design, Automation & Test in Europe Conference & Exhibition (DATE)
Onlinehd: robust, efficient, and single-pass online learning using hyper- dimensional system. In2021 Design, Automation & Test in Europe Conference & Exhibition (DATE). IEEE, 56–61
-
[8]
Shijin Duan, Yejia Liu, Shaolei Ren, and Xiaolin Xu. 2022. Lehdc: learning-based hyperdimensional computing classifier. InProceedings of the 59th ACM/IEEE Design Automation Conference(DAC ’22). Association for Computing Machin- ery, San Francisco, California, 1111–1116.isbn: 9781450391429. doi:10.1145/34 89517.3530593
work page doi:10.1145/34 2022
-
[9]
Weihong Xu, Jaeyoung Kang, and Tajana Rosing. 2023. Fsl-hd: accelerating few-shot learning on reram using hyperdimensional computing. In2023 Design, Automation & Test in Europe Conference & Exhibition (DATE). IEEE, 1–6
2023
-
[10]
Cong Liu et al. 2024. A reram-based processing-in-memory architecture for hyperdimensional computing.IEEE TCAD
2024
-
[11]
Sabrina Hassan Moon, Ahmed Ahmed, Abu Kaisar Mohammad Masum, Sercan Aygun, and Dayane Reis. 2025. Rex-hd: a deterministic reram-based hyperdi- mensional computing framework for edge computing. InProceedings of the Great Lakes Symposium on VLSI 2025, 568–574
2025
-
[12]
Anthony Thomas, Sanjoy Dasgupta, and Tajana Rosing. 2021. A theoretical perspective on hyperdimensional computing.Journal of Artificial Intelligence Research, 72, 215–249
2021
-
[13]
Arman Kazemi, Franz Müller, Mohammad Mehdi Sharifi, Hamza Errahmouni, Gerald Gerlach, Thomas Kämpfe, Mohsen Imani, Xiaobo Sharon Hu, and Michael Niemier. 2022. Achieving software-equivalent accuracy for hyperdi- mensional computing with ferroelectric-based in-memory computing.Scientific Reports, 12, 1, (Nov. 2022), 19201. doi:10.1038/s41598-022-23116-w
-
[14]
Mehran Shoushtari Moghadam, Sercan Aygun, and M. Hassan Najafi. 2023. No- multiplication deterministic hyperdimensional encoding for resource-constrained devices.IEEE Embedded Systems Letters, 15, 4, 210–213. doi:10.1109/LES.2023.3 298732
-
[15]
Dayane Reis, Michael Niemier, and X Sharon Hu. 2018. Computing in mem- ory with fefets. InProceedings of the international symposium on low power electronics and design, 1–6
2018
-
[16]
Abu Sebastian, Manuel Le Gallo, Riduan Khaddam-Aljameh, and Evangelos Eleftheriou. 2020. Memory devices and applications for in-memory computing. Nature nanotechnology, 15, 7, 529–544
2020
-
[17]
Ping Chi, Shuangchen Li, Cong Xu, Tao Zhang, Jishen Zhao, Yongpan Liu, Yu Wang, and Yuan Xie. 2016. Prime: a novel processing-in-memory architecture for neural network computation in reram-based main memory.ACM SIGARCH Computer Architecture News, 44, 3, 27–39
2016
-
[18]
Dayane Reis et al. 2019. Design and analysis of an ultra-dense, low-leakage, and fast fefet-based random access memory array.IEEE Journal on Exploratory Solid-State Computational Devices and Circuits, 5, 2, 103–112
2019
-
[19]
Sabrina Hassan Moon and Dayane Reis. 2024. Afecam: an energy efficient analog 1fefet content addressable memory. InGLSVLSI 2024, 541–545
2024
-
[20]
Manuel Eggimann, Abbas Rahimi, and Luca Benini. 2021. A 5 𝜇w standard cell memory-based configurable hyperdimensional computing accelerator for always-on smart sensing.IEEE Transactions on Circuits and Systems I: Regular Papers, 68, 10, 4116–4128
2021
-
[21]
Ruixuan Wang, Sabrina Hassan Moon, Xiaobo Sharon Hu, Xun Jiao, and Dayane Reis. 2024. A computing-in-memory-based one-class hyperdimensional com- puting model for outlier detection.IEEE Transactions on Computers, 73, 6, 1559– 1574
2024
-
[22]
Ahmed Mamdouh and Dayane Reis. 2025. Hide: a hyperdimensional in-dram encoder for fast and energy-efficient classification. In2025 26th International Symposium on Quality Electronic Design (ISQED). IEEE, 1–7
2025
-
[23]
Qingrong Huang, Zeyu Yang, Kai Ni, Mohsen Imani, Cheng Zhuo, and Xunzhao Yin. 2023. Fefet-based in-memory hyperdimensional encoding design.IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 42, 11, 3829–3839
2023
-
[24]
Sercan Aygun and M Hassan Najafi. 2024. Sobol sequence optimization for hardware-efficient vector symbolic architectures.IEEE Transactions on Computer- Aided Design of Integrated Circuits and Systems
2024
-
[25]
Pere Vergés, Mike Heddes, Igor Nunes, Denis Kleyko, Tony Givargis, and Alexandru Nicolau. 2025. Classification using hyperdimensional computing: a review with comparative analysis.Artificial Intelligence Review, 58, 6, 173
2025
-
[26]
X Tang and K-P Pun. 2009. High-performance cmos current comparator.Elec- tronics Letters, 45, 20, 1007–1009
2009
-
[27]
Zizhen Jiang, Yi Wu, Shimeng Yu, Lin Yang, Kay Song, Zia Karim, and H-S Philip Wong. 2016. A compact model for metal–oxide resistive random access memory with experiment verification.IEEE Transactions on Electron Devices, 63, 5, 1884–1892
2016
-
[28]
Jesper Knudsen. 2008. Nangate 45nm open cell library.CDNLive, EMEA
2008
-
[29]
Pai-Yu Chen, Xiaochen Peng, and Shimeng Yu. 2018. Neurosim: a circuit-level macro model for benchmarking neuro-inspired architectures in online learning. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 37, 12, 3067–3080
2018
-
[30]
Sujan K Gonugondla, Ameya D Patil, and Naresh R Shanbhag. 2020. Swipe: enhancing robustness of reram crossbars for in-memory computing. InPro- ceedings of the 39th International Conference on Computer-Aided Design, 1– 9
2020
-
[31]
Pentti Kanerva. 2009. Hyperdimensional computing: an introduction to com- puting in distributed representation with high-dimensional random vectors. Cognitive computation, 1, 139–159
2009
-
[32]
Mohsen Imani, Xunzhao Yin, John Messerly, Saransh Gupta, Michael Niemier, Xiaobo Sharon Hu, and Tajana Rosing. 2019. Searchd: a memory-centric hy- perdimensional computing with stochastic training.IEEE TCAD, 39, 10, 2422– 2433
2019
-
[33]
Mohsen Imani, Samuel Bosch, Sohum Datta, Sharadhi Ramakrishna, Sahand Salamat, Jan M Rabaey, and Tajana Rosing. 2019. Quanthd: a quantization framework for hyperdimensional computing.IEEE TCAD, 39, 10, 2268–2278
2019
-
[34]
Mohsen Imani, John Messerly, Fan Wu, Wang Pi, and Tajana Rosing. 2019. A binary learning framework for hyperdimensional computing. In2019 Design, Automation & Test in Europe Conference & Exhibition (DATE). IEEE, 126–131
2019
-
[35]
Yann Lecun. 1995. Mnist. https://api.openml.org/d/554. Accessed: 2024-11-22. (1995)
1995
-
[36]
Andrew Frank. 2010. Uci machine learning repository.http://archive. ics. uci. edu/ml
2010
-
[37]
Davide Anguita, Alessandro Ghio, Luca Oneto, Xavier Parra, and Jorge L Reyes- Ortiz. 2012. Human activity recognition on smartphones using a multiclass hardware-friendly support vector machine. InInternational workshop on ambi- ent assisted living. Springer, 216–223
2012
-
[38]
Rajeev Balasubramonian, Andrew B Kahng, Naveen Muralimanohar, Ali Shafiee, and Vaishnav Srinivas. 2017. Cacti 7: new tools for interconnect exploration in innovative off-chip memories.ACM Transactions on Architecture and Code Optimization (TACO), 14, 2, 1–25
2017
-
[39]
Weihong Xu, Sean Fuhrman, Keming Fan, Sumukh Pinge, Wei-Chen Chen, and Tajana Rosing. 2025. Hypermetric: efficient hyperdimensional computing with metric learning for robust edge intelligence.IEEE Transactions on Computer- Aided Design of Integrated Circuits and Systems
2025
-
[40]
Satyabrata Sarangi and Bevan Baas. 2021. Deepscaletool: a tool for the accurate estimation of technology scaling in the deep-submicron era. In2021 IEEE International Symposium on Circuits and Systems (ISCAS). IEEE, 1–5
2021
-
[41]
Behnam Khaleghi, Hanyang Xu, Justin Morris, and Tajana Šimunić Rosing
-
[42]
In2021 Design, Automation & Test in Europe Conference & Exhibition (DATE)
Tiny-hd: ultra-efficient hyperdimensional computing engine for iot ap- plications. In2021 Design, Automation & Test in Europe Conference & Exhibition (DATE). IEEE, 408–413
-
[43]
Behnam Khaleghi, Jaeyoung Kang, Hanyang Xu, Justin Morris, and Tajana Rosing. 2022. Generic: highly efficient learning engine on edge using hyperdi- mensional computing. InProceedings of the 59th ACM/IEEE Design Automation Conference, 1117–1122. 7
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.