Sampling Distributions as Regularization in Learned Inverse Problems
Pith reviewed 2026-06-29 23:30 UTC · model grok-4.3
The pith
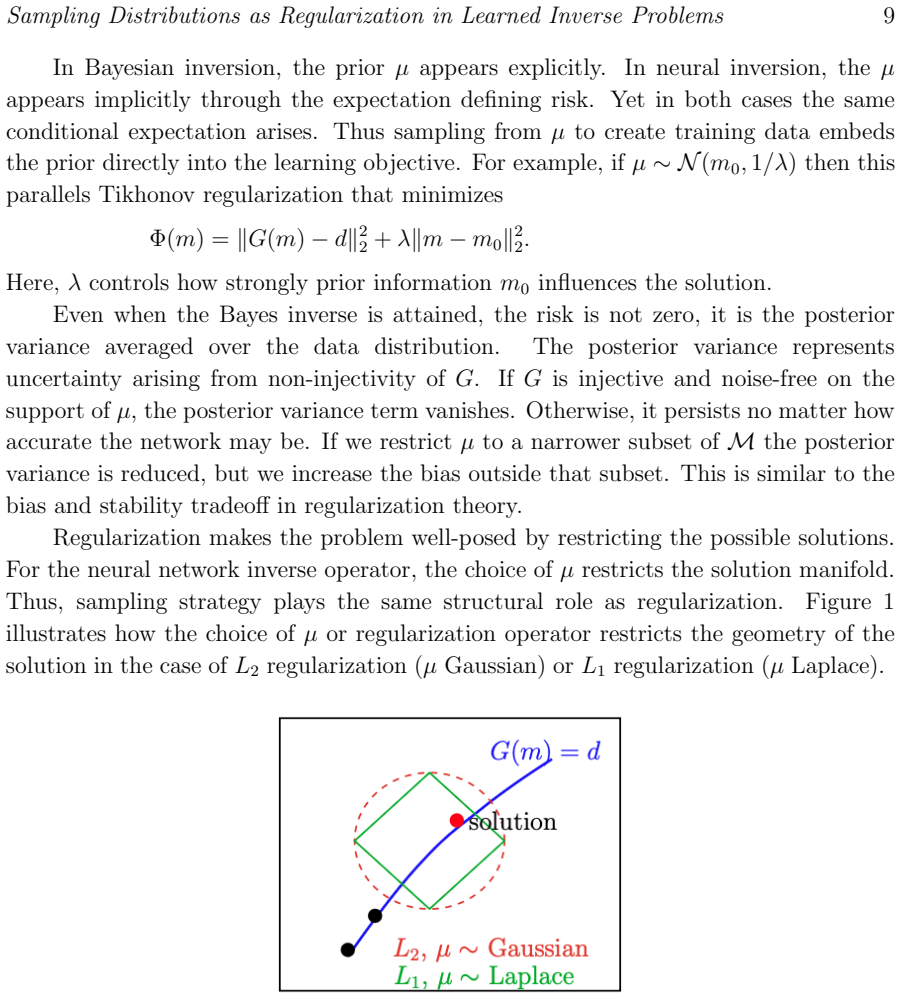
Sampling parameters from the forward model to create synthetic training data defines an implicit regularization operator on the learned inverse map.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
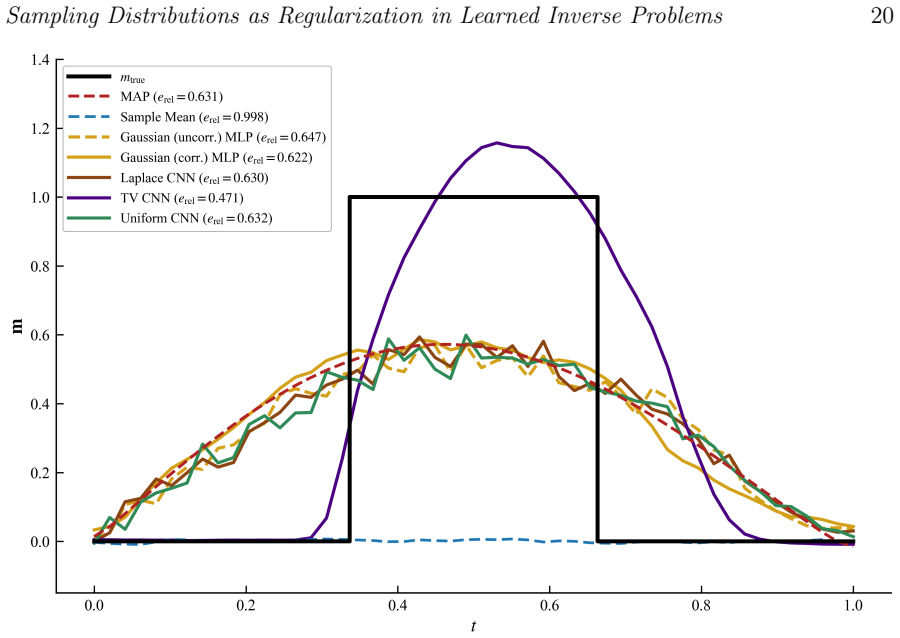
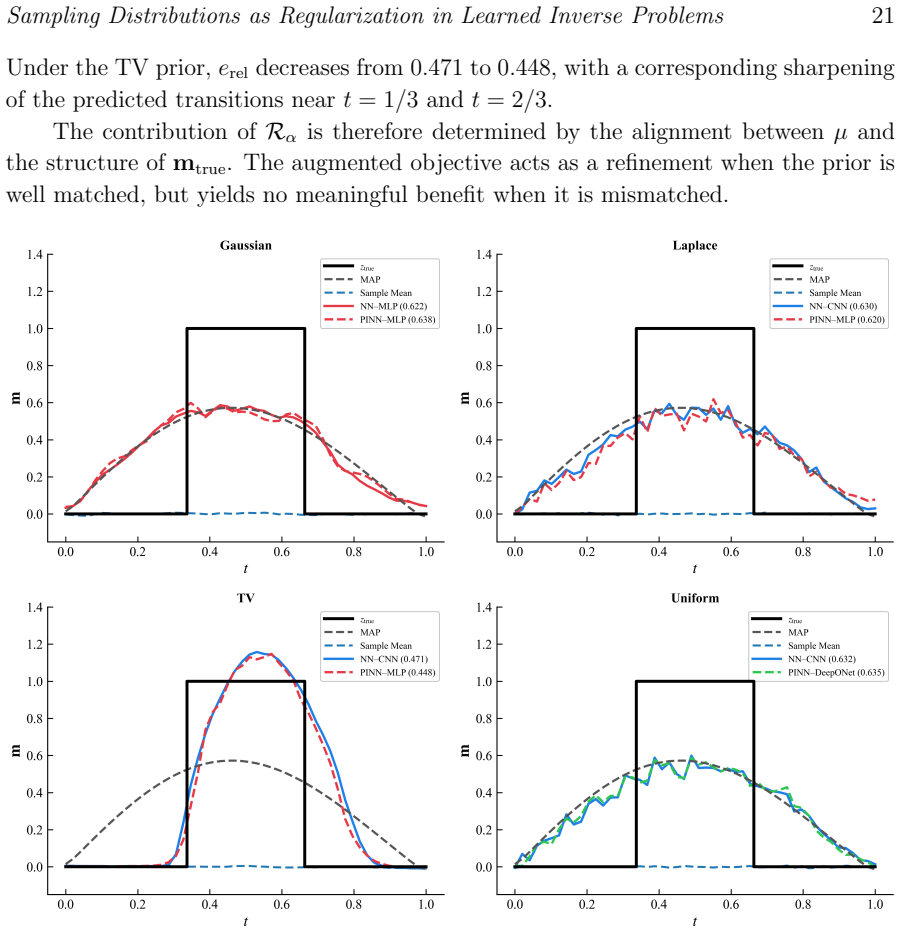
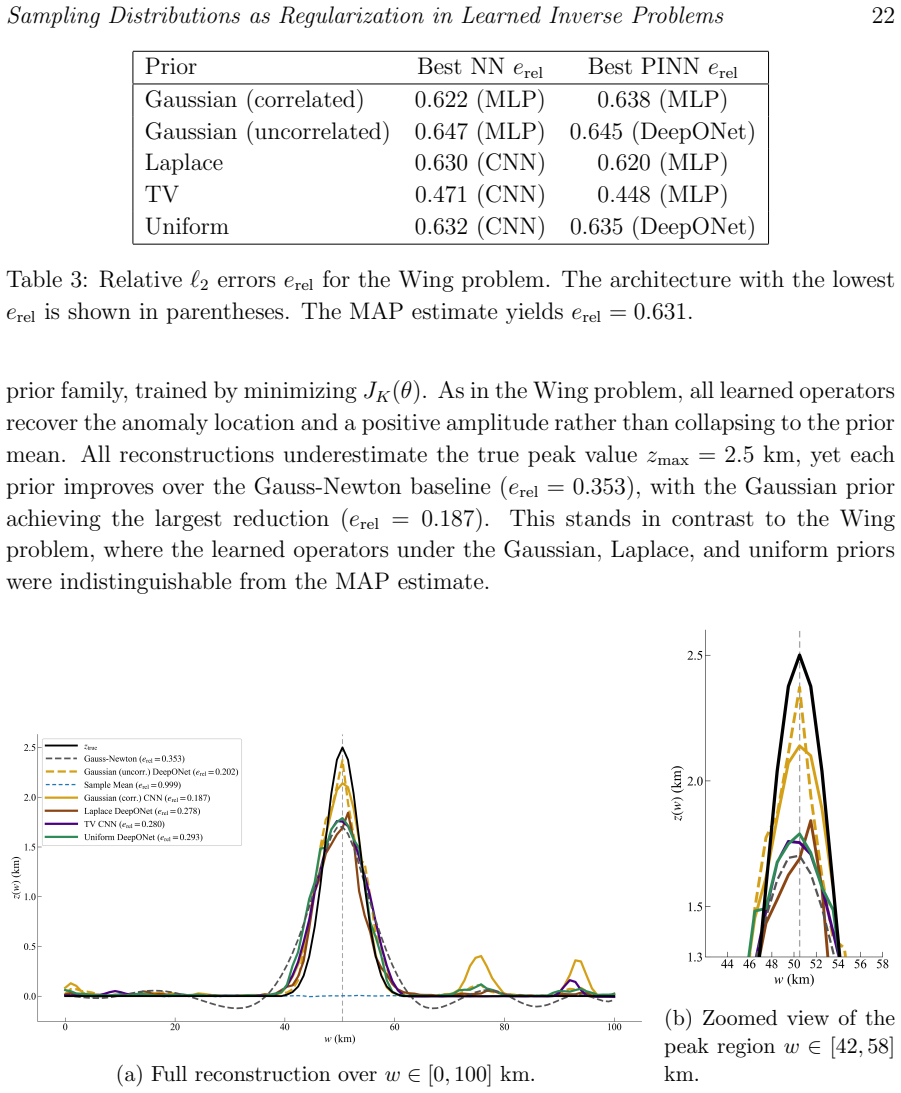
The learned inverse operator obtained by empirical-risk minimization on pairs generated by sampling parameters from the forward model converges to the conditional expectation of the parameters given the observations; this conditional expectation is itself an implicit regularization operator whose form is determined by the sampling measure. The same mechanism applies to physics-informed neural networks. In finite samples the operator remains influenced by the sampling distribution, and mismatched sampling produces reconstruction errors that neither richer architectures nor additional physics residuals can eliminate.
What carries the argument
The implicit regularization operator induced by the sampling distribution used to generate training pairs (synthetic observations, true parameters) from the forward model.
If this is right
- In the infinite-data limit the learned map equals the conditional expectation under the chosen sampling measure.
- Finite-data training still inherits bias from the sampling distribution in addition to architectural and physics-informed effects.
- A mismatched sampling distribution produces persistent reconstruction artifacts that cannot be removed by increasing network capacity or adding physics residuals alone.
- The sampling distribution must be designed with the same attention given to a classical regularization functional.
Where Pith is reading between the lines
- One could deliberately engineer sampling distributions to realize target regularization operators that are difficult to express as explicit penalties.
- The same sampling-induced regularization may appear in any learned inverse method that generates its own training pairs from a forward simulator, not only neural networks.
- In practice, validation on held-out synthetic or real data could be used to tune the sampling distribution itself rather than only the network weights.
Load-bearing premise
The neural inverse operator is trained by minimizing empirical risk on input-output pairs that are generated by sampling parameters from the forward model.
What would settle it
Train the same network architecture on the same three test problems but replace the original sampling distribution with one that differs only in its moments; if the reconstruction error does not change in the manner predicted by the conditional-expectation formula while architecture and physics terms are held fixed, the claim is falsified.
Figures
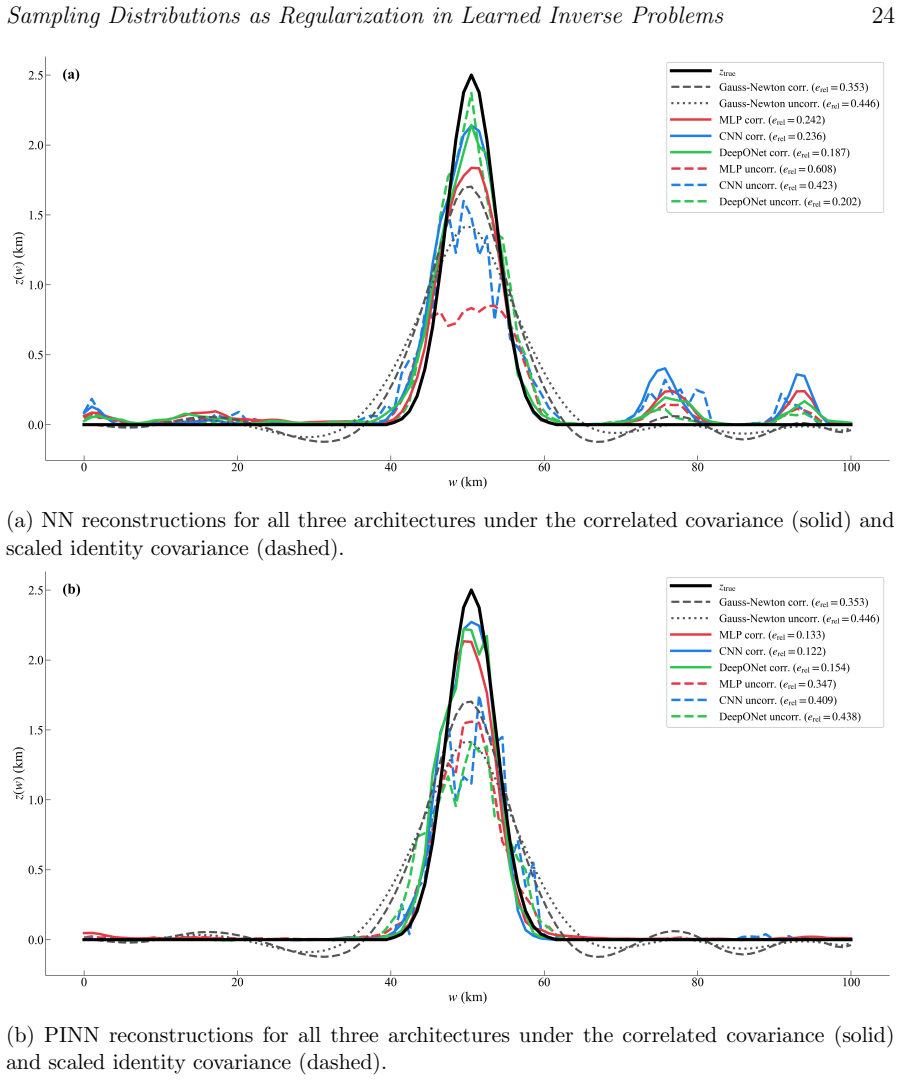
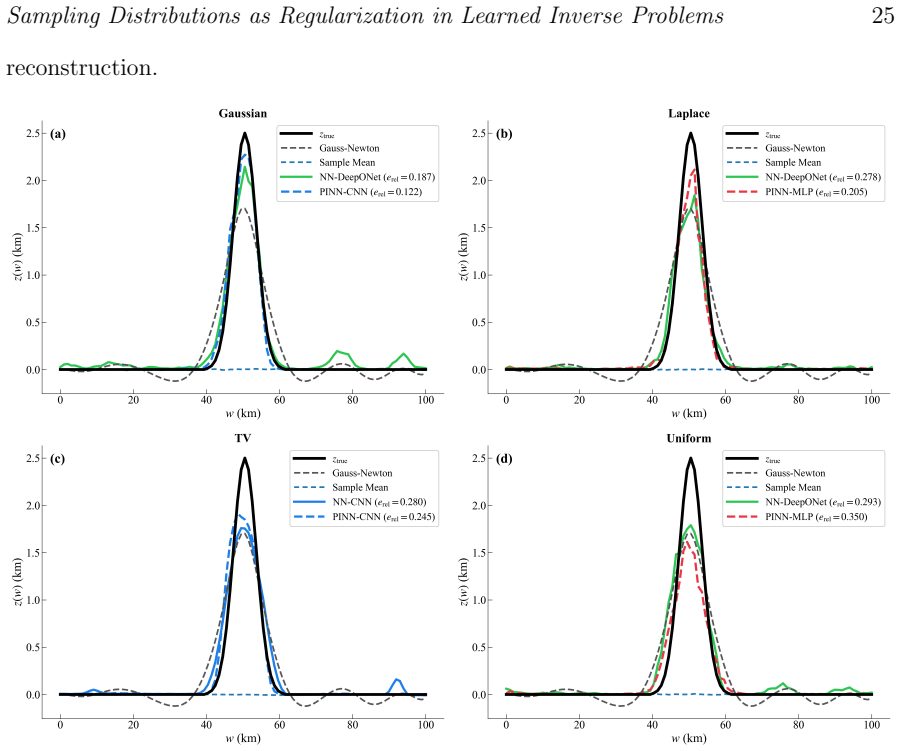
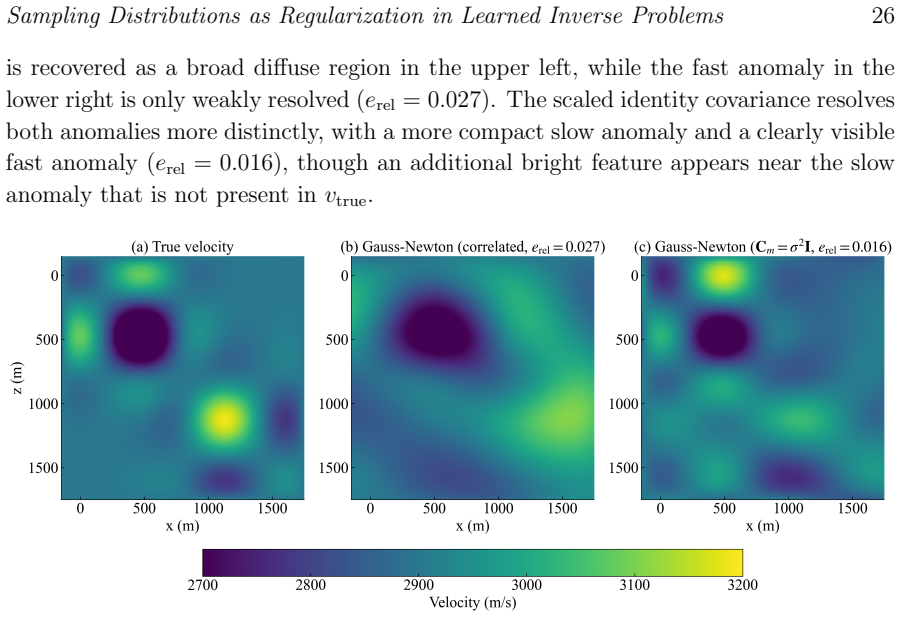
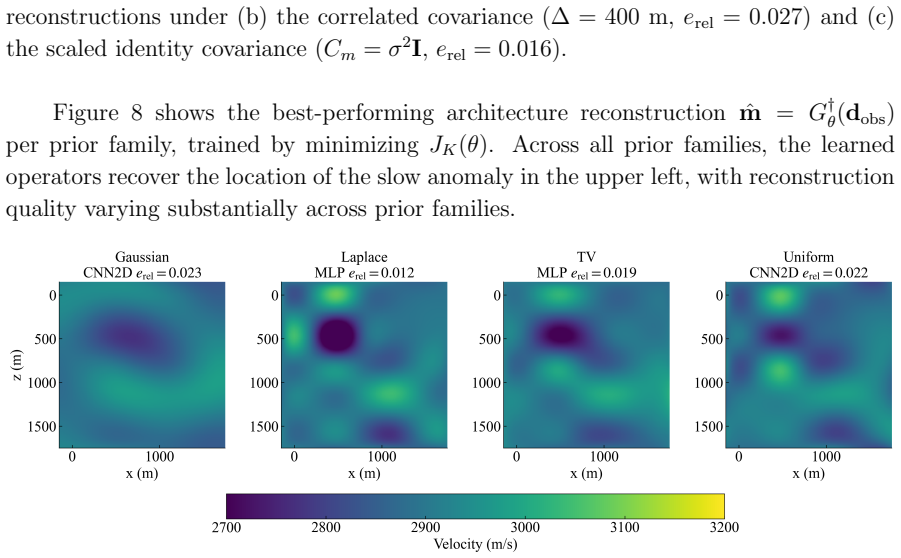
read the original abstract
Neural networks have emerged as effective tools for solving ill-posed inverse problems. In many scientific applications, however, observational training data are insufficient, and learned inverse operators must instead be trained on synthetic data generated from the forward model. This requires specifying unknown parameters in the forward model and solving the model to generate synthetic observations. Typically, the unknown parameters are sampled from a prescribed probability distribution. Here, we show that this sampling strategy is not a neutral preprocessing step, but instead defines an implicit regularization operator. This result follows from the fact that the learned inverse operator minimizes empirical risk together with the classical result that conditional expectation minimizes mean-square error. We present theoretical results for the implicit regularization operator in both infinite- and finite-data settings, including Physics Informed Neural Networks (PINNs). These results are demonstrated numerically on three inverse problems of increasing complexity: a 1D linear Fredholm integral equation, a 1D nonlinear subsurface interface inversion, and a 2D nonlinear cross-well seismic traveltime tomography problem. Across all three problems, three distinct sources of regularization are identified in the learned operator: prior sampling, architectural, and physics-informed regularization. A mismatched sampling distribution is shown to degrade reconstruction quality in ways that neither more expressive architectures nor augmented physics residuals can fully correct. The results demonstrate that the sampling distribution should be chosen with the same care as a classical regularization functional and provide a practical framework for implementing more sophisticated regularization operators using neural networks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that the choice of sampling distribution for generating synthetic training pairs (observations, parameters) from a forward model is not neutral but defines an implicit regularization operator on the learned inverse. This follows because the neural network minimizes empirical risk (MSE) on those pairs and the conditional expectation E[parameter | observation] under the sampling measure is the unique minimizer of population MSE. Theoretical results are derived for both infinite- and finite-data regimes and are stated to extend to Physics-Informed Neural Networks; the claim is illustrated on three inverse problems of increasing complexity, with the sampling distribution, network architecture, and physics residual each identified as distinct regularization sources.
Significance. If the central equivalence holds, the result is significant because it supplies a precise statistical interpretation of a ubiquitous but rarely analyzed preprocessing choice in learned inverse problems, elevating parameter sampling to the same status as an explicit regularization functional. The explicit identification of three regularization mechanisms and the demonstration that a mismatched prior cannot be fully compensated by architecture or physics terms are practically useful. The paper receives credit for stating results in both population and finite-sample settings and for including PINNs within the theoretical scope.
major comments (2)
- [theoretical results for PINNs] The section presenting theoretical results for PINNs: the central derivation equates the learned operator to the conditional expectation because the network minimizes empirical MSE on (observation, parameter) pairs. Standard PINN training, however, minimizes a physics-residual loss over collocation points (plus optional data misfit) without an explicit supervised term ||NN(obs) - true_param||^2. The manuscript must supply the additional argument showing that the residual objective induces the same population risk; without it the inclusion of PINNs in the theoretical claims is not supported.
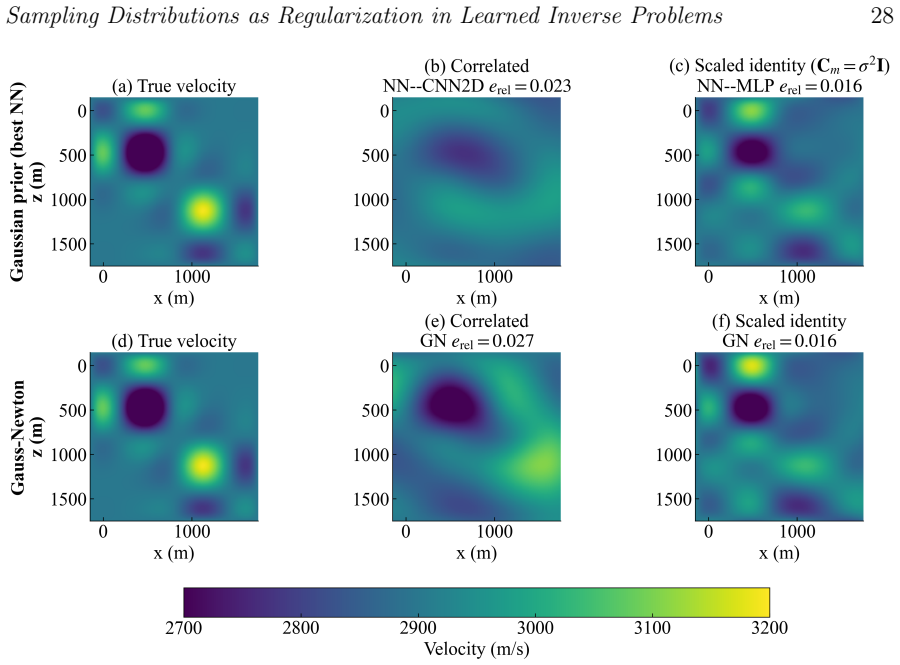
- [numerical experiments] Numerical experiments on the three inverse problems (1D Fredholm, 1D subsurface, 2D cross-well tomography): the claim that mismatched sampling degrades reconstructions in ways that neither more expressive architectures nor augmented physics residuals can fully correct is load-bearing for the practical recommendation. The experiments must demonstrate that the architecture and physics variants were varied while holding the sampling distribution fixed at the mismatched choice; otherwise the separation of the three regularization sources is not cleanly established.
minor comments (2)
- [theoretical development] Notation for the sampling distribution and the induced measure on observations should be introduced once and used consistently; the current alternation between p( heta) and the push-forward measure occasionally obscures whether statements refer to the parameter prior or the induced observation distribution.
- [figures] Figure captions for the reconstruction-error plots should state the precise sampling distributions used in each panel so that the mismatch experiments can be reproduced without consulting the main text.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive comments, which help clarify the scope of our theoretical claims and the presentation of the experiments. We respond to each major comment below.
read point-by-point responses
-
Referee: [theoretical results for PINNs] The section presenting theoretical results for PINNs: the central derivation equates the learned operator to the conditional expectation because the network minimizes empirical MSE on (observation, parameter) pairs. Standard PINN training, however, minimizes a physics-residual loss over collocation points (plus optional data misfit) without an explicit supervised term ||NN(obs) - true_param||^2. The manuscript must supply the additional argument showing that the residual objective induces the same population risk; without it the inclusion of PINNs in the theoretical claims is not supported.
Authors: We agree that the core derivation relies on minimization of the supervised empirical MSE, which yields the conditional expectation. The manuscript states that the results extend to PINNs, but does not supply a separate argument showing that a pure residual loss induces equivalent population risk. In revision we will either restrict the theoretical statements to supervised settings or add the required argument, for example by considering PINN formulations that incorporate a parameter data-misfit term or by analyzing the residual objective in the limit of the inverse problem. We will include this clarification as a new subsection. revision: yes
-
Referee: [numerical experiments] Numerical experiments on the three inverse problems (1D Fredholm, 1D subsurface, 2D cross-well tomography): the claim that mismatched sampling degrades reconstructions in ways that neither more expressive architectures nor augmented physics residuals can fully correct is load-bearing for the practical recommendation. The experiments must demonstrate that the architecture and physics variants were varied while holding the sampling distribution fixed at the mismatched choice; otherwise the separation of the three regularization sources is not cleanly established.
Authors: The experiments were performed by holding the sampling distribution fixed at each mismatched choice while separately varying architecture (depth, width, activations) and physics residuals (added or removed terms, different collocation densities). These controlled comparisons appear in the result figures for all three problems. To make the isolation of regularization sources explicit, we will add direct statements in the text and figure captions confirming that sampling remains fixed in the architecture and physics variants. This will strengthen the presentation without altering the experimental design. revision: partial
Circularity Check
No circularity; derivation applies standard conditional-expectation property to ERM objective
full rationale
The paper's central claim states that sampling defines implicit regularization because the learned operator minimizes empirical risk and conditional expectation minimizes MSE. This is a direct invocation of a classical, externally verifiable result (not derived within the paper) applied to the supervised training objective on synthetic pairs. No step reduces a prediction to a fitted input by construction, renames a known result, or relies on a load-bearing self-citation chain. The extension to PINNs is asserted under the paper's stated assumptions without exhibiting a self-referential reduction. The derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- parameter sampling distribution
axioms (1)
- standard math conditional expectation minimizes mean-square error
Reference graph
Works this paper leans on
-
[1]
Andrew M. Stuart. Inverse problems: A bayesian perspective.Acta Numerica, 19:451–559, 2010
2010
-
[2]
Masoumeh Dashti and Andrew M. Stuart. The bayesian approach to inverse problems. In Roger Ghanem, Dave Higdon, and Houman Owhadi, editors,Handbook of Uncertainty Quantification, pages 311–428. Springer, 2017
2017
-
[3]
Solving inverse problems using data-driven models.Acta Numerica, 28:1–174, 2019
Simon Arridge, Peter Maass, Ozan ¨Oktem, and Carola-Bibiane Sch¨ onlieb. Solving inverse problems using data-driven models.Acta Numerica, 28:1–174, 2019
2019
-
[4]
Learned primal-dual reconstruction.IEEE Transactions on Medical Imaging, 37(6):1322–1332, 2018
Jonas Adler and Ozan ¨Oktem. Learned primal-dual reconstruction.IEEE Transactions on Medical Imaging, 37(6):1322–1332, 2018
2018
-
[5]
Wainwright.High-Dimensional Statistics: A Non-Asymptotic Viewpoint
Martin J. Wainwright.High-Dimensional Statistics: A Non-Asymptotic Viewpoint. Cambridge University Press, 2019
2019
-
[6]
Andreas Hauptmann, Simon Arridge, Felix Lucka, Vivek Muthurangu, and Jennifer A. Steeden. Real-time cardiovascular mri reconstruction using deep learning.Magnetic Resonance in Medicine, 79(3):1374–1383, 2018
2018
-
[7]
Stuart, and Anima Anandkumar
Nikola Kovachki, Zongyi Li, Burigede Liu, Kamyar Azizzadenesheli, Kaushik Bhattacharya, Andrew M. Stuart, and Anima Anandkumar. Neural operator: Learning maps between function spaces.Journal of Machine Learning Research, 24(89):1–97, 2023
2023
-
[8]
Ashish Bora, Ajil Jalal, Eric Price, and Alexandros G. Dimakis. Compressed sensing using generative models. InProceedings of the 34th International Conference on Machine Learning (ICML), pages 537–546, 2017
2017
-
[9]
Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole
Yang Song, Jascha Sohl-Dickstein, Diederik P. Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. International Conference on Learning Representations (ICLR), 2021
2021
-
[10]
Mead and R.A
J.L. Mead and R.A. Renaut. Least squares problems with inequality constraints as quadratic constraints.Linear Algebra and Its Applications, 432(8):1936–1949, 2010
1936
-
[11]
On the well-posedness of bayesian inverse problems.SIAM/ASA Journal on Uncertainty Quantification, 8(1):451–482, 2020
Jonas Latz. On the well-posedness of bayesian inverse problems.SIAM/ASA Journal on Uncertainty Quantification, 8(1):451–482, 2020
2020
-
[12]
Maziar Raissi, Paris Perdikaris, and George E Karniadakis. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations.Journal of Computational Physics, 378:686–707, 2019
2019
-
[13]
Physics-informed neural networks to solve inverse problems in unbounded domains, 2025
Gregorio P´ erez-Bernal, Oscar Rinc´ on-Carde˜ no, Silvana Montoya-Noguera, and Nicol´ as Guar´ ın-Zapata. Physics-informed neural networks to solve inverse problems in unbounded domains, 2025
2025
-
[14]
Adams, and George Em Karniadakis
Ameya Dilip Jagtap, Zhiping Mao, Nikolaus A. Adams, and George Em Karniadakis. Physics-informed neural networks for inverse problems in supersonic flows.ArXiv, abs/2202.11821, 2022
-
[15]
Springer Series in Statistics
Trevor Hastie, Robert Tibshirani, and Jerome Friedman.The Elements of Statistical Learning. Springer Series in Statistics. Springer New York Inc., New York, NY, USA, 2001
2001
-
[16]
Deep learning techniques for inverse problems in imaging.IEEE Journal on Selected Areas in Information Theory, 1(1):39–56, 2020
Gregory Ongie, Ajil Jalal, Christopher A Metzler, Richard G Baraniuk, Alexandros G Dimakis, and Rebecca Willett. Deep learning techniques for inverse problems in imaging.IEEE Journal on Selected Areas in Information Theory, 1(1):39–56, 2020
2020
-
[17]
Ghosh, and Aad W
Subhashis Ghosal, Jayanta K. Ghosh, and Aad W. van der Vaart. Convergence rates of posterior distributions.Annals of Statistics, 28(2):500–531, 2000
2000
-
[18]
SIAM, 2005
Albert Tarantola.Inverse problem theory and methods for model parameter estimation. SIAM, 2005
2005
-
[19]
Elsevier, 2018
Richard C Aster, Brian Borchers, and Clifford H Thurber.Parameter estimation and inverse problems. Elsevier, 2018
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.