C3P: Contrastive promoter-protein pretraining yields representations capturing bacterial gene regulation
Pith reviewed 2026-06-29 23:02 UTC · model grok-4.3
The pith
Contrastive alignment of bacterial promoters with their proteins yields representations that capture gene regulation better than genome language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
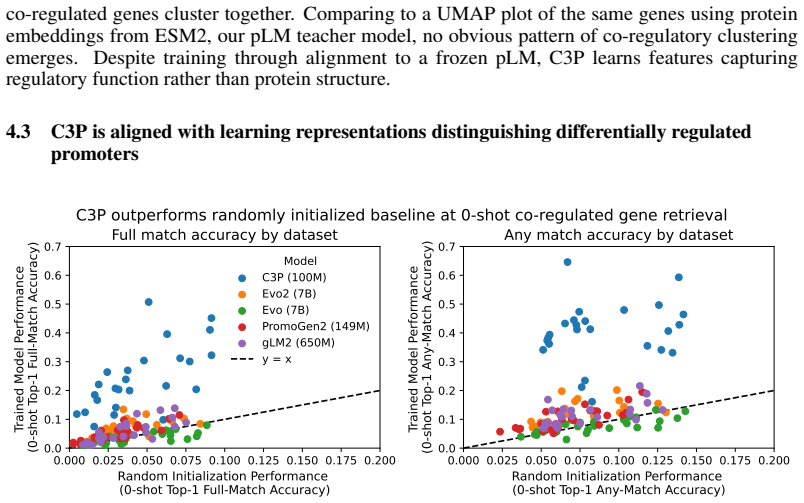
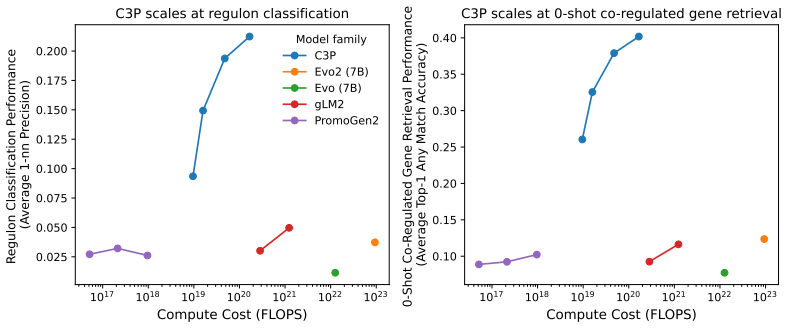
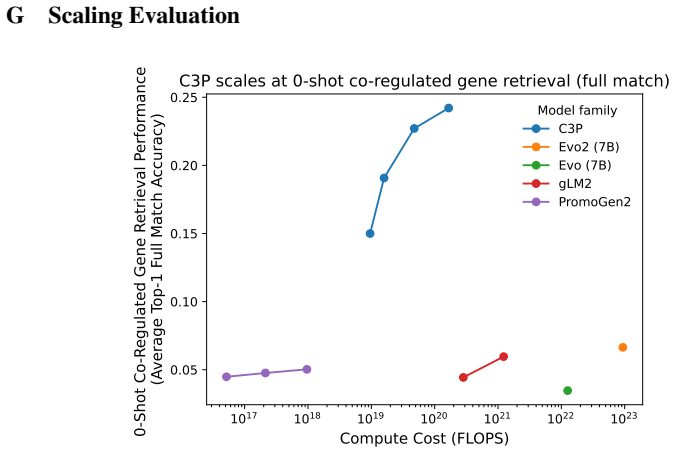
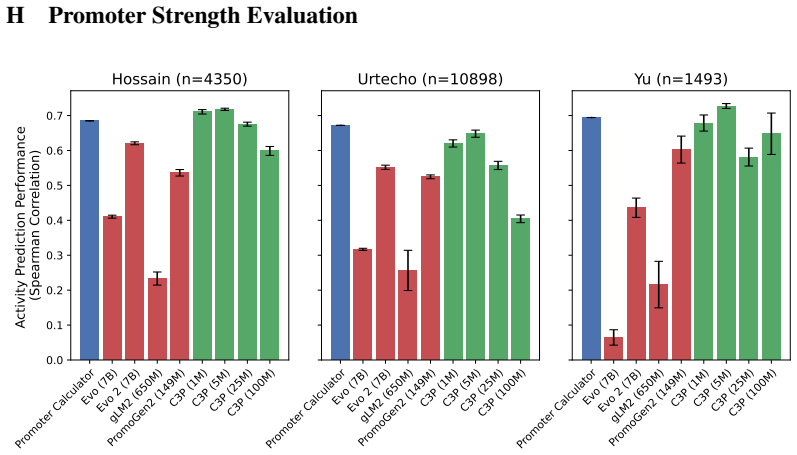
By training on 88 million bacterial promoter-protein pairs to align promoters with protein embeddings from protein language models, C3P produces promoter representations that achieve multi-fold improvements in predicting curated regulatory annotations and enable significant zero-shot co-regulated gene retrieval, unlike gLMs.
What carries the argument
The contrastive loss that aligns promoter embeddings with corresponding protein embeddings, using protein language model representations as the supervisory signal.
If this is right
- Multi-fold improvement over gLMs for inference of regulatory annotations
- Significant zero-shot gains in co-regulated gene retrieval compared to random baseline and gLMs
- Achieves strong performance at a fraction of the training cost of leading gLMs
- Further improvement is possible with additional scaling of the training data
Where Pith is reading between the lines
- The method may allow inference of gene regulation in uncultured bacteria solely from their genome sequences.
- Protein embeddings could serve as a general supervisory signal for learning representations of other regulatory sequence types.
- Zero-shot retrieval performance could be validated against experimentally confirmed co-regulation datasets in well-studied model bacteria.
Load-bearing premise
Protein embeddings encode information relevant to the regulatory function of the promoters that control their expression.
What would settle it
If C3P representations do not show improved performance over gLMs when tested on a large independent set of curated bacterial regulatory annotations from a different species.
Figures
read the original abstract
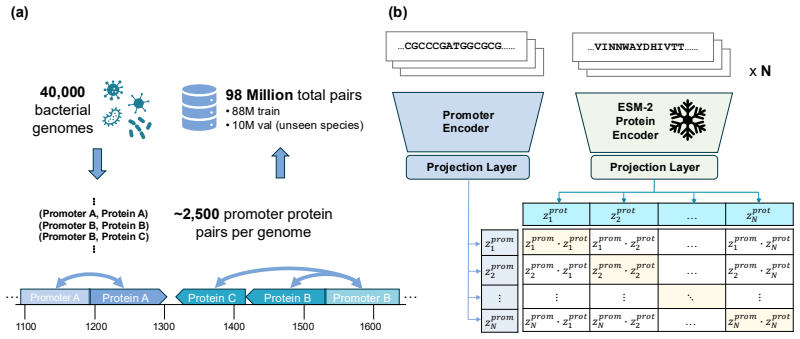
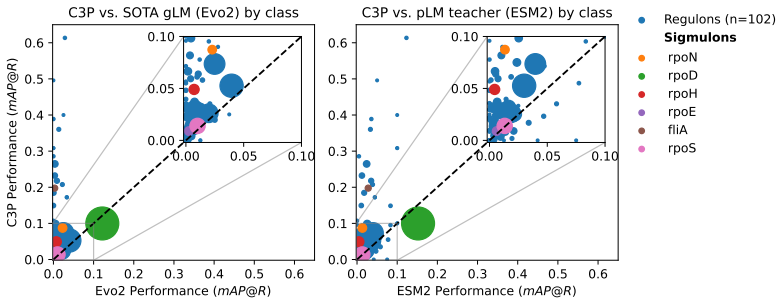
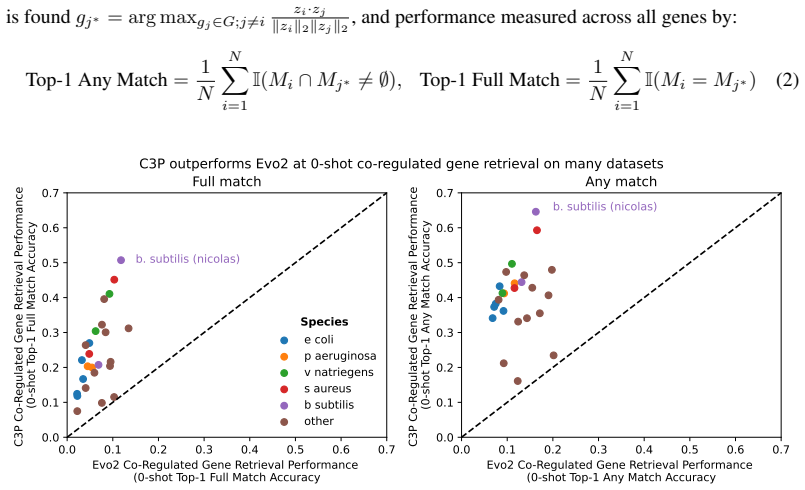
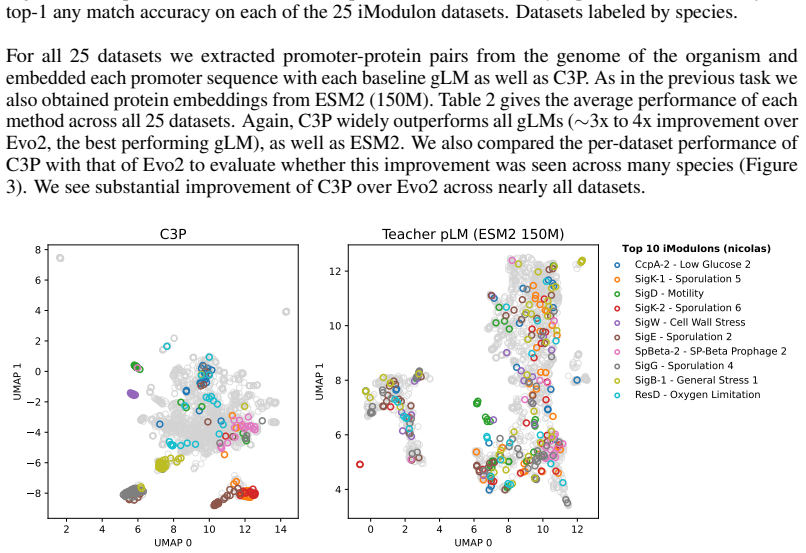
Despite the increasing scale of genome language models (gLMs), their ability to decode the function of regulatory sequences remains unclear. gLM pretraining relies on sequence reconstruction, which may struggle due to the noisy, rapidly evolving nature of regulatory DNA. Self-supervised contrastive approaches provide a promising alternative. Inspired by language-image architectures like CLIP, we introduce contrastive promoter-protein pretraining (C3P). By learning to align promoters to their corresponding proteins, we leverage the rich representations of proteins learned by protein language models as supervisory signal for the learning of promoter representations. After training on 88 million bacterial promoter-protein pairs, we evaluate the predictive power of C3P-learned promoter representations for inference of curated regulatory annotations, finding multi-fold improvement over leading gLMs. We also introduce zero-shot co-regulated gene retrieval, the ability to find co-regulated genes in a genome using no experimental data. We find that compared to a randomly initialized baseline, C3P training consistently provides significant zero-shot performance gains, unlike gLMs. Scaling analysis reveals the potential for further improvement as well as the efficiency of C3P, which achieved strong performance at a fraction of the training cost of leading gLMs. In addition to demonstrating that C3P training is effective for learning representations of bacterial regulatory sequences, our strong zero-shot co-regulated gene retrieval performance suggests the possibility of decoding gene regulation for millions of bacteria from their genomes alone.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces C3P, a contrastive pretraining method inspired by CLIP that aligns bacterial promoters with their corresponding protein embeddings from protein language models. Trained on 88 million promoter-protein pairs, the resulting promoter representations are shown to outperform leading genome language models in inferring curated regulatory annotations and achieve significant gains in a novel zero-shot co-regulated gene retrieval task, while being more efficient.
Significance. If the empirical gains are robust, this work provides a scalable and data-efficient approach to learning regulatory sequence representations by leveraging protein supervision, potentially enabling better decoding of gene regulation across bacterial genomes without extensive experimental data. The introduction of the zero-shot retrieval task is a notable contribution.
major comments (2)
- [Abstract] Abstract: The claim of 'multi-fold improvement over leading gLMs' for inference of curated regulatory annotations lacks any specification of the exact gLM baselines, statistical tests, data splits, or ablation controls, preventing assessment of whether post-hoc choices or dataset biases affect the central claim.
- [Results] Results (zero-shot retrieval and scaling analysis): The reported gains are attributed to the contrastive alignment supplying regulatory signal from protein embeddings, but no direct controls (e.g., shuffled pairs or protein-embedding ablations) are described to rule out that gains arise instead from architecture scale, data volume, or objective differences; this is load-bearing for the claim that protein embeddings encode promoter-specific features.
minor comments (1)
- [Abstract] Abstract: The efficiency claim ('fraction of the training cost of leading gLMs') is stated without quantitative comparison of FLOPs, wall-clock time, or parameter counts.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive review. The comments highlight opportunities to improve clarity and strengthen the attribution of results. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim of 'multi-fold improvement over leading gLMs' for inference of curated regulatory annotations lacks any specification of the exact gLM baselines, statistical tests, data splits, or ablation controls, preventing assessment of whether post-hoc choices or dataset biases affect the central claim.
Authors: We agree that greater specificity in the abstract will aid assessment of the claims. The full manuscript already details the gLM baselines (e.g., specific models compared in Results), statistical tests (paired t-tests with reported p-values), chromosome-level data splits to prevent leakage, and ablation controls in the Supplementary Information. In revision we will update the abstract to explicitly name the baselines, reference the tests and splits, and point to the ablations, ensuring the central claim is presented with appropriate context. revision: yes
-
Referee: [Results] Results (zero-shot retrieval and scaling analysis): The reported gains are attributed to the contrastive alignment supplying regulatory signal from protein embeddings, but no direct controls (e.g., shuffled pairs or protein-embedding ablations) are described to rule out that gains arise instead from architecture scale, data volume, or objective differences; this is load-bearing for the claim that protein embeddings encode promoter-specific features.
Authors: We acknowledge the value of direct controls to isolate the role of contrastive alignment with protein embeddings. Existing comparisons to a randomly initialized baseline and to gLMs provide partial controls for architecture, data volume, and objective, and the zero-shot gains over random initialization support the contribution of C3P training. However, to more rigorously rule out alternative explanations, we will add the requested experiments during revision: training on shuffled promoter-protein pairs and ablations replacing protein embeddings with random or non-informative vectors. These will be reported in the zero-shot retrieval and scaling sections to directly test whether protein-specific features drive the observed gains. revision: yes
Circularity Check
No significant circularity; method uses external pairs and pLMs with independent downstream evaluations
full rationale
The paper defines C3P as standard contrastive alignment of promoters to protein embeddings from external pLMs on 88M pairs, then reports empirical gains on held-out regulatory annotation inference and zero-shot co-regulated gene retrieval. No equations reduce these gains to quantities defined by the training objective itself. No self-citation chains or fitted inputs are invoked as load-bearing for the central claims. The derivation remains self-contained against external benchmarks and does not match any enumerated circularity patterns.
Axiom & Free-Parameter Ledger
free parameters (1)
- contrastive temperature and model hyperparameters
axioms (1)
- domain assumption Protein language model representations encode information relevant to promoter regulatory function
Reference graph
Works this paper leans on
-
[1]
Joint-Embedding vs Reconstruction: Provable Benefits of Latent Space Prediction for Self-Supervised Learning
Hugues Van Assel, Mark Ibrahim, Tommaso Biancalani, Aviv Regev, and Randall Balestriero. Joint-Embedding vs Reconstruction: Provable Benefits of Latent Space Prediction for Self-Supervised Learning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, October 2025
2025
-
[2]
Ledsam, Agnieszka Grabska- Barwinska, Kyle R
Žiga Avsec, Vikram Agarwal, Daniel Visentin, Joseph R. Ledsam, Agnieszka Grabska- Barwinska, Kyle R. Taylor, Yannis Assael, John Jumper, Pushmeet Kohli, and David R. Kelley. Effective gene expression prediction from sequence by integrating long-range interactions. Nature Methods, 18(10):1196–1203, October 2021
2021
-
[3]
Žiga Avsec, Natasha Latysheva, Jun Cheng, Guido Novati, Kyle R. Taylor, Tom Ward, Clare Bycroft, Lauren Nicolaisen, Eirini Arvaniti, Joshua Pan, Raina Thomas, Vincent Dutordoir, Matteo Perino, Soham De, Alexander Karollus, Adam Gayoso, Toby Sargeant, Anne Mottram, Lai Hong Wong, Pavol Drotár, Adam Kosiorek, Andrew Senior, Richard Tanburn, Taylor Applebaum...
2026
-
[4]
Baumgart, Ji Eun Lee, Asaf Salamov, David J
Leo A. Baumgart, Ji Eun Lee, Asaf Salamov, David J. Dilworth, Hyunsoo Na, Matthew Mingay, Matthew J. Blow, Yu Zhang, Yuko Yoshinaga, Chris G. Daum, and Ronan C. O’Malley. Persistence and plasticity in bacterial gene regulation.Nature Methods, 18(12):1499–1505, December 2021
2021
-
[5]
Durrant, Jerome Ku, Mohsen Naghipourfar, Michael Poli, Gwang- gyu Sun, Greg Brockman, Daniel Chang, Alison Fanton, Gabriel A
Garyk Brixi, Matthew G. Durrant, Jerome Ku, Mohsen Naghipourfar, Michael Poli, Gwang- gyu Sun, Greg Brockman, Daniel Chang, Alison Fanton, Gabriel A. Gonzalez, Samuel H. King, David B. Li, Aditi T. Merchant, Eric Nguyen, Chiara Ricci-Tam, David W. Romero, Jonathan C. Schmok, Ali Taghibakhshi, Anton V orontsov, Brandon Yang, Myra Deng, Liv Gorton, Nam Nguy...
2026
-
[6]
Exploring Simple Siamese Representation Learning, November
Xinlei Chen and Kaiming He. Exploring Simple Siamese Representation Learning, November
- [7]
-
[8]
Consens, Cameron Dufault, Michael Wainberg, Duncan Forster, Mehran Karimzadeh, Hani Goodarzi, Fabian J
Micaela E. Consens, Cameron Dufault, Michael Wainberg, Duncan Forster, Mehran Karimzadeh, Hani Goodarzi, Fabian J. Theis, Alan Moses, and Bo Wang. Transformers and genome language models.Nature Machine Intelligence, 7(3):346–362, March 2025
2025
-
[9]
The OMG dataset: An open metagenomic corpus for mixed-modality genomic language modeling
Andre Cornman, Jacob West-Roberts, Antonio Pedro Camargo, Simon Roux, Martin Bera- cochea, Milot Mirdita, Sergey Ovchinnikov, and Yunha Hwang. The OMG dataset: An open metagenomic corpus for mixed-modality genomic language modeling. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[10]
Eisen, Paul T
Michael B. Eisen, Paul T. Spellman, Patrick O. Brown, and David Botstein. Cluster analysis and display of genome-wide expression patterns.Proceedings of the National Academy of Sciences, 95(25):14863–14868, December 1998
1998
-
[11]
Learning Visual Representations via Language-Guided Sampling
Mohamed El Banani, Karan Desai, and Justin Johnson. Learning Visual Representations via Language-Guided Sampling. InCVPR, 2023
2023
-
[12]
Frey, Leo J
Philip Fradkin, Ruian “Ian” Shi, Taykhoom Dalal, Keren Isaev, Brendan J. Frey, Leo J. Lee, Quaid Morris, and Bo Wang. Orthrus: toward evolutionary and functional RNA foundation models.Nature Methods, pages 1–11, April 2026. 11
2026
-
[13]
NCBI RefSeq: reference sequence standards through 25 years of curation and annotation.Nucleic Acids Research, 53(D1):D243–D257, January 2025
Tamara Goldfarb, Vamsi K Kodali, Shashikant Pujar, Vyacheslav Brover, Barbara Robbertse, Catherine M Farrell, Dong-Ha Oh, Alexander Astashyn, Olga Ermolaeva, Diana Haddad, Wratko Hlavina, Jinna Hoffman, John D Jackson, Vinita S Joardar, David Kristensen, Patrick Masterson, Kelly M McGarvey, Richard McVeigh, Eyal Mozes, Michael R Murphy, Susan S Schafer, A...
2025
-
[14]
Halper, Daniel P
Ayaan Hossain, Eriberto Lopez, Sean M. Halper, Daniel P. Cetnar, Alexander C. Reis, Devin Strickland, Eric Klavins, and Howard M. Salis. Automated design of thousands of nonrepeti- tive parts for engineering stable genetic systems.Nature Biotechnology, 38(12):1466–1475, December 2020
2020
-
[15]
Scaling up visual and vision-language representation learning with noisy text supervision
Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representation learning with noisy text supervision. InProceedings of the 38th International Conference on Machine Learning, volume 139 ofProceedings of Machine Learning Research, pages 4904–4916. P...
2021
-
[16]
John Jumper, Richard Evans, Alexander Pritzel, Tim Green, Michael Figurnov, Olaf Ron- neberger, Kathryn Tunyasuvunakool, Russ Bates, Augustin Žídek, Anna Potapenko, Alex Bridgland, Clemens Meyer, Simon A. A. Kohl, Andrew J. Ballard, Andrew Cowie, Bernardino Romera-Paredes, Stanislav Nikolov, Rishub Jain, Jonas Adler, Trevor Back, Stig Petersen, David Reim...
2021
-
[17]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models, 2020. arXiv:2001.08361 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[18]
Flexible comparative genomics of prokaryotic transcriptional regulatory networks.BMC Genomics, 21(5):466, December 2020
Sefa Kılıç, Miquel Sánchez-Osuna, Antonio Collado-Padilla, Jordi Barbé, and Ivan Erill. Flexible comparative genomics of prokaryotic transcriptional regulatory networks.BMC Genomics, 21(5):466, December 2020
2020
-
[19]
LaFleur, Ayaan Hossain, and Howard M
Travis L. LaFleur, Ayaan Hossain, and Howard M. Salis. Automated model-predictive design of synthetic promoters to control transcriptional profiles in bacteria.Nature Communications, 13(1):5159, September 2022
2022
-
[20]
Harnessing a unified multi-modal sequence modeling to unveil protein-dna interdependency.bioRxiv, pages 2025–02, 2025
Mingchen Li, Yuchen Ren, Peng Ye, Jiabei Cheng, Xinzhu Ma, Yuchen Cai, Wanli Ouyang, Bozitao Zhong, Banghao Wu, Nanqing Dong, et al. Harnessing a unified multi-modal sequence modeling to unveil protein-dna interdependency.bioRxiv, pages 2025–02, 2025
2025
-
[21]
Evolutionary-scale prediction of atomic- level protein structure with a language model.Science, 379(6637):1123–1130, March 2023
Zeming Lin, Halil Akin, Roshan Rao, Brian Hie, Zhongkai Zhu, Wenting Lu, Nikita Smetanin, Robert Verkuil, Ori Kabeli, Yaniv Shmueli, Allan dos Santos Costa, Maryam Fazel-Zarandi, Tom Sercu, Salvatore Candido, and Alexander Rives. Evolutionary-scale prediction of atomic- level protein structure with a language model.Science, 379(6637):1123–1130, March 2023
2023
-
[22]
Johannes Linder, Divyanshi Srivastava, Han Yuan, Vikram Agarwal, and David R. Kelley. Predicting RNA-seq coverage from DNA sequence as a unifying model of gene regulation. Nature Genetics, 57(4):949–961, April 2025
2025
-
[23]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations, 2019
2019
-
[24]
A census-based estimate of Earth’s bacterial and archaeal diversity.PLOS Biology, 17(2):e3000106, February 2019
Stilianos Louca, Florent Mazel, Michael Doebeli, and Laura Wegener Parfrey. A census-based estimate of Earth’s bacterial and archaeal diversity.PLOS Biology, 17(2):e3000106, February 2019. 12
2019
-
[25]
Amy X. Lu, Alex X. Lu, and Alan Moses. Evolution Is All You Need: Phylogenetic Augmenta- tion for Contrastive Learning, December 2020. arXiv:2012.13475 [q-bio]
-
[26]
Lu, Haoran Zhang, Marzyeh Ghassemi, and Alan Moses
Amy X. Lu, Haoran Zhang, Marzyeh Ghassemi, and Alan Moses. Self-supervised contrastive learning of protein representations by mutual information maximization.bioRxiv, 2020
2020
-
[27]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
Leland McInnes, John Healy, and James Melville. UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction, September 2020. arXiv:1802.03426 [stat]
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[28]
Moses, Jason E
Alan M. Moses, Jason E. Stajich, Audrey P. Gasch, and David A. Knowles. Inferring fungal cis- regulatory networks from genome sequences via unsupervised and interpretable representation learning.Genetics, page iyaf209, September 2025
2025
-
[29]
A Metric Learning Reality Check
Kevin Musgrave, Serge Belongie, and Ser-Nam Lim. A Metric Learning Reality Check. In Computer Vision – ECCV 2020, pages 681–699, Cham, 2020. Springer International Publishing
2020
-
[30]
Durrant, Brian Kang, Dhruva Katrekar, David B
Eric Nguyen, Michael Poli, Matthew G. Durrant, Brian Kang, Dhruva Katrekar, David B. Li, Liam J. Bartie, Armin W. Thomas, Samuel H. King, Garyk Brixi, Jeremy Sullivan, Madelena Y . Ng, Ashley Lewis, Aaron Lou, Stefano Ermon, Stephen A. Baccus, Tina Hernandez-Boussard, Christopher Ré, Patrick D. Hsu, and Brian L. Hie. Sequence modeling and design from mole...
2024
-
[31]
Representation Learning with Contrastive Predictive Coding
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation Learning with Contrastive Predictive Coding, January 2019. arXiv:1807.03748 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[32]
O’Leary, Eric Cox, J
Nuala A. O’Leary, Eric Cox, J. Bradley Holmes, W. Ray Anderson, Robert Falk, Vichet Hem, Mirian T. N. Tsuchiya, Gregory D. Schuler, Xuan Zhang, John Torcivia, Anne Ketter, Laurie Breen, Jonathan Cothran, Hena Bajwa, Jovany Tinne, Peter A. Meric, Wratko Hlavina, and Valerie A. Schneider. Exploring and retrieving sequence and metadata for species across the...
2024
-
[33]
Pedregosa, G
F. Pedregosa, G. Varoquaux, A. Gramfort, V . Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V . Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duchesnay. Scikit-learn: Machine learning in Python.Journal of Machine Learning Research, 12:2825–2830, 2011
2011
-
[34]
Stripedhyena: Moving beyond transformers with hybrid signal processing models.GitHub repository, 12, 2023
Michael Poli, Jue Wang, Stefano Massaroli, Jeffrey Quesnelle, Ryan Carlow, Eric Nguyen, and Armin Thomas. Stripedhyena: Moving beyond transformers with hybrid signal processing models.GitHub repository, 12, 2023
2023
-
[35]
Stephen R. Quake. The cellular dogma.Cell, 187(23):6421–6423, November 2024
2024
-
[36]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InProceed- ings of the 38th International Conference on Machine Learning, volume 139 ofProceedings...
2021
-
[37]
Robust and Decomposable Average Precision for Image Retrieval
Elias Ramzi, Nicolas Thome, Clément Rambour, Nicolas Audebert, and Xavier Bitot. Robust and Decomposable Average Precision for Image Retrieval. InAdvances in Neural Information Processing Systems, volume 34, pages 23569–23581. Curran Associates, Inc., 2021
2021
-
[38]
Lawrence Zitnick, Jerry Ma, and Rob Fergus
Alexander Rives, Joshua Meier, Tom Sercu, Siddharth Goyal, Zeming Lin, Jason Liu, Demi Guo, Myle Ott, C. Lawrence Zitnick, Jerry Ma, and Rob Fergus. Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences.Proceedings of the National Academy of Sciences, 118(15):e2016239118, April 2021
2021
-
[39]
iModulonDB: a knowledgebase of microbial transcriptional regulation derived from machine learning.Nucleic Acids Research, 49(D1):D112–D120, January 2021
Kevin Rychel, Katherine Decker, Anand V Sastry, Patrick V Phaneuf, Saugat Poudel, and Bernhard O Palsson. iModulonDB: a knowledgebase of microbial transcriptional regulation derived from machine learning.Nucleic Acids Research, 49(D1):D112–D120, January 2021. 13
2021
-
[40]
RegulonDB v12.0: a comprehensive resource of transcriptional regulation in E
Heladia Salgado, Socorro Gama-Castro, Paloma Lara, Citlalli Mejia-Almonte, Gabriel Alarcón- Carranza, Andrés G López-Almazo, Felipe Betancourt-Figueroa, Pablo Peña-Loredo, Shirley Alquicira-Hernández, Daniela Ledezma-Tejeida, Lizeth Arizmendi-Zagal, Francisco Mendez- Hernandez, Ana K Diaz-Gomez, Elizabeth Ochoa-Praxedis, Luis J Muñiz-Rascado, Jair S Garcí...
2024
-
[41]
Sangster, Cameron Dufault, Haoning Qu, Denise Le, Julie D
Ami G. Sangster, Cameron Dufault, Haoning Qu, Denise Le, Julie D. Forman-Kay, and Alan M. Moses. Zero-shot segmentation using embeddings from a protein language model identifies functional regions in the human proteome.PLOS Computational Biology, 21(11):e1012929, November 2025
2025
-
[42]
Sastry, Ye Gao, Richard Szubin, Ying Hefner, Sibei Xu, Donghyuk Kim, Kumari Sonal Choudhary, Laurence Yang, Zachary A
Anand V . Sastry, Ye Gao, Richard Szubin, Ying Hefner, Sibei Xu, Donghyuk Kim, Kumari Sonal Choudhary, Laurence Yang, Zachary A. King, and Bernhard O. Palsson. The Escherichia coli transcriptome mostly consists of independently regulated modules.Nature Communications, 10(1):5536, December 2019
2019
-
[43]
GenBank 2025 update.Nucleic Acids Research, 53(D1):D56–D61, January 2025
Eric W Sayers, Mark Cavanaugh, Linda Frisse, Kim D Pruitt, Valerie A Schneider, Beverly A Underwood, Linda Yankie, and Ilene Karsch-Mizrachi. GenBank 2025 update.Nucleic Acids Research, 53(D1):D56–D61, January 2025
2025
-
[44]
MMseqs2 enables sensitive protein sequence searching for the analysis of massive data sets.Nature Biotechnology, 35(11):1026–1028, November 2017
Martin Steinegger and Johannes Söding. MMseqs2 enables sensitive protein sequence searching for the analysis of massive data sets.Nature Biotechnology, 35(11):1026–1028, November 2017
2017
-
[45]
RoFormer: Enhanced Transformer with Rotary Position Embedding
Jianlin Su, Yu Lu, Shengfeng Pan, Bo Wen, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding, 2021. arXiv:2104.09864v1 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[46]
Ziqi Tang, Nirali Somia, Yiyang Yu, and Peter K. Koo. Evaluating the representational power of pre-trained DNA language models for regulatory genomics.Genome Biology, 26(1):203, July 2025
2025
-
[47]
Esm cambrian: Revealing the mysteries of proteins with unsupervised learning
ESM Team et al. Esm cambrian: Revealing the mysteries of proteins with unsupervised learning. EvolutionaryScale Website, 2024
2024
-
[48]
Tripp, Kimberly D
Guillaume Urtecho, Arielle D. Tripp, Kimberly D. Insigne, Hwangbeom Kim, and Sriram Kosuri. Systematic Dissection of Sequence Elements Controlling σ70 Promoters Using a Genomically Encoded Multiplexed Reporter Assay in Escherichia coli.Biochemistry, 58(11):1539–1551, March 2019
2019
-
[49]
Attention is All you Need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is All you Need. InAdvances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017
2017
-
[50]
Tokenization to transfer: Do genomic foundation models learn good representations? InThe Fourteenth International Conference on Learning Representations, 2026
Kirill Vishniakov, Karthik Viswanathan, Aleksandr Medvedev, Praveenkumar Kanithi, Marco AF Pimentel, Ronnie Rajan, and Shadab Khan. Tokenization to transfer: Do genomic foundation models learn good representations? InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[51]
Weirauch and Timothy R
Matthew T. Weirauch and Timothy R. Hughes. Conserved expression without conserved regulatory sequence: the more things change, the more they stay the same.Trends in Genetics, 26(2):66–74, February 2010
2010
-
[52]
Design prokaryotic cis-regulatory elements using language model.Nucleic Acids Research, 54(4):gkag122, February 2026
Yan Xia, Jinyuan Sun, Xiaowen Du, Zeyu Liang, Xin Wu, Wenyu Shi, Bin Shao, Shuyuan Guo, and Yi-Xin Huo. Design prokaryotic cis-regulatory elements using language model.Nucleic Acids Research, 54(4):gkag122, February 2026
2026
-
[53]
DNASimCLR: a contrastive learning-based deep learning approach for gene sequence data classification.BMC Bioinformatics, 25(1):328, October 2024
Minghao Yang, Zehua Wang, Zizhuo Yan, Wenxiang Wang, Qian Zhu, and Changlong Jin. DNASimCLR: a contrastive learning-based deep learning approach for gene sequence data classification.BMC Bioinformatics, 25(1):328, October 2024. 14
2024
-
[54]
Yu, Winnie L
Timothy C. Yu, Winnie L. Liu, Marcia S. Brinck, Jessica E. Davis, Jeremy Shek, Grace Bower, Tal Einav, Kimberly D. Insigne, Rob Phillips, Sriram Kosuri, and Guillaume Urtecho. Multi- plexed characterization of rationally designed promoter architectures deconstructs combinatorial logic for IPTG-inducible systems.Nature Communications, 12(1):325, January 2021
2021
-
[55]
Lit: Zero-shot transfer with locked-image text tuning
Xiaohua Zhai, Xiao Wang, Basil Mustafa, Andreas Steiner, Daniel Keysers, Alexander Kolesnikov, and Lucas Beyer. Lit: Zero-shot transfer with locked-image text tuning. In 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 18102–18112, 2022
2022
-
[56]
Wayment-Steele, Garyk Brixi, Haobo Wang, Dorothee Kern, and Sergey Ovchinnikov
Zhidian Zhang, Hannah K. Wayment-Steele, Garyk Brixi, Haobo Wang, Dorothee Kern, and Sergey Ovchinnikov. Protein language models learn evolutionary statistics of interacting sequence motifs.Proceedings of the National Academy of Sciences, 121(45):e2406285121, November 2024. 15 A Dataset creation A.1 Genome sampling and diversity Table 3: Summary of taxono...
2024
-
[57]
In their evaluations the authors used the final layer embeddings of the Evo 7B model, averaged over the sequence length and having a dimensionality of 4,096
architecture, an efficient transformer alternative. In their evaluations the authors used the final layer embeddings of the Evo 7B model, averaged over the sequence length and having a dimensionality of 4,096. We extract embeddings of promoter sequences from Evo in the same manner.Evo2 (7B)
-
[58]
2.4T tokens) with sequences from all domains of life (downloaded from https://huggingface.co/arcinstitute/evo2_7b, apache-2.0 license)
uses a similar training regime and architecture to Evo (7B), but was trained on a significantly larger dataset (300B vs. 2.4T tokens) with sequences from all domains of life (downloaded from https://huggingface.co/arcinstitute/evo2_7b, apache-2.0 license). Rather than extracting embeddings from the final hidden layer, we extract Evo2 embeddings from layer...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.