Multimodal Optical Feature Extraction with a Free-Space Photonic Extreme Learning Machine
Pith reviewed 2026-06-29 10:09 UTC · model grok-4.3
The pith
A single free-space optical apparatus extracts features for images, audio spectrograms, tabular data, and regression without hardware changes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
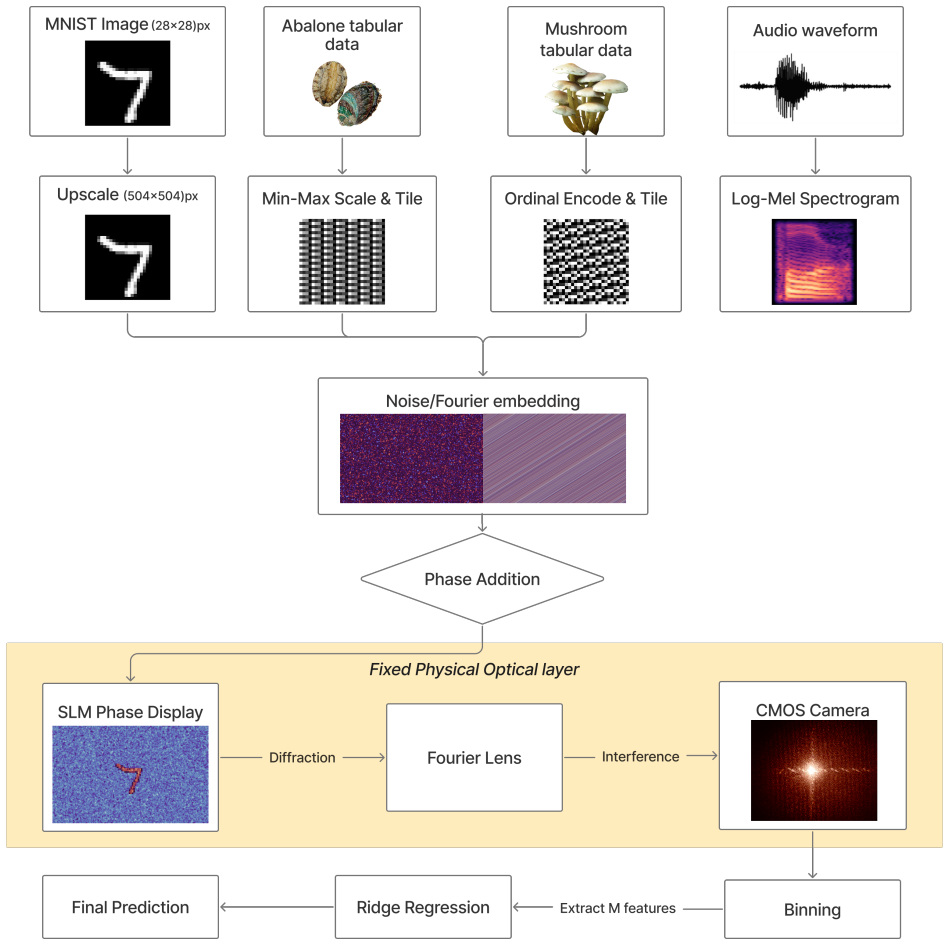
A fixed free-space photonic extreme learning machine using phase-only SLM encoding followed by Fourier-like propagation and camera detection generates a task-agnostic feature map that supports high-accuracy performance on image classification, spectrogram-based audio classification, binary tabular classification, and regression within the same physical pipeline.
What carries the argument
The fixed optical transformation of phase-only SLM encoding, free-space Fourier-like propagation, and intensity detection that maps inputs to a high-dimensional feature space for downstream linear readout.
If this is right
- The same apparatus handles image, audio-derived, tabular, and regression tasks without optical reconfiguration.
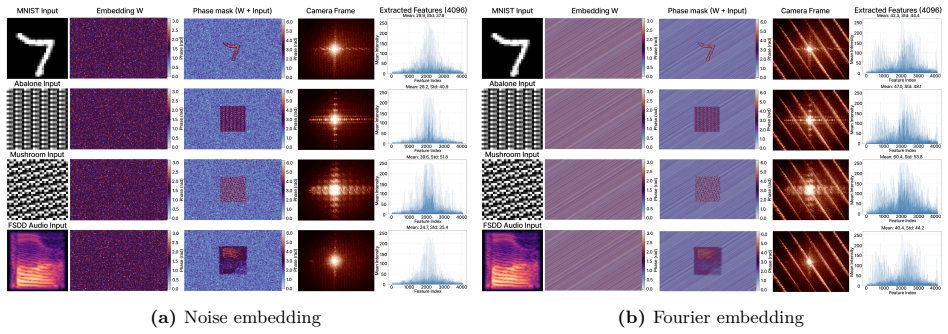
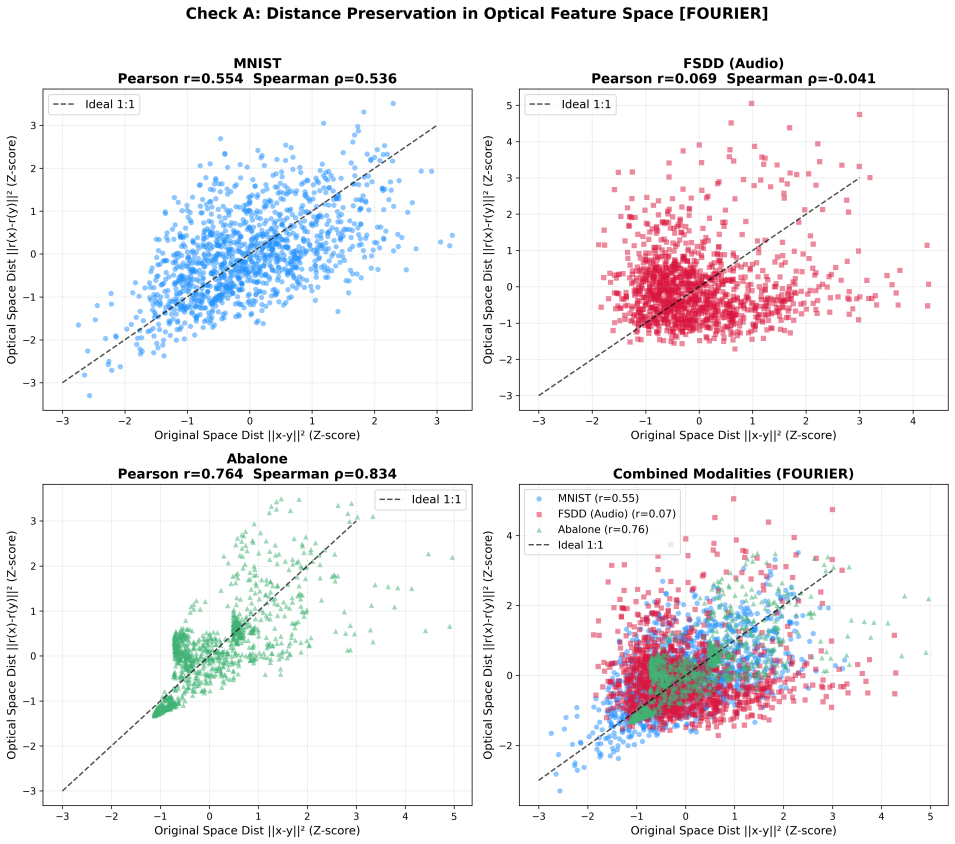
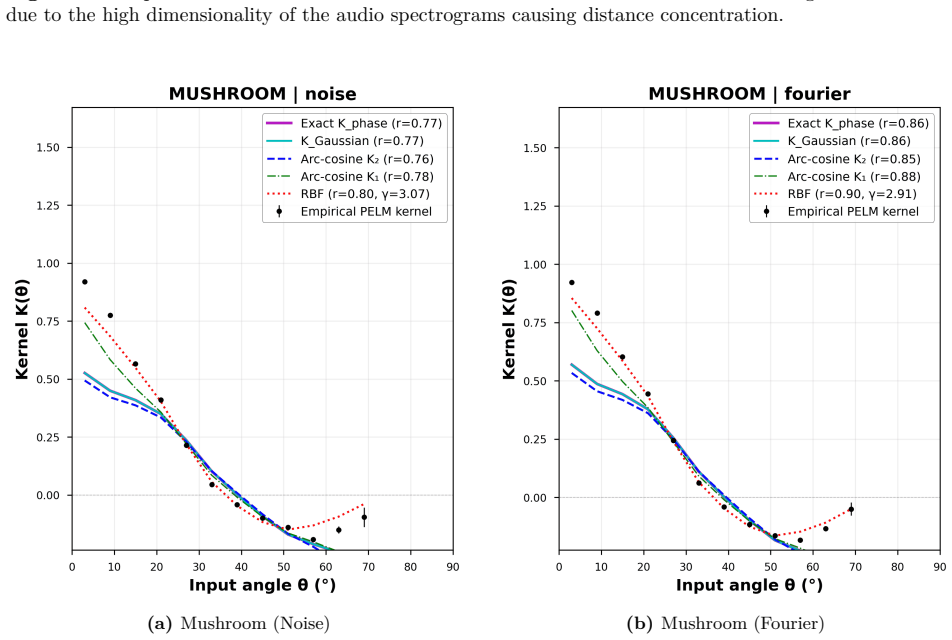
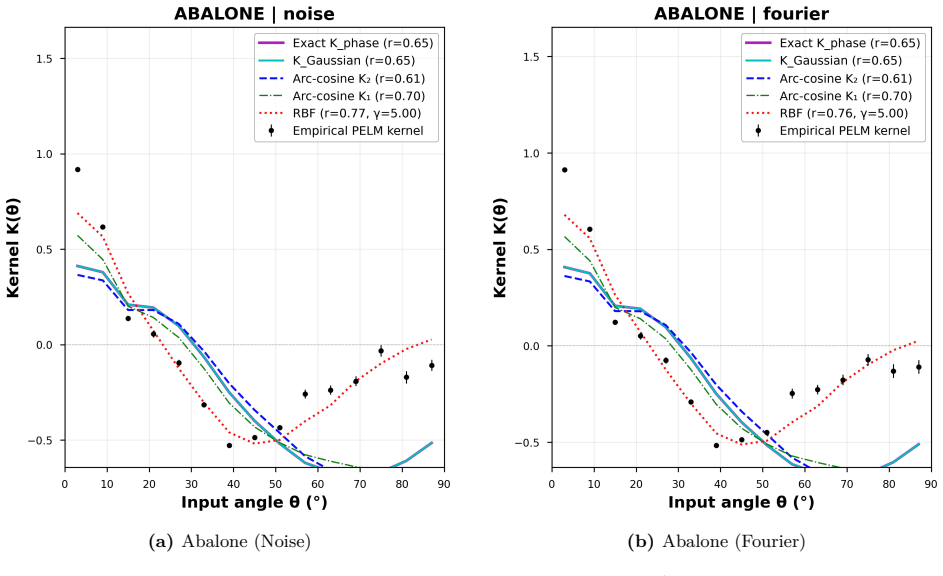
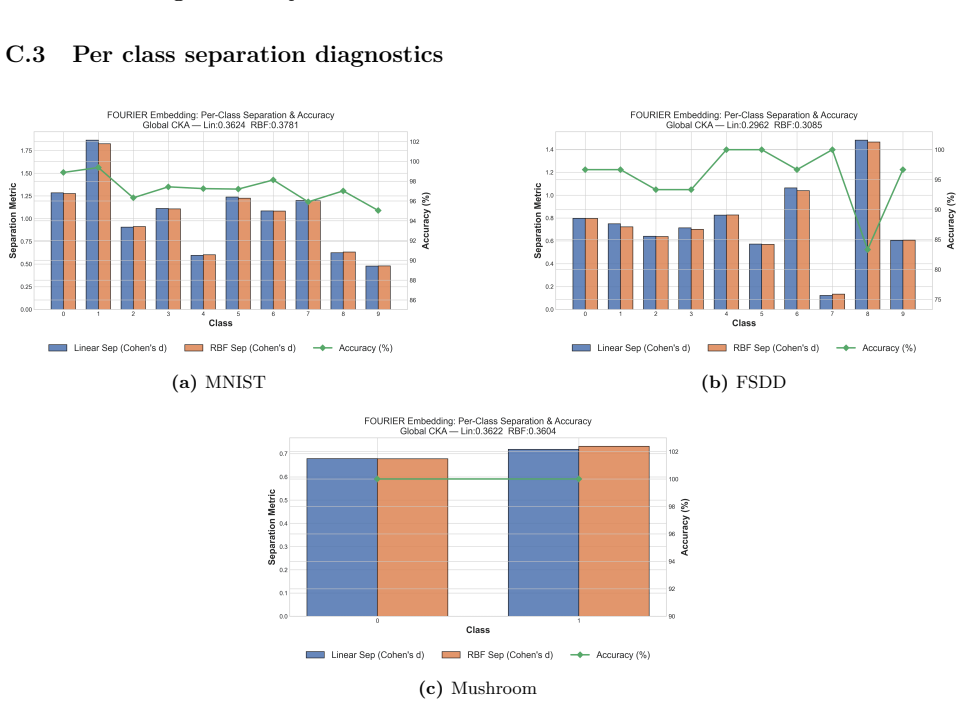
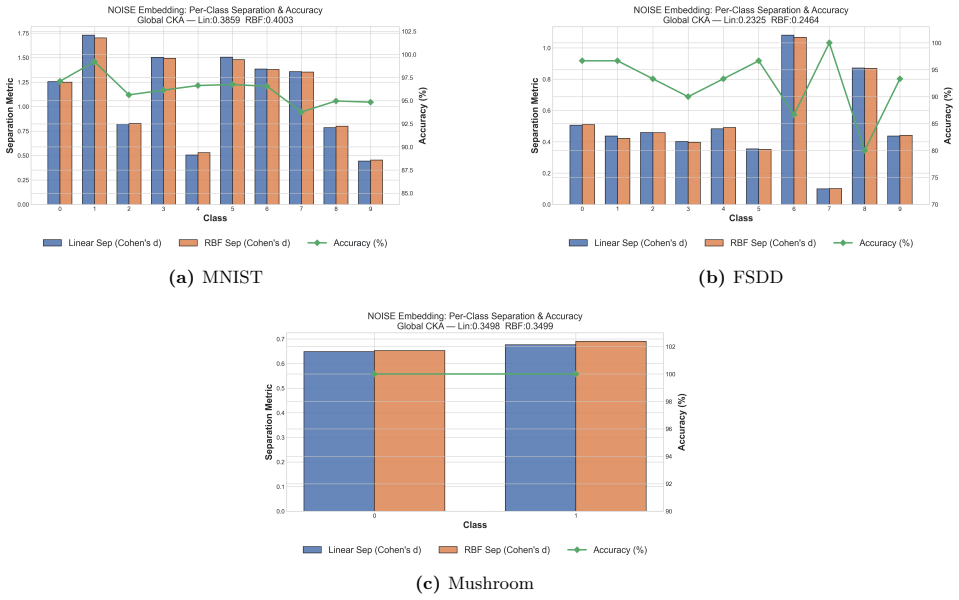
- Empirical diagnostics separate geometry-preserving behavior for images and regression from class-mean accumulation for spectrograms.
- Multimodal PELMs become a practical route to general-purpose optical feature extraction.
Where Pith is reading between the lines
- If the optical map remains effective across more modalities, it could reduce the need for separate digital feature extractors in mixed-sensor systems.
- Encoding additional data types such as time-series directly onto the SLM might test whether the current propagation distance suffices or whether multiple planes become necessary.
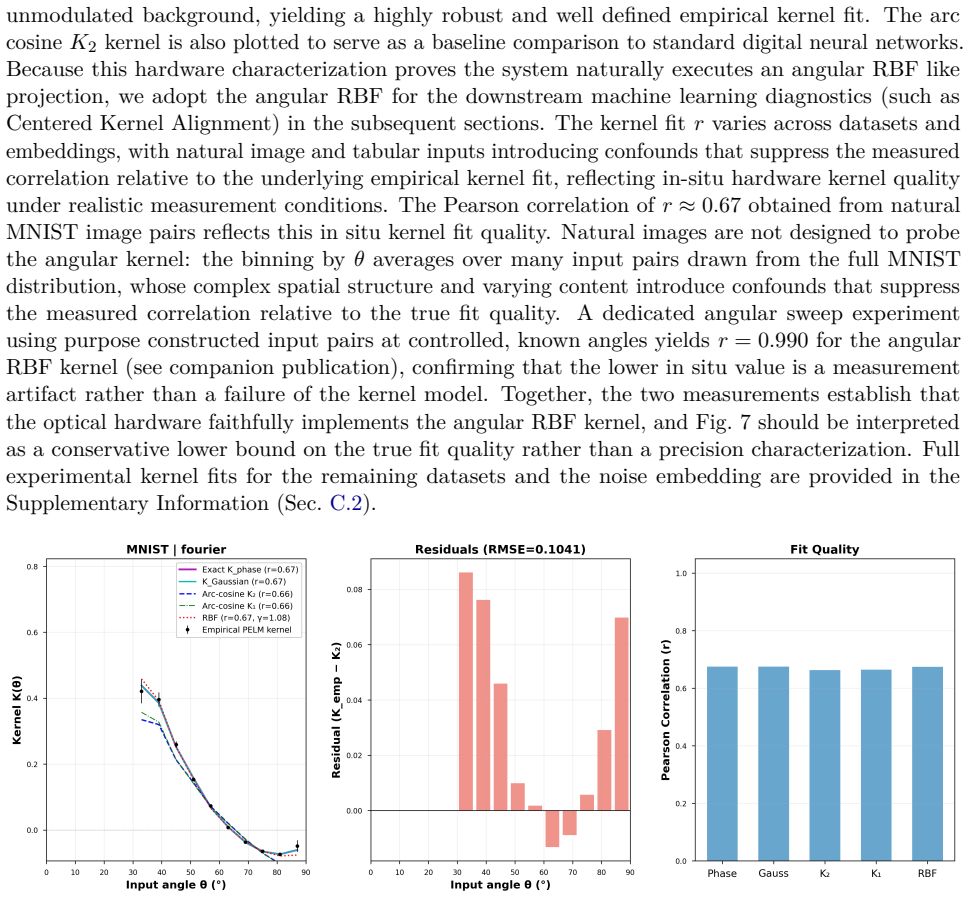
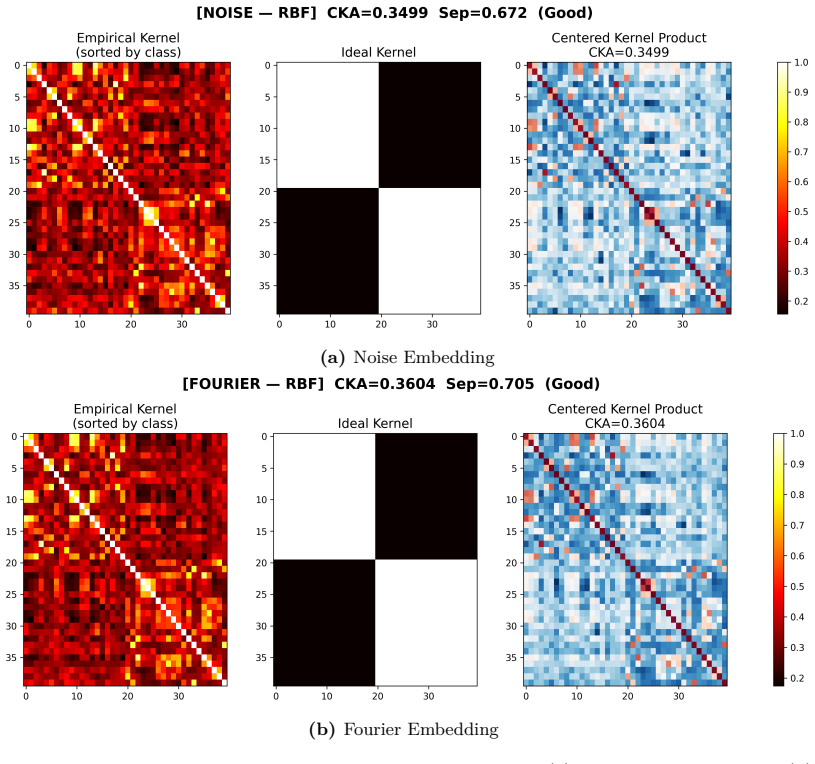
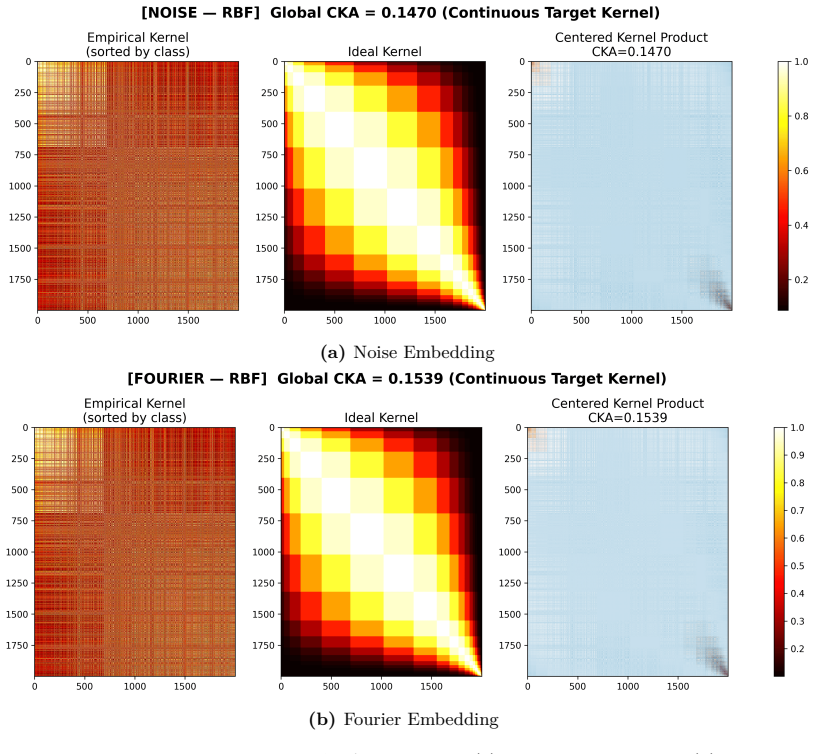
- The reported kernel alignment values suggest the optical stage approximates certain kernel functions; measuring explicit kernel matrices on held-out data would quantify how closely it matches standard random feature maps.
Load-bearing premise
A single fixed optical transformation produces a sufficiently rich feature map for structurally different inputs without any optical reconfiguration or extra modality-specific preprocessing.
What would settle it
Running a new data type such as raw video frames or text token sequences through the identical fixed optical apparatus and checking whether linear readout accuracy stays comparable to the reported benchmarks without any change to the SLM or propagation path.
Figures
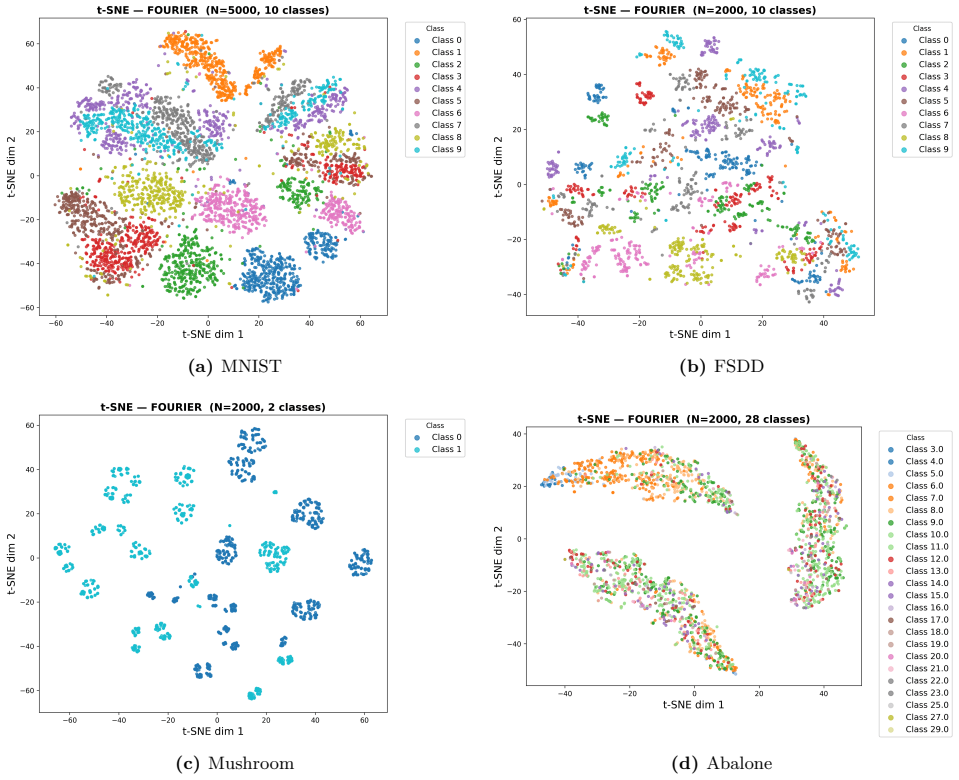
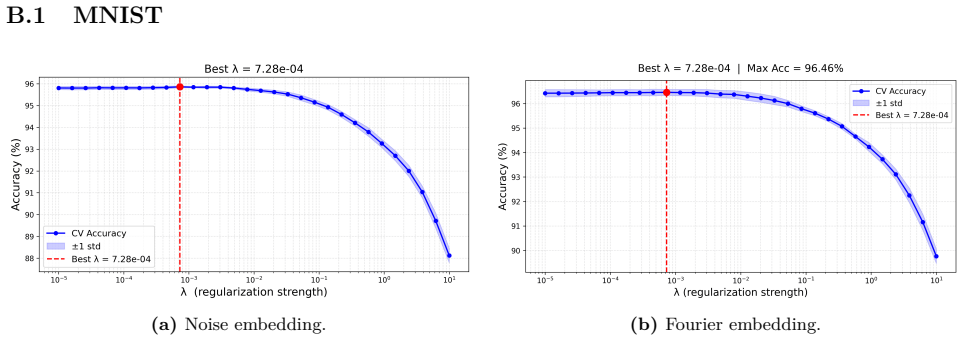
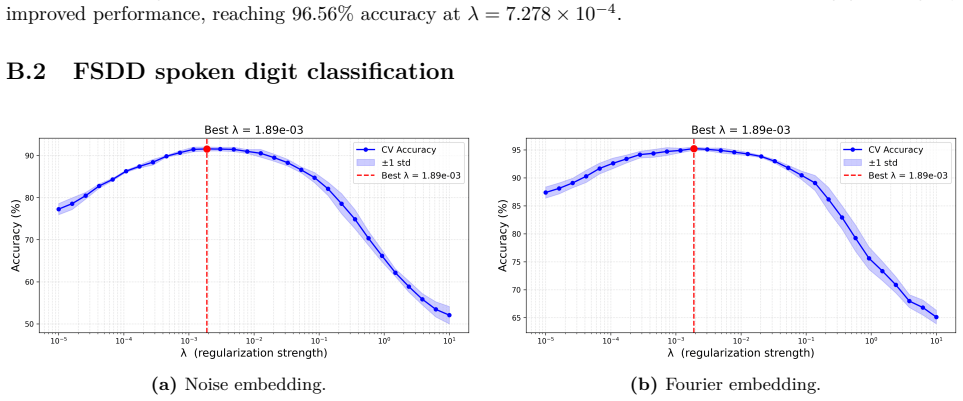
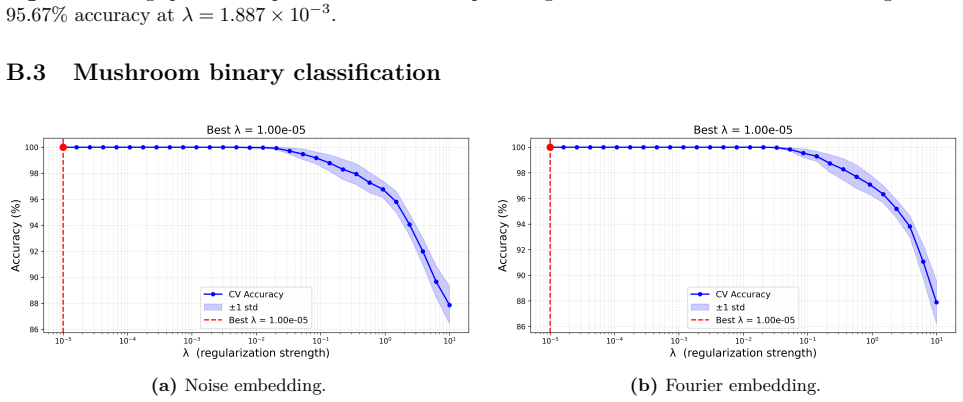
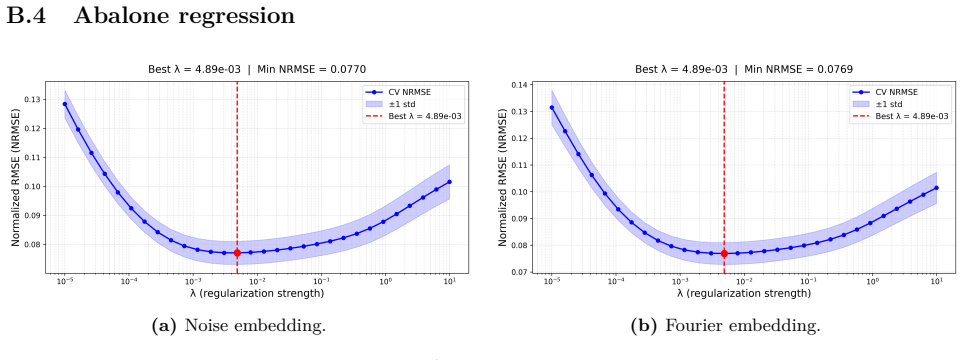
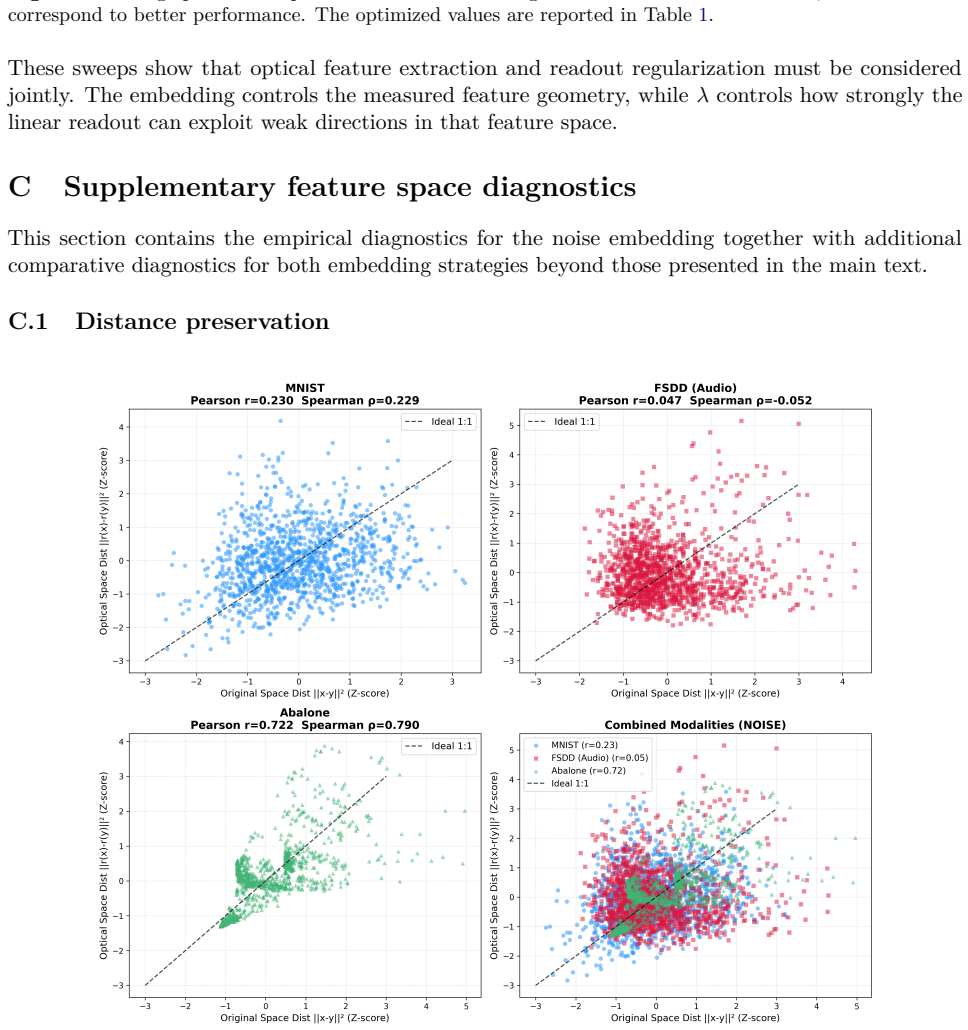
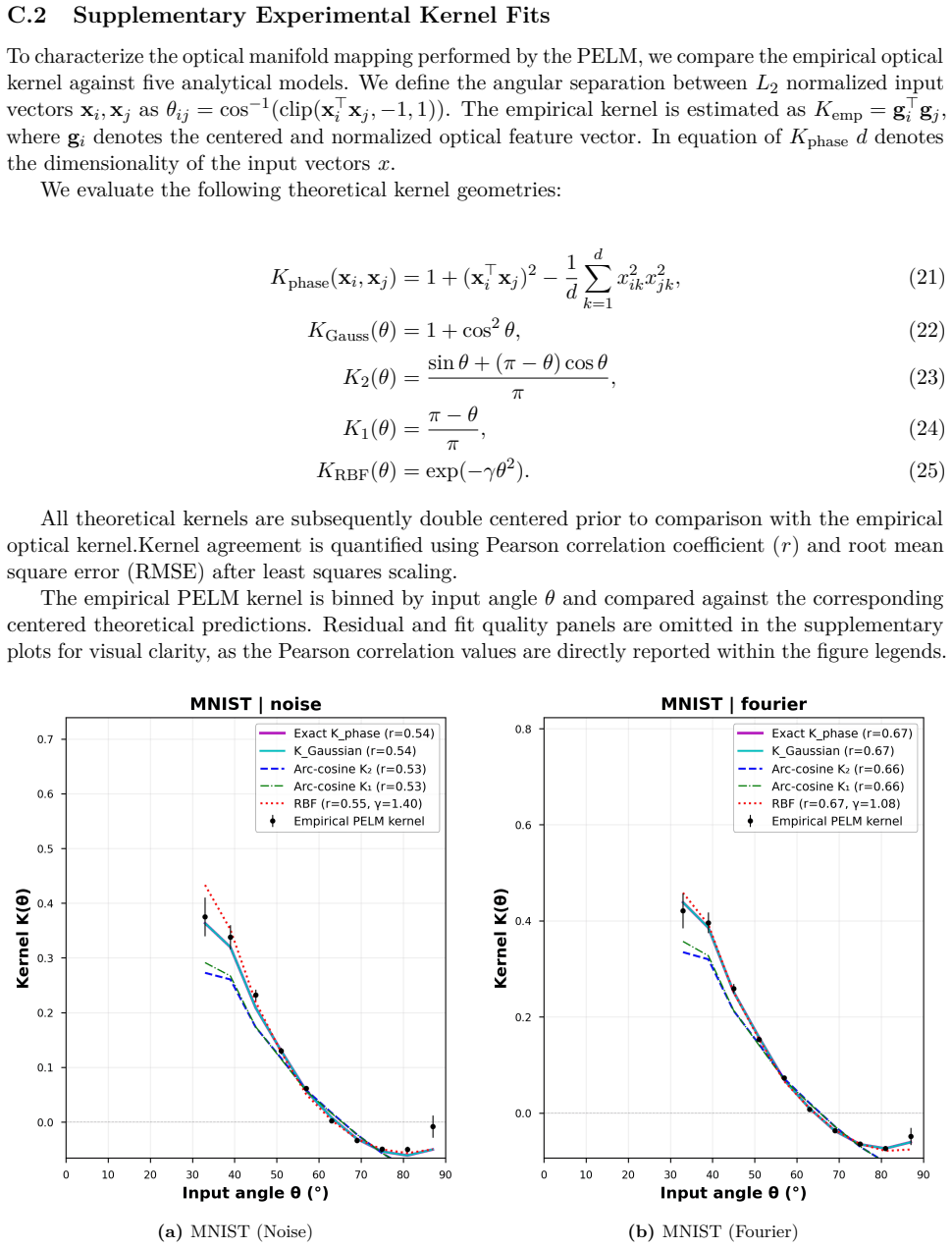
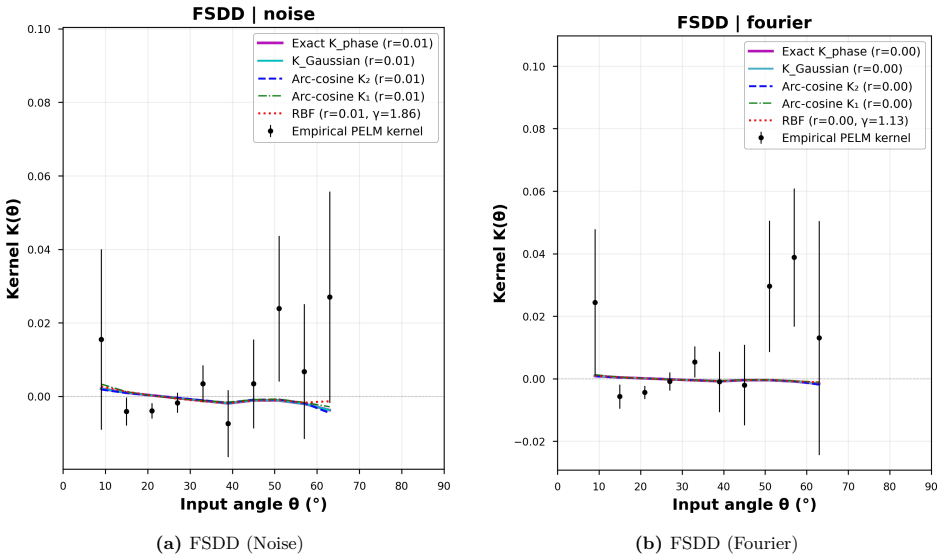
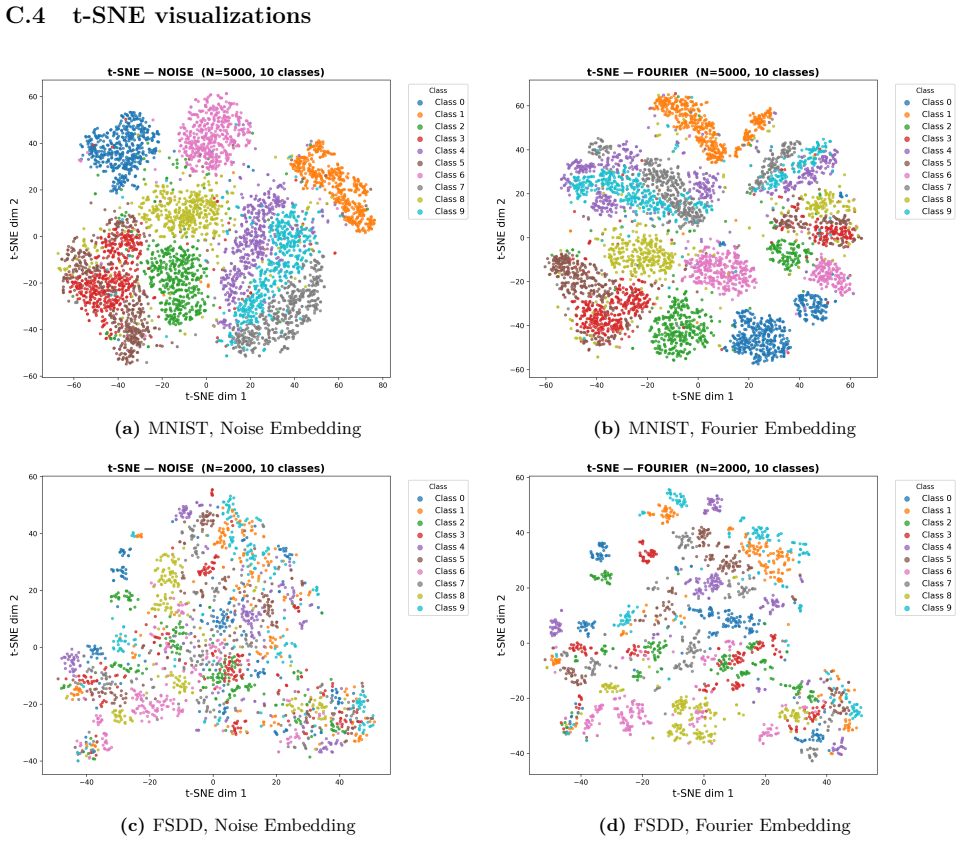
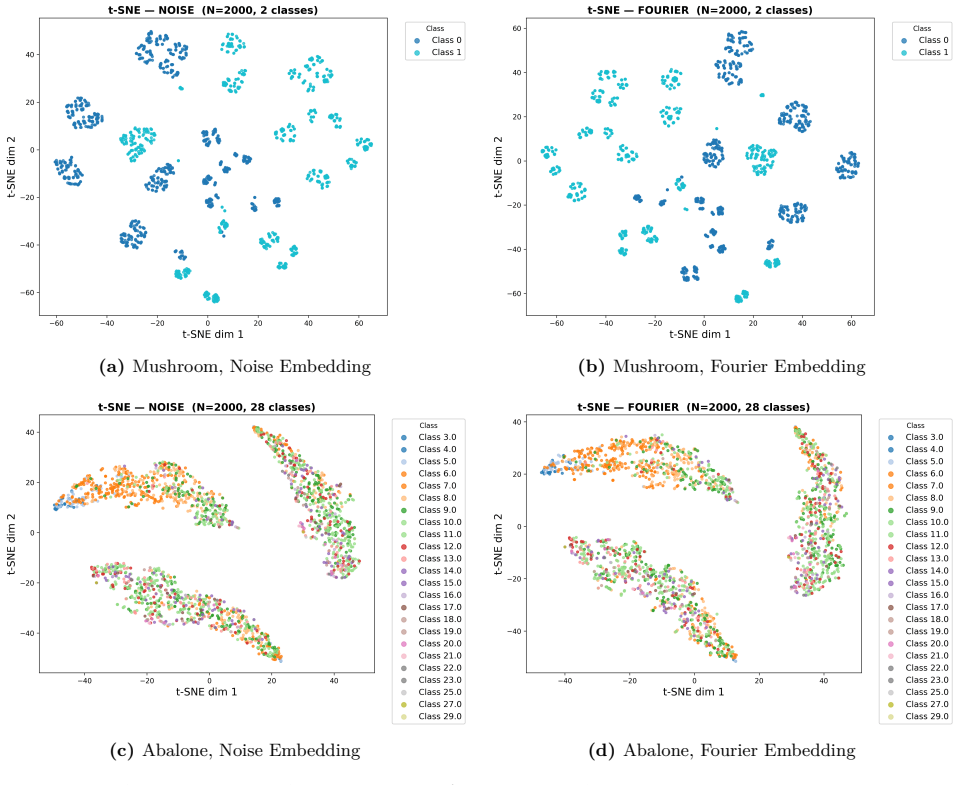
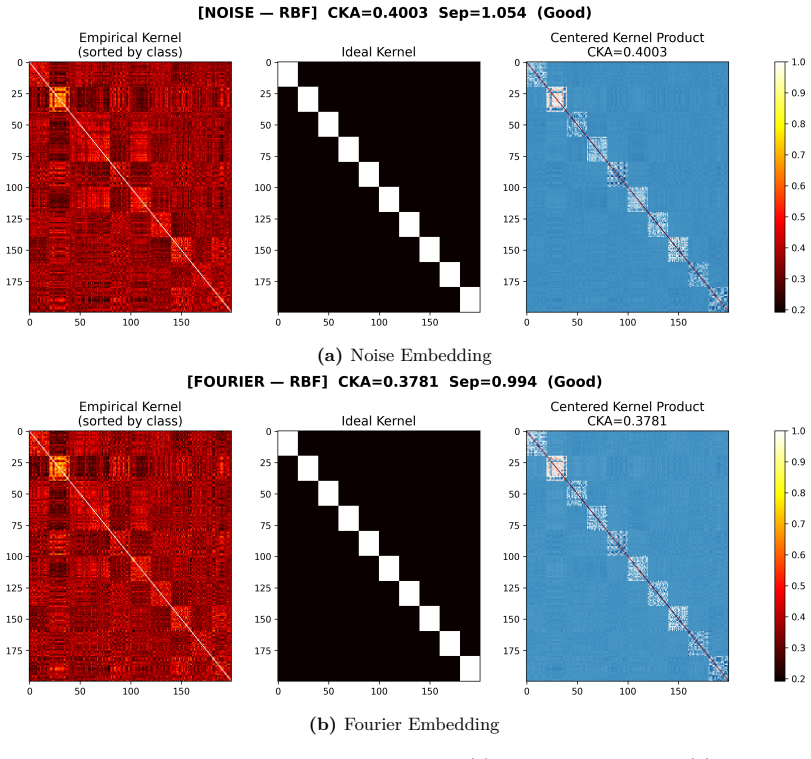
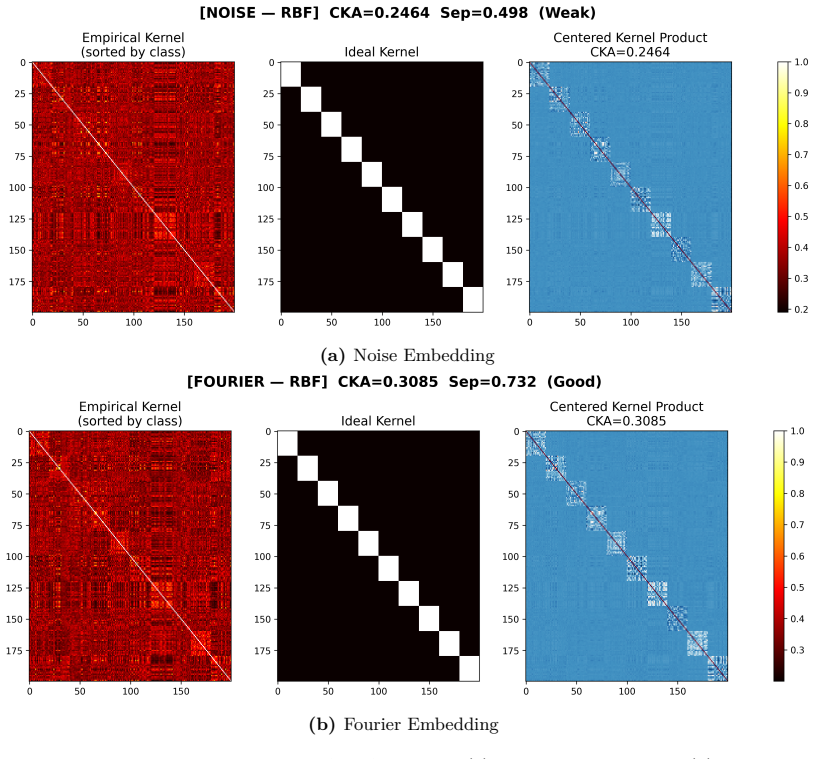
read the original abstract
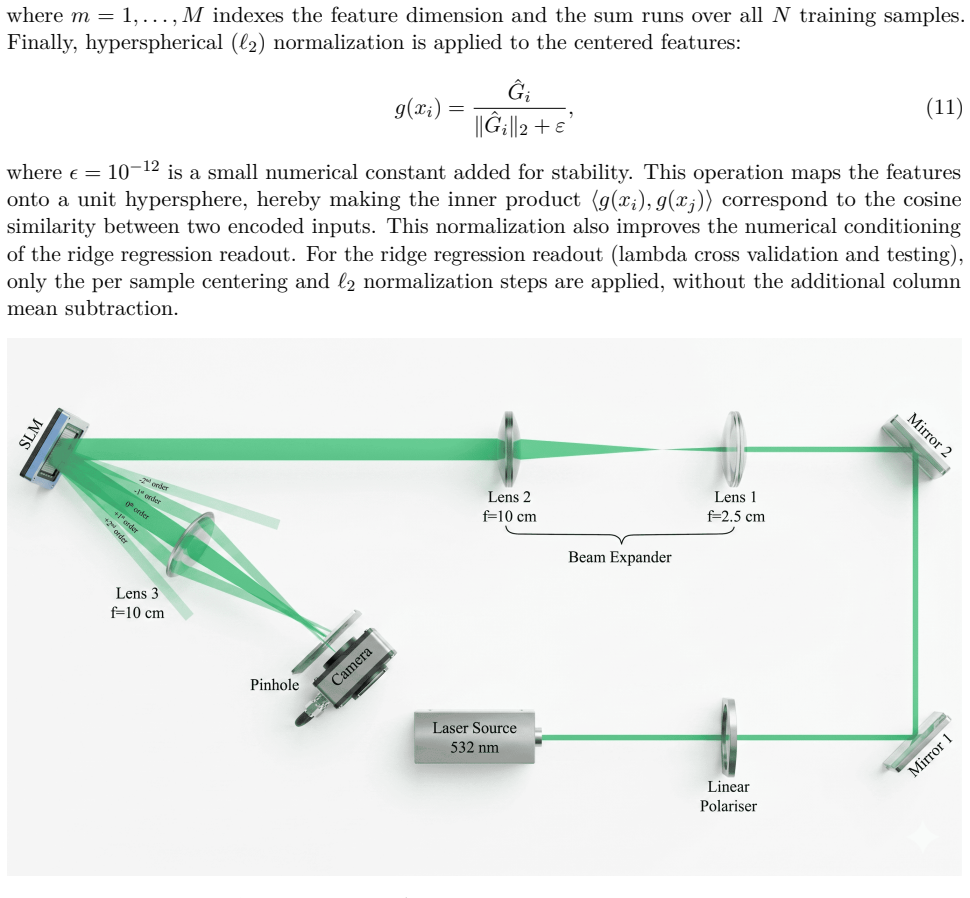
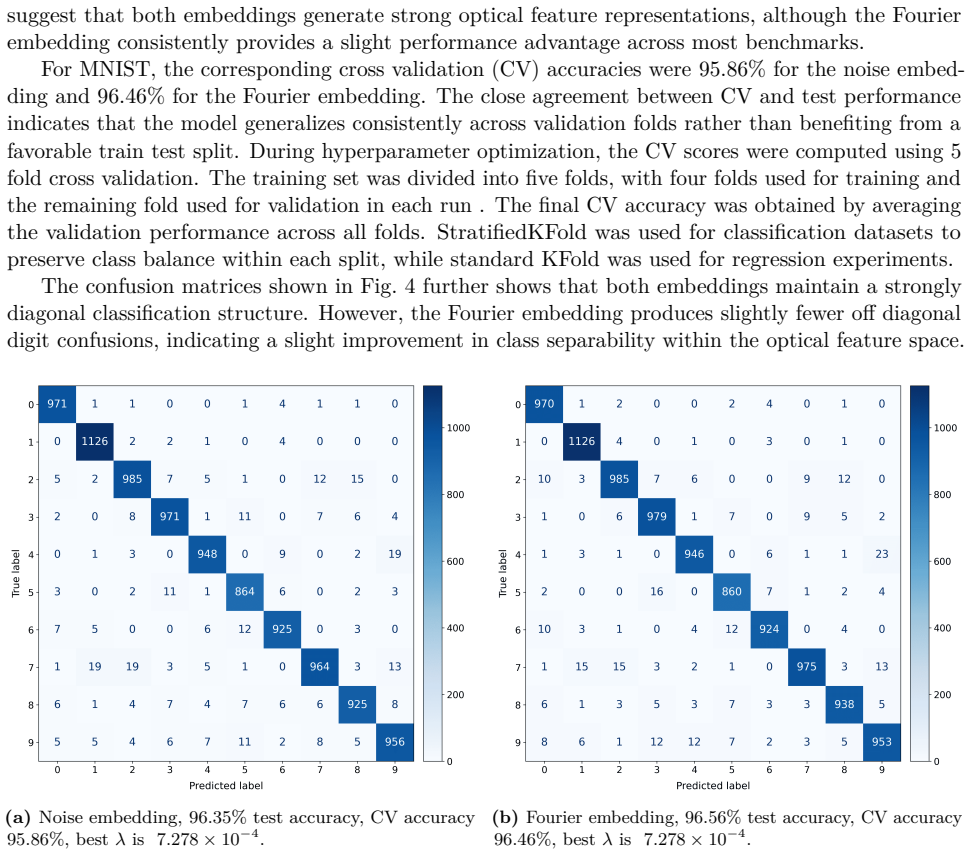
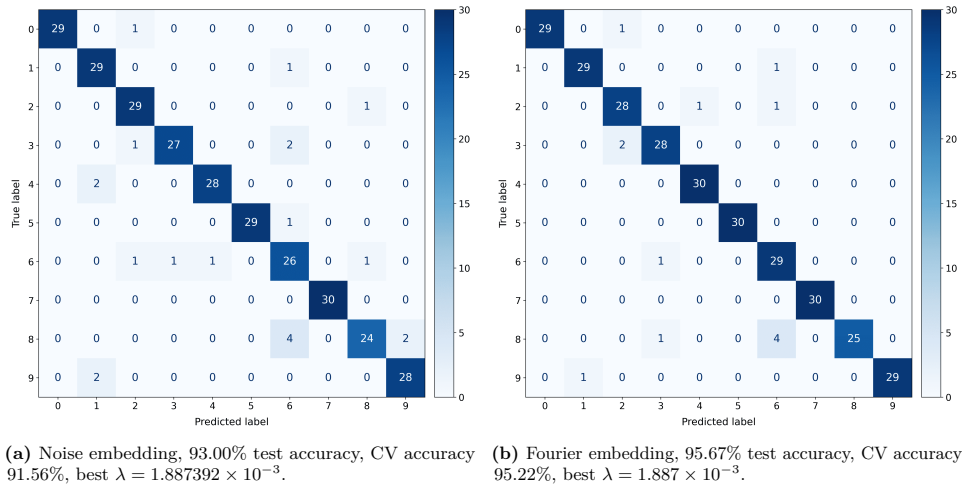
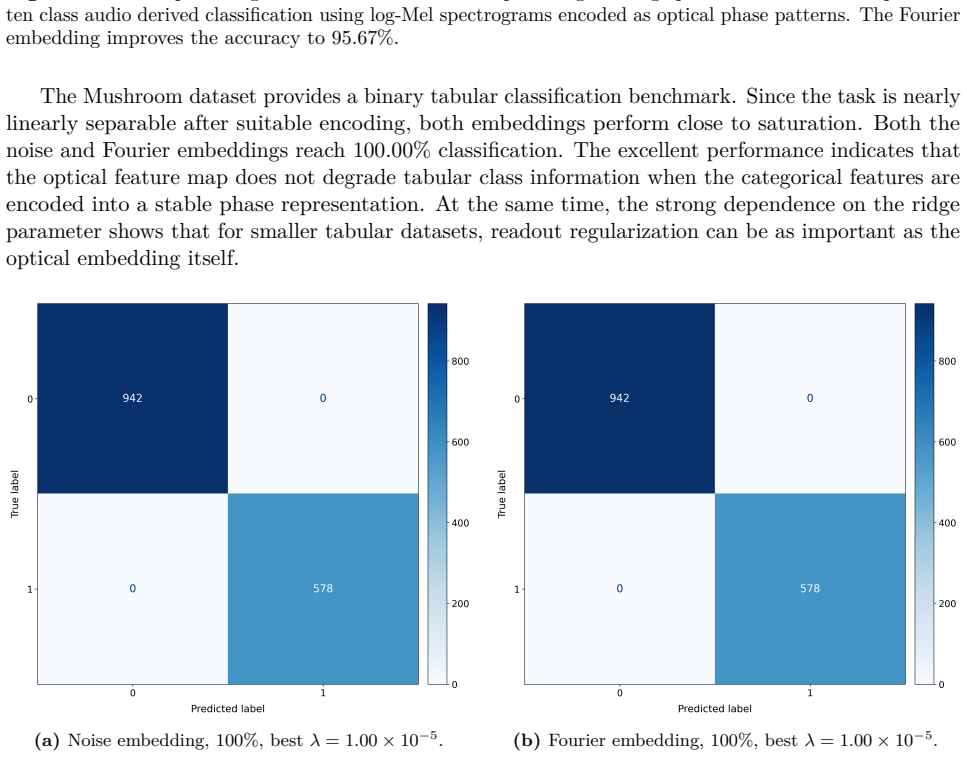
Photonic extreme learning machines (PELMs) replace a digitally trained hidden layer by a fixed optical transformation, allowing a high dimensional feature map to be generated by physical propagation while only the final readout is learned. Existing free-space PELM demonstrations have established this principle for image and tabular benchmarks, but a unified multimodal optical feature extractor spanning structurally different data types has remained largely undeveloped. Here we demonstrate a single free-space PELM platform for image, audio derived, binary tabular, and regression tasks using phase only SLM encoding, Fourier like free space propagation, and camera intensity detection. The same optical apparatus achieves 96.56% accuracy on MNIST, 95.67% on spoken digit audio from log-Mel spectrograms, 100.00% on Mushroom classification, and 0.0699 NRMSE on Abalone regression. To our knowledge, this is the first free space PELM spanning image, audio derived, and tabular tasks in one physical pipeline, and the first PELM implementation of spectrogram based spoken digit classification. Empirical distance preservation and kernel alignment diagnostics reveal two operating regimes: geometry preserving for image and regression tasks, and distributed class mean accumulation for audio derived spectrograms. These results establish multimodal PELMs as a practical route toward general purpose optical machine learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper demonstrates a single free-space photonic extreme learning machine (PELM) using phase-only SLM encoding, Fourier-like free-space propagation, and intensity detection that performs image classification on MNIST (96.56% accuracy), spoken-digit classification from log-Mel spectrograms (95.67% accuracy), binary tabular classification on the Mushroom dataset (100% accuracy), and regression on the Abalone dataset (0.0699 NRMSE) without optical reconfiguration between tasks. It reports two operating regimes (geometry-preserving for images/regression and class-mean accumulation for spectrograms) via distance-preservation and kernel-alignment diagnostics and claims this is the first such multimodal free-space PELM.
Significance. If the experimental claims hold, the work provides the first experimental demonstration of a free-space PELM spanning image, audio-derived spectrogram, and tabular modalities in one fixed physical pipeline, together with falsifiable diagnostics that distinguish geometry-preserving versus class-mean regimes. This strengthens the case for practical optical feature extraction beyond single-modality benchmarks.
major comments (2)
- [abstract and operating-regimes discussion] The central claim that a single fixed optical transformation generates a task-agnostic feature map is load-bearing for the multimodal result, yet the manuscript does not specify the exact 2D encoding procedure that maps the 22 categorical features of Mushroom and the 8 continuous features of Abalone onto the SLM phase pattern (normalization, possible one-hot or binning steps, reshaping/padding). Without this detail it is impossible to verify that the optical stage is equivalent to the direct pixel-to-phase mapping used for MNIST and log-Mel spectrograms (abstract and § on operating regimes).
- [abstract] Performance numbers (96.56%, 95.67%, 100%, 0.0699 NRMSE) are reported without any information on the number of independent experimental runs, error bars, training/test splits, or statistical significance tests. This absence directly undermines the reliability of the cross-modality comparison (abstract).
minor comments (1)
- [diagnostics section] Notation for the two operating regimes should be introduced with explicit equations or a table rather than only descriptive labels.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help strengthen the manuscript. We respond to each major comment below and will revise the manuscript to address the identified gaps in detail and statistical reporting.
read point-by-point responses
-
Referee: [abstract and operating-regimes discussion] The central claim that a single fixed optical transformation generates a task-agnostic feature map is load-bearing for the multimodal result, yet the manuscript does not specify the exact 2D encoding procedure that maps the 22 categorical features of Mushroom and the 8 continuous features of Abalone onto the SLM phase pattern (normalization, possible one-hot or binning steps, reshaping/padding). Without this detail it is impossible to verify that the optical stage is equivalent to the direct pixel-to-phase mapping used for MNIST and log-Mel spectrograms (abstract and § on operating regimes).
Authors: We agree that the encoding procedure for the tabular datasets requires explicit description to support the multimodal claim. In the revised manuscript we will insert a dedicated methods subsection that specifies: (i) one-hot encoding and min-max normalization of the 22 Mushroom features, followed by zero-padding and reshaping to a 64×64 phase grid; (ii) direct normalization and binning of the 8 Abalone features into the same grid format. These steps will be shown to be mathematically equivalent to the pixel-to-phase mapping used for MNIST and log-Mel spectrograms, thereby confirming that the same fixed optical pipeline is applied across modalities. revision: yes
-
Referee: [abstract] Performance numbers (96.56%, 95.67%, 100%, 0.0699 NRMSE) are reported without any information on the number of independent experimental runs, error bars, training/test splits, or statistical significance tests. This absence directly undermines the reliability of the cross-modality comparison (abstract).
Authors: We acknowledge that the absence of run statistics and error bars limits the strength of the reported figures. In the revised version we will augment the abstract and results section with: the number of independent experimental repetitions performed for each task, the corresponding standard deviations or error bars, the exact train/test split ratios employed, and any statistical significance tests (e.g., McNemar or paired t-tests) used to compare modalities. Where only single-run data exist due to experimental constraints, we will state this explicitly and discuss its implications for the cross-modality comparison. revision: yes
Circularity Check
No circularity; experimental results from physical measurements
full rationale
The paper reports measured classification accuracies and regression error from a physical free-space optical setup (phase-only SLM encoding, propagation, intensity detection) followed by digital linear readout training. No derivation chain, equations, or first-principles predictions are presented that reduce by construction to fitted inputs, self-citations, or ansatzes; the central claims rest on external benchmark performance obtained via hardware experiment rather than any self-referential mathematical step. The two operating regimes noted are diagnosed empirically from the same physical data, not imposed by definition.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Fourier optics governs the free-space propagation between SLM and camera
Reference graph
Works this paper leans on
-
[1]
Bernstein, and Philip Bertani
Michael Reck, Anton Zeilinger, Herbert J. Bernstein, and Philip Bertani. Experimental realization of any discrete unitary operator. Physical Review Letters , 73(1):58–61, 1994. doi: 10.1103/ PhysRevLett.73.58
1994
-
[2]
Clements, Peter C
William R. Clements, Peter C. Humphreys, Benjamin J. Metcalf, W. Steven Kolthammer, and Ian A. Walmsley. Optimal design for universal multiport interferometers.Optica, 3(12):1460–1465,
-
[3]
doi: 10.1364/OPTICA.3.001460
-
[4]
Harris, Scott Skirlo, Mihika Prabhu, Tom Baehr-Jones, Michael Hochberg, Xin Sun, Shijie Zhao, Hugo Larochelle, Dirk Englund, and Marin Soljačić
Yichen Shen, Nicholas C. Harris, Scott Skirlo, Mihika Prabhu, Tom Baehr-Jones, Michael Hochberg, Xin Sun, Shijie Zhao, Hugo Larochelle, Dirk Englund, and Marin Soljačić. Deep learning with coherent nanophotonic circuits.Nature Photonics, 11:441–446, 2017. doi: 10.1038/ nphoton.2017.93
2017
-
[5]
Quantum transport simulations in a pro- grammable nanophotonic processor
Nicholas C. Harris, Gregory R. Steinbrecher, Mihika Prabhu, Yoav Lahini, Jacob Mower, Darius Bunandar, Changchen Chen, Franco N. C. Wong, Tom Baehr-Jones, Michael Hochberg, Seth Lloyd, and Dirk Englund. Quantum transport simulations in a programmable nanophotonic processor. Nature Photonics, 11:447–452, 2017. doi: 10.1038/nphoton.2017.95
-
[6]
Wim Bogaerts, Daniel Pérez, José Capmany, David A. B. Miller, Joyce Poon, Dirk Englund, Francesco Morichetti, and Andrea Melloni. Programmable photonic circuits.Nature, 586(7828): 207–216, 2020. doi: 10.1038/s41586-020-2764-0
-
[7]
Yardimci, Muhammed Veli, Yi Luo, Mona Jarrahi, and Aydogan Ozcan
Xing Lin, Yair Rivenson, Nezih T. Yardimci, Muhammed Veli, Yi Luo, Mona Jarrahi, and Aydogan Ozcan. All-optical machine learning using diffractive deep neural networks.Science, 361(6406):1004–1008, 2018. doi: 10.1126/science.aat8084
-
[8]
Deniz Mengu, Yi Luo, Yair Rivenson, and Aydogan Ozcan. Analysis of diffractive optical neural networks and their integration with electronic neural networks.IEEE Journal of Selected Topics in Quantum Electronics, 26(1):8732486, 2020. doi: 10.1109/JSTQE.2019.2921376
-
[9]
Tao Yan, Rui Yang, Ziyang Zheng, Xing Lin, Hongkai Xiong, and Qionghai Dai. All-optical graph representation learning using integrated diffractive photonic computing units.Science Advances, 8(24):eabn7630, 2022. doi: 10.1126/sciadv.abn7630
-
[10]
Sophisticated deep learning with on-chip optical diffractive tensor processing
Yuyao Huang, Tingzhao Fu, Honghao Huang, Sigang Yang, and Hongwei Chen. Sophisticated deep learning with on-chip optical diffractive tensor processing. Photonics Research, 11(6): 1125–1138, 2023. doi: 10.1364/PRJ.484662
-
[11]
David Wright, Harish Bhaskaran, and Wolfram H
Carlos Rios, Matthias Stegmaier, Peiman Hosseini, Dandan Wang, Thomas Scherer, C. David Wright, Harish Bhaskaran, and Wolfram H. P. Pernice. Integrated all-photonic non-volatile multi-level memory. Nature Photonics, 9:725–732, 2015. doi: 10.1038/nphoton.2015.182
-
[12]
David Wright, Harish Bhaskaran, and Wolfram H
Johannes Feldmann, Nathan Youngblood, C. David Wright, Harish Bhaskaran, and Wolfram H. P. Pernice. All-optical spiking neurosynaptic networks with self-learning capabilities.Nature, 569:208–214, 2019. doi: 10.1038/s41586-019-1157-8
-
[13]
JohannesFeldmann, NathanYoungblood, MaximKarpov, HelgeGehring, XuanLi, MaikStappers, Manuel Le Gallo, Xin Fu, Anton Lukashchuk, Arslan S. Raja, Junqiu Liu, C. David Wright, Abu Sebastian, Tobias J. Kippenberg, Wolfram H. P. Pernice, and Harish Bhaskaran. Parallel convolutional processing using an integrated photonic tensor core.Nature, 589(7840):52–58, 20...
-
[14]
Zhongjin Lin, Bhavin J. Shastri, Shangxuan Yu, Jingxiang Song, Yuntao Zhu, Arman Safarne- jadian, Wangning Cai, Yanmei Lin, Wei Ke, Mustafa Hammood, Tianye Wang, Mengyue Xu, Zibo Zheng, Mohammed Al-Qadasi, Omid Esmaeeli, Mohamed Rahim, Grzegorz Pakulski, Jens Schmid, Pedro Barrios, Weihong Jiang, Hugh Morison, Matthew Mitchell, Xun Guan, Nicolas 30 A. F. ...
-
[15]
Daniel Brunner, Miguel C. Soriano, Claudio R. Mirasso, and Ingo Fischer. Parallel photonic information processing at gigabyte per second data rates using transient states.Nature Commu- nications, 4:1364, 2013. doi: 10.1038/ncomms2368
-
[16]
Luengo-Kovac, Joseph Pilawa, Timothy J
Upendra Paudel, M. Luengo-Kovac, Joseph Pilawa, Timothy J. Shaw, and George C. Valley. Classification of time-domain waveforms using a speckle-based optical reservoir computer.Optics Express, 28(2):1225–1237, 2020. doi: 10.1364/OE.28.001225
-
[17]
Physical Review X10, 041037 (2020) https://doi.org/10.1103/PhysRevX.10.041037
Mushegh Rafayelyan, Jing Dong, Yiqing Tan, Florent Krzakala, and Sylvain Gigan. Large-scale optical reservoir computing for spatiotemporal chaotic systems prediction.Physical Review X, 10:041037, 2020. doi: 10.1103/PhysRevX.10.041037
-
[18]
Hughes, Momchil Minkov, Yu Shi, and Shanhui Fan
Tyler W. Hughes, Momchil Minkov, Yu Shi, and Shanhui Fan. Training of photonic neural networks through in situ backpropagation and gradient measurement.Optica, 5(7):864–871, 2018. doi: 10.1364/OPTICA.5.000864
-
[19]
L2ight: En- ablingon-chiplearningforopticalneuralnetworksviaefficientin-situsubspaceoptimization
JiaqiGu, HanqingZhu, ChenghaoFeng, ZixuanJiang, RayT.Chen, andDavidZ.Pan. L2ight: En- ablingon-chiplearningforopticalneuralnetworksviaefficientin-situsubspaceoptimization. In Ad- vances in Neural Information Processing Systems , volume 34, 2021. URLhttps://proceedings. neurips.cc/paper/2021/hash/48aedb8880cab8c45637abc7493ecddd-Abstract.html
2021
-
[20]
Junwei Cheng, Chaoran Huang, Jialong Zhang, Bo Wu, Wenkai Zhang, Xinyu Liu, Jiahui Zhang, Yiyi Tang, Hailong Zhou, Qiming Zhang, Min Gu, Jianji Dong, and Xinliang Zhang. Multimodal deep learning using on-chip diffractive optics with in situ training capability.Nature Communications, 15(1):6189, 2024. doi: 10.1038/s41467-024-50677-3. URLhttps://doi.org/ 10...
-
[21]
Gordon Wetzstein, Aydogan Ozcan, Sylvain Gigan, Shanhui Fan, Dirk Englund, Marin Soljačić, Cornelia Denz, David A. B. Miller, and Demetri Psaltis. Inference in artificial intelligence with deep optics and photonics.Nature, 588:39–47, 2020. doi: 10.1038/s41586-020-2973-6
-
[22]
Bhavin J. Shastri, Alexander N. Tait, Thomas Ferreira de Lima, Wolfram H. P. Pernice, Harish Bhaskaran, C. David Wright, and Paul R. Prucnal. Photonics for artificial intelligence and neuromorphic computing. Nature Photonics, 15:102–114, 2021. doi: 10.1038/s41566-020-00754-y
-
[23]
Extreme learning machine: theory and applications
Guang-Bin Huang, Qin-Yu Zhu, and Chee-Kheong Siew. Extreme learning machine: theory and applications. Neurocomputing, 70(1–3):489–501, 2006. doi: 10.1016/j.neucom.2005.12.126
-
[24]
Photonic extreme learning machine by free- space optical propagation
Davide Pierangeli, Giulia Marcucci, and Claudio Conti. Photonic extreme learning machine by free- space optical propagation. Photonics Research, 9(8):1446–1454, 2021. doi: 10.1364/PRJ.423531
-
[25]
Free spoken digit dataset (fsdd)
Zohar Jackson. Free spoken digit dataset (fsdd). https://github.com/Jakobovski/ free-spoken-digit-dataset, 2017. Accessed: 2026-05-21
2017
-
[26]
Steven B. Davis and Paul Mermelstein. Comparison of parametric representations for monosyllabic word recognition in continuously spoken sentences.IEEE Transactions on Acoustics, Speech, and Signal Processing, 28(4):357–366, 1980. doi: 10.1109/TASSP.1980.1163420
-
[27]
Mushroom dataset.https://archive.ics.uci.edu/ml/ datasets/mushroom,
UCI Machine Learning Repository. Mushroom dataset.https://archive.ics.uci.edu/ml/ datasets/mushroom, . Accessed: 2026-05-21
2026
-
[28]
Abalone dataset
UCI Machine Learning Repository. Abalone dataset. https://archive.ics.uci.edu/ml/ datasets/abalone, . Accessed: 2026-05-21. 31
2026
-
[29]
Bernhard Schölkopf and Alexander J. Smola. Learning with Kernels: Support Vector Ma- chines, Regularization, Optimization, and Beyond . MIT Press, Cambridge, MA, 2002. ISBN 9780262194754
2002
-
[30]
Nello Cristianini, John Shawe-Taylor, André Elisseeff, and Jaz S. Kandola. On kernel-target alignment. In Advances in Neural Information Processing Systems , vol- ume 14, 2001. URL https://proceedings.neurips.cc/paper_files/paper/2001/hash/ 1f71e393b3809197ed66df836fe833e5-Abstract.html
2001
-
[31]
Similarity of neural network representations revisited
Simon Kornblith, Mohammad Norouzi, Honglak Lee, and Geoffrey Hinton. Similarity of neural network representations revisited. InProceedings of the 36th International Conference on Machine Learning, volume 97 ofProceedings of Machine Learning Research , pages 3519–3529. PMLR,
-
[32]
URL https://proceedings.mlr.press/v97/kornblith19a.html
-
[33]
Visualizing data using t-SNE
Laurens van der Maaten and Geoffrey Hinton. Visualizing data using t-SNE. Journal of Machine Learning Research , 9(86):2579–2605, 2008. URL http://jmlr.org/papers/v9/ vandermaaten08a.html. 32
2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.