SWORD: Spectral Wasserstein Online Regime Detection in Dynamic Networks
Pith reviewed 2026-06-29 00:05 UTC · model grok-4.3
The pith
SWORD improves online change point detection by comparing the mean of Chebyshev moments from two adjacent windows with L1 distance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
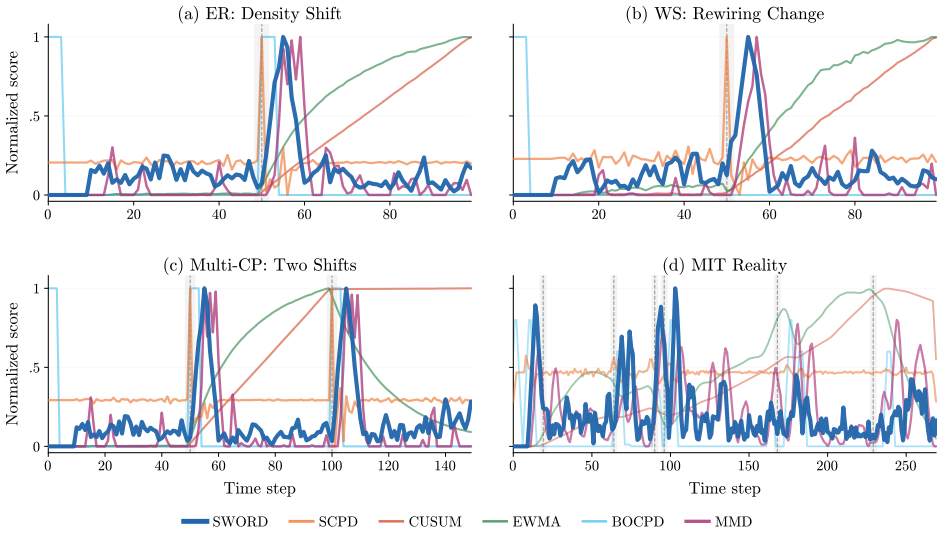
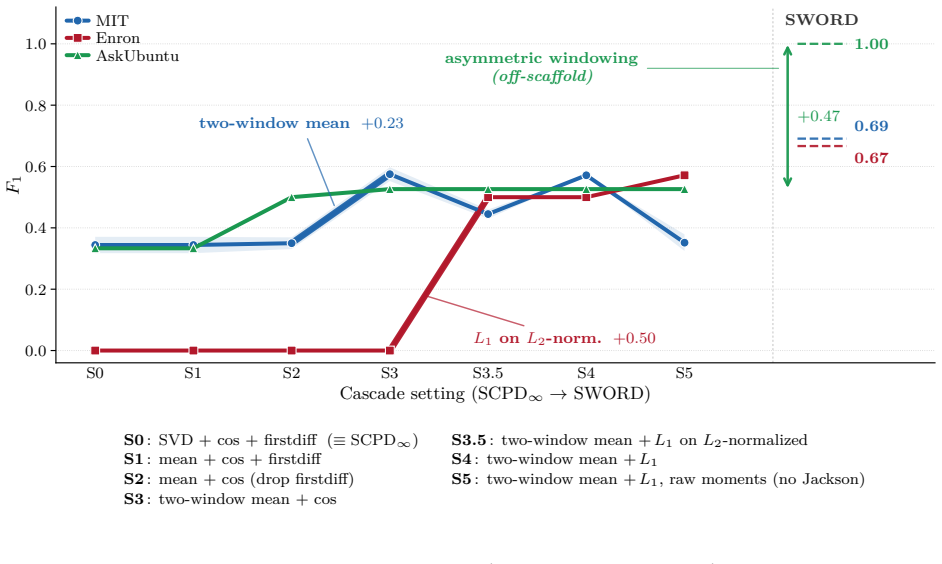
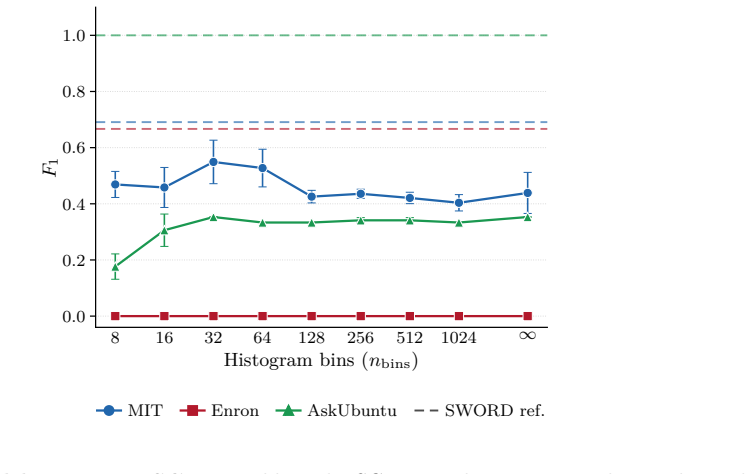
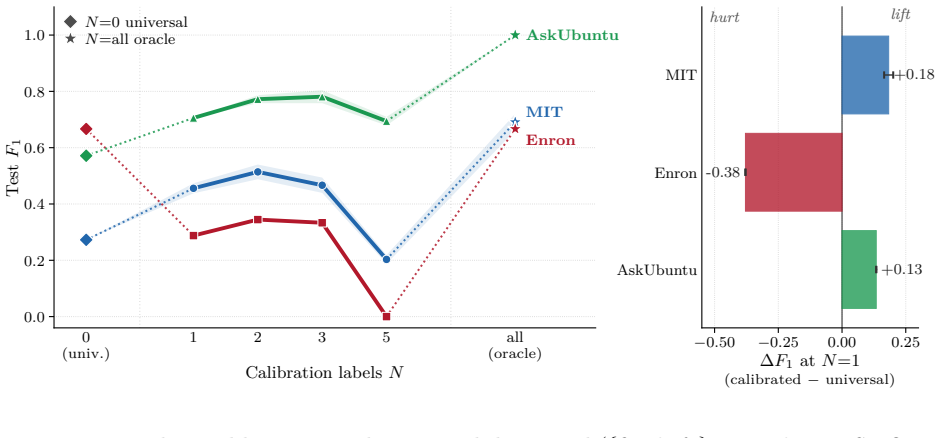
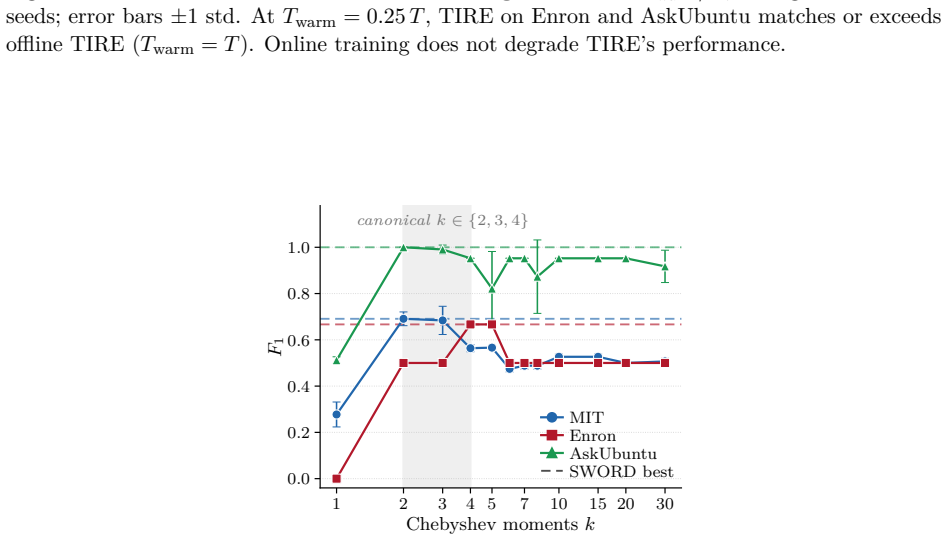
SWORD computes the same Chebyshev moments as SCPD but compares their mean across two adjacent time windows by L1 distance rather than discretizing them into a density-of-states histogram and scoring with SVD plus cosine similarity, lifting mean F1 from 0.27 to 0.79 on three real-world dynamic-network benchmarks while preserving linear scaling in the number of edges.
What carries the argument
The mean vector of KPM-computed Chebyshev moments of the normalized Laplacian taken over two adjacent windows and compared by L1 distance.
If this is right
- Mean F1 reaches 0.79 across the three benchmarks while SCPD fails entirely on Enron.
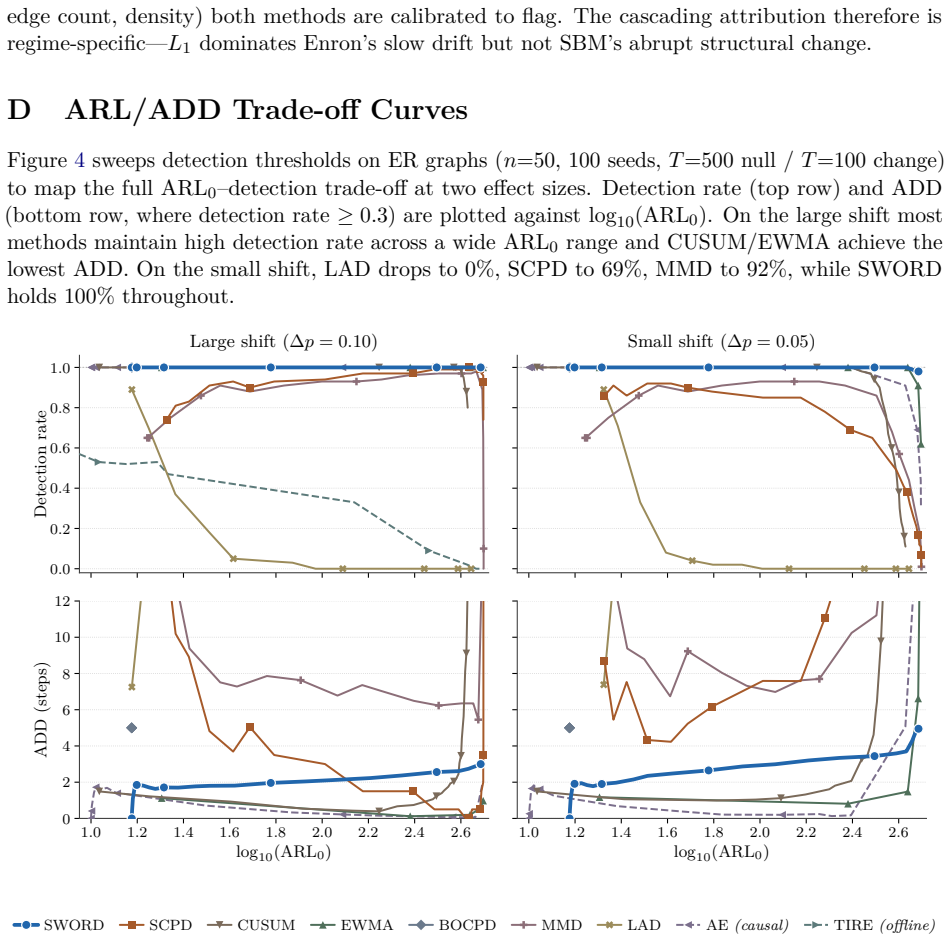
- Per-graph cost remains O(KRm) with no eigendecomposition, scaling to 86,000-node networks.
- With per-dataset tuning it matches the offline TIRE autoencoder on mean F1.
- It attains the highest precision (0.91) among online methods, with only two false positives total.
- Histogram bin width is ruled out as the driver of the prior performance gap.
Where Pith is reading between the lines
- The two-window averaging may supply the minimal temporal context needed to distinguish transient fluctuations from regime shifts in streaming graph data.
- Direct L1 comparison on moment vectors could be applied to other polynomial approximations or moment bases without requiring histogram construction.
- Because the method inherits the KPM core, it can be swapped into any pipeline already using Chebyshev expansions of graph operators.
- Controlled synthetic graphs with injected regime changes would isolate whether the L1-on-means advantage holds when edge density and noise are varied independently.
Load-bearing premise
The performance difference is attributable to the two-window mean structure and L1 metric as identified by the cascading ablation, rather than other unmentioned factors such as specific parameter choices or dataset characteristics.
What would settle it
Re-running the cascading ablation on the same three benchmarks after swapping only the two-window mean and L1 components back to histogram-plus-cosine yields F1 scores indistinguishable from the original SCPD baseline.
Figures
read the original abstract
Online change point detection in dynamic graphs requires comparing graphs as they arrive, in time linear in the number of edges, without parametric assumptions. Recent spectral methods address scale via the Kernel Polynomial Method (KPM): SCPD computes Chebyshev moments of the normalized Laplacian, discretizes them into a density-of-states histogram, and scores the histogram with SVD plus cosine similarity. We introduce SWORD, which computes the same moments and instead compares their mean across two adjacent time windows by their $L_1$ distance. On three real-world benchmarks (MIT Reality, AskUbuntu, Enron), this lifts mean $F_1$ from SCPD's $0.27$ to $0.79$, with SCPD failing to detect any change on Enron. A controlled cascading ablation attributes the gap to two design choices: the two-window mean structure (dominant on MIT) and the $L_1$ metric on those mean vectors (dominant on Enron). A bin-width sweep rules out histogram discretization -- SCPD's most visible architectural choice -- as the driver. SWORD inherits SCPD's KPM core, so per-graph cost is $O(KRm)$ with no eigendecomposition, scaling to $86{,}000$-node networks. With per-dataset tuning it matches the offline TIRE autoencoder on mean $F_1$ and attains the highest precision among online methods ($0.91$, only $2$ false positives across the three benchmarks).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SWORD, an online regime detection method for dynamic networks that inherits the Kernel Polynomial Method (KPM) Chebyshev moments from SCPD but replaces histogram discretization + SVD-cosine scoring with the mean of moments across two adjacent windows scored by L1 distance. On the MIT Reality, AskUbuntu, and Enron benchmarks it reports mean F1 of 0.79 (vs. SCPD's 0.27), matches offline TIRE under per-dataset tuning, and attains the highest online precision (0.91). A cascading ablation attributes the gains primarily to the two-window mean (dominant on MIT) and L1 metric (dominant on Enron), while a bin-width sweep rules out discretization as the driver. Per-graph cost remains O(KRm) with no eigendecomposition.
Significance. If the ablation isolates the claimed factors, the result supplies a simpler, empirically stronger online spectral baseline for change-point detection that scales to 86k-node networks and closes much of the gap to offline methods. The explicit cascading ablation, the direct comparison against both online (SCPD) and offline (TIRE) baselines, and the scaling claim are concrete strengths that would be useful to the community.
major comments (2)
- [Abstract / Experiments (cascading ablation)] Abstract and §4 (cascading ablation): the central attribution of the F1 lift (0.27→0.79) to the two-window mean and L1 metric rests on the claim that the ablation is 'controlled.' The manuscript states that final SWORD numbers use per-dataset tuning, yet does not explicitly confirm that K, window length, Laplacian normalization, and moment truncation were frozen identically across all ablation variants. If these were allowed to vary, the performance gap could arise from hyperparameter differences rather than the two design choices highlighted. This is load-bearing for the paper's explanation of why SWORD outperforms SCPD.
- [Abstract / Table 1 or equivalent results table] Abstract / Results on Enron: the statement that 'SCPD failing to detect any change on Enron' is used to support the aggregate 0.79 vs 0.27 claim. The per-dataset F1 (or detection count) for SCPD on Enron should be reported explicitly so readers can verify the magnitude of the improvement and assess whether the L1 metric is the dominant factor as asserted.
minor comments (2)
- [Abstract] The abstract refers to 'mean F1' and 'highest precision' but does not state whether these are macro- or micro-averaged across the three benchmarks; adding this detail would improve reproducibility.
- [Methods] Notation for the two-window mean vector and the precise definition of the L1 distance on moment vectors could be given an equation number in the methods section for easier reference in the ablation discussion.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our ablation study and results. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract / Experiments (cascading ablation)] Abstract and §4 (cascading ablation): the central attribution of the F1 lift (0.27→0.79) to the two-window mean and L1 metric rests on the claim that the ablation is 'controlled.' The manuscript states that final SWORD numbers use per-dataset tuning, yet does not explicitly confirm that K, window length, Laplacian normalization, and moment truncation were frozen identically across all ablation variants. If these were allowed to vary, the performance gap could arise from hyperparameter differences rather than the two design choices highlighted. This is load-bearing for the paper's explanation of why SWORD outperforms SCPD.
Authors: The cascading ablation was performed with K, window length, Laplacian normalization, and moment truncation held fixed at the values used for the final per-dataset SWORD configurations; only the two-window mean structure and L1 metric were varied. Per-dataset tuning was applied solely to select those fixed values for the complete method, not re-tuned independently for each ablation variant. We will revise §4 to state this explicitly and add a footnote confirming the shared hyperparameter settings. revision: yes
-
Referee: [Abstract / Table 1 or equivalent results table] Abstract / Results on Enron: the statement that 'SCPD failing to detect any change on Enron' is used to support the aggregate 0.79 vs 0.27 claim. The per-dataset F1 (or detection count) for SCPD on Enron should be reported explicitly so readers can verify the magnitude of the improvement and assess whether the L1 metric is the dominant factor as asserted.
Authors: We agree that explicit per-dataset values improve verifiability. SCPD records zero detections on Enron (F1 = 0), while SWORD records F1 = 0.92 on the same dataset. We will add a supplementary table (or expand Table 1) listing per-dataset F1, precision, and recall for SCPD, SWORD, and TIRE on all three benchmarks. revision: yes
Circularity Check
No circularity: empirical variant evaluated on external benchmarks
full rationale
The paper proposes SWORD as a direct algorithmic variant of SCPD (same KPM moments, but mean across windows scored by L1 instead of histogram + SVD/cosine). The central claim is an empirical F1 lift on three named external datasets, with attribution via cascading ablation on those same datasets. No derivation chain, no fitted parameter renamed as prediction, no self-citation invoked as uniqueness theorem, and no ansatz or renaming of known results. The method is self-contained against the cited baseline and public benchmarks; performance numbers do not reduce to the inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Chebyshev moments computed via KPM provide a sufficient approximation for comparing graph spectra in change detection tasks.
Reference graph
Works this paper leans on
-
[1]
R. P. Adams and D. J. C. MacKay. Bayesian online changepoint detection.arXiv preprint arXiv:0710.3742,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
doi: 10.1145/3519935.3520009. arXiv:2104.03461. T. De Ryck, M. De Vos, and A. Bertrand. Change point detection in time series data using autoencoders with a time-invariant representation. InIEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 3720–3724,
-
[3]
doi: 10.1287/opre.2021.0413. A. Gretton, K. M. Borgwardt, M. J. Rasch, B. Schölkopf, A. Smola, et al. A kernel two-sample test. Journal of Machine Learning Research, 13:723–773,
-
[4]
doi: 10.1016/j.patcog.2025. 111855. S. Huang, Y. Hitti, G. Rabusseau, and R. Rabbany. Laplacian change point detection for dynamic graphs. InProceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 349–358,
- [5]
-
[6]
G. Lorden. Procedures for reacting to a change in distribution.The Annals of Mathematical Statistics, 42(6):1897–1908,
1908
- [7]
-
[8]
arXiv:2408.12385. R. Musco and C. Musco. Improved spectral density estimation via explicit and implicit deflation. Proceedings of the ACM-SIAM Symposium on Discrete Algorithms (SODA),
work page internal anchor Pith review Pith/arXiv arXiv
- [9]
-
[10]
and SCPD (Huang et al., 2023), replacing LAD’s exact eigenvalue signatures with KPM-approximated DOS histograms while keeping the same two-window SVD + cosine detection. The only algorithmic difference from SCPD is the order of two operations: LADdos clamps the first-differenceZ∗to non-negative per window before taking the max, whereas SCPD takes the max ...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.