CARM Tool: Cache-Aware Roofline Model Automatic Benchmarking and Application Analysis
Pith reviewed 2026-06-29 05:39 UTC · model grok-4.3
The pith
An automated tool constructs accurate Cache-Aware Roofline Models for Intel, AMD, ARM, and RISC-V CPUs using custom microbenchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
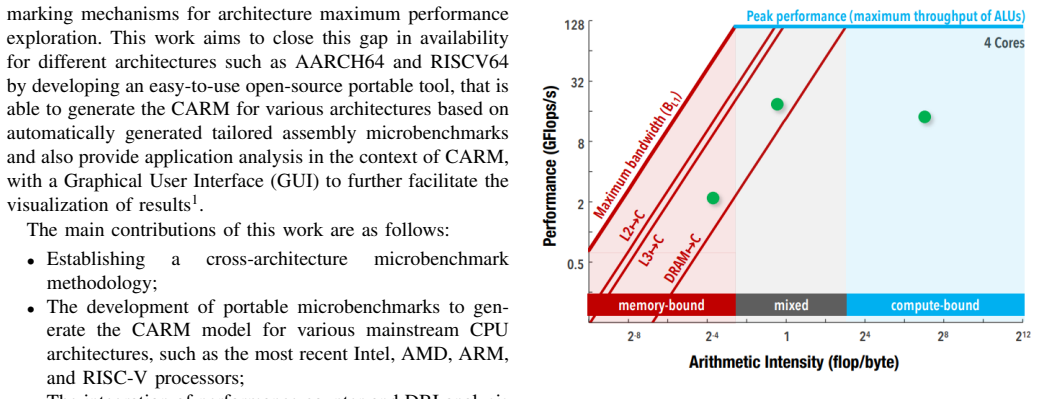
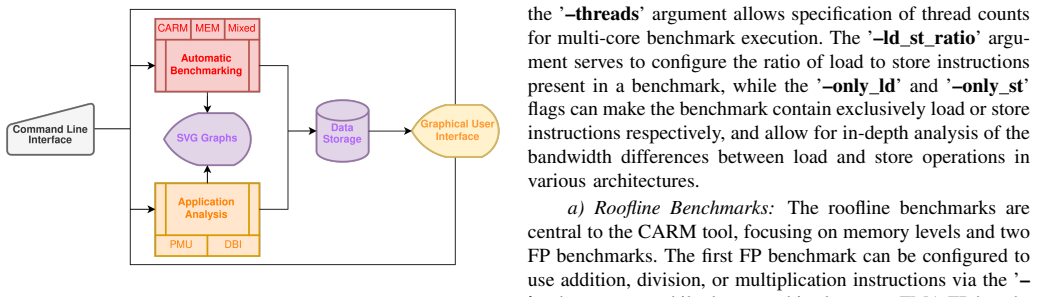
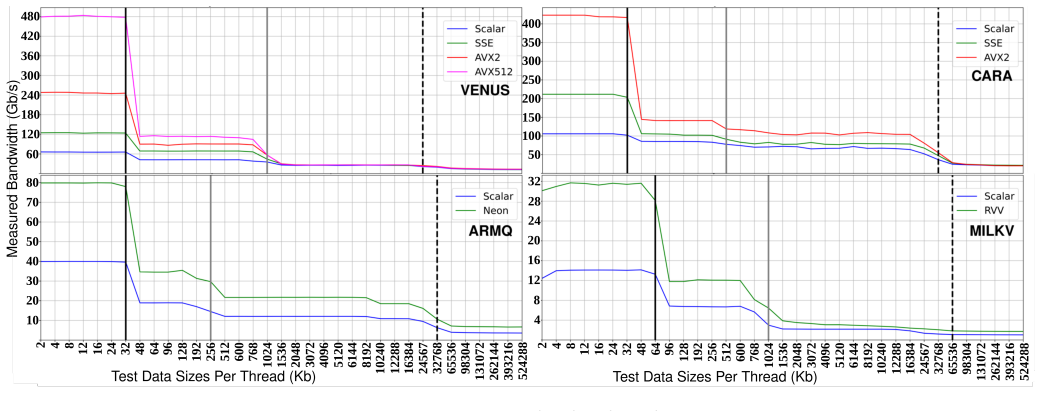
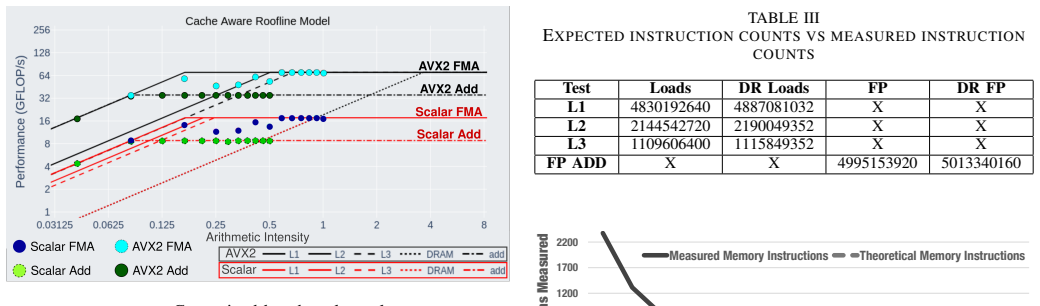
The paper presents the CARM Tool, an automated framework that builds Cache-Aware Roofline Models by executing architecture-specific assembly microbenchmarks covering scalar through all supported vector ISA extensions for both computational units and every level of the memory hierarchy, while integrating application characterization via performance counters and dynamic binary instrumentation; the constructed roofs deviate less than 1 percent from independently verified architectural maximums across tested systems.
What carries the argument
Architecture-specific assembly microbenchmarks that saturate computational units and memory hierarchy levels, executed inside an automated benchmarking and analysis framework to populate CARM roofs.
If this is right
- CARM optimization guidance becomes available for AMD, ARM, and RISC-V CPUs where no comparable automated tools existed.
- Application analysis is integrated directly into the CARM framework through performance counters and dynamic binary instrumentation.
- Roof values remain within 1 percent of architectural maximums across the tested systems.
- Microbenchmarks span the full spectrum from scalar to all supported vector ISA extensions for each architecture.
Where Pith is reading between the lines
- The same microbenchmark approach could be applied to future ISA extensions or new CPU designs as they appear.
- Coupling the tool with compiler feedback loops might allow automatic code transformations guided by the generated roofs.
- Comparison of roofs across vendors could highlight systematic differences in memory hierarchy behavior.
Load-bearing premise
The custom assembly microbenchmarks fully saturate every computational unit and memory level without hidden bottlenecks or measurement artifacts.
What would settle it
Independent measurement of a known peak performance on any tested architecture that differs by more than 1 percent from the roof produced by the tool's microbenchmarks.
Figures
read the original abstract
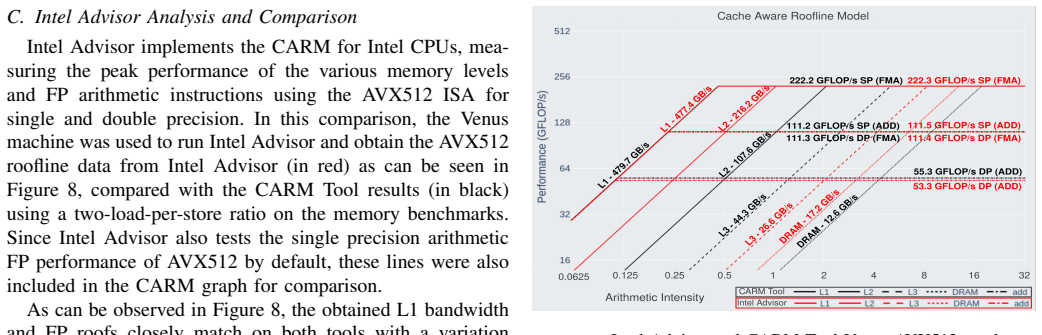
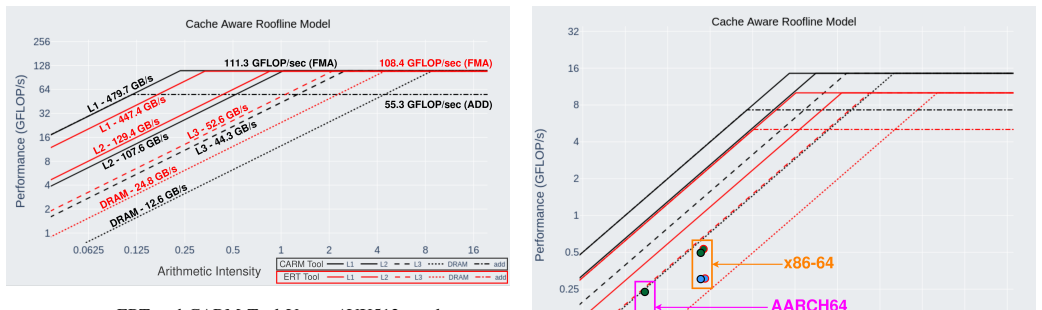
In recent years, HPC systems and CPU architectures as their central components, have become increasingly complex, making application development and optimization quite challenging. In this respect, intuitive performance models like the Cache-aware Roofline Model (CARM) offer effective guidance by providing insights into bottlenecks that limit the application's ability to reach the system's maximum performance. To fully exploit the benefits of CARM optimization guidance for application development, automatic tools for cross-architecture model construction and in-depth application characterization are absolutely essential. Given a plethora of existing CPU architectures, the current landscape of CARM-enabled tools covers either vendor-specific (Intel Advisor), not sufficiently developed (ARM) or simply non-existing (AMD, RISC-V) tools. This is a particular gap that this work intends to close by bringing automatic CARM support to all major CPU architectures and ISAs, i.e., x86 (Intel, AMD), ARM, and RISC-V, by developing assembly microbenchmarks specifically tailored to cover a full performance spectrum of modern CPUs (from scalar to all supported vector ISA extensions) for both computational units and all memory hierarchy levels. Additionally, this work integrates application analysis within the CARM framework using performance counters and dynamic binary instrumentation. Experimental results show that the CARM roofs constructed with the proposed automated framework provide less than a 1% deviation across various tested architectural maximums.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents the CARM Tool, an automated framework for constructing Cache-Aware Roofline Models across x86 (Intel, AMD), ARM, and RISC-V CPUs. It develops custom assembly microbenchmarks tailored to scalar through vector ISA extensions and all memory hierarchy levels, then integrates application characterization via performance counters and dynamic binary instrumentation. The central empirical claim is that roofs built with this framework deviate by less than 1% from the tested architectures' maximums.
Significance. If the saturation accuracy of the microbenchmarks is independently verified, the work would fill a genuine tooling gap by delivering open CARM support for non-Intel ISAs, directly aiding performance analysis and optimization on a broad range of modern CPUs. The multi-architecture microbenchmark approach and integration of dynamic instrumentation are practical strengths that could see adoption if the <1% result is shown to be robust.
major comments (2)
- [Abstract] Abstract (and results section): the quantitative claim of <1% deviation from architectural maximums is load-bearing for the paper's contribution, yet the manuscript supplies no description of the independent reference values used for the maximums, no error analysis, and no saturation verification procedure (e.g., performance-counter utilization rates or comparison against vendor peak FLOPS/bandwidth specifications).
- [Microbenchmark design] Microbenchmark design section: the central assumption that the custom assembly kernels saturate every computational unit and cache level without hidden contention or measurement artifacts is not supported by any cross-validation experiments; if saturation is incomplete for any ISA extension, the reported roofs would systematically understate the true maxima and the <1% figure would not hold.
minor comments (1)
- [Abstract] The first sentence of the abstract contains an awkward phrasing ("HPC systems and CPU architectures as their central components") that could be clarified for readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential value of the CARM Tool for multi-architecture support. We address each major comment below and commit to revisions that directly strengthen the empirical claims.
read point-by-point responses
-
Referee: [Abstract] Abstract (and results section): the quantitative claim of <1% deviation from architectural maximums is load-bearing for the paper's contribution, yet the manuscript supplies no description of the independent reference values used for the maximums, no error analysis, and no saturation verification procedure (e.g., performance-counter utilization rates or comparison against vendor peak FLOPS/bandwidth specifications).
Authors: We agree that the manuscript currently lacks explicit documentation of the reference values, error analysis, and saturation verification. In the revised version we will add a new subsection (in both the methods and results) that (i) lists the independent reference values (vendor peak FLOPS/bandwidth specifications together with our own microbenchmark-derived maxima), (ii) reports the error analysis performed, and (iii) details the saturation verification procedure, including performance-counter utilization rates and direct comparisons against vendor peaks for each ISA extension and memory level. These additions will make the <1% claim fully traceable. revision: yes
-
Referee: [Microbenchmark design] Microbenchmark design section: the central assumption that the custom assembly kernels saturate every computational unit and cache level without hidden contention or measurement artifacts is not supported by any cross-validation experiments; if saturation is incomplete for any ISA extension, the reported roofs would systematically understate the true maxima and the <1% figure would not hold.
Authors: We acknowledge that the current manuscript does not present explicit cross-validation experiments for saturation. We will extend the microbenchmark design section with additional validation results: achieved versus vendor peak FLOPS/bandwidth for every supported ISA extension on each architecture, together with performance-counter utilization data demonstrating that computational units and memory hierarchy levels reach saturation without measurable contention. These experiments will be reported for all four ISAs (Intel, AMD, ARM, RISC-V). revision: yes
Circularity Check
No circularity; empirical benchmarking results are independent of fitted inputs or self-citations
full rationale
The paper describes development of custom assembly microbenchmarks to automatically construct CARM roofs for multiple ISAs and architectures, followed by experimental measurement of <1% deviation from architectural maxima. No equations, derivations, or predictions are presented that reduce to inputs by construction; the central claim rests on direct empirical comparison rather than self-referential fitting, renaming, or load-bearing self-citations. The methodology is self-contained against external architectural specifications and performance measurements.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
(2024) Amd uprof user guide
AMD. (2024) Amd uprof user guide. [Online]. Avail- able: https://www.amd.com/content/dam/amd/en/documents/developer/ uprof-v4.0-gaGA-user-guide.pdf
2024
-
[2]
Aergia: leveraging heterogeneity in federated learning systems,
B. Cox, L. Y . Chen, and J. Decouchant, “Aergia: leveraging heterogeneity in federated learning systems,” inProceedings of the 23rd ACM/IFIP International Middleware Conference, ser. Middleware ’22. New York, NY , USA: Association for Computing Machinery, 2022, p. 107–120. [Online]. Available: https://doi.org/10.1145/3528535.3565238
-
[3]
Reducing the bandwidth of sparse symmetric matrices,
E. Cuthill and J. McKee, “Reducing the bandwidth of sparse symmetric matrices,” inProceedings of the 1969 24th National Conference, ser. ACM ’69. New York, NY , USA: Association for Computing Machinery, 1969, p. 157–172. [Online]. Available: https://doi.org/10.1145/800195.805928
-
[4]
T. Davis. Sparse matrix collection. Accessed on 5th October 2023. [Online]. Available: https://sparse.tamu.edu/
2023
-
[5]
The new linux’perf’tools,
A. C. De Melo, “The new linux’perf’tools,” inSlides from Linux Kongress, vol. 18, 2010, pp. 1–42
2010
-
[6]
An instruction roofline model for gpus,
N. Ding and S. Williams, “An instruction roofline model for gpus,” in 2019 IEEE/ACM Performance Modeling, Benchmarking and Simulation of High Performance Computer Systems (PMBS), 2019, pp. 7–18
2019
-
[7]
(2024) Dynamorio webpage
DynamoRIO. (2024) Dynamorio webpage. [Online]. Available: https: //dynamorio.org/
2024
-
[8]
(2024) Eigen library main page
Eigen. (2024) Eigen library main page. [Online]. Available: https: //eigen.tuxfamily.org/index.php?title=Main Page
2024
-
[9]
Cache-aware roofline model: Upgrading the loft,
A. Ilic, F. Pratas, and L. Sousa, “Cache-aware roofline model: Upgrading the loft,”IEEE Computer Architecture Letters, vol. 13, no. 1, pp. 21–24, 2013
2013
-
[10]
(2023) Intel advisor carm overview
Intel. (2023) Intel advisor carm overview. [Online]. Available: https://www.intel.com/content/www/us/en/developer/articles/ technical/integrated-roofline-model-with-intel-advisor.html
2023
-
[11]
(2024) Intel 64 and ia-32 architectures optimization reference manual volume 1
——. (2024) Intel 64 and ia-32 architectures optimization reference manual volume 1. [Online]. Available: https://www.intel.com/content/www/us/en/content-details/671488/ intel-64-and-ia-32-architectures-optimization-reference-manual-volume-1. html
2024
-
[12]
(2024) Intel sde overview
——. (2024) Intel sde overview. [Online]. Avail- able: https://www.intel.com/content/www/us/en/developer/articles/tool/ software-development-emulator.html
2024
-
[13]
A novel multi-level integrated roofline model approach for performance characterization,
T. Koskela, Z. Matveev, C. Yang, A. Adedoyin, R. Belenov, P. Thierry, Z. Zhao, R. Gayatri, H. Shan, L. Oliker, J. Deslippe, R. Green, and S. Williams, “A novel multi-level integrated roofline model approach for performance characterization,” inHigh Performance Computing, R. Yokota, M. Weiland, D. Keyes, and C. Trinitis, Eds. Cham: Springer International P...
2018
-
[14]
B. Lab. (2024) Empirical roofline tool bitbucket repository. [Online]. Available: https://bitbucket.org/berkeleylab/cs-roofline-toolkit/ src/master/
2024
-
[15]
Ai-enabling workloads on large-scale gpu-accelerated system: Characterization, op- portunities, and implications,
B. Li, R. Arora, S. Samsi, T. Patel, W. Arcand, D. Bestor, C. Byun, R. B. Roy, B. Bergeron, J. Holodnak, M. Houle, M. Hubbell, M. Jones, J. Kepner, A. Klein, P. Michaleas, J. McDonald, L. Milechin, J. Mullen, A. Prout, B. Price, A. Reuther, A. Rosa, M. Weiss, C. Yee, D. Edelman, A. Vanterpool, A. Cheng, V . Gadepally, and D. Tiwari, “Ai-enabling workloads...
2022
-
[16]
Application-driven cache-aware roofline model,
D. Marques, A. Ilic, Z. A. Matveev, and L. Sousa, “Application-driven cache-aware roofline model,”Future Generation Computer Systems, vol. 107, pp. 257–273, 2020
2020
-
[17]
Papi: A portable interface to hardware performance counters,
P. Mucci, S. Moore, C. Deane, and G. Ho, “Papi: A portable interface to hardware performance counters,” 01 1999
1999
-
[18]
(2024) Xuantie c910-c920 usermanual
Sophgo. (2024) Xuantie c910-c920 usermanual. [Online]. Avail- able: https://github.com/sophgo/sophgo-doc/blob/main/SG2042/T-Head/ XuanTie-C910-C920-UserManual.pdf
2024
-
[19]
Likwid: A lightweight performance-oriented tool suite for x86 multicore environments,
J. Treibig, G. Hager, and G. Wellein, “Likwid: A lightweight performance-oriented tool suite for x86 multicore environments,” in 2010 39th International Conference on Parallel Processing Workshops, 2010, pp. 207–216
2010
-
[20]
Roofline: an insightful visual performance model for multicore architectures,
S. Williams, A. Waterman, and D. Patterson, “Roofline: an insightful visual performance model for multicore architectures,”Communications of the ACM, vol. 52, no. 4, pp. 65–76, 2009
2009
-
[21]
High-performance computing environment: A review of twenty years of experiments in china,
Z. Xu, X. Chi, and N. Xiao, “High-performance computing environment: A review of twenty years of experiments in china,”National Science Review, vol. 3, p. nww001, 01 2016
2016
-
[22]
An empirical roofline methodology for quantitatively assessing per- formance portability,
C. Yang, R. Gayatri, T. Kurth, P. Basu, Z. Ronaghi, A. Adetokunbo, B. Friesen, B. Cook, D. Doerfler, L. Oliker, J. Deslippe, and S. Williams, “An empirical roofline methodology for quantitatively assessing per- formance portability,” in2018 IEEE/ACM International Workshop on Performance, Portability and Productivity in HPC (P3HPC), 2018, pp. 14–23. APPEND...
-
[23]
Users need to clone this repository for the artifact evaluation
How to access:The tool can be accessed via its GitHub repository. Users need to clone this repository for the artifact evaluation
-
[24]
Hardware dependencies:A system that contains an x86- 64 CPU (Intel Skylake-X) is ideal for reproducing most results from the paper, however, other CPUs can be used, in which case an A VX-512 capable CPU allows for more comparable results
-
[25]
Software dependencies:The tool has been mostly tested under Linux Ubuntu or Cent OS, however, any Linux distri- bution should also work. For the tool itself, to generate SVG memory curve graphs the following Python packages are required: plotly; numpy; For the Graphical User Interface some form of browser is required and the following Python packages: das...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.