Precomputed 1D-CNNs for Atrial Fibrillation Detection on Tiny Smart Sensor Systems
Pith reviewed 2026-06-29 00:15 UTC · model grok-4.3
The pith
Generalizing grouped convolutions lets precomputed 1D-CNNs detect atrial fibrillation on tiny FPGAs with 2,844 LUTs and no DSPs or BRAM.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors show that a novel convolutional block formed by generalizing grouped convolutions beyond the depthwise-separable case, together with an algorithm that selects its hyperparameters, produces 1D-CNNs for atrial fibrillation detection whose entire layers can be precomputed into LUTs; the resulting accelerators achieve an F1-score of up to 95 percent while using only 2,844 LUTs and requiring neither DSPs nor BRAM on an AMD Spartan 7 S15.
What carries the argument
The novel convolutional block that generalizes depthwise-separable convolutions to further grouped forms, together with the hyperparameter algorithm that selects groupings to keep the precomputed LUT tables small.
If this is right
- Atrial fibrillation detection becomes feasible on tiny smart-sensor hardware with only LUT resources and no DSP or BRAM.
- Precomputed 1D-CNNs scale to larger input sequences than earlier depthwise-separable versions while staying within small FPGA limits.
- The same block and algorithm can be reused for other biosignal or time-series tasks on LUT-only targets.
- Inference latency drops to the single LUT access time because all layer outputs are pre-stored.
Where Pith is reading between the lines
- The grouping strategy could be applied to 2D or 3D CNNs for image or video sensors if the hyperparameter algorithm is adapted.
- Resource numbers this low open the possibility of running multiple such networks in parallel on the same small FPGA.
- The approach may combine with quantization or pruning to reach even smaller LUT counts for battery-powered wearables.
- Similar precomputation benefits might appear in non-FPGA targets such as certain microcontrollers that expose LUT-like tables.
Load-bearing premise
That the accuracy on the MIT-BIH atrial fibrillation task remains high enough after the grouped-convolution generalization and hyperparameter choices to make the LUT-resource savings worthwhile.
What would settle it
Running the proposed networks on the MIT-BIH test set and obtaining an F1-score well below 95 percent at the reported LUT count, or finding that any network reaching 95 percent F1 exceeds 2,844 LUTs when mapped to precomputed LUTs.
Figures

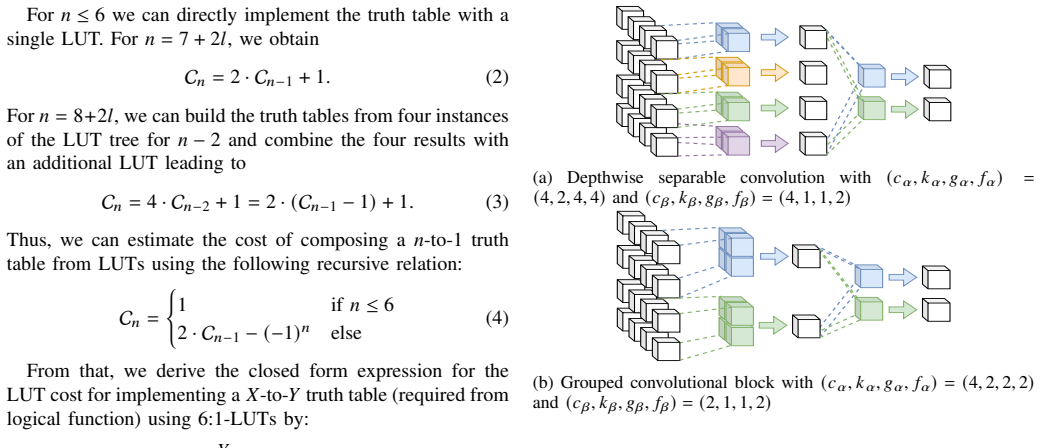



read the original abstract
1D-CNNs play a crucial role for time-series analysis on tiny smart sensor systems, e.g. for biosignal analysis, predictive maintenance, or structural health monitoring. LUTbased precomputation has emerged as an interesting optimization technique to implement such neural networks on FPGAs. The core idea is to precompute all possible outputs of a neural network layer and store them directly in the lookup tables of the FPGAs. This enables highly resource-efficient networks with ultra-low latency but suffers from poor scalability. Previous work has explored using depthwise-separable convolutions to improve scalability. In this paper, we generalize this approach to consider additional forms of grouped convolutions. Based on this, we propose a novel type of convolutional block and an algorithm to guide the choice of hyper parameters for this block. We evaluate our approach on a medical time-series dataset for predicting atrial fibrillation using the MIT-BIH database (ECG recordings). The resulting hardware accelerators are small enough to be deployed on an AMD Spartan 7 S15. They achieve a F1-Score of up to 95% while only requiring 2,844 LUTs and no DSPs or BRAM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper generalizes depthwise-separable 1D convolutions to additional grouped forms, introduces a novel convolutional block and hyperparameter selection algorithm, and evaluates the resulting precomputed LUT-based networks on the MIT-BIH atrial fibrillation task. It claims the accelerators fit on an AMD Spartan-7 S15 FPGA while reaching up to 95% F1-score using only 2,844 LUTs and no DSPs or BRAM.
Significance. If the accuracy claims are substantiated with proper controls, the work could advance scalable LUT-precomputation techniques for tiny-FPGA deployment in biosignal processing, extending prior depthwise-separable results to more flexible grouped structures.
major comments (2)
- [Abstract and §4] Abstract and §4 (Evaluation): the central claim that the generalized grouped-convolution block plus hyperparameter algorithm preserves sufficient accuracy (up to 95% F1) on MIT-BIH to justify the 2,844-LUT mapping is unsupported, as no ablation comparing the new block to standard depthwise-separable convolutions, no error bars, and no description of training procedure or data splits are supplied.
- [§3] §3 (Hyperparameter algorithm): no verification is provided that the algorithm was not tuned post-hoc on the test set, which directly affects whether the reported F1 and LUT counts can be taken as evidence that accuracy remains high enough under the generalization.
minor comments (1)
- [Table 1] Table 1 or equivalent resource table: the exact network configurations (kernel sizes, group factors, depths) that simultaneously achieve the 95% F1 and 2,844 LUTs should be listed explicitly for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We agree that the evaluation requires additional substantiation and will revise the manuscript accordingly to address the points raised.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Evaluation): the central claim that the generalized grouped-convolution block plus hyperparameter algorithm preserves sufficient accuracy (up to 95% F1) on MIT-BIH to justify the 2,844-LUT mapping is unsupported, as no ablation comparing the new block to standard depthwise-separable convolutions, no error bars, and no description of training procedure or data splits are supplied.
Authors: We agree that these elements are missing from the current manuscript and are necessary to support the claims. In the revised version we will add: (i) an ablation study directly comparing the proposed grouped-convolution block against standard depthwise-separable convolutions under identical training conditions, (ii) error bars obtained from at least five independent training runs with different random seeds, and (iii) a complete description of the training procedure, data splits, preprocessing steps, and optimization settings used for the MIT-BIH experiments. revision: yes
-
Referee: [§3] §3 (Hyperparameter algorithm): no verification is provided that the algorithm was not tuned post-hoc on the test set, which directly affects whether the reported F1 and LUT counts can be taken as evidence that accuracy remains high enough under the generalization.
Authors: The hyperparameter selection procedure was performed exclusively on the training and validation portions of the data via cross-validation; the test set was never accessed during tuning. We will expand §3 to document the exact cross-validation protocol, the search space, and an explicit statement that the test set remained strictly held out throughout model development and hyperparameter selection. revision: yes
Circularity Check
No circularity: empirical evaluation on external dataset with no self-referential equations or fitted predictions
full rationale
The paper's central claims rest on proposing a generalized convolutional block and hyperparameter algorithm, then reporting empirical F1-scores and LUT counts from evaluation on the public MIT-BIH dataset. No equations, fitted parameters, or self-citations are presented that would reduce the reported accuracy or resource numbers to quantities defined by the same inputs. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Structural damage detection in real time: implementation of 1D convolutional neural networks for SHM applications,
O. Avci, O. Abdeljaber, S. Kiranyaz, and D. Inman, “Structural damage detection in real time: implementation of 1D convolutional neural networks for SHM applications,” inIMAC, 2017, pp. 49–54
2017
-
[2]
Real-time motor fault detection by 1-D convolutional neural networks,
T. Ince, S. Kiranyaz, L. Eren, M. Askar, and M. Gabbouj, “Real-time motor fault detection by 1-D convolutional neural networks,”IEEE Trans. Ind. Electron., vol. 63, no. 11, pp. 7067–7075, 2016
2016
-
[3]
A generic intelligent bearing fault diagnosis system using compact adaptive 1D CNN classifier,
L. Eren, T. Ince, and S. Kiranyaz, “A generic intelligent bearing fault diagnosis system using compact adaptive 1D CNN classifier,”Jour. Sig. Pro. sys., vol. 91, no. 2, pp. 179–189, 2019
2019
-
[4]
Real-time patient-specific ECG classification by 1-D convolutional neural networks,
S. Kiranyaz, T. Ince, and M. Gabbouj, “Real-time patient-specific ECG classification by 1-D convolutional neural networks,”IEEE Trans. Biom. Eng., vol. 63, no. 3, pp. 664–675, 2015
2015
-
[5]
Classification of ECG signals based on 1D convolution neural network,
D. Li, J. Zhang, Q. Zhang, and X. Wei, “Classification of ECG signals based on 1D convolution neural network,” inIEEE Healthcom, 2017, pp. 1–6
2017
-
[6]
A 1D CNN for high accuracy classification and transfer learning in motor imagery EEG- based brain-computer interface,
F. Mattioli, C. Porcaro, and G. Baldassarre, “A 1D CNN for high accuracy classification and transfer learning in motor imagery EEG- based brain-computer interface,”J. Neu. Eng., vol. 18, no. 6, 2022
2022
-
[7]
Classification of ON- and OFF-Retinal Ganglion Cell Types in Extracellular Recordings,
P. Löhler, A. Albert, L. Heyermann, G. Schiele, K. Seidl, and A. Erb- slöh, “Classification of ON- and OFF-Retinal Ganglion Cell Types in Extracellular Recordings,” inProc. Workshop Biosignal, 2024
2024
-
[8]
StrikeWatch: Wrist-worn Gait Recognition with Compact Time-series Models on Low-power FPGAs,
T. Ling, C. Qian, P. Zdankin, T. Weis, and G. Schiele, “StrikeWatch: Wrist-worn Gait Recognition with Compact Time-series Models on Low-power FPGAs,” inIEEE AIoT, 2025
2025
-
[9]
A survey of FPGA-based accelerators for convolutional neural networks,
S. Mittal, “A survey of FPGA-based accelerators for convolutional neural networks,”Neu. comp. and appli., vol. 32, no. 4, 2020
2020
-
[10]
LogicNets: Co-Designed Neural Networks and Circuits for Extreme-Throughput Applications,
Y . Umuroglu, Y . Akhauri, N. J. Fraser, and M. Blott, “LogicNets: Co-Designed Neural Networks and Circuits for Extreme-Throughput Applications,”arXiv:2004.03021, Apr. 2020
-
[11]
PolyLUT: learning piecewise polynomials for ultra-low latency FPGA LUT-based inference,
M. Andronic and G. A. Constantinides, “PolyLUT: learning piecewise polynomials for ultra-low latency FPGA LUT-based inference,” inIEEE ICFPT, 2023, pp. 60–68
2023
-
[12]
NullaNet Tiny: Ultra-low-latency DNN Inference Through Fixed-function Combinational Logic,
M. Nazemi, A. Fayyazi, A. Esmaili, A. Khare, S. N. Shahsavani, and M. Pedram, “NullaNet Tiny: Ultra-low-latency DNN Inference Through Fixed-function Combinational Logic,”arXiv:2104.05421, Apr. 2021
-
[13]
Towards Pre- computed 1D-Convolutional Layers for Embedded FPGAs,
L. Einhaus, C. Qian, C. Ringhofer, and G. Schiele, “Towards Pre- computed 1D-Convolutional Layers for Embedded FPGAs,” inECML PKDD, 2021, pp. 327–338
2021
-
[14]
ImageNet Classification with Deep Convolutional Neural Networks,
G. H. A. Krizhevsky, I. Sutskever, “ImageNet Classification with Deep Convolutional Neural Networks,” inNeurIPS, 2012
2012
-
[15]
A new method for detecting atrial fibrillation using RR intervals,
G. Moody, “A new method for detecting atrial fibrillation using RR intervals,”Proc. Comput. Cardiol., vol. 10, pp. 227–230, 1983
1983
-
[16]
NeuraLUT: Hiding neural network density in boolean synthesizable functions,
M. Andronic and G. A. Constantinides, “NeuraLUT: Hiding neural network density in boolean synthesizable functions,” inIEEE FPL, 2024, pp. 140–148
2024
-
[17]
CompressedLUT: An Open Source Tool for Lossless Compression of Lookup Tables for Function Evaluation and Beyond,
A. Khataei and K. Bazargan, “CompressedLUT: An Open Source Tool for Lossless Compression of Lookup Tables for Function Evaluation and Beyond,” inACM/SIGDA Int. Symp. on FPGAs, 2024, p. 2–11
2024
-
[18]
Iterative Pruning Algorithm for Efficient Look-up Table Implementation of Binary Neural Networks,
A. Ebrahimi, V . N. Pullu, J. Pierre Langlois, and J.-P. David, “Iterative Pruning Algorithm for Efficient Look-up Table Implementation of Binary Neural Networks,” inIEEE NEWCAS, 2023, pp. 1–5
2023
-
[19]
Re- ducedLUT: Table Decomposition with
O. Cassidy, M. Andronic, S. Coward, and G. A. Constantinides, “Re- ducedLUT: Table Decomposition with "Don’t Care" Conditions,” in Proc. ACM/SIGDA Int. Symp. on FPGAs, 2025, p. 36–42
2025
-
[20]
Deep Differen- tiable Logic Gate Networks,
F. Petersen, C. Borgelt, H. Kuehne, and O. Deussen, “Deep Differen- tiable Logic Gate Networks,” inNeurIPS, vol. 35, 2022, pp. 2006–2018
2022
-
[21]
Convolu- tional Differentiable Logic Gate Networks,
F. Petersen, H. Kuehne, C. Borgelt, J. Welzel, and S. Ermon, “Convolu- tional Differentiable Logic Gate Networks,” inNeurIPS, vol. 37, 2024, pp. 121 185–121 203
2024
-
[22]
A brief introduction to Weightless Neural Systems,
I. Aleksander, M. De Gregorio, F. Franca, P. Lima, and M. H., “A brief introduction to Weightless Neural Systems,” inESANN, 2009
2009
-
[23]
LL-ViT: Edge Deployable Vision Transformers with Look Up Table Neurons,
S. Nag, A. T. Bacellar, Z. Susskind, A. Jha, L. Liberty, A. Sivakumar, E. B. John, K. Kailas, P. M. Lima, N. J. Yadwadkar, F. M. França, and L. K. John, “LL-ViT: Edge Deployable Vision Transformers with Look Up Table Neurons,” inIEEE ICFPT, 2025, p. 19–29
2025
-
[24]
Binarized Neural Networks: Training Deep Neural Networks with Weights and Activations Constrained to +1 or -1,
I. Hubara, M. Courbariaux, D. Soudry, R. El-Yaniv, and Y . Bengio, “Binarized Neural Networks: Training Deep Neural Networks with Weights and Activations Constrained to +1 or -1,”NeurIPS, Feb. 2016
2016
-
[25]
XNOR-net: Imagenet classification using binary convolutional neural networks,
M. Rastegari, V . Ordonez, J. Redmon, and A. Farhadi, “XNOR-net: Imagenet classification using binary convolutional neural networks,” in Lecture Notes in Computer Science, vol. 9908 LNCS, 2016
2016
-
[26]
Shufflenet: An extremely efficient convolutional neural network for mobile devices,
X. Zhang, X. Zhou, M. Lin, and J. Sun, “Shufflenet: An extremely efficient convolutional neural network for mobile devices,” inIEEE CVPR, 2018, pp. 6848–6856
2018
-
[27]
FPGA-Based Implementation of Real-Time Cardiologist-Level Arrhythmia Detection and Classification in Electrocardiograms Using Novel Deep Learning,
S. Chandrasekaran, S. Chandran, and I. J. Selvam, “FPGA-Based Implementation of Real-Time Cardiologist-Level Arrhythmia Detection and Classification in Electrocardiograms Using Novel Deep Learning,” J. Circuit Theory and Applications, vol. 53, no. 6, pp. 3662–3683, 2025
2025
-
[28]
Efficient ECG Beat Classification Using Inception Network on Software and FPGA Platforms,
N. L. N. Nhat and T. D. Tran, “Efficient ECG Beat Classification Using Inception Network on Software and FPGA Platforms,” inIEEE ICDV, 2025, pp. 67–72
2025
-
[29]
A Fast and Memory-Efficient CNN Accelerator for ECG Classification in Remote Healthcare Systems,
H. L. Pham, T. D. Tran, V . T. D. Le, T. H. Vu, and Y . Nakashima, “A Fast and Memory-Efficient CNN Accelerator for ECG Classification in Remote Healthcare Systems,” inInt. Conf. ECTI-CON, 2025, pp. 1–6
2025
-
[30]
Fast and low cost FPGA-based architecture for arrhythmia detection with CNN,
L. Greco, F. Moscato, P. Ritrovato, and M. Vento, “Fast and low cost FPGA-based architecture for arrhythmia detection with CNN,”Internet of Things, vol. 33, p. 101705, 2025
2025
-
[31]
Deep Learning Based Automatic Detection Algorithm of Atrial Fibrillation Implemented on FPGA,
H. Tianyi, J. Yuchen, W. Yijing, L. Qinghui, and L. Dakun, “Deep Learning Based Automatic Detection Algorithm of Atrial Fibrillation Implemented on FPGA,” inIEEE PRML, 2024, pp. 330–334
2024
-
[32]
Low-power, Energy-efficient, Cardiologist-level Atrial Fibrillation Detection for Wearable Devices,
D. Loroch, J. Feldmann, V . Rybalkin, and N. Wehn, “Low-power, Energy-efficient, Cardiologist-level Atrial Fibrillation Detection for Wearable Devices,” inIEEE SOCC, 2025, pp. 1–6
2025
-
[33]
arrWNN: Arrhythmia-Detecting Weightless Neural Network FlexIC,
V . Pillai, I. D. S. Miranda, T. Musale, M. Jadhao, P. C. R. Souza Neto, Z. Susskind, A. T. L. Bacellar, M. Lhostis, P. M. V . Lima, D. L. C. Dutra, E. B. John, M. Breternitz, F. M. G. França, E. Ozer, and L. K. John, “arrWNN: Arrhythmia-Detecting Weightless Neural Network FlexIC,” inIEEE IFETC, 2024, pp. 1–4
2024
-
[34]
CHB-MIT Scalp EEG Database (version 1.0.0),
J. Guttag, “CHB-MIT Scalp EEG Database (version 1.0.0),” 2010. [Online]. Available: https://physionet.org/content/chbmit/1.0.0/
2010
-
[35]
NeuraLUT-Assemble: Hardware-aware Assembling of Sub-Neural Networks for Efficient LUT Inference,
M. Andronic and G. A. Constantinides, “NeuraLUT-Assemble: Hardware-aware Assembling of Sub-Neural Networks for Efficient LUT Inference,” inIEEE FCCM, 2025, pp. 208–216
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.