MixFP4: Enhancing NVFP4 with Adaptive FP4/INT4 Block Representations
Pith reviewed 2026-06-28 20:15 UTC · model grok-4.3
The pith
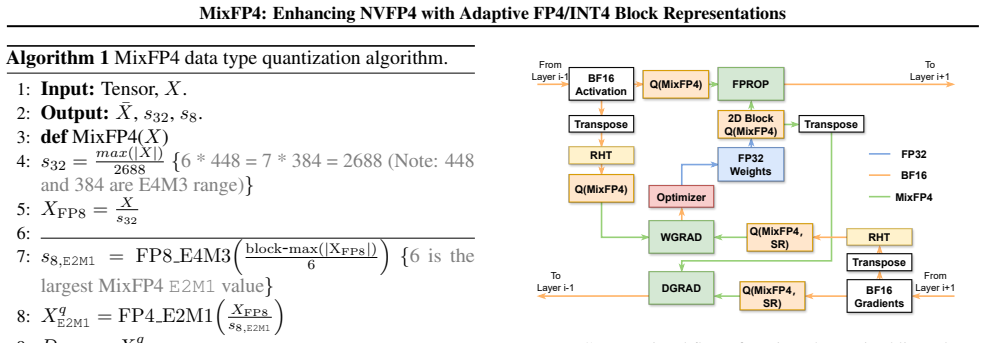
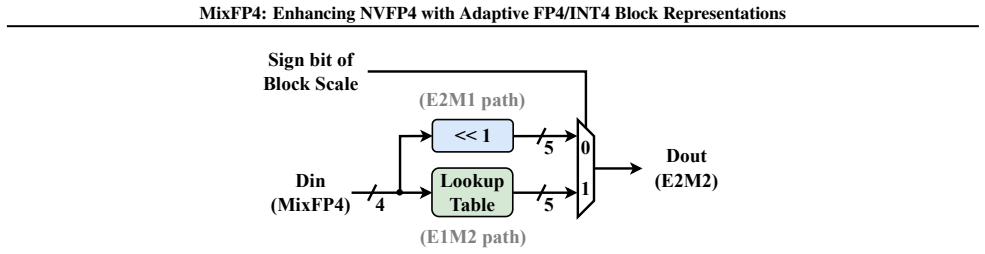
MixFP4 selects between E2M1 and E1M2 micro-formats per FP4 block by repurposing the FP8 scale sign bit and decodes both to a shared E2M2 internal format.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
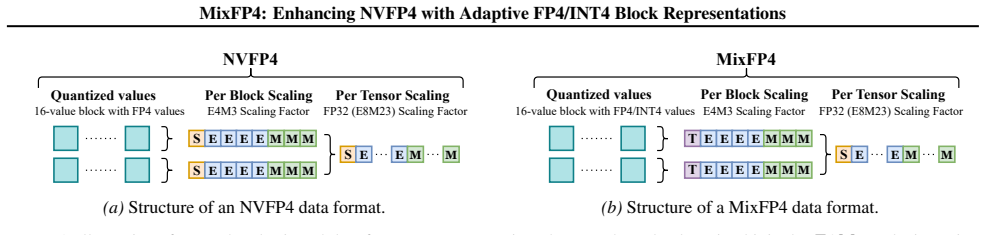
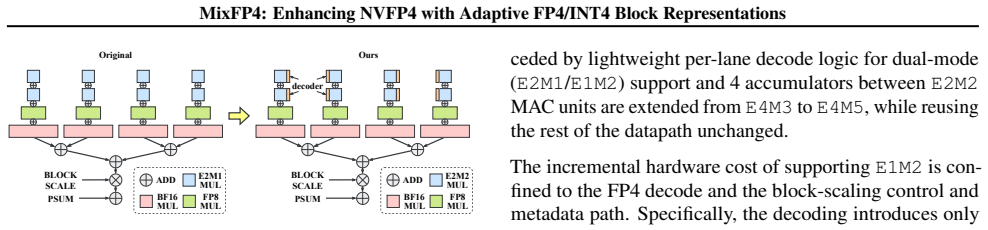
MixFP4 extends NVFP4 by selecting per block between the stored FP4 micro-formats E2M1 and E1M2, reuses the existing scale hierarchy, encodes the selection inside the sign bit of the FP8 E4M3 block scale with zero added metadata, and decodes the chosen values into a unified E2M2 internal representation so that the compute datapath stays single.
What carries the argument
Per-block choice between E2M1 and E1M2 micro-formats, signaled by the sign bit of the FP8 E4M3 scale and mapped to a common E2M2 internal representation.
If this is right
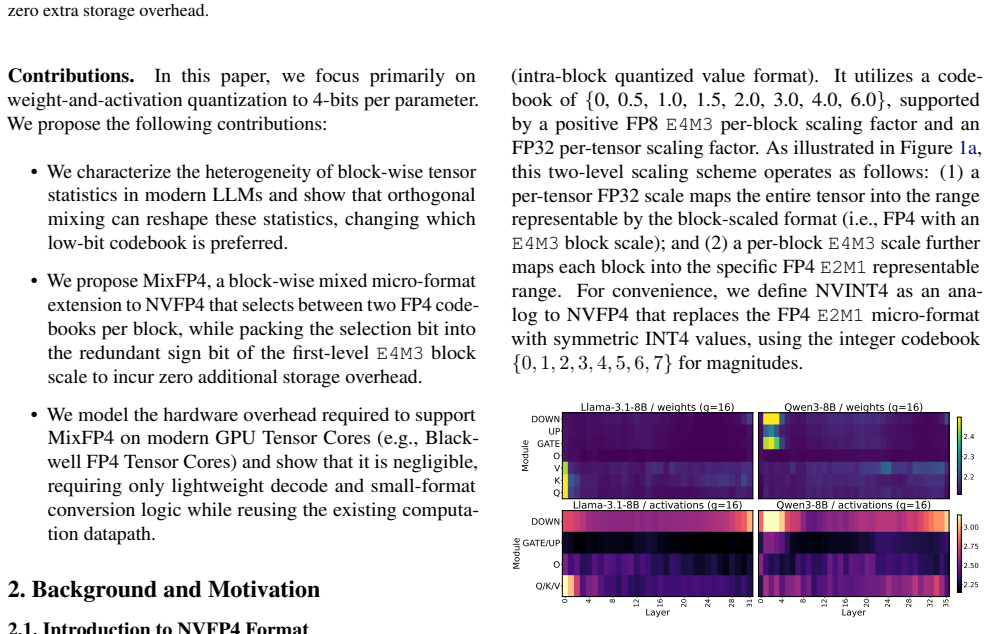
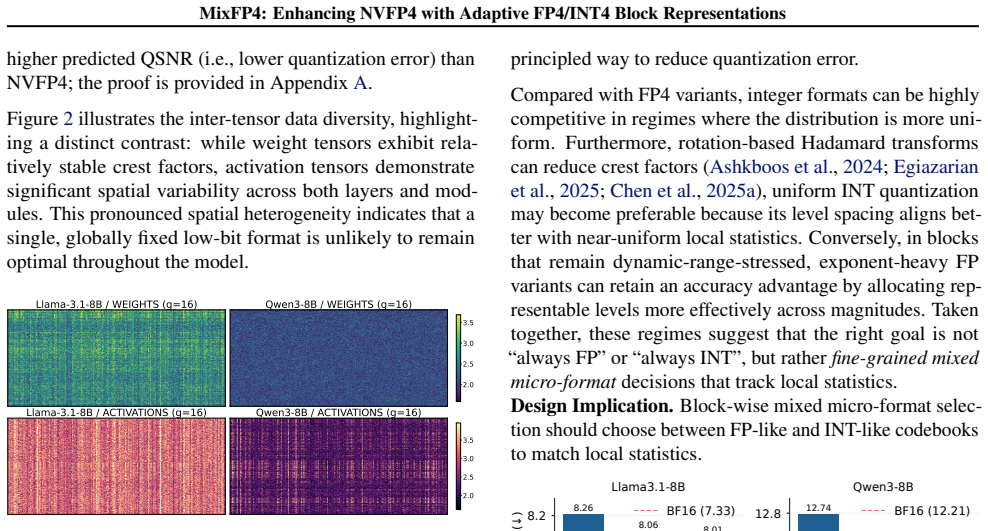
- FP4 quantization becomes more robust to heterogeneous block statistics while preserving the standard block-scaled MMA and GEMM execution path.
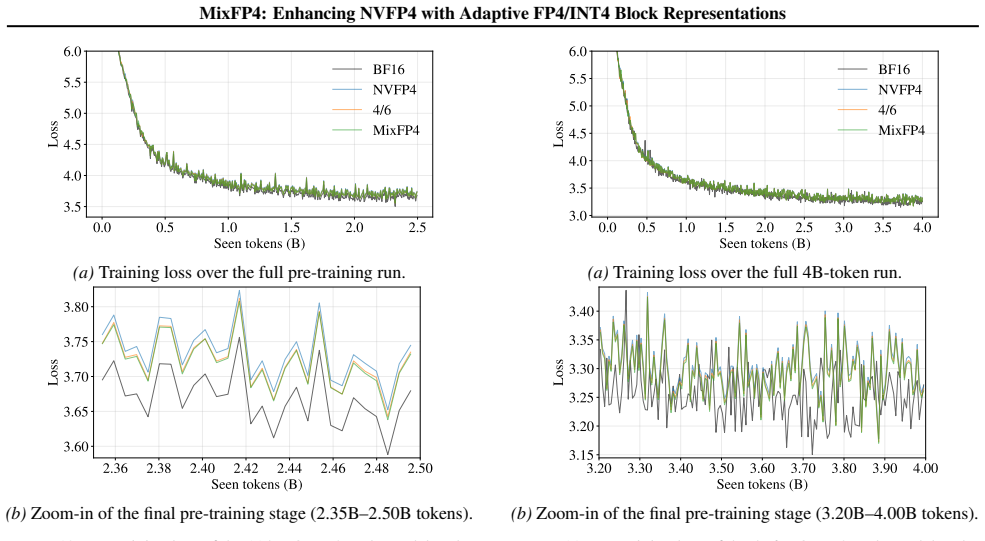
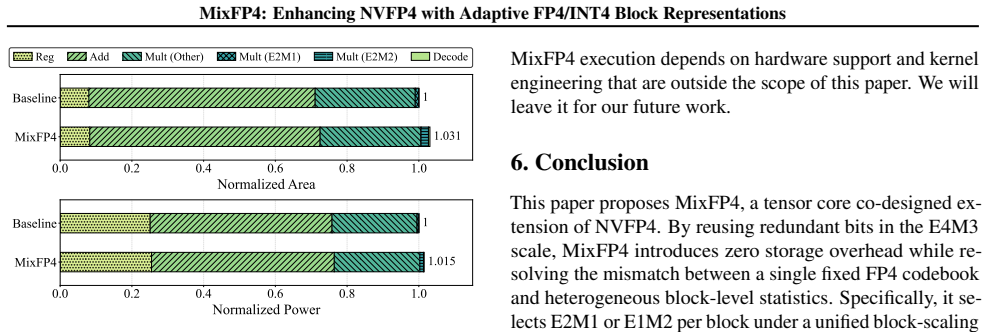
- Accuracy gains appear across representative LLM families with only 3.1 percent area and 1.5 percent power overhead in the tensor core.
- No additional selection metadata or datapath duplication is required.
- The same scale hierarchy already used by NVFP4 continues to apply without modification.
Where Pith is reading between the lines
- The same sign-bit encoding trick could be reused to switch among three or more micro-formats if future hardware supports an extra internal representation.
- Unified internal formats may become a general pattern for letting storage precision diversify while keeping compute units simple.
- The method suggests a route to apply similar per-block adaptation at even lower precisions such as 3-bit formats without increasing metadata traffic.
Load-bearing premise
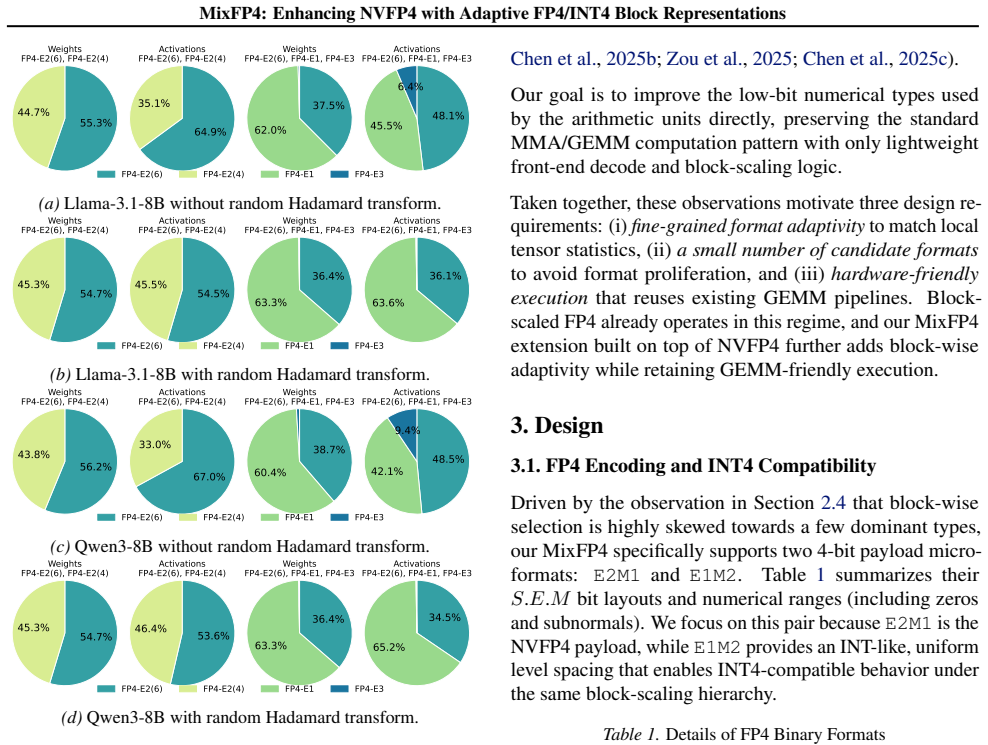
That two micro-formats plus one shared internal representation are enough to cover the range of block statistics that appear in practice.
What would settle it
Running the same LLM workloads on a new model whose block value distributions fall outside the representable ranges of both E2M1 and E1M2 and checking whether accuracy still improves over NVFP4.
Figures




read the original abstract
As large language models continue to scale, fine-grained block-scaled low-precision formats such as NVFP4 are increasingly adopted for their substantial throughput and memory benefits. However, a single FP4 micro-format often mismatches heterogeneous block-level tensor statistics. To address this without changing the standard block-scaled MMA/GEMM execution path, we propose MixFP4, a mixed micro-format extension to NVFP4 that selects between two stored FP4 micro-formats (E2M1 and E1M2) per block. MixFP4 reuses NVFP4's scale hierarchy and encodes the format choice with zero additional metadata by repurposing the sign bit of the FP8 E4M3 block scale. By decoding both micro-formats into a unified internal E2M2 compute representation, MixFP4 avoids datapath duplication. Across representative LLM families, MixFP4 improves FP4 quantization robustness and accuracy over NVFP4 baselines with modest tensor-core overhead (3.1\% area, 1.5\% power).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MixFP4 as a mixed micro-format extension to NVFP4 for block-scaled low-precision quantization in LLMs. Per-block selection occurs between stored E2M1 and E1M2 FP4 formats, with the choice encoded in the reused sign bit of the FP8 E4M3 scale factor and both formats decoded into a single internal E2M2 representation to preserve the existing MMA/GEMM datapath. The authors claim this yields improved quantization robustness and accuracy over fixed NVFP4 baselines across representative LLM families, at a tensor-core overhead of 3.1% area and 1.5% power.
Significance. If the empirical claims are substantiated, the work provides a low-overhead engineering path to adapt FP4 quantization to heterogeneous block statistics without extra metadata or datapath duplication. The sign-bit reuse for format selection is a compact, parameter-free mechanism that could be adopted in existing hardware flows; however, its value depends on whether the reported accuracy gains are robustly isolated to the mixed-format choice and whether the unified E2M2 representation incurs no hidden fidelity loss.
major comments (3)
- [Abstract] Abstract: the stated accuracy and overhead improvements are presented without dataset details, error bars, ablation controls, or explicit comparison isolating the contribution of the E2M1/E1M2 selection from other unmentioned implementation changes; this leaves the central robustness claim unverifiable from the provided description.
- [Scale encoding description] Scale encoding description: repurposing the sign bit of the FP8 E4M3 block scale for format selection is asserted to incur zero metadata cost, yet no analysis is supplied of whether this narrows the usable positive scale exponent range or introduces asymmetric treatment of positive versus negative scales; this directly affects the claim that the mechanism preserves NVFP4's scale hierarchy without loss.
- [Internal representation section] Internal representation section: the assertion that a single E2M2 format can faithfully decode and represent the distinct exponent/mantissa trade-offs of both E2M1 and E1M2 for actual LLM tensor distributions lacks supporting range analysis, conversion-error bounds, or counterexample checks; this assumption is load-bearing for the robustness improvement claim.
minor comments (1)
- [Abstract] The overhead figures (3.1% area, 1.5% power) are stated without reference to the specific tensor-core baseline, synthesis conditions, or measurement methodology.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight opportunities to improve clarity and substantiation. We respond point-by-point to the major comments below and will incorporate the indicated revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the stated accuracy and overhead improvements are presented without dataset details, error bars, ablation controls, or explicit comparison isolating the contribution of the E2M1/E1M2 selection from other unmentioned implementation changes; this leaves the central robustness claim unverifiable from the provided description.
Authors: We agree the abstract is high-level. In revision we will expand it to name the LLM families evaluated (Llama-2, Mistral, Qwen), note that accuracy figures include standard deviation over three random seeds, and state that Section 4.3 ablations isolate the mixed-format choice from other implementation details. The main text already contains these elements; the abstract update will make the central claim verifiable at a glance. revision: yes
-
Referee: [Scale encoding description] Scale encoding description: repurposing the sign bit of the FP8 E4M3 block scale for format selection is asserted to incur zero metadata cost, yet no analysis is supplied of whether this narrows the usable positive scale exponent range or introduces asymmetric treatment of positive versus negative scales; this directly affects the claim that the mechanism preserves NVFP4's scale hierarchy without loss.
Authors: This observation is correct; the manuscript provides no explicit range analysis. We will add a short subsection and accompanying table that (1) confirms block scales remain strictly positive by NVFP4 convention, so the sign bit carries no scale sign information to lose, (2) shows the 4-bit exponent field and bias are unchanged, preserving the full positive exponent range, and (3) reports the empirical distribution of block scales from the evaluated tensors to demonstrate no truncation occurs. Revision will therefore include this analysis. revision: yes
-
Referee: [Internal representation section] Internal representation section: the assertion that a single E2M2 format can faithfully decode and represent the distinct exponent/mantissa trade-offs of both E2M1 and E1M2 for actual LLM tensor distributions lacks supporting range analysis, conversion-error bounds, or counterexample checks; this assumption is load-bearing for the robustness improvement claim.
Authors: We acknowledge the absence of quantitative support for the E2M2 unification claim. In the revised manuscript we will augment the internal-representation section with (a) dynamic-range comparison showing E2M2 covers the maximum representable values of both source formats for observed LLM weight/activation magnitudes, (b) worst-case relative conversion error bounds (< 2^-3), and (c) explicit checks on the 0.1 % most extreme blocks confirming no overflow or precision collapse. These additions will directly substantiate the fidelity claim. revision: yes
Circularity Check
No circularity: engineering design proposal with no derivation chain
full rationale
The paper describes MixFP4 as a hardware-software extension to NVFP4 that reuses the FP8 E4M3 scale sign bit to select between E2M1 and E1M2 micro-formats per block and decodes both into a shared E2M2 internal format. No equations, fitted parameters, predictions, or first-principles derivations appear in the abstract or visible text. The improvement claim rests on the proposed mechanism's construction and empirical evaluation rather than any self-referential reduction or self-citation load-bearing step. The work is therefore self-contained as an engineering proposal.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 2 Pith papers
-
Rethinking Shrinkage Bias in LLM FP4 Pretraining: Geometric Origin, Systemic Impact, and UFP4 Recipe
E2M1 FP4 has inherent shrinkage bias from asymmetric bin geometry that accumulates and destabilizes training; UFP4 with uniform E1M2/INT4 grids and selective RHT/stochastic rounding reduces BF16-relative degradation i...
-
GoldenFloat: A Phi-Derived Static-Split Floating-Point Family from GF4 to GF1024 with a Lucas-Exact Integer Identity
GoldenFloat introduces a phi-derived rule for setting exponent and fraction widths across floating-point formats from 4 to 1024 bits, backed by open RTL generator, Lucas-exact accumulator, and FPGA implementation.
Reference graph
Works this paper leans on
-
[1]
Pretraining large language models with NVFP4.arXiv preprint arXiv:2509.25149, 2025
Abecassis, F., Agrusa, A., Ahn, D., Alben, J., Alborghetti, S., Andersch, M., Arayandi, S., Bjorlin, A., Blakeman, A., Briones, E., et al. Pretraining large language models with nvfp4.arXiv preprint arXiv:2509.25149,
-
[2]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
9 MixFP4: Enhancing NVFP4 with Adaptive FP4/INT4 Block Representations Chen, M., Wu, M., Jin, H., Yuan, Z., Liu, J., Zhang, C., Li, Y ., Huang, J., Ma, J., Xue, Z., et al. Int vs fp: A comprehensive study of fine-grained low-bit quantization formats.arXiv preprint arXiv:2510.25602, 2025a. Chen, Y ., AbouElhamayed, A. F., Dai, X., Wang, Y ., An- dronic, M....
-
[4]
Chen, Y ., Zou, J., and Chen, X
IEEE, 2025b. Chen, Y ., Zou, J., and Chen, X. April: Accuracy-improved floating-point approximation for neural network accelera- tors. In2025 62nd ACM/IEEE Design Automation Con- ference (DAC), pp. 1–7, 2025c. doi: 10.1109/DAC63849. 2025.11133083. Clark, P., Cowhey, I., Etzioni, O., Khot, T., Sabharwal, A., Schoenick, C., and Tafjord, O. Think you have so...
-
[5]
Four Over Six: More Accurate NVFP4 Quantization with Adaptive Block Scaling
Cook, J., Guo, J., Xiao, G., Lin, Y ., and Han, S. Four over six: More accurate nvfp4 quantization with adaptive block scaling.arXiv preprint arXiv:2512.02010,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Bridging the gap between promise and performance for microscaling fp4 quantization,
Egiazarian, V ., Castro, R. L., Kuznedelev, D., Panferov, A., Kurtic, E., Pandit, S., Marques, A., Kurtz, M., Ashkboos, S., Hoefler, T., et al. Bridging the gap between promise and performance for microscaling fp4 quantization.arXiv preprint arXiv:2509.23202,
-
[7]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
Frantar, E., Ashkboos, S., Hoefler, T., and Alistarh, D. Gptq: Accurate post-training quantization for generative pre- trained transformers.arXiv preprint arXiv:2210.17323,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
The language model evaluation harness, 07 2024.https://zenodo.org/records/12608602
URL https://zenodo.org/records/12608602. Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
-
[9]
Measuring Massive Multitask Language Understanding
Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., and Steinhardt, J. Measuring mas- sive multitask language understanding.arXiv preprint arXiv:2009.03300,
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[10]
R., Pawar, S
Henry, A., Dachapally, P. R., Pawar, S. S., and Chen, Y . Query-key normalization for transformers. InFindings of the Association for Computational Linguistics: EMNLP 2020, pp. 4246–4253,
2020
-
[11]
arXiv preprint arXiv:2501.13987
Hu, W., Zhang, H., Guo, C., Feng, Y ., Guan, R., Hua, Z., Liu, Z., Guan, Y ., Guo, M., and Leng, J. M-ant: Efficient low-bit group quantization for llms via mathematically adaptive numerical type. In2025 IEEE International Symposium on High Performance Computer Architecture (HPCA), pp. 1112–1126. IEEE, 2025a. Hu, X., Cheng, Y ., Yang, D., Xu, Z., Yuan, Z....
-
[12]
doi: 10.1109/IEEESTD.2019.8766229. Kamath, A. K., Prabhu, R., Mohan, J., Peter, S., Ramjee, R., and Panwar, A. Pod-attention: Unlocking full prefill- decode overlap for faster llm inference. InProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Sys- tems, Volume 2, pp. 897–912,
-
[13]
URL https://doi.org/ 10.1145/3779212.3790135
1145/3779212.3790135. URL https://doi.org/ 10.1145/3779212.3790135. Liu, A., Feng, B., Xue, B., Wang, B., Wu, B., Lu, C., Zhao, C., Deng, C., Zhang, C., Ruan, C., et al. Deepseek- v3 technical report.arXiv preprint arXiv:2412.19437, 2024a. Liu, Z., Zhao, C., Fedorov, I., Soran, B., Choudhary, D., Kr- ishnamoorthi, R., Chandra, V ., Tian, Y ., and Blankevo...
-
[14]
Pointer Sentinel Mixture Models
Merity, S., Xiong, C., Bradbury, J., and Socher, R. Pointer sentinel mixture models.arXiv preprint arXiv:1609.07843,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
GLU Variants Improve Transformer
Shazeer, N. Glu variants improve transformer.arXiv preprint arXiv:2002.05202,
work page internal anchor Pith review Pith/arXiv arXiv 2002
-
[16]
Sun, Y ., Liu, R., Bai, H., Bao, H., Zhao, K., Li, Y ., Hu, J., Yu, X., Hou, L., Yuan, C., et al. Flatquant: Flatness matters for llm quantization.arXiv preprint arXiv:2410.09426,
-
[17]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
HellaSwag: Can a Machine Really Finish Your Sentence?
Zellers, R., Holtzman, A., Bisk, Y ., Farhadi, A., and Choi, Y . Hellaswag: Can a machine really finish your sentence? arXiv preprint arXiv:1905.07830,
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[19]
Associa- tion for Computing Machinery. ISBN 9798400715730. doi: 10.1145/3725843.3756094. URL https://doi. org/10.1145/3725843.3756094. 11 MixFP4: Enhancing NVFP4 with Adaptive FP4/INT4 Block Representations A. NVINT4 vs. NVFP4 QSNR Crossover with Exact INT4 Range This appendix derives the crest-factor crossover κ at which NVINT4 and NVFP4 have equal quant...
-
[20]
2 – – AND, FA, HA Adder (mantissa/int) – –2k(x+y+ 1)knFA, HA Exponent adder –kx– – FA, HA Exponent subtractor – – –kxXOR, FA, HA Comparator – – –kxXOR, AND, OR Aligner (barrel) – – –knlog 2 nMUX Normalizer (shared) – – –nlog 2 nMUX, OR B.4.1. COSTMODEL We use standard architecture-level approximations: GNOT = 1N AN D,(41) GAND2 = 2N AN D,(42) GOR2 = 2N AN...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.