Model-free LQG Control with Chance Constraints
Pith reviewed 2026-06-28 21:17 UTC · model grok-4.3
The pith
A two-timescale NPG actor-critic algorithm solves chance-constrained LQG control model-free while proving linear convergence via Lagrangian properties.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
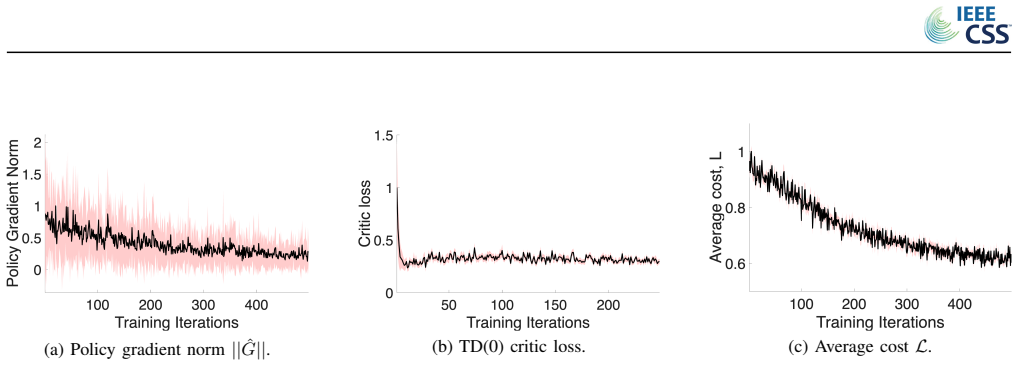
For linear time-invariant systems the risk is defined as the probability that a function of the one-step-ahead state exceeds a user-specified threshold; the NPG-based actor-critic algorithm with two timescales and Lagrangian primal-dual updates establishes coercivity and gradient dominance of the Lagrangian, yielding linear convergence and closed-loop stability for the actor, convergence of the TD(0) critic by stochastic approximation theory, and zero duality gap in the constrained problem.
What carries the argument
Lagrangian primal-dual framework applied to the two-timescale NPG actor-critic updates, which preserves the coercivity and gradient dominance properties needed for convergence analysis.
If this is right
- The actor updates converge linearly to the optimal policy under the chance constraint.
- Closed-loop stability is maintained throughout the training process.
- The constrained optimization problem has no duality gap, so primal and dual solutions coincide.
- The TD(0) critic converges in the mean-square sense by stochastic approximation.
- Numerical tests show risk is limited while performance stays close to model-based LQR.
Where Pith is reading between the lines
- The same Lagrangian construction could be tested on systems with partial model information to see whether convergence rates degrade gracefully.
- Because the method avoids real-time optimization, it may suit embedded platforms where scenario-based MPC is too slow.
- Extending the risk definition to multi-step or output-based constraints would require checking whether gradient dominance still holds.
Load-bearing premise
The chosen risk definition as a probability on the one-step-ahead state allows the Lagrangian to keep the coercivity and gradient dominance properties required for the linear convergence proofs.
What would settle it
An explicit instance of a chance-constrained LQG problem in which the Lagrangian exhibits a duality gap or the actor parameters fail to converge linearly under the stated risk definition would disprove the main claims.
Figures

read the original abstract
This paper studies model-free optimal control design and its convergence properties for linear time-invariant systems subject to probabilistic risk or chance constraints. In particular, we study a natural policy gradient (NPG)-based actor-critic (AC) algorithm with two timescales, using a Lagrangian primal-dual framework to enforce the constraint. Furthermore, the risk is defined as the probability that a function of the one-step-ahead state exceeds a user-specified threshold. To our knowledge, this is the first work to study the analytical convergence properties for NPG-based AC in a chance-constrained linear-quadratic Gaussian (LQG) regulator setting without model knowledge. We establish the coercivity and gradient dominance properties of the Lagrangian function, which ensure linear convergence and closed-loop stability during training for the actor. On the other hand, we analyse the convergence properties of the temporal difference (TD(0)) learning for the critic, applying stochastic approximation theory. Also, we demonstrate no duality gap in the constrained optimisation problem. Additionally, we have performed numerical analysis of the convergence properties and accuracy of the proposed method, comparing it with model-based chance-constrained LQR and scenario-based MPC. Results show that our approach effectively limits risk while maintaining near-optimal performance, without requiring full model knowledge or real-time optimisation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a model-free natural policy gradient (NPG) actor-critic algorithm for chance-constrained LQG regulation. It employs a Lagrangian primal-dual framework to enforce a one-step probabilistic risk constraint P(g(x_{t+1}) > threshold) ≤ allowed level, claims to prove that the resulting Lagrangian retains coercivity and gradient dominance (yielding linear convergence and closed-loop stability of the actor), analyzes TD(0) critic convergence via stochastic approximation, establishes zero duality gap, and reports numerical comparisons against model-based chance-constrained LQR and scenario MPC.
Significance. If the preservation of coercivity/gradient dominance under the probabilistic risk term holds and the derivations are complete, the work would provide the first analytical convergence guarantees for model-free NPG-AC in this constrained LQG setting, strengthening the case for safe RL methods on linear systems without requiring real-time optimization or full model knowledge.
major comments (2)
- [Lagrangian analysis / convergence theorems] The linear-convergence and stability claims rest on the Lagrangian (quadratic cost + λ·(risk − allowed)) inheriting coercivity and gradient dominance from the unconstrained LQG case. The risk term is defined as the probability that a function of the one-step-ahead state exceeds a threshold, which is generally non-convex and non-smooth in the gain matrix. The manuscript must supply the explicit argument (lemma or theorem) showing that this term does not destroy the dominance constant or coercivity; without it the NPG linear-convergence and zero-duality-gap results are not yet established.
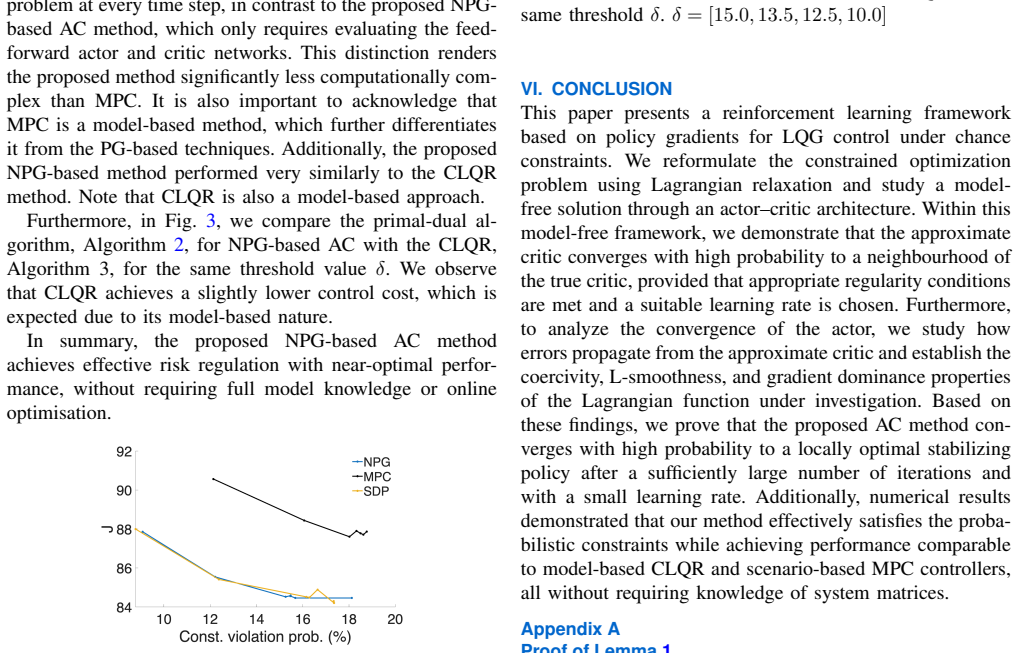
- [Numerical experiments] Numerical section: the comparisons with model-based chance-constrained LQR and scenario MPC lack reported details on the exact risk metric used for evaluation, number of Monte-Carlo trials, data-exclusion criteria, and error bars. These omissions prevent verification that the model-free method truly achieves comparable risk control and near-optimal cost.
minor comments (2)
- [Problem formulation] Clarify the precise functional form of g(·) and the threshold in the risk definition; the current description is too terse for reproducibility.
- [Algorithm description] The two-time-scale AC update rules should be written with explicit step-size schedules and the precise critic parameterization (linear or otherwise).
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. The comments highlight important points for strengthening the presentation of our theoretical results and experimental details. We address each major comment below and indicate the revisions planned for the next version.
read point-by-point responses
-
Referee: [Lagrangian analysis / convergence theorems] The linear-convergence and stability claims rest on the Lagrangian (quadratic cost + λ·(risk − allowed)) inheriting coercivity and gradient dominance from the unconstrained LQG case. The risk term is defined as the probability that a function of the one-step-ahead state exceeds a threshold, which is generally non-convex and non-smooth in the gain matrix. The manuscript must supply the explicit argument (lemma or theorem) showing that this term does not destroy the dominance constant or coercivity; without it the NPG linear-convergence and zero-duality-gap results are not yet established.
Authors: We agree that an explicit lemma is needed to rigorously demonstrate preservation of coercivity and gradient dominance when the probabilistic risk term is added to the Lagrangian. Although the manuscript states that these properties hold, the current presentation does not isolate the argument in a dedicated lemma. In the revised version we will insert a new lemma (placed after the definition of the Lagrangian) that shows, under the Gaussian noise assumption, the risk term is Lipschitz continuous in the gain and its contribution is dominated by the quadratic cost term, thereby leaving the dominance constant and coercivity unchanged. This will directly underpin the linear convergence and zero-duality-gap claims. revision: yes
-
Referee: [Numerical experiments] Numerical section: the comparisons with model-based chance-constrained LQR and scenario MPC lack reported details on the exact risk metric used for evaluation, number of Monte-Carlo trials, data-exclusion criteria, and error bars. These omissions prevent verification that the model-free method truly achieves comparable risk control and near-optimal cost.
Authors: We accept this criticism. The revised manuscript will expand Section 5 to report: (i) the risk metric is the empirical probability computed from Monte-Carlo rollouts, (ii) 5000 independent trajectories per evaluation point, (iii) no data-exclusion criteria were applied, and (iv) error bars show one standard deviation over 20 independent algorithm runs. These additions will enable direct verification of the reported risk control and cost performance. revision: yes
Circularity Check
No significant circularity; claims rest on explicit derivation of Lagrangian properties
full rationale
The paper asserts it establishes coercivity and gradient dominance of the Lagrangian (cost + λ·risk) directly from the problem setup and risk definition P(g(x_{t+1}) > threshold), then uses these to prove linear convergence of NPG actor and zero duality gap. No equations or steps are shown reducing the claimed properties to a fitted parameter, self-citation chain, or renamed input; the TD(0) critic analysis invokes standard stochastic approximation. The derivation chain is presented as self-contained against the LQG structure and Lagrangian framework, with numerical comparisons to model-based baselines serving as external checks rather than internal fits.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The underlying plant is linear time-invariant.
- domain assumption The Lagrangian primal-dual formulation of the chance constraint admits zero duality gap and yields a coercive, gradient-dominant objective.
Reference graph
Works this paper leans on
-
[1]
Risk-Constrained Linear-Quadratic Regulators,
A. Tsiamis, D. S. Kalogerias, L. F. O. Chamon, A. Ribeiro, and G. J. Pappas, “Risk-Constrained Linear-Quadratic Regulators,” in2020 59th IEEE Conference on Decision and Control (CDC), Dec. 2020, pp. 3040–3047. VOLUME 15 A. NAHAET AL.: PREPARATION OF PAPERS FOR IEEE OPEN JOURNAL OF CONTROL SYSTEMS
2020
-
[2]
The scenario approach for Stochastic Model Predictive Control with bounds on closed-loop constraint violations,
G. Schildbach, L. Fagiano, C. Frei, and M. Morari, “The scenario approach for Stochastic Model Predictive Control with bounds on closed-loop constraint violations,”Automatica, vol. 50, no. 12, pp. 3009–3018, Dec. 2014
2014
-
[3]
Stochastic MPC for Additive and Mul- tiplicative Uncertainty Using Sample Approximations,
J. Fleming and M. Cannon, “Stochastic MPC for Additive and Mul- tiplicative Uncertainty Using Sample Approximations,”IEEE Trans. Automat. Contr., vol. 64, no. 9, pp. 3883–3888, Sep. 2019
2019
-
[4]
Linear controller design for chance constrained systems,
G. Schildbach, P. Goulart, and M. Morari, “Linear controller design for chance constrained systems,”Automatica, vol. 51, pp. 278–284, Jan. 2015
2015
-
[5]
Stochastic MPC with robustness to bounded parametric uncertainty,
E. Arcari, A. Iannelli, A. Carron, and M. N. Zeilinger, “Stochastic MPC with robustness to bounded parametric uncertainty,”IEEE Trans- actions on Automatic Control, pp. 1–14, 2023
2023
-
[6]
Data- Driven Tube-Based Stochastic Predictive Control,
S. Kerz, J. Teutsch, T. Br ¨udigam, M. Leibold, and D. Wollherr, “Data- Driven Tube-Based Stochastic Predictive Control,”IEEE Open Journal of Control Systems, vol. 2, pp. 185–199, 2023
2023
-
[7]
Global Convergence of Policy Gradi- ent Methods for Output Feedback Linear Quadratic Control,
F. Zhao, X. Fu, and K. You, “Global Convergence of Policy Gradi- ent Methods for Output Feedback Linear Quadratic Control,”arXiv preprint arXiv:2211.04051, 2022
-
[8]
Infinite-horizon Risk-constrained Linear Quadratic Regulator with Average Cost,
F. Zhao, K. You, and T. Basar, “Infinite-horizon Risk-constrained Linear Quadratic Regulator with Average Cost,” in2021 60th IEEE Conference on Decision and Control (CDC). Austin, TX, USA: IEEE, Dec. 2021, pp. 390–395
2021
-
[9]
Bertsekas,Reinforcement Learning and Optimal Control
D. Bertsekas,Reinforcement Learning and Optimal Control. Athena Scientific, Jul. 2019
2019
-
[10]
Re- inforcement learning for control: Performance, stability, and deep approximators,
L. Bus ¸oniu, T. de Bruin, D. Toli ´c, J. Kober, and I. Palunko, “Re- inforcement learning for control: Performance, stability, and deep approximators,”Annual Reviews in Control, vol. 46, pp. 8–28, Jan. 2018
2018
-
[11]
Efficient Off-Policy Q-Learning for Data-Based Discrete-Time LQR Problems,
V . G. Lopez, M. Alsalti, and M. A. M ¨uller, “Efficient Off-Policy Q-Learning for Data-Based Discrete-Time LQR Problems,”IEEE Transactions on Automatic Control, pp. 1–12, 2023
2023
-
[12]
R. S. Sutton and A. G. Barto,Reinforcement Learning, Second Edition: An Introduction. MIT Press, Nov. 2018
2018
-
[13]
Global convergence of policy gradient methods for the linear quadratic regulator,
M. Fazel, R. Ge, S. Kakade, and M. Mesbahi, “Global convergence of policy gradient methods for the linear quadratic regulator,” in International Conference on Machine Learning. PMLR, 2018, pp. 1467–1476
2018
-
[14]
Toward a Theoretical Foundation of Policy Optimization for Learning Control Policies,
B. Hu, K. Zhang, N. Li, M. Mesbahi, M. Fazel, and T. Bas ¸ar, “Toward a Theoretical Foundation of Policy Optimization for Learning Control Policies,”Annual Review of Control, Robotics, and Autonomous Sys- tems, vol. 6, no. 1, pp. 123–158, 2023
2023
-
[15]
Provably Global Con- vergence of Actor-Critic: A Case for Linear Quadratic Regulator with Ergodic Cost,
Z. Yang, Y . Chen, M. Hong, and Z. Wang, “Provably Global Con- vergence of Actor-Critic: A Case for Linear Quadratic Regulator with Ergodic Cost,” inAdvances in Neural Information Processing Systems, vol. 32. Curran Associates, Inc., 2019
2019
-
[16]
X. Chen, J. Duan, and L. Zhao, “Global optimality of single-timescale actor-critic under continuous state-action space: A study on linear quadratic regulator,”arXiv preprint arXiv:2505.01041, 2025
-
[17]
Policy optimization forH 2 linear control withH ∞ robustness guarantee: Implicit regularization and global convergence,
K. Zhang, B. Hu, and T. Bas ¸ar, “Policy optimization forH 2 linear control withH ∞ robustness guarantee: Implicit regularization and global convergence,”SIAM J. Control Optim., vol. 59, no. 6, pp. 4081– 4109, Jan. 2021
2021
-
[18]
Global Convergence of Policy Gradient Primal–Dual Methods for Risk-Constrained LQRs,
F. Zhao, K. You, and T. Bas ¸ar, “Global Convergence of Policy Gradient Primal–Dual Methods for Risk-Constrained LQRs,”IEEE Trans. Automat. Contr., vol. 68, no. 5, pp. 2934–2949, May 2023
2023
-
[19]
Policy gradient methods for the cost-constrained lqr: Strong duality and global convergence,
F. Zhao and K. You, “Policy gradient methods for the cost-constrained lqr: Strong duality and global convergence,”IEEE Transactions on Automatic Control, 2025
2025
-
[20]
Reinforcement learning control of constrained dynamic systems with uniformly ultimate boundedness stability guarantee,
M. Han, Y . Tian, L. Zhang, J. Wang, and W. Pan, “Reinforcement learning control of constrained dynamic systems with uniformly ultimate boundedness stability guarantee,”Automatica, vol. 129, p. 109689, Jul. 2021
2021
-
[21]
Learning control barrier functions and their application in reinforcement learning: A survey,
M. Guerrier, H. Fouad, and G. Beltrame, “Learning control barrier functions and their application in reinforcement learning: A survey,” arXiv preprint arXiv:2404.16879, 2024
-
[22]
End-to-end safe reinforcement learning through barrier functions for safety-critical continuous control tasks,
R. Cheng, G. Orosz, R. M. Murray, and J. W. Burdick, “End-to-end safe reinforcement learning through barrier functions for safety-critical continuous control tasks,” inProceedings of the AAAI conference on artificial intelligence, vol. 33, no. 01, 2019, pp. 3387–3395
2019
-
[23]
CBF-RL: Safety Filtering Reinforcement Learning in Training with Control Barrier Functions
L. Yang, B. Werner, M. de Sa, and A. D. Ames, “Cbf-rl: Safety filtering reinforcement learning in training with control barrier functions,”arXiv preprint arXiv:2510.14959, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Reinforcement learning based optimal control with a probabilistic risk constraint,
A. Naha and S. Dey, “Reinforcement learning based optimal control with a probabilistic risk constraint,”arXiv preprint arXiv:2305.15755, 2023
-
[25]
Single timescale actor-critic method to solve the linear quadratic regulator with convergence guarantees,
M. Zhou and J. Lu, “Single timescale actor-critic method to solve the linear quadratic regulator with convergence guarantees,”Journal of Machine Learning Research, vol. 24, no. 222, pp. 1–34, 2023
2023
-
[26]
A finite-time analysis of two time-scale actor-critic methods,
Y . F. Wu, W. Zhang, P. Xu, and Q. Gu, “A finite-time analysis of two time-scale actor-critic methods,”Advances in Neural Information Processing Systems, vol. 33, pp. 17 617–17 628, 2020
2020
-
[27]
Convergence of actor-critic with multi-layer neural networks,
H. Tian, A. Olshevsky, and Y . Paschalidis, “Convergence of actor-critic with multi-layer neural networks,”Advances in neural information processing systems, vol. 36, pp. 9279–9321, 2023
2023
-
[28]
Analysis of the Optimization Landscape of Linear Quadratic Gaussian (LQG) Control,
Y . Tang, Y . Zheng, and N. Li, “Analysis of the Optimization Landscape of Linear Quadratic Gaussian (LQG) Control,” inProceedings of the 3rd Conference on Learning for Dynamics and Control. PMLR, May 2021, pp. 599–610
2021
-
[29]
V . S. Borkar and V . S. Borkar,Stochastic approximation: a dynamical systems viewpoint. Springer, 2008, vol. 100
2008
-
[30]
A simple finite-time analysis of td learning with linear function approximation,
A. Mitra, “A simple finite-time analysis of td learning with linear function approximation,”IEEE Transactions on Automatic Control, 2024
2024
-
[31]
Finite sample analyses for td (0) with function approximation,
G. Dalal, B. Sz ¨or´enyi, G. Thoppe, and S. Mannor, “Finite sample analyses for td (0) with function approximation,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 32, no. 1, 2018
2018
-
[32]
Neural temporal-difference learning converges to global optima,
Q. Cai, Z. Yang, J. D. Lee, and Z. Wang, “Neural temporal-difference learning converges to global optima,”Advances in Neural Information Processing Systems, vol. 32, 2019
2019
-
[33]
Towards Generalization and Simplicity in Continuous Control,
A. Rajeswaran, K. Lowrey, E. V . Todorov, and S. M. Kakade, “Towards Generalization and Simplicity in Continuous Control,” inAdvances in Neural Information Processing Systems, vol. 30. Curran Associates, Inc., 2017
2017
-
[34]
A natural policy gradient,
S. M. Kakade, “A natural policy gradient,”Advances in neural information processing systems, vol. 14, 2001
2001
-
[35]
Policy gradient-based reinforcement learning for lqg control with chance constraints,
A. Naha and S. Dey, “Policy gradient-based reinforcement learning for lqg control with chance constraints,” in2025 European Control Conference (ECC). IEEE, 2025, pp. 364–371
2025
-
[36]
D. P. Bertsekas,Dynamic Programming and Optimal Control 3rd Edition, Volume II. Athena Scientific, 2011
2011
-
[37]
High- Dimensional Continuous Control Using Generalized Advantage Esti- mation,
J. Schulman, P. Moritz, S. Levine, M. Jordan, and P. Abbeel, “High- Dimensional Continuous Control Using Generalized Advantage Esti- mation,” Oct. 2018
2018
-
[38]
Human-level control through deep reinforcement learning,
V . Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovski et al., “Human-level control through deep reinforcement learning,” nature, vol. 518, no. 7540, pp. 529–533, 2015
2015
-
[39]
Continuous control with deep reinforce- ment learning, ICLR (2016),
T. P. Lillicrap, J. J. Hunt, A. Pritzel, N. Heess, T. Erez, Y . Tassa, D. Silver, and D. Wierstra, “Continuous control with deep reinforce- ment learning, ICLR (2016),”arXiv preprint arXiv:1509.0297, 2016
-
[40]
Global convergence of policy gradient primal-dual methods for risk-constrained LQRs,
F. Zhao, K. You, and T. Bas ¸ar, “Global convergence of policy gradient primal-dual methods for risk-constrained LQRs,”IEEE Transactions on Automatic Control, 2023
2023
-
[41]
Nonlinear q-design for convex stochastic control,
J. Skaf and S. Boyd, “Nonlinear q-design for convex stochastic control,”IEEE Transactions on Automatic Control, vol. 54, no. 10, pp. 2426–2430, 2009
2009
-
[42]
On matrix trace inequalities and related topics for products of hermitian matrices,
I. Coope, “On matrix trace inequalities and related topics for products of hermitian matrices,”Journal of mathematical analysis and appli- cations, vol. 188, no. 3, pp. 999–1001, 1994
1994
-
[43]
An introduction to matrix concentration inequali- ties,
J. A. Troppet al., “An introduction to matrix concentration inequali- ties,”Foundations and Trends® in Machine Learning, vol. 8, no. 1-2, pp. 1–230, 2015
2015
-
[44]
On the perturbation of pseudo-inverses, projections and linear least squares problems,
G. W. Stewart, “On the perturbation of pseudo-inverses, projections and linear least squares problems,”SIAM review, vol. 19, no. 4, pp. 634–662, 1977. 16 VOLUME
1977
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.