Bounding Global and Local Compression Error of Signal Parameterizations
Pith reviewed 2026-06-29 00:18 UTC · model grok-4.3
The pith
When a signal parameterization meets certain natural properties, its reconstruction error at any compression level is bounded by a scaled difference between its predictions at two different compression levels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
When parameterization-based compression satisfies certain natural properties, the compression error at any compression level is bounded by a simple scaled difference between model predictions at different compression levels.
What carries the argument
The error bound formed by a scaled difference between a parameterization's predictions at two compression levels, which serves as a computable proxy for reconstruction error.
If this is right
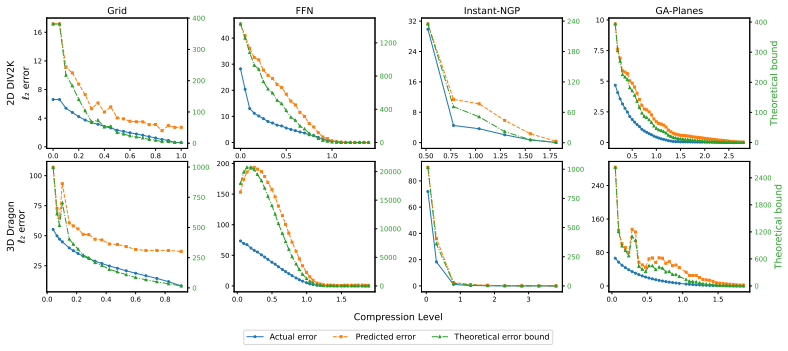
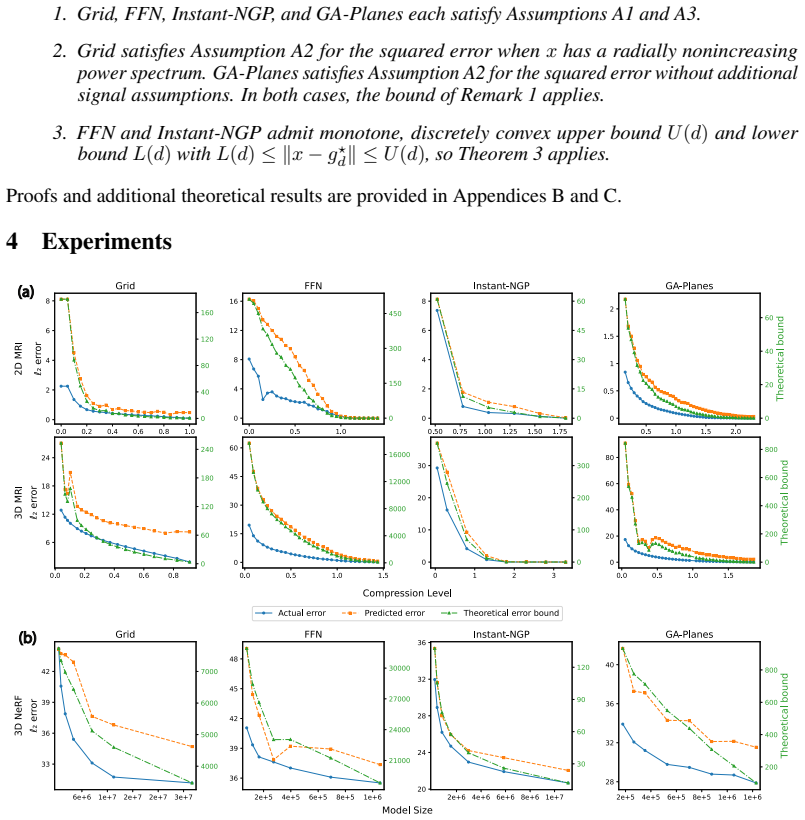
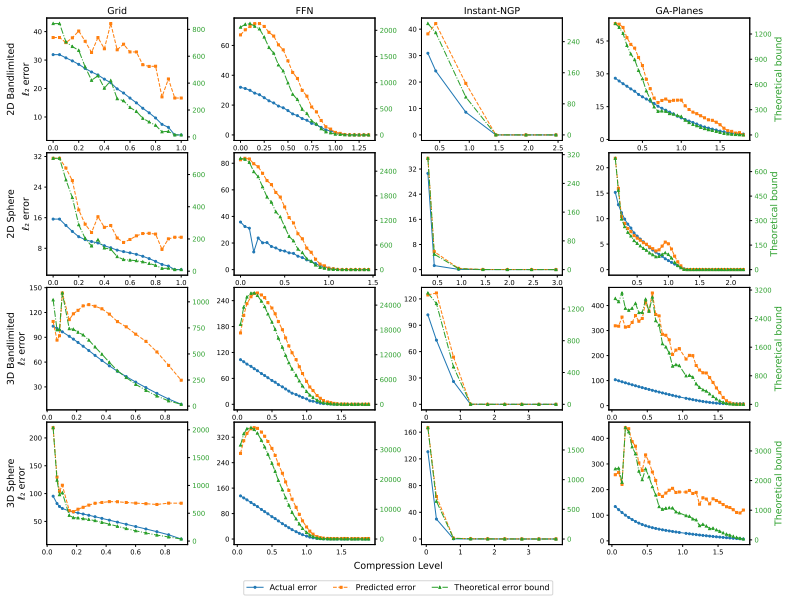
- The bound holds for interpolated grids, Fourier feature networks, multi-resolution hash encodings, and tensor factorizations.
- It produces tight, generalizable, signal-specific error predictors that are efficiently computable.
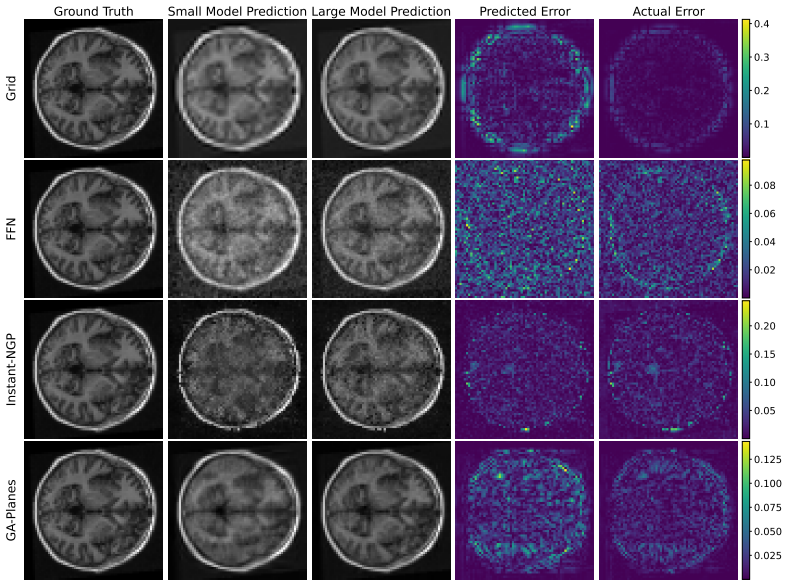
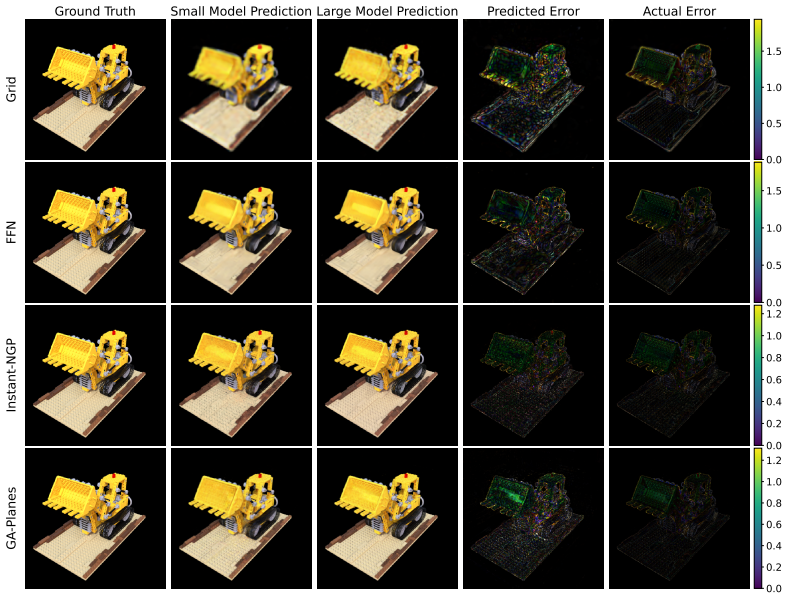
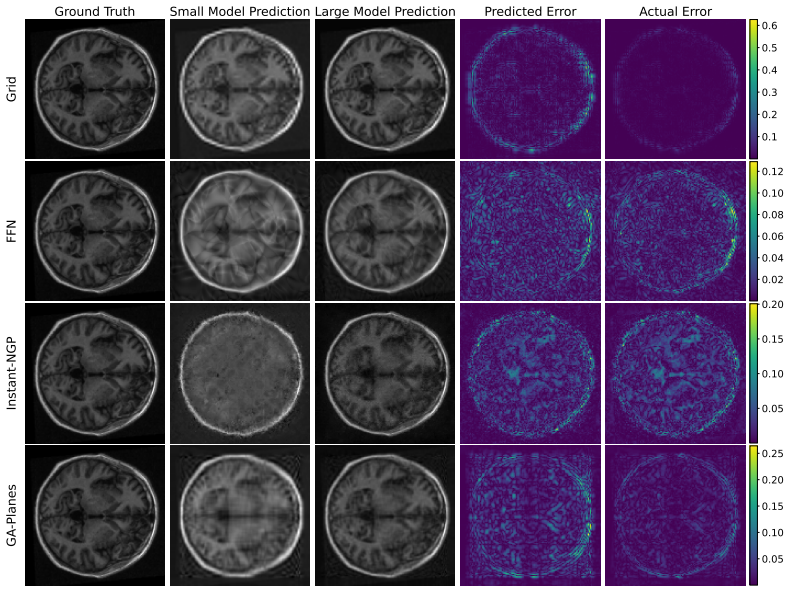
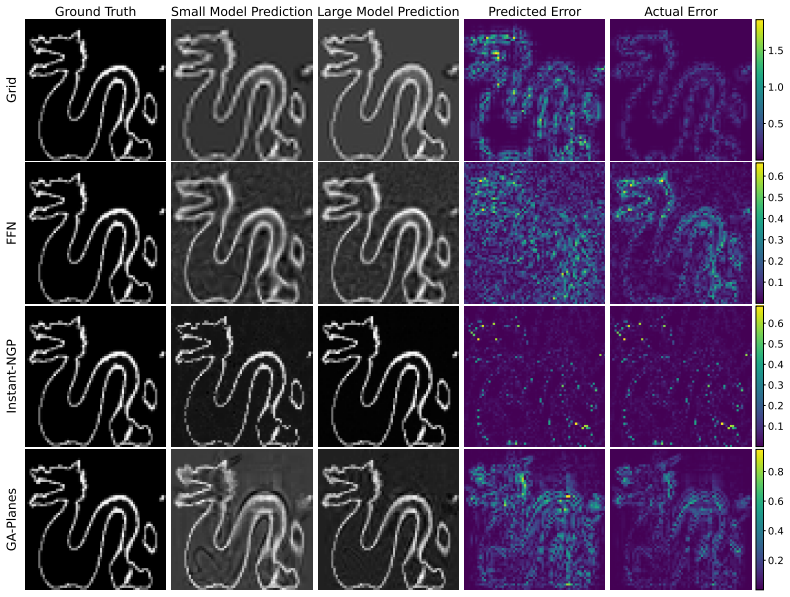
- The method yields both global error curves and local error heatmaps without ground truth.
- It applies to direct signal fitting and to inverse problems such as radiance field and MRI reconstruction.
Where Pith is reading between the lines
- The bound could support choosing compression levels during training by tracking the difference in real time.
- Similar difference-based bounds might be derivable for other parameterization families not yet verified.
- Local error heatmaps could guide spatially adaptive compression or refinement in imaging pipelines.
Load-bearing premise
The parameterization must satisfy certain natural properties for the error bound to apply.
What would settle it
Finding a parameterization that satisfies the natural properties yet has actual reconstruction error larger than the scaled prediction difference at some compression level.
Figures

read the original abstract
Differentiable signal parameterizations such as implicit neural representations (INRs) and hybrid models are increasingly central to computational imaging, yet principled tools for evaluating reconstruction fidelity at finite model size remain limited when ground truth is unavailable. We introduce a framework for predicting the reconstruction error of compressive signal parameterizations, yielding non-asymptotic, signal-specific bounds that are both theoretically sound and efficiently computable without access to the ground truth signal. Specifically, we prove that when parameterization-based compression satisfies certain natural properties, the compression error at any compression level is bounded by a simple scaled difference between model predictions at different compression levels. We verify these properties for representative model families including interpolated grids, Fourier feature networks, multi-resolution hash encodings, and tensor factorizations, and show empirically that the resulting worst-case guarantees can be efficiently adapted into signal-specific error predictors that are tight and generalizable. Across direct fitting of synthetic and natural signals, and inverse problems including radiance field and MRI reconstruction, our method closely tracks global error curves and yields informative local error heatmaps without ground-truth access. Code is available at https://github.com/voilalab/global_error_bound.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce a framework for non-asymptotic, ground-truth-free bounds on global and local reconstruction error for compressive differentiable signal parameterizations (INRs, grids, Fourier networks, hash encodings, tensor factorizations). The central result is a proof that, when the parameterization satisfies certain natural properties, the compression error at any level is bounded by a scaled difference between predictions at two different compression levels; these properties are verified for the listed families, and the bounds are empirically adapted into tight, generalizable error predictors demonstrated on direct fitting and inverse problems (radiance fields, MRI).
Significance. If the properties are correctly identified and the bound holds without reducing to a fitted quantity, the result supplies a practical, signal-specific tool for assessing finite-model reconstruction fidelity in settings where ground truth is unavailable. The empirical adaptation to global error curves and local heatmaps, plus code release, strengthens applicability in computational imaging.
major comments (3)
- [Proof of the bound] The central theorem (proof section): the bound is stated to hold under 'certain natural properties,' but the manuscript must explicitly enumerate these properties (e.g., any requirements on monotonicity, interpolation behavior, or continuity) and prove they are necessary and sufficient; without this, it is impossible to verify whether the guarantee applies to standard INR variants or contains hidden restrictions that would make the non-asymptotic claim inapplicable.
- [Verification for model families] Verification subsection for model families: the claim that the properties hold for multi-resolution hash encodings and tensor factorizations must include explicit checks against common implementation choices (e.g., hash collisions, rank choices); any counter-example in these families would render the headline guarantee inapplicable to the very models highlighted in the abstract and experiments.
- [Empirical adaptation into predictors] Empirical adaptation section: the post-hoc conversion of the bound into a signal-specific predictor must be shown not to introduce fitting parameters that make the 'ground-truth-free' guarantee circular; if the scaling factor or predictor coefficients are estimated from data, the independence from ground truth claimed in the abstract is undermined.
minor comments (2)
- [Abstract] Abstract and introduction: the phrase 'post-hoc adaptation into predictors' is mentioned but not expanded; a one-sentence clarification of the adaptation procedure would improve readability.
- [Figures] Figure captions for local error heatmaps: ensure axis labels and color scales are defined so that readers can directly compare predicted vs. actual local error without referring to the main text.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the presentation of our theoretical framework. We address each major comment point by point below, providing clarifications and indicating where the manuscript will be revised.
read point-by-point responses
-
Referee: [Proof of the bound] The central theorem (proof section): the bound is stated to hold under 'certain natural properties,' but the manuscript must explicitly enumerate these properties (e.g., any requirements on monotonicity, interpolation behavior, or continuity) and prove they are necessary and sufficient; without this, it is impossible to verify whether the guarantee applies to standard INR variants or contains hidden restrictions that would make the non-asymptotic claim inapplicable.
Authors: We will revise the proof section to explicitly enumerate the properties in a dedicated lemma (P1: monotonic decrease in prediction difference with increasing compression; P2: bounded Lipschitz constant of the parameterization map; P3: continuity of the compression operator). The central theorem shows these are sufficient for the non-asymptotic bound to hold via a direct application of the triangle inequality and the parameterization assumptions. We do not claim necessity, as the result is an implication (properties imply bound), and proving necessity would require constructing counterexamples outside the stated families, which is not required for the contribution but can be briefly discussed as future work. revision: partial
-
Referee: [Verification for model families] Verification subsection for model families: the claim that the properties hold for multi-resolution hash encodings and tensor factorizations must include explicit checks against common implementation choices (e.g., hash collisions, rank choices); any counter-example in these families would render the headline guarantee inapplicable to the very models highlighted in the abstract and experiments.
Authors: We agree this strengthens the verification. In the revised subsection, we will add explicit analysis: for hash encodings, the properties depend only on the differentiability and interpolation scheme, which hold independently of hash collisions (collisions affect the stored values but preserve monotonicity and continuity of the overall map); for tensor factorizations, we verify across rank choices by showing the low-rank constraint maintains the required properties as long as the factorization remains differentiable. No counterexamples arise under standard implementations. revision: yes
-
Referee: [Empirical adaptation into predictors] Empirical adaptation section: the post-hoc conversion of the bound into a signal-specific predictor must be shown not to introduce fitting parameters that make the 'ground-truth-free' guarantee circular; if the scaling factor or predictor coefficients are estimated from data, the independence from ground truth claimed in the abstract is undermined.
Authors: The adaptation computes the scaling factor and predictor coefficients exclusively from the model's own predictions at multiple compression levels, using only the theoretical bound expression; no ground-truth signal is involved at any stage. This preserves the ground-truth-free property. We will add a clarifying paragraph in the empirical section to explicitly state that all estimation steps operate solely on model outputs. revision: partial
Circularity Check
No circularity; bound is a conditional mathematical result under independently verified properties
full rationale
The paper states a theorem that compression error is bounded by a scaled difference of model predictions at different levels, conditional on the parameterization satisfying certain natural properties. It then verifies those properties hold for the listed families (grids, Fourier networks, hash encodings, tensor factorizations) and demonstrates empirical tightness. No equations reduce the bound to a fitted quantity by construction, no load-bearing self-citations are invoked for the core result, and the derivation does not rename known empirical patterns. The central claim remains independent of ground truth and is not forced by its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Parameterization-based compression satisfies certain natural properties (invoked as prerequisite for the error bound).
Reference graph
Works this paper leans on
-
[1]
Extreme MRI: Large-scale volumetric dynamic imaging from continuous non-gated acquisitions.Magnetic Resonance in Medicine, 84(4):1763–1780, 2020
Frank Ong, Xucheng Zhu, Joseph Y Cheng, Kevin M Johnson, Peder EZ Larson, Shreyas S Vasanawala, and Michael Lustig. Extreme MRI: Large-scale volumetric dynamic imaging from continuous non-gated acquisitions.Magnetic Resonance in Medicine, 84(4):1763–1780, 2020
2020
-
[2]
FFEINR: Flow Feature-Enhanced Implicit Neural Representation for Spatiotemporal Super-Resolution.Journal of Visualization, 27(2):273–289, 2024
Chenyue Jiao, Chongke Bi, and Lu Yang. FFEINR: Flow Feature-Enhanced Implicit Neural Representation for Spatiotemporal Super-Resolution.Journal of Visualization, 27(2):273–289, 2024
2024
-
[3]
D-NeRF: Neural Radiance Fields for Dynamic Scenes
Albert Pumarola, Enric Corona, Gerard Pons-Moll, and Francesc Moreno-Noguer. D-NeRF: Neural Radiance Fields for Dynamic Scenes. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10318–10327, 2021
2021
-
[4]
Plenoxels: Radiance Fields without Neural Networks
Sara Fridovich-Keil, Alex Yu, Matthew Tancik, Qinhong Chen, Benjamin Recht, and Angjoo Kanazawa. Plenoxels: Radiance Fields without Neural Networks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5501–5510, 2022
2022
-
[5]
Morgan Kaufmann, 1995
Richard H Bartels, John C Beatty, and Brian A Barsky.An Introduction to Splines for Use in Computer Graphics and Geometric Modeling. Morgan Kaufmann, 1995
1995
-
[6]
John Wiley & Sons, 2018
S Allen Broughton and Kurt Bryan.Discrete Fourier Analysis and Wavelets: Applications to Signal and Image Processing. John Wiley & Sons, 2018
2018
-
[7]
Learning Continuous Image Representation with Local Implicit Image Function
Yinbo Chen, Sifei Liu, and Xiaolong Wang. Learning Continuous Image Representation with Local Implicit Image Function. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8628–8638, 2021
2021
-
[8]
Lindell, Dave Van Veen, Jeong Joon Park, and Gordon Wetzstein
David B. Lindell, Dave Van Veen, Jeong Joon Park, and Gordon Wetzstein. BACON: Band- limited Coordinate Networks for Multiscale Scene Representation. In2022 IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR), pages 16231–16241, 2022. doi: 10.1109/CVPR52688.2022.01577
-
[9]
WIRE: Wavelet Implicit Neural Representations
Vishwanath Saragadam, Daniel LeJeune, Jasper Tan, Guha Balakrishnan, Ashok Veeraraghavan, and Richard G Baraniuk. WIRE: Wavelet Implicit Neural Representations. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18507–18516, 2023
2023
-
[10]
Martel, Alexander W
Vincent Sitzmann, Julien N.P. Martel, Alexander W. Bergman, David B. Lindell, and Gordon Wetzstein. Implicit Neural Representations with Periodic Activation Functions. InAdvances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[11]
Fourier Features Let Networks Learn High Frequency Functions in Low Dimensional Domains.Advances in Neural Information Processing Systems (NeurIPS), 33:7537–7547, 2020
Matthew Tancik, Pratul Srinivasan, Ben Mildenhall, Sara Fridovich-Keil, Nithin Raghavan, Utkarsh Singhal, Ravi Ramamoorthi, Jonathan Barron, and Ren Ng. Fourier Features Let Networks Learn High Frequency Functions in Low Dimensional Domains.Advances in Neural Information Processing Systems (NeurIPS), 33:7537–7547, 2020. 10
2020
-
[12]
Implicit Neural Representations for Image Compression
Yannick Strümpler, Janis Postels, Ren Yang, Luc Van Gool, and Federico Tombari. Implicit Neural Representations for Image Compression. InEuropean Conference on Computer Vision, pages 74–91. Springer, 2022
2022
-
[13]
Instant Neural Graphics Primitives with a Multiresolution Hash Encoding.ACM Transactions on Graphics (TOG), 41 (4):1–15, 2022
Thomas Müller, Alex Evans, Christoph Schied, and Alexander Keller. Instant Neural Graphics Primitives with a Multiresolution Hash Encoding.ACM Transactions on Graphics (TOG), 41 (4):1–15, 2022
2022
-
[14]
3D Gaussian Splatting for Real-Time Radiance Field Rendering.ACM Transactions on Graphics, 42(4), July
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis. 3D Gaussian Splatting for Real-Time Radiance Field Rendering.ACM Transactions on Graphics, 42(4), July
-
[15]
URLhttps://repo-sam.inria.fr/fungraph/3d-gaussian-splatting/
-
[16]
Yawar Siddiqui, Antonio Alliegro, Alexey Artemov, Tatiana Tommasi, Daniele Sirigatti, Vladislav Rosov, Angela Dai, and Matthias Nießner. MeshGPT: Generating Triangle Meshes with Decoder-Only Transformers.arXiv preprint arXiv:2311.15475, 2023
-
[17]
Continuous PDE Dynamics Forecasting with Implicit Neural Representations
Yuan Yin, Matthieu Kirchmeyer, Jean-Yves Franceschi, Alain Rakotomamonjy, and patrick gallinari. Continuous PDE Dynamics Forecasting with Implicit Neural Representations. In NeurIPS 2022 AI for Science: Progress and Promises, 2022. URL https://openreview. net/forum?id=iB3KkHR4gc
2022
-
[18]
TensoRF: Tensorial Radiance Fields
Anpei Chen, Zexiang Xu, Andreas Geiger, Jingyi Yu, and Hao Su. TensoRF: Tensorial Radiance Fields. InComputer Vision – ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XXXII, page 333–350, Berlin, Heidelberg,
2022
-
[19]
Springer-Verlag. ISBN 978-3-031-19823-6. doi: 10.1007/978-3-031-19824-3_20. URL https://doi.org/10.1007/978-3-031-19824-3_20
-
[20]
K-Planes: Explicit Radiance Fields in Space, Time, and Appearance
Sara Fridovich-Keil, Giacomo Meanti, Frederik Warburg, Benjamin Recht, and Angjoo Kanazawa. K-Planes: Explicit Radiance Fields in Space, Time, and Appearance. InComputer Vision and Pattern Recognition (CVPR), 2023
2023
-
[21]
Geometric Algebra Planes: Convex Implicit Neural V olumes
Irmak Sivgin, Sara Fridovich-Keil, Gordon Wetzstein, and Mert Pilanci. Geometric Algebra Planes: Convex Implicit Neural V olumes. InForty-second International Conference on Machine Learning, 2025. URLhttps://openreview.net/forum?id=yHpWI6a2xT
2025
-
[22]
Dictionary Fields: Learning a Neural Basis Decomposition.ACM Trans
Anpei Chen, Zexiang Xu, Xinyue Wei, Siyu Tang, Hao Su, and Andreas Geiger. Dictionary Fields: Learning a Neural Basis Decomposition.ACM Trans. Graph., 42(4), July 2023. ISSN 0730-0301. doi: 10.1145/3592135. URLhttps://doi.org/10.1145/3592135
-
[23]
Mixture of V olumetric Primitives for Efficient Neural Rendering.ACM Trans
Stephen Lombardi, Tomas Simon, Gabriel Schwartz, Michael Zollhoefer, Yaser Sheikh, and Jason Saragih. Mixture of V olumetric Primitives for Efficient Neural Rendering.ACM Trans. Graph., 40(4), 2021. ISSN 0730-0301. doi: 10.1145/3450626.3459863. URL https://doi. org/10.1145/3450626.3459863
-
[24]
Deep Learning for Accelerated and Robust MRI Reconstruction: a Review, 2024
Reinhard Heckel, Mathews Jacob, Akshay Chaudhari, Or Perlman, and Efrat Shimron. Deep Learning for Accelerated and Robust MRI Reconstruction: a Review, 2024. URL https: //arxiv.org/abs/2404.15692
-
[25]
Michael Lustig, David Donoho, and John M. Pauly. Sparse MRI: The application of compressed sensing for rapid MR imaging.Magnetic Resonance in Medicine, 58(6):1182–1195, 2007. doi: https://doi.org/10.1002/mrm.21391. URL https://onlinelibrary.wiley.com/doi/abs/ 10.1002/mrm.21391
-
[26]
Implicit Neural Representation in Medical Imaging: A Comparative Survey, 2023
Amirali Molaei, Amirhossein Aminimehr, Armin Tavakoli, Amirhossein Kazerouni, Bobby Azad, Reza Azad, and Dorit Merhof. Implicit Neural Representation in Medical Imaging: A Comparative Survey, 2023. URLhttps://arxiv.org/abs/2307.16142
-
[27]
NeRFs in Robotics: A Survey, 2025
Guangming Wang, Lei Pan, Songyou Peng, Shaohui Liu, Chenfeng Xu, Yanzi Miao, Wei Zhan, Masayoshi Tomizuka, Marc Pollefeys, and Hesheng Wang. NeRFs in Robotics: A Survey, 2025. URLhttps://arxiv.org/abs/2405.01333. 11
-
[28]
Teixeira, Joaquim Fonseca, Ricardo Cerqueira, and Sofia C
Bernardo Araújo, João F. Teixeira, Joaquim Fonseca, Ricardo Cerqueira, and Sofia C. Beco. The Road to Safety: A Review of Uncertainty and Applications to Autonomous Driving Perception.Entropy, 26(8), 2024. ISSN 1099-4300. doi: 10.3390/e26080634. URL https: //www.mdpi.com/1099-4300/26/8/634
-
[29]
Oswald, and Marc Pollefeys
Zihan Zhu, Songyou Peng, Viktor Larsson, Weiwei Xu, Hujun Bao, Zhaopeng Cui, Martin R. Oswald, and Marc Pollefeys. NICE-SLAM: Neural Implicit Scalable Encoding for SLAM. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
2022
-
[30]
iMAP: Implicit Mapping and Positioning in Real-Time
Edgar Sucar, Shikun Liu, Joseph Ortiz, and Andrew Davison. iMAP: Implicit Mapping and Positioning in Real-Time. InProceedings of the International Conference on Computer Vision (ICCV), 2021
2021
-
[31]
Satellite Image Compression-Detailed Survey of the Algo- rithms
KS Gunasheela and HS Prasantha. Satellite Image Compression-Detailed Survey of the Algo- rithms. InProceedings of International Conference on Cognition and Recognition: ICCR 2016, pages 187–198. Springer, 2018
2016
-
[32]
Carlos Gomes, Isabelle Wittmann, Damien Robert, Johannes Jakubik, Tim Reichelt, Stefano Maurogiovanni, Rikard Vinge, Jonas Hurst, Erik Scheurer, Rocco Sedona, Thomas Brun- schwiler, Stefan Kesselheim, Matej Bati ˇc, Philip Stier, Jan Dirk Wegner, Gabriele Caval- laro, Edzer Pebesma, Michael Marszalek, Miguel A. Belenguer-Plomer, Kennedy Adriko, Paolo Frac...
-
[33]
Astro- nomical image compression.Astronomy and Astrophysics Supplement Series, 136(3):579–590, 1999
Mireille Louys, Jean-Luc Starck, Simona Mei, François Bonnarel, and Fionn Murtagh. Astro- nomical image compression.Astronomy and Astrophysics Supplement Series, 136(3):579–590, 1999
1999
-
[34]
Compression of interferometric radio-astronomical data.Astronomy & Astro- physics, 595:A99, 2016
AR Offringa. Compression of interferometric radio-astronomical data.Astronomy & Astro- physics, 595:A99, 2016
2016
-
[35]
Dat Ngo, Hyun-Cheol Park, and Bongsoon Kang. Edge Intelligence: A Review of Deep Neural Network Inference in Resource-Limited Environments.Electronics, 14(12), 2025. ISSN 2079-9292. doi: 10.3390/electronics14122495. URL https://www.mdpi.com/2079-9292/ 14/12/2495
-
[36]
Zengshan YIN, Changhao WU, Chongbin GUO, Yuanchun LI, Mengwei XU, Weiwei GAO, and Chuanxiu CHI. A Comprehensive Survey on Orbital Edge Computing: Systems, Applications, and Algorithms.Chinese Journal of Aeronautics, 38(7):103316, July 2025. ISSN 1000-9361. doi: 10.1016/j.cja.2024.11.026. URL http://dx.doi.org/10.1016/j.cja.2024.11.026
-
[37]
R. Del Prete, P. K. Thind, A. Mazzeo, M. Whitley, L. Papa, N. Longépé, and G. Meoni. Optimizing deep learning models for on-orbit deployment through neural architecture search. Scientific Reports, 15(1), 2025. doi: 10.1038/s41598-025-21467-8. URL https://doi.org/ 10.1038/s41598-025-21467-8
-
[38]
Cover and Joy A
Thomas M. Cover and Joy A. Thomas.Elements of Information Theory. Wiley-Interscience, Hoboken, NJ, 2 edition, 2006
2006
-
[39]
A general approximation lower bound in L p norm, with applications to feed-forward neural networks
El Mehdi Achour, Armand Foucault, Sébastien Gerchinovitz, and Francois Malgouyres. A general approximation lower bound in L p norm, with applications to feed-forward neural networks. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho, editors, Advances in Neural Information Processing Systems, 2022. URL https://openreview.net/ forum?id=tfkeJG9yAX
2022
-
[40]
Jonathan W. Siegel and Jinchao Xu. Approximation Rates for Neural Networks with General Activation Functions.Neural Networks, 128:313–321, 2020. ISSN 0893-6080. doi: https:// doi.org/10.1016/j.neunet.2020.05.019. URL https://www.sciencedirect.com/science/ article/pii/S0893608020301891. 12
-
[41]
C. E. Shannon. Probability of Error for Optimal Codes in a Gaussian Channel.Bell System Technical Journal, 38:611–656, 1959. doi: 10.1002/j.1538-7305.1959.tb03905.x
-
[42]
NeRV: Neural Representations for Videos
Hao Chen, Bo He, Hanyu Wang, Yixuan Ren, Ser-Nam Lim, and Abhinav Shrivastava. NeRV: Neural Representations for Videos. InNeurIPS, 2021
2021
-
[43]
G. Dai, R. Zhang, Q. Wuwu, and et al. Implicit Neural Image Field for Biological Microscopy Image Compression.Nature Computational Science, 5:1041–1050, 2025. doi: 10.1038/ s43588-025-00889-4. URLhttps://doi.org/10.1038/s43588-025-00889-4
-
[44]
Compression with Bayesian Implicit Neural Representations
Zongyu Guo, Gergely Flamich, Jiajun He, Zhibo Chen, and José Miguel Hernández- Lobato. Compression with Bayesian Implicit Neural Representations. In A. Oh, T. Nau- mann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neu- ral Information Processing Systems, volume 36, pages 1938–1956. Curran Associates, Inc., 2023. URL https://proce...
1938
-
[45]
Towards Lossless Implicit Neural Representation via Bit Plane Decomposition
Woo Kyoung Han, Byeonghun Lee, Hyunmin Cho, Sunghoon Im, and Kyong Hwan Jin. Towards Lossless Implicit Neural Representation via Bit Plane Decomposition. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[46]
Andrew R. Barron. Universal Approximation Bounds for Superpositions of a Sigmoidal Function.IEEE Transactions on Information Theory, 39(3):930–945, 1993. doi: 10.1109/18. 256500
work page doi:10.1109/18 1993
-
[47]
Multilayer Feedforward Networks are Universal Approximators.Neural Networks, 2(5):359–366, 1989
Kurt Hornik, Maxwell Stinchcombe, and Halbert White. Multilayer Feedforward Networks are Universal Approximators.Neural Networks, 2(5):359–366, 1989. doi: 10.1016/0893-6080(89) 90020-8
-
[48]
Minimum Width for Universal Approximation
Sejun Park, Chulhee Yun, Jaeho Lee, and Jinwoo Shin. Minimum Width for Universal Approximation. InInternational Conference on Learning Representations, 2021. URL https://openreview.net/forum?id=O-XJwyoIF-k
2021
-
[49]
Minimum width for universal approximation using ReLU networks on compact domain
Namjun Kim, Chanho Min, and Sejun Park. Minimum width for universal approximation using ReLU networks on compact domain. InThe Twelfth International Conference on Learning Representations, 2024. URLhttps://openreview.net/forum?id=dpDw5U04SU
2024
-
[50]
NTIRE 2017 Challenge on Single Image Super-Resolution: Dataset and Study
Eirikur Agustsson and Radu Timofte. NTIRE 2017 Challenge on Single Image Super-Resolution: Dataset and Study. InThe IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, July 2017
2017
-
[51]
A V olumetric Method for Building Complex Models from Range Images
Brian Curless and Marc Levoy. A V olumetric Method for Building Complex Models from Range Images. InProceedings of the 23rd annual conference on Computer graphics and interactive techniques, pages 303–312, 1996
1996
-
[52]
Donnelly, Artemis Zavaliangos-Petropulu, Jessica N
Sook-Lei Liew, Bethany Lo, Miranda R. Donnelly, Artemis Zavaliangos-Petropulu, Jessica N. Jeong, Giuseppe Barisano, Alexandre Hutton, Julia P. Simon, Julia M. Juliano, Anisha Suri, Tyler Ard, Nerisa Banaj, Michael R. Borich, Lara A. Boyd, Amy Brodtmann, Cathrin M. Buetefisch, Lei Cao, Jessica M. Cassidy, Valentina Ciullo, Adriana B. Conforto, Steven C. Cr...
-
[53]
URL https://www.medrxiv.org/content/ early/2021/12/11/2021.12.09.21267554
doi: 10.1101/2021.12.09.21267554. URL https://www.medrxiv.org/content/ early/2021/12/11/2021.12.09.21267554. 13
-
[54]
Srinivasan, Matthew Tancik, Jonathan T
Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis. In Andrea Vedaldi, Horst Bischof, Thomas Brox, and Jan-Michael Frahm, editors,Computer Vision – ECCV 2020, pages 405–421, Cham, 2020. Springer International Publishing. ISBN 978-3-0...
2020
-
[55]
Grids Often Outperform Implicit Neural Representation at Compressing Dense Signals
Namhoon Kim and Sara Fridovich-Keil. Grids Often Outperform Implicit Neural Representation at Compressing Dense Signals. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URLhttps://openreview.net/forum?id=OZljvntsto
2025
-
[56]
van der Schaaf and J
A. van der Schaaf and J. H. van Hateren. Modelling the Power Spectra of Natural Images: Statistics and Information.Vision Research, 36(17):2759–2770, 1996
1996
-
[57]
Statistics of natural image categories.Network: Computation in Neural Systems, 14(3):391–412, 2003
Antonio Torralba and Aude Oliva. Statistics of natural image categories.Network: Computation in Neural Systems, 14(3):391–412, 2003
2003
-
[58]
Xu et al
Y . Xu et al. Systematic Differences Between Perceptually Relevant Image Statistics of Brain MRI and Natural Images.Frontiers in Neuroinformatics, 13:46, 2019
2019
-
[59]
Bartlett, Nick Harvey, Christopher Liaw, and Abbas Mehrabian
Peter L. Bartlett, Nick Harvey, Christopher Liaw, and Abbas Mehrabian. Nearly-tight VC- dimension and Pseudodimension Bounds for Piecewise Linear Neural Networks.Journal of Machine Learning Research, 20(63):1–17, 2019. URL http://jmlr.org/papers/v20/ 17-612.html
2019
-
[60]
Introduction to the non-asymptotic analysis of random matrices
Roman Vershynin. Introduction to the non-asymptotic analysis of random matrices, 2011. URL https://arxiv.org/abs/1011.3027
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[61]
Optimized Spatial Hashing for Collision Detection of Deformable Objects
Matthias Teschner, Bruno Heidelberger, Matthias Müller, D Pomerantes, Markus Gross, et al. Optimized Spatial Hashing for Collision Detection of Deformable Objects. InProc. VMV, pages 47–54, 2003
2003
-
[62]
Optical Models for Direct V olume Rendering.IEEE Transactions on Visualization and Computer Graphics, 1(2):99–108, 2002
Nelson Max. Optical Models for Direct V olume Rendering.IEEE Transactions on Visualization and Computer Graphics, 1(2):99–108, 2002. 14 Appendices Norm notation.Throughout the appendices, we use Lp to denote the function-space norms on continuous domains, consistent with the approximation theory literature [ 37, 38, 44], whereas ℓp denotes the finite-dime...
2002
-
[63]
The appended channel ofW ′ line is zero, so W ′⊤ line(e′ 1 ◦e ′
= (e1 ◦e 2) 0 . The appended channel ofW ′ line is zero, so W ′⊤ line(e′ 1 ◦e ′
-
[64]
low-bandwidth
+W ′⊤ planee′ 12 +b ′ =W ⊤ line(e1 ◦e 2) +W ⊤ planee12 +b, which equals the output of g∈ G k1. Therefore, Gk1 ⊆ G k1+1 and the optimal reconstruction error is nonincreasing ink 1. Lemma GAP.2(GA-Planes satisfies Assumption A2 for squared error).For allk 1 ≥0, ∥x−g ⋆ k1 ∥2 − ∥x−g ⋆ k1+1∥2 ≥ ∥x−g ⋆ k1+1∥2 − ∥x−g ⋆ k1+2∥2. Proof. By the matrix-completion equ...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.