HeLoCo: Efficient asynchronous low-communication training under data and device heterogeneity
Pith reviewed 2026-06-28 20:43 UTC · model grok-4.3
The pith
HeLoCo corrects misaligned pseudo-gradients in asynchronous DiLoCo training by referencing outer momentum to handle data and device heterogeneity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
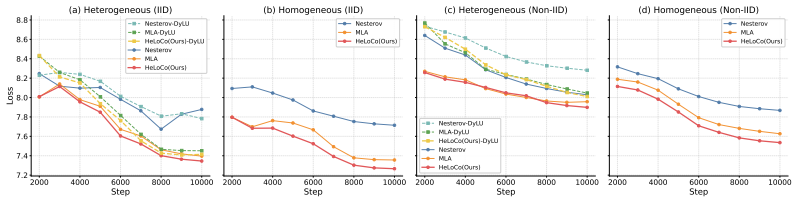
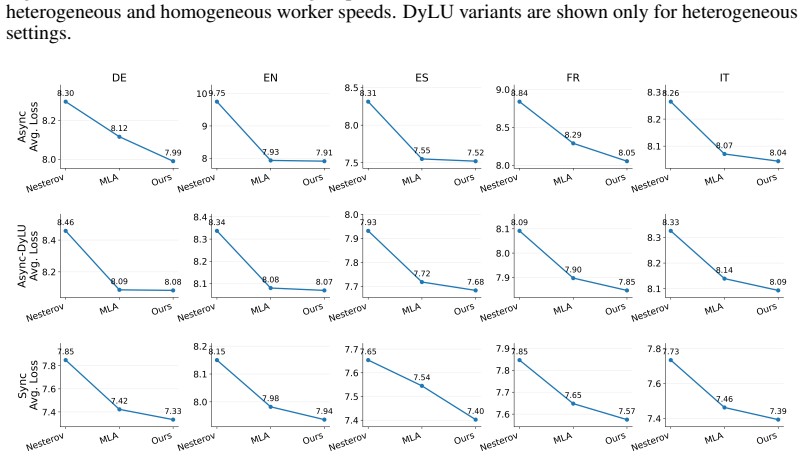
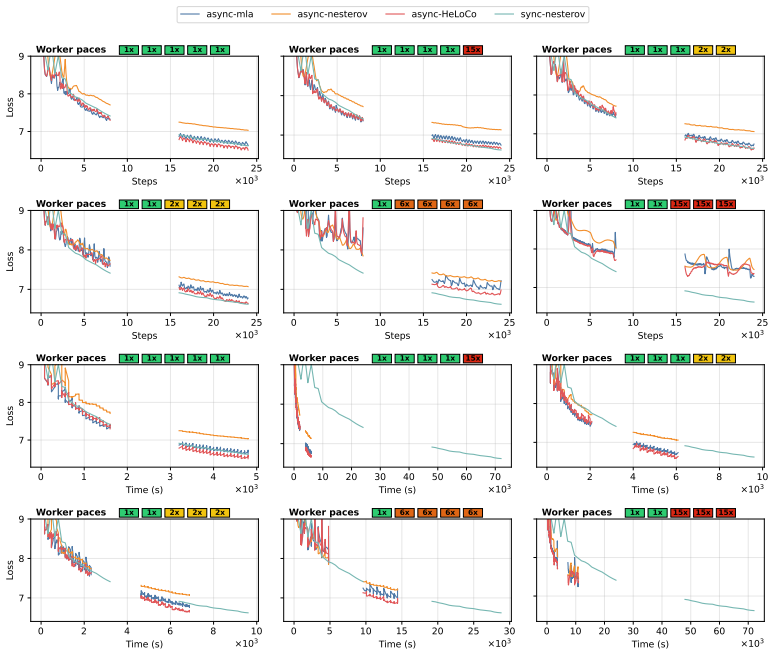
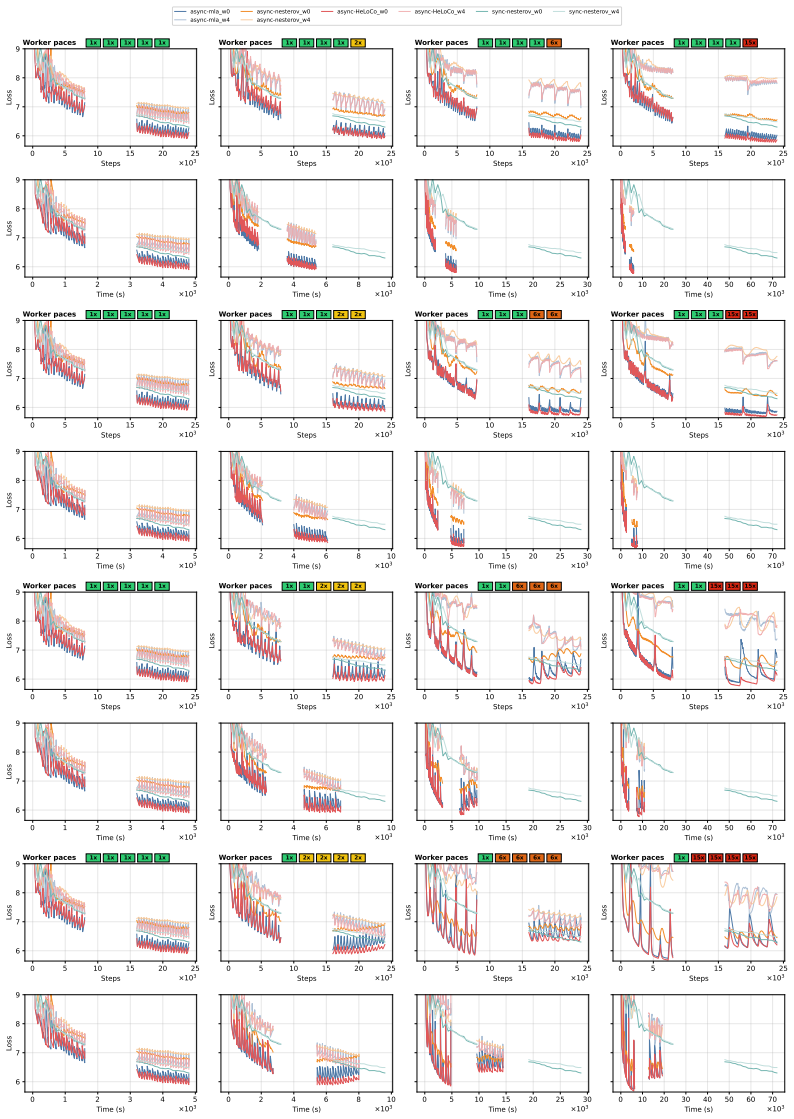
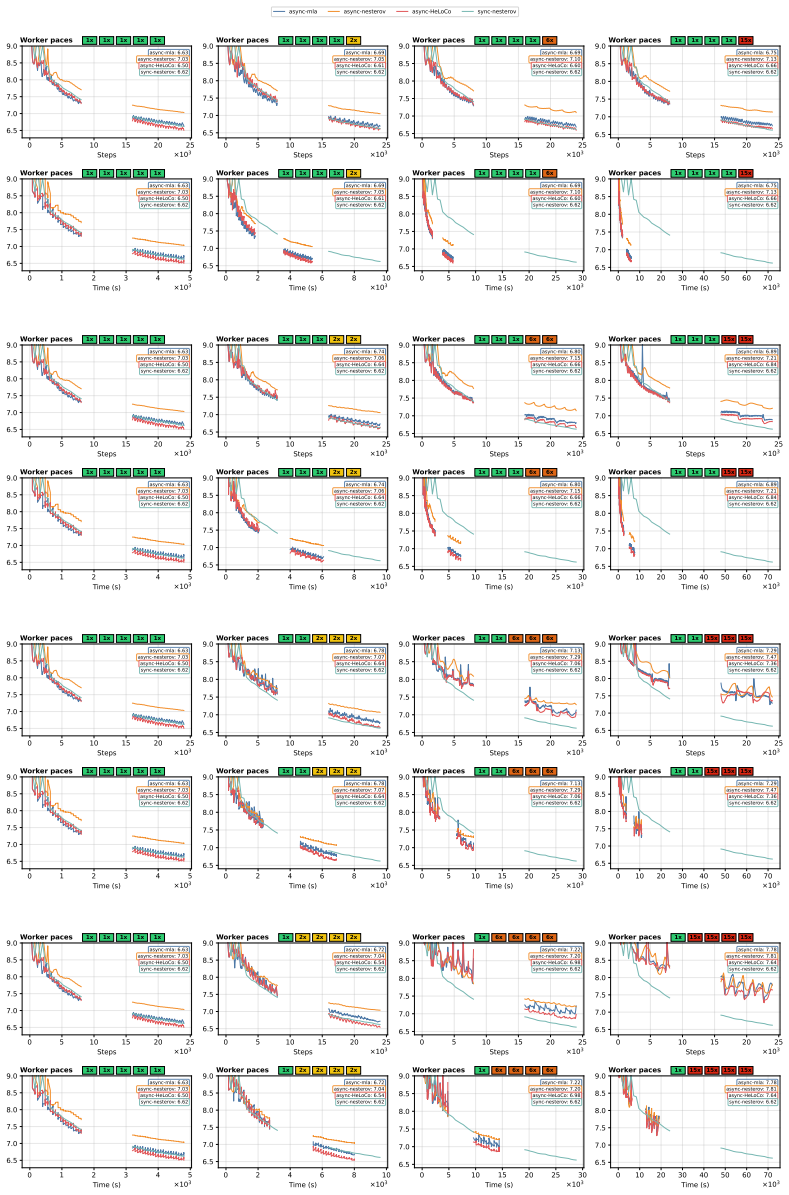
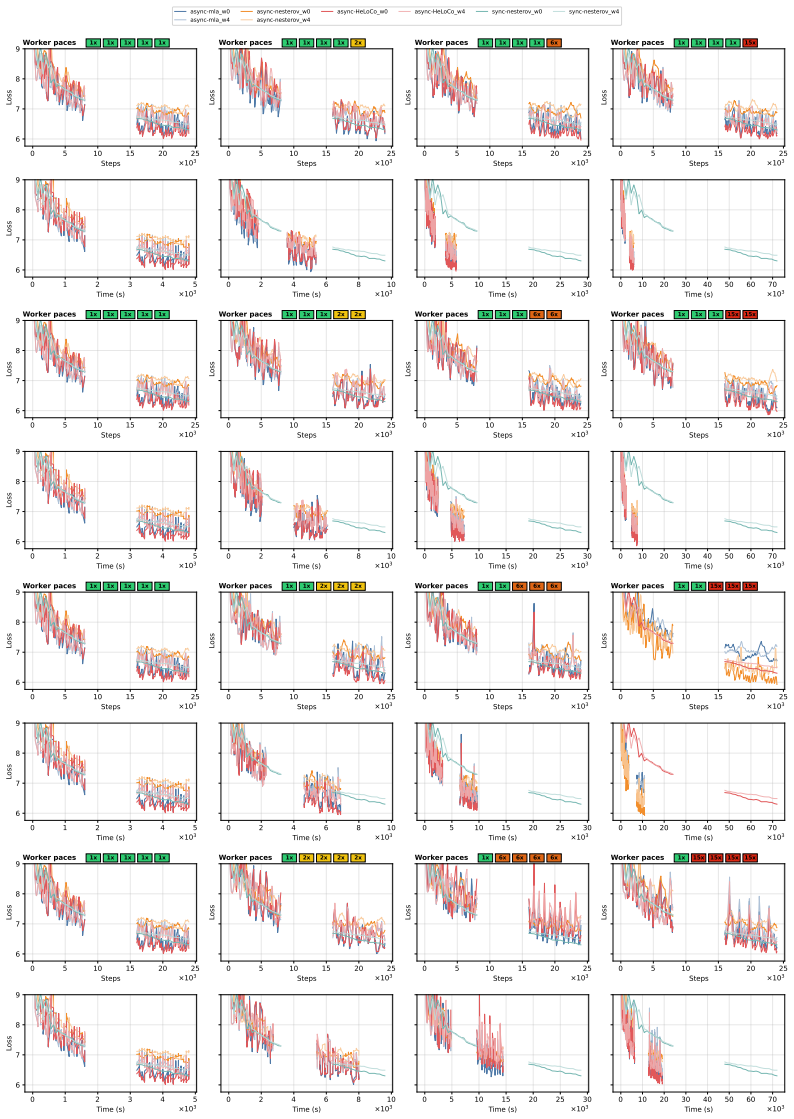
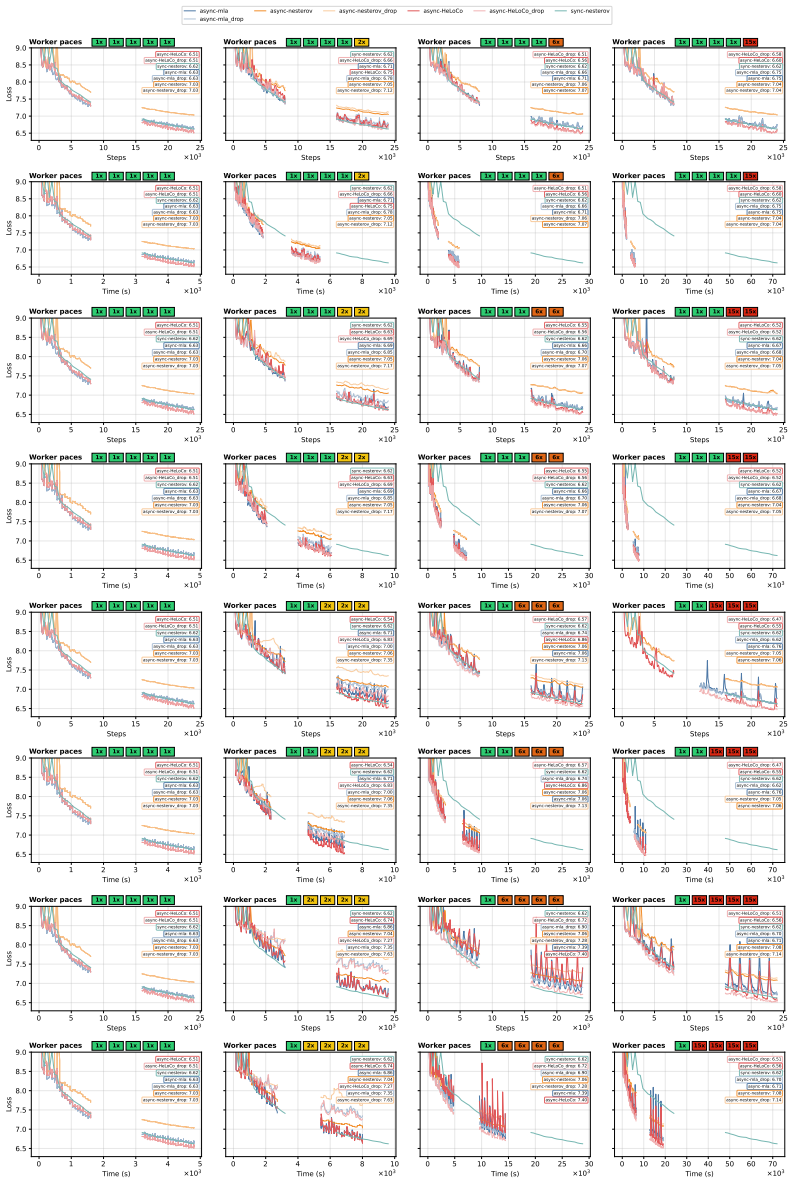
HeLoCo is a direction-aware correction method for asynchronous low-communication training that uses outer momentum as a reference for the current optimization trajectory and selectively adjusts incoming pseudo-gradients before the outer update. Updates that remain aligned are preserved, while directionally conflicting components are corrected. On multilingual language-model training with heterogeneous workers and non-IID data, HeLoCo consistently improves validation loss. It outperforms existing asynchronous DiLoCo-based baselines by up to 7.5% at a fixed token budget, exceeds asynchronous momentum look-ahead by up to 3.3% at a fixed wall-clock budget, and surpasses the synchronous baseline
What carries the argument
Outer-momentum reference for selective direction-aware correction of incoming pseudo-gradients before the global outer update.
If this is right
- Validation loss improves consistently in multilingual LM training under worker and data heterogeneity.
- Outperforms async DiLoCo baselines by up to 7.5 percent at fixed token budget.
- Outperforms async momentum look-ahead by up to 3.3 percent at fixed wall-clock budget.
- Outperforms the fully synchronous baseline by up to 22.1 percent when system heterogeneity is severe.
Where Pith is reading between the lines
- The correction may allow training to continue scaling as the number of heterogeneous devices grows without proportional slowdown.
- Momentum could serve as a lightweight proxy for global direction in other decentralized optimizers beyond DiLoCo.
- The method's effectiveness likely depends on how quickly outer momentum tracks changes when data partitions differ sharply across workers.
Load-bearing premise
Outer momentum provides a sufficiently accurate reference for the current global optimization trajectory so selective correction of pseudo-gradients improves rather than harms convergence under non-IID data and varying worker speeds.
What would settle it
In a controlled run with the same heterogeneous workers and non-IID data, remove the selective correction step and check whether validation loss stops improving or worsens relative to the corrected version.
Figures

read the original abstract
Distributed Low-Communication (DiLoCo) training reduces communication overhead by allowing workers to perform multiple local optimization steps before sending pseudo-gradients to a global outer update. Its asynchronous variant further improves hardware utilization by removing synchronization barriers, but at the cost of stale pseudo-gradients computed from outdated model states. As a result, these updates can become misaligned with the current global optimization direction, particularly in heterogeneous systems. This issue becomes even more pronounced when data are non-IID, a setting that has not been well studied in asynchronous low-communication training. To address this limitation, we propose \textbf{HeLoCo}, a direction-aware correction method for asynchronous low-communication training that uses outer momentum as a reference for the current optimization trajectory and selectively adjusts incoming pseudo-gradients before the outer update. Updates that remain aligned are preserved, while directionally conflicting components are corrected. On multilingual language-model training with heterogeneous workers and non-IID data, HeLoCo consistently improves validation loss. It outperforms existing asynchronous DiLoCo-based baselines by up to 7.5\% at a fixed token budget, exceeds asynchronous momentum look-ahead by up to 3.3\% at a fixed wall-clock budget, and surpasses the synchronous baseline by up to 22.1\% under severe system heterogeneity. Our analysis further shows how staleness, worker speed, and data heterogeneity shape update quality and convergence in highly decentralized and heterogeneous training setups.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes HeLoCo, a direction-aware correction technique for asynchronous DiLoCo training. It uses outer momentum as a reference trajectory to selectively preserve or correct components of stale pseudo-gradients before the outer update, targeting misalignment caused by asynchrony, device heterogeneity, and non-IID data. On multilingual language-model training, the method is reported to improve validation loss by up to 7.5% over async DiLoCo baselines at fixed token budget, 3.3% over async momentum look-ahead at fixed wall-clock time, and 22.1% over the synchronous baseline under severe heterogeneity.
Significance. If the empirical gains and the underlying correction rule prove robust, the work would address a practically relevant gap in low-communication asynchronous training under realistic heterogeneity. The focus on non-IID multilingual data and the explicit handling of staleness via momentum alignment are timely; reproducible code or parameter-free derivations are not mentioned.
major comments (3)
- [Method / Analysis] The central mechanism treats outer momentum as a stable proxy for the current global trajectory when deciding which pseudo-gradient components to correct. No section provides a bound or convergence argument showing that this proxy remains faithful under the paper's target regime of arbitrary staleness combined with non-IID data partitions; the skeptic concern therefore remains unaddressed.
- [Experiments] Abstract and claimed results report quantitative improvements (7.5%, 3.3%, 22.1%) without error bars, number of independent runs, or ablation on the alignment threshold / correction rule. This makes it impossible to judge whether the gains are statistically reliable or sensitive to hyper-parameter choices.
- [Experimental Setup] The description of data heterogeneity and worker-speed distributions is insufficient to reproduce the claimed non-IID + heterogeneous regime; no table or section lists the exact partitioning strategy, degree of non-IIDness, or speed variance used in the multilingual experiments.
minor comments (2)
- [Method] Notation for pseudo-gradient, outer momentum, and correction operator should be introduced once with consistent symbols rather than re-defined inline.
- [Figures] Figure captions should explicitly state whether shaded regions represent standard deviation across seeds or across workers.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each of the major comments below and outline the revisions we plan to make.
read point-by-point responses
-
Referee: [Method / Analysis] The central mechanism treats outer momentum as a stable proxy for the current global trajectory when deciding which pseudo-gradient components to correct. No section provides a bound or convergence argument showing that this proxy remains faithful under the paper's target regime of arbitrary staleness combined with non-IID data partitions; the skeptic concern therefore remains unaddressed.
Authors: We acknowledge that a formal convergence analysis or bound for the outer momentum proxy under arbitrary staleness and non-IID conditions is not provided. Deriving such a bound is challenging due to the complex interactions in heterogeneous asynchronous settings and would likely require restrictive assumptions not aligned with our practical focus. Our contribution is empirical, demonstrating consistent improvements across various heterogeneity levels. In the revision, we will expand the discussion section to better justify the proxy choice and highlight its empirical robustness. revision: partial
-
Referee: [Experiments] Abstract and claimed results report quantitative improvements (7.5%, 3.3%, 22.1%) without error bars, number of independent runs, or ablation on the alignment threshold / correction rule. This makes it impossible to judge whether the gains are statistically reliable or sensitive to hyper-parameter choices.
Authors: We agree that including statistical measures and ablations would strengthen the claims. We will rerun the key experiments with multiple random seeds to report means and standard deviations (error bars), specify the number of runs, and add an ablation study on the alignment threshold and correction rule parameters to assess sensitivity. revision: yes
-
Referee: [Experimental Setup] The description of data heterogeneity and worker-speed distributions is insufficient to reproduce the claimed non-IID + heterogeneous regime; no table or section lists the exact partitioning strategy, degree of non-IIDness, or speed variance used in the multilingual experiments.
Authors: We apologize for the insufficient detail in the experimental setup. In the revised manuscript, we will include a new subsection or table that explicitly describes the data partitioning strategy for non-IID multilingual data, the metric or parameter quantifying the degree of non-IIDness, and the specific distributions or variances for worker speeds used in the experiments. revision: yes
- A formal convergence bound or theoretical guarantee for the outer momentum reference under arbitrary staleness and non-IID data.
Circularity Check
No circularity: method is a proposed heuristic with empirical validation
full rationale
The paper introduces HeLoCo as a direction-aware correction heuristic that references outer momentum to adjust stale pseudo-gradients. No derivation chain, equations, or self-citations are exhibited that reduce the claimed improvements to a fit, self-definition, or prior result by the same authors. The reported gains (7.5%, 3.3%, 22.1%) are presented as experimental outcomes under heterogeneous conditions rather than predictions forced by construction from inputs. The central premise relies on the external validity of the momentum reference, which is an assumption open to falsification rather than a closed loop.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
and Chhaparia, Rachita and Donchev, Yani and Kuncoro, Adhiguna and Ranzato, Marc'Aurelio and Szlam, Arthur and Shen, Jiajun , title =
Douillard, Arthur and Feng, Qixuan and Rusu, Andrei A. and Chhaparia, Rachita and Donchev, Yani and Kuncoro, Adhiguna and Ranzato, Marc'Aurelio and Szlam, Arthur and Shen, Jiajun , title =. arXiv , year =
-
[2]
URLhttps://openreview.net/forum?id= yYk3zK0X6Q
Streaming diloco with overlapping communication: Towards a distributed free lunch , author=. arXiv preprint arXiv:2501.18512 , year=
-
[3]
Jaghouar, Sami and Ong, Jack Min and Hagemann, Johannes , journal=
-
[4]
arXiv preprint arXiv:2401.09135 , year=
Asynchronous local-sgd training for language modeling , author=. arXiv preprint arXiv:2401.09135 , year=
-
[5]
ICLR 2025 Workshop on Modularity for Collaborative, Decentralized, and Continual Deep Learning , year=
Momentum look-ahead for asynchronous distributed low-communication training , author=. ICLR 2025 Workshop on Modularity for Collaborative, Decentralized, and Continual Deep Learning , year=
2025
-
[6]
arXiv preprint arXiv:2401.00809 , year=
A review on different techniques used to combat the non-IID and heterogeneous nature of data in FL , author=. arXiv preprint arXiv:2401.00809 , year=
-
[7]
Proceedings of the AAAI conference on artificial intelligence , volume=
Fedasmu: Efficient asynchronous federated learning with dynamic staleness-aware model update , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[8]
Qi, Ji and Zhu, WenPeng and Li, Li and Wu, Ming and Wu, YingJun and He, Wu and Gao, Xun and Zeng, Jason and Heinrich, Michael , journal=
-
[9]
arXiv preprint arXiv:2506.10911 , year=
Kolehmainen, Jari and Blagoev, Nikolay and Donaghy, John and Ersoy, O. arXiv preprint arXiv:2506.10911 , year=
-
[10]
Advances in neural information processing systems , volume=
Hogwild!: A lock-free approach to parallelizing stochastic gradient descent , author=. Advances in neural information processing systems , volume=
-
[11]
Advances in Neural Information Processing Systems , volume=
Slow learners are fast , author=. Advances in Neural Information Processing Systems , volume=
-
[12]
Advances in Neural Information Processing Systems , volume=
Large scale distributed deep networks , author=. Advances in Neural Information Processing Systems , volume=
-
[13]
2016 54th Annual Allerton Conference on Communication, Control, and Computing (Allerton) , pages=
Asynchrony begets momentum, with an application to deep learning , author=. 2016 54th Annual Allerton Conference on Communication, Control, and Computing (Allerton) , pages=. 2016 , organization=
2016
-
[14]
International conference on machine learning , pages=
Asynchronous stochastic gradient descent with delay compensation , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[15]
2017 , volume =
McMahan, Brendan and Moore, Eider and Ramage, Daniel and Hampson, Seth and Arcas, Blaise Aguera y , booktitle =. 2017 , volume =
2017
-
[16]
Proceedings of Machine learning and systems , volume=
Federated optimization in heterogeneous networks , author=. Proceedings of Machine learning and systems , volume=
-
[17]
2020 , organization=
Karimireddy, Sai Praneeth and Kale, Satyen and Mohri, Mehryar and Reddi, Sashank and Stich, Sebastian U and Suresh, Ananda Theertha , booktitle=. 2020 , organization=
2020
-
[18]
Advances in Neural Information Processing Systems , volume=
Tackling the objective inconsistency problem in heterogeneous federated optimization , author=. Advances in Neural Information Processing Systems , volume=
-
[19]
Advances in Neural Information Processing Systems , volume=
Gradient surgery for multi-task learning , author=. Advances in Neural Information Processing Systems , volume=
-
[20]
, title =
Raffel, Colin and Shazeer, Noam and Roberts, Adam and Lee, Katherine and Narang, Sharan and Matena, Michael and Zhou, Yanqi and Li, Wei and Liu, Peter J. , title =. Journal of Machine Learning Research , year =
-
[21]
OpenAI blog , volume=
Language models are unsupervised multitask learners , author=. OpenAI blog , volume=
-
[22]
Advances in neural information processing systems , volume=
Lookahead optimizer: k steps forward, 1 step back , author=. Advances in neural information processing systems , volume=
-
[23]
Proceedings of Machine Learning and Systems , volume=
Adaptive communication strategies to achieve the best error-runtime trade-off in local-update SGD , author=. Proceedings of Machine Learning and Systems , volume=
-
[24]
Decoupled DiLoCo for Resilient Distributed Pre-training
Decoupled DiLoCo for Resilient Distributed Pre-training , author=. arXiv preprint arXiv:2604.21428 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Toward Understanding the Impact of Staleness in Distributed Machine Learning
Toward understanding the impact of staleness in distributed machine learning , author=. arXiv preprint arXiv:1810.03264 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Proceedings of the 39th International Conference on Machine Learning , pages =
B. Proceedings of the 39th International Conference on Machine Learning , pages =. 2022 , volume =
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.