Generative Multi-Robot Motion Planning via Diffusion Modeling with Multi-Agent Reinforcement Learning Guidance
Pith reviewed 2026-06-28 18:15 UTC · model grok-4.3
The pith
A MARL-trained value function guides diffusion models to generate coordinated multi-robot trajectories without joint planning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
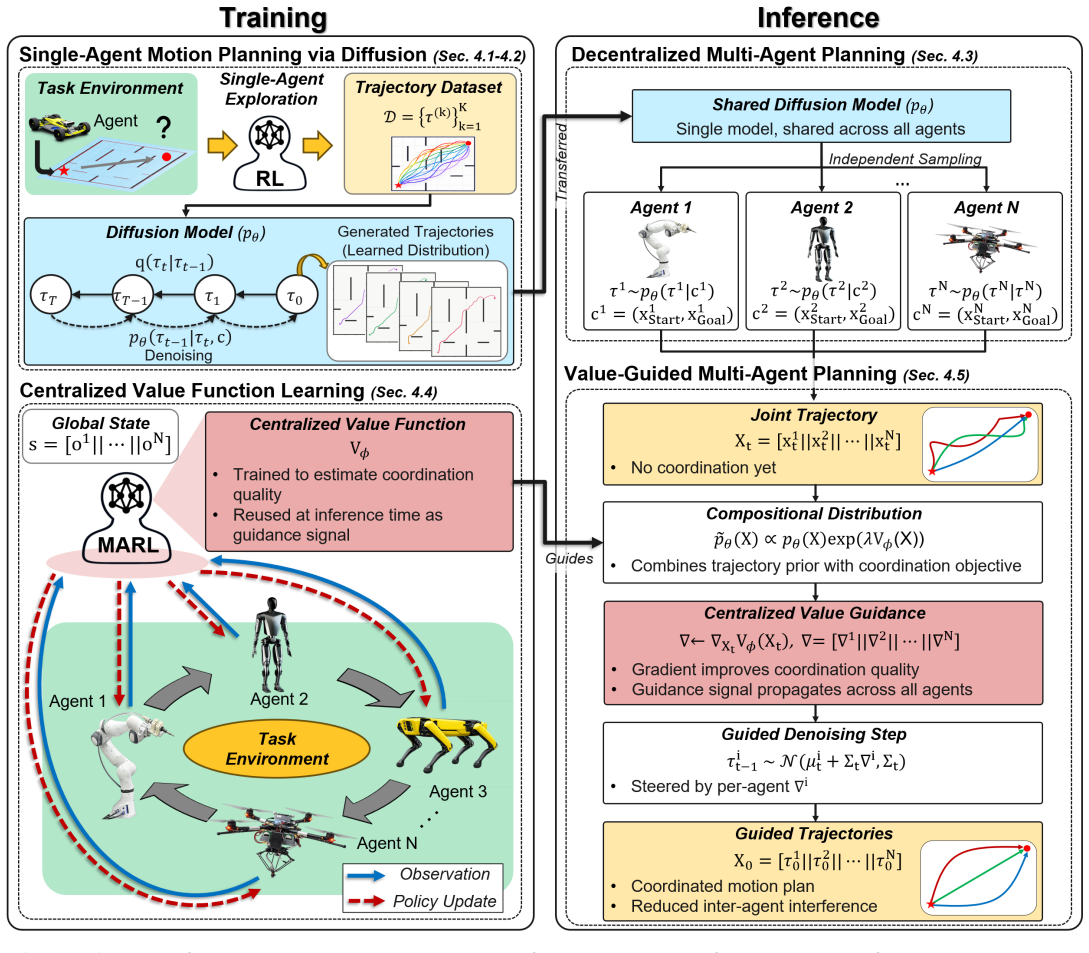
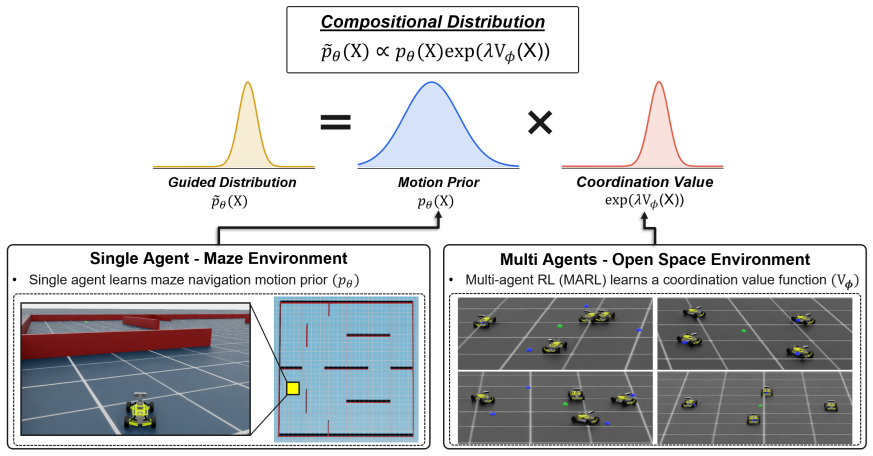
Each robot independently generates candidate trajectories using a diffusion model trained on single-agent motion data. A centralized value function trained via MARL guides the reverse diffusion process through gradient-based steering using an exponential tilting formulation, biasing the denoising distribution toward trajectories with higher expected multi-agent return. This enables interaction-aware trajectory generation without centralized joint planning or retraining of the generative model.
What carries the argument
The exponential tilting formulation that uses the MARL value function to steer the reverse diffusion process toward higher multi-agent returns.
If this is right
- Coordination is introduced into decentralized planners without requiring a fully joint multi-robot model.
- The generative model does not need retraining for multi-agent settings.
- Scalability of decentralized trajectory generation is preserved as the number of robots grows.
- Inter-agent interference is reduced in simulated environments with multiple mobile robots.
Where Pith is reading between the lines
- This approach might extend to other types of generative models if they support gradient-based guidance during generation.
- Real-world deployment would require testing whether the value function generalizes across different maze layouts or robot dynamics.
- Agents could potentially operate with less communication if the value function captures most interaction effects.
- The method suggests a hybrid path between fully decentralized and fully centralized planning for other multi-agent tasks.
Load-bearing premise
The centralized value function from MARL can be used to steer individual diffusion processes effectively enough to reduce conflicts without needing to model the full joint state space during planning.
What would settle it
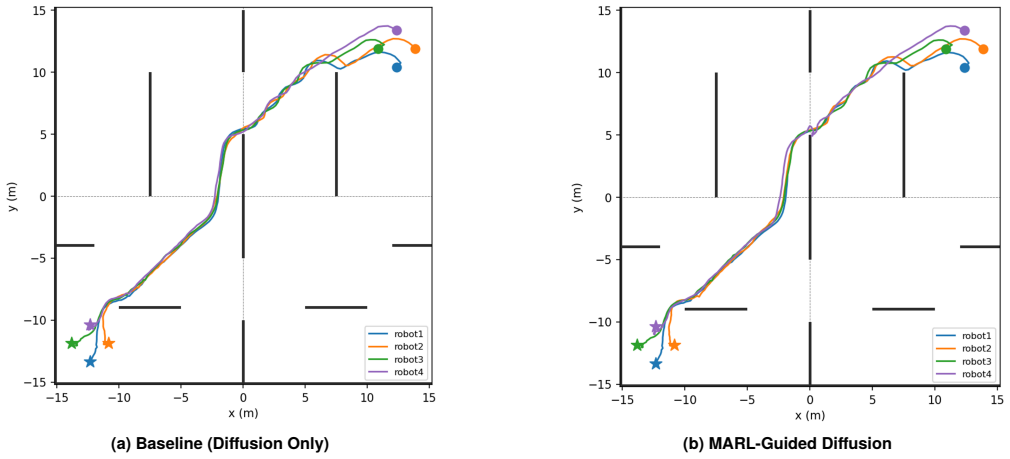
Running the four-robot maze simulation and observing no reduction from the 55.4% interference rate when the value guidance is applied.
Figures

read the original abstract
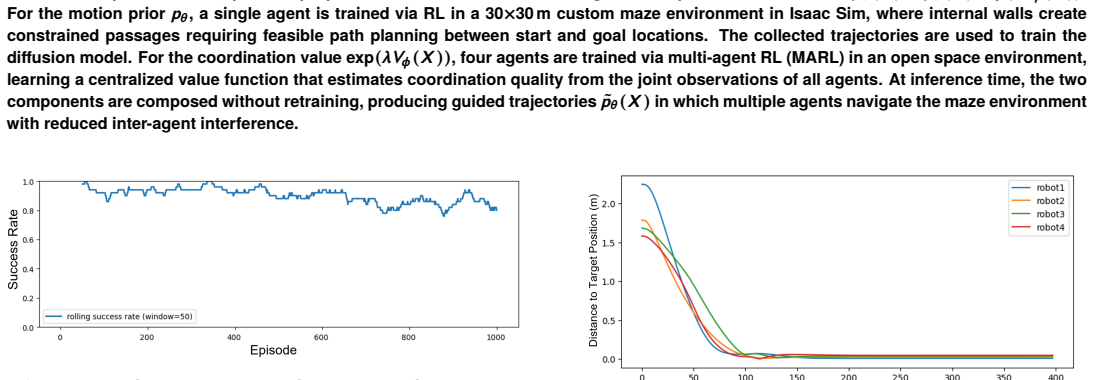
Coordinating multiple robots in shared environments requires generating feasible trajectories for each agent while accounting for interactions among agents. Centralized planning approaches become difficult to scale as the number of robots increases, while decentralized approaches that allow each agent to plan independently do not inherently account for inter-agent interactions. This paper presents a framework for coordinated multi-robot motion planning that combines decentralized generative trajectory planning with multi-agent reinforcement learning (MARL)-based coordination. Each robot independently generates candidate trajectories using a diffusion model trained on single-agent motion data, leveraging the generative model's ability to produce feasible and diverse trajectories. To reduce conflicts between agents, a centralized value function trained via MARL guides the reverse diffusion process through gradient-based steering, enabling interaction-aware trajectory generation without centralized joint planning or retraining of the generative model. This guidance follows an exponential tilting formulation, in which the value function biases the denoising distribution toward trajectories with higher expected multi-agent return. The framework is evaluated in a simulated maze environment with four mobile robots. Experimental results show that the proposed value-guided diffusion planning reduces the inter-agent interference rate from 55.4% to 41.8%, demonstrating that coordination can be effectively achieved while preserving the scalability of decentralized trajectory generation. These results suggest that MARL-based value guidance can effectively introduce coordination into decentralized generative planners without requiring a fully joint multi-robot model.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a multi-robot motion planning framework that generates trajectories independently per robot using a diffusion model trained on single-agent data, then applies gradient-based steering from a centralized MARL-trained value function during the reverse diffusion process (via exponential tilting) to bias toward higher multi-agent returns and reduce conflicts, without retraining the generative model or performing joint planning. In a four-robot maze simulation, this yields an inter-agent interference rate reduction from 55.4% to 41.8%.
Significance. If the quantitative result holds under scrutiny, the approach demonstrates a practical way to inject coordination into scalable decentralized generative planners, addressing a key tension between decentralization and interaction awareness in multi-robot systems.
major comments (1)
- [Abstract] Abstract (evaluation paragraph): the central claim rests on the reported interference reduction (55.4% o 41.8%), yet no information is supplied on the number of trials, variance, statistical tests, choice of baselines (e.g., pure diffusion without guidance, centralized planners), or training details for the diffusion model and MARL value function; this prevents verification that the improvement is robust and not an artifact of post-hoc selection or insufficient controls.
minor comments (1)
- [Abstract] Abstract: the description of the exponential-tilting guidance mechanism would be clearer with an explicit equation relating the value function to the modified denoising distribution.
Simulated Author's Rebuttal
We thank the referee for the detailed comment on the abstract. We address the point below and will revise the manuscript to improve clarity and completeness of the reported results.
read point-by-point responses
-
Referee: [Abstract] Abstract (evaluation paragraph): the central claim rests on the reported interference reduction (55.4% o 41.8%), yet no information is supplied on the number of trials, variance, statistical tests, choice of baselines (e.g., pure diffusion without guidance, centralized planners), or training details for the diffusion model and MARL value function; this prevents verification that the improvement is robust and not an artifact of post-hoc selection or insufficient controls.
Authors: We agree that the abstract would benefit from additional context on the evaluation to allow readers to assess robustness. In the revised manuscript we will expand the evaluation sentence in the abstract to note that results are reported over multiple independent simulation trials (with full counts, variance measures, and any statistical tests provided in Section 4), identify the unguided diffusion model as the direct baseline, and briefly summarize the single-agent training of the diffusion model and the centralized MARL value function. The paper focuses on decentralized planning and therefore does not include centralized joint planners as baselines; we can add an explicit statement on this design choice and its rationale if desired. These changes will make the abstract self-contained while preserving its length. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes a hybrid framework where a diffusion model is trained on single-agent trajectories and a separate centralized value function is trained via MARL; the guidance mechanism (exponential tilting via gradient steering) is applied at inference time. The reported result is an empirical measurement of interference rate reduction in simulation, not a quantity derived by construction from the same fitted parameters or self-referential definitions. No equations, uniqueness theorems, or self-citations are shown that collapse the central claim to its inputs. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Diffusion models trained on single-agent motion data can generate feasible and diverse trajectories for each robot independently.
- domain assumption A centralized value function trained via MARL can be used to steer the denoising process without retraining the generative model.
Reference graph
Works this paper leans on
-
[1]
Ad- vances in multi-robot systems
Arai, Tamio, Pagello, Enrico, Parker, Lynne E et al. “Ad- vances in multi-robot systems.”IEEE Transactions on robotics and automationVol. 18 No. 5 (2002): pp. 655– 661
2002
-
[2]
Multi-robot motion planning byincrementalcoordination
Saha, Mitul and Isto, Pekka. “Multi-robot motion planning byincrementalcoordination.”2006IEEE/RSJInternational Conference on Intelligent Robots and Systems: pp. 5960–
-
[3]
Generative Model PredictiveControlinManufacturingProcesses: AReview
Lee,SukKi,Stone,RonnieFP,Gao,Max,Zhang,Wenlong, Sha, Zhenghui and Ko, Hyunwoong. “Generative Model PredictiveControlinManufacturingProcesses: AReview.” arXiv preprint arXiv:2511.17865(2025)
arXiv 2025
-
[4]
SafeZone*: A Graph-Based and Time-Optimal Coopera- tive 3D Printing Framework
Stone, Ronnie FP, Ebert, Matthew, Zhou, Wenchao, Akle- man, Ergun, Krishnamurthy, Vinayak and Sha, Zhenghui. “SafeZone*: A Graph-Based and Time-Optimal Coopera- tive 3D Printing Framework.”Journal of Computing and Information Science in EngineeringVol. 25 No. 6 (2025): p. 061004
2025
-
[5]
A heuristic scaling strat- egy for multi-robot cooperative three-dimensional print- ing
Poudel, Laxmi, Blair, Chandler, McPherson, Jace, Sha, Zhenghui and Zhou, Wenchao. “A heuristic scaling strat- egy for multi-robot cooperative three-dimensional print- ing.”Journal of Computing and Information Science in EngineeringVol. 20 No. 4 (2020): p. 041002
2020
-
[6]
Conflict-based search for optimal multi-agent pathfinding
Sharon, Guni, Stern, Roni, Felner, Ariel and Sturtevant, Nathan R. “Conflict-based search for optimal multi-agent pathfinding.”Artificial intelligenceVol. 219 (2015): pp. 40–66
2015
-
[7]
Decentralized and centralized plan- ning for multi-robot additive manufacturing
Poudel, Laxmi, Elagandula, Saivipulteja, Zhou, Wenchao and Sha, Zhenghui. “Decentralized and centralized plan- ning for multi-robot additive manufacturing.”Journal of Mechanical DesignVol. 145 No. 1 (2023): p. 012003
2023
-
[8]
Decentralized non-communicating multia- gentcollisionavoidancewithdeepreinforcementlearning
Chen, Yu Fan, Liu, Miao, Everett, Michael and How, Jonathan P. “Decentralized non-communicating multia- gentcollisionavoidancewithdeepreinforcementlearning.” 10 2017 IEEE international conference on robotics and au- tomation (ICRA): pp. 285–292. 2017. IEEE
2017
-
[9]
Generative machine learninginadaptivecontrolofdynamicmanufacturingpro- cesses: Areview
Lee, Suk Ki and Ko, Hyunwoong. “Generative machine learninginadaptivecontrolofdynamicmanufacturingpro- cesses: Areview.”InternationalDesignEngineeringTech- nicalConferencesandComputersandInformationinEngi- neering Conference, Vol. 89213: p. V02BT02A017. 2025. American Society of Mechanical Engineers
2025
-
[10]
Denoising diffusion probabilistic models
Ho, Jonathan, Jain, Ajay and Abbeel, Pieter. “Denoising diffusion probabilistic models.”Advances in neural infor- mation processing systemsVol. 33 (2020): pp. 6840–6851
2020
-
[11]
Planningwithdiffusionforflexiblebehav- ior synthesis
Janner, Michael, Du, Yilun, Tenenbaum, Joshua B and Levine,Sergey. “Planningwithdiffusionforflexiblebehav- ior synthesis.”arXiv preprint arXiv:2205.09991(2022)
Pith/arXiv arXiv 2022
-
[12]
Motion planning diffusion: Learning and planning of robot motions with diffusion models
Carvalho, Joao, Le, An T, Baierl, Mark, Koert, Dorothea and Peters, Jan. “Motion planning diffusion: Learning and planning of robot motions with diffusion models.”2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS): pp. 1916–1923. 2023. IEEE
2023
-
[13]
Multi- agentreinforcementlearning: Aselectiveoverviewoftheo- ries and algorithms
Zhang, Kaiqing, Yang, Zhuoran and Başar, Tamer. “Multi- agentreinforcementlearning: Aselectiveoverviewoftheo- ries and algorithms.”Handbook of reinforcement learning and control(2021): pp. 321–384
2021
-
[14]
Multi- agent actor-critic for mixed cooperative-competitive envi- ronments
Lowe, Ryan, Wu, Yi I, Tamar, Aviv, Harb, Jean, Pieter Abbeel, OpenAI and Mordatch, Igor. “Multi- agent actor-critic for mixed cooperative-competitive envi- ronments.”Advancesinneuralinformationprocessingsys- temsVol. 30 (2017)
2017
-
[15]
Proximal policy optimization al- gorithms
Schulman,John,Wolski,Filip,Dhariwal,Prafulla,Radford, Alec and Klimov, Oleg. “Proximal policy optimization al- gorithms.”arXiv preprint arXiv:1707.06347(2017)
Pith/arXiv arXiv 2017
-
[16]
The surpris- ingeffectivenessofppoincooperativemulti-agentgames
Yu, Chao, Velu, Akash, Vinitsky, Eugene, Gao, Jiaxuan, Wang, Yu, Bayen, Alexandre and Wu, Yi. “The surpris- ingeffectivenessofppoincooperativemulti-agentgames.” Advances in neural information processing systemsVol. 35 (2022): pp. 24611–24624
2022
-
[17]
Pathplanningapproachesinmulti-robotsys- tem: A review
Banik, Semonti, Banik, Sajal Chandra and Mahmud, SarkerSafat. “Pathplanningapproachesinmulti-robotsys- tem: A review.”Engineering ReportsVol. 7 No. 1 (2025): p. e13035
2025
-
[18]
Cooperative pathfinding
Silver, David. “Cooperative pathfinding.”Proceedings of theaaaiconferenceonartificialintelligenceandinteractive digital entertainment, Vol. 1. 1: pp. 117–122. 2005
2005
-
[19]
Multi- agent path finding with delay probabilities
Ma, Hang, Kumar, TK Satish and Koenig, Sven. “Multi- agent path finding with delay probabilities.”Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 31
-
[20]
Denoising diffusion implicit models
Song, Jiaming, Meng, Chenlin and Ermon, Stefano. “Denoising diffusion implicit models.”arXiv preprint arXiv:2010.02502(2020)
Pith/arXiv arXiv 2010
-
[21]
Diffusionmod- elsbeatgansonimagesynthesis
Dhariwal,PrafullaandNichol,Alexander. “Diffusionmod- elsbeatgansonimagesynthesis.”Advancesinneuralinfor- mation processing systemsVol. 34 (2021): pp. 8780–8794
2021
-
[22]
Diffusion policy: Visuomotor policy learning via action diffusion
Chi, Cheng, Xu, Zhenjia, Feng, Siyuan, Cousineau, Eric, Du, Yilun, Burchfiel, Benjamin, Tedrake, Russ and Song, Shuran. “Diffusion policy: Visuomotor policy learning via action diffusion.”The International Journal of Robotics ResearchVol. 44 No. 10-11 (2025): pp. 1684–1704
2025
-
[23]
Sutton, Richard S, Barto, Andrew G et al.Reinforcement learning: An introduction. Vol. 1. MIT press Cambridge (1998)
1998
-
[24]
A comprehensive survey of multiagent reinforcement learn- ing
Busoniu,Lucian,Babuska,RobertandDeSchutter,Bart.“A comprehensive survey of multiagent reinforcement learn- ing.”IEEE Transactions on Systems, Man, and Cybernet- ics,PartC(ApplicationsandReviews)Vol.38No.2(2008): pp. 156–172. 11
2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.