FinCom: A Financial Multi-Agent Demo with Disagree-or-Commit Deliberation
Pith reviewed 2026-06-28 16:34 UTC · model grok-4.3
The pith
Financial multi-agent committees using Disagree-or-Commit deliberation achieve higher reasoning accuracy and risk awareness than consensus methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
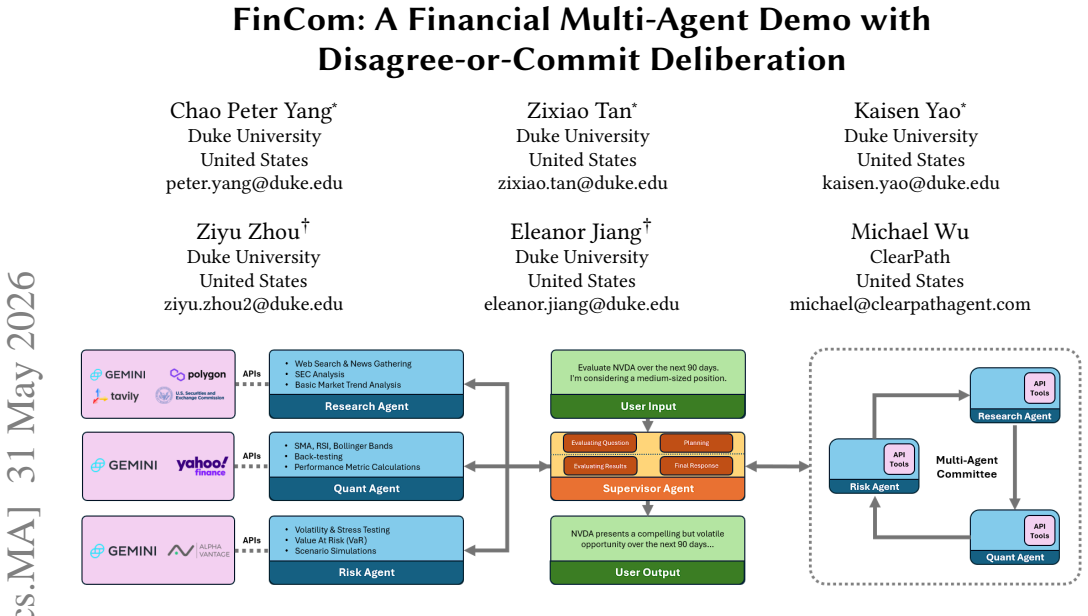
FinCom operationalizes the Disagree-or-Commit (DoC) protocol in a governed multi-agent framework with a central Supervisor and three ReAct-enabled specialist agents for research, quantitative analysis, and risk assessment. Each agent uses role-specific tools, and during deliberation agents must critique or commit to peers' reasoning before converging on a unified recommendation. This produces improved reasoning accuracy and risk awareness over consensus-seeking baselines on both in-house and external evaluation sets.
What carries the argument
The Disagree-or-Commit (DoC) protocol, which requires agents to explicitly critique or commit to peer reasoning before agreement as a governance primitive.
If this is right
- Structured dissent via DoC reduces premature agreement and sycophancy in multi-agent financial deliberations.
- The framework supports coordinated report generation and interactive decision support through agent orchestration.
- DoC provides a lightweight prompt-only approach to increase accountability, transparency, and epistemic robustness.
- Improvements hold across both the most recent financial agent benchmark and 90 internal handcrafted tasks.
Where Pith is reading between the lines
- DoC could be adapted to other high-stakes domains where evidence-based dissent matters more than alignment.
- The evaluation results invite direct comparison with human-judge protocols to check for LLM-judge artifacts.
- The supervisor-plus-specialists structure suggests a template for governed committees in non-financial analysis.
Load-bearing premise
The LLM-as-a-Judge protocol accurately and unbiasedly measures reasoning accuracy and risk awareness without introducing its own sycophancy or preference biases.
What would settle it
Human expert ratings on a fresh set of financial tasks that show no significant difference in reasoning accuracy or risk awareness between DoC and consensus-seeking agent outputs.
Figures




read the original abstract
Multi-agent systems powered by large language models (LLMs) are increasingly used for financial analysis and decision support. However, existing coordination schemes, especially those emphasizing consensus or debate, are vulnerable to sycophancy: agents conform to peer reasoning instead of evidence, leading to premature agreement and degraded outcomes. We introduce FinCom (Financial Committee), a governed multi-agent framework and interactive system that operationalizes the Disagree-or-Commit (DoC) protocol to embed structured dissent into financial AI committees. A central Supervisor orchestrates three ReAct-enabled specialist agents: Research, Quantitative, and Risk. Each agent is equipped with role-specific tools for retrieval, computation, and stress testing. During deliberation, agents must either explicitly critique or commit to their peers' reasoning before converging on a unified recommendation. This demonstration showcases how FinCom supports committee-style financial analysis through coordinated multi-agent interaction, including structured report generation and interactive decision support. Evaluated across the most recent financial agent benchmark, in addition to 90 internal handcrafted financial tasks using an LLM-as-a-Judge protocol, DoC improves reasoning accuracy and risk awareness significantly over a consensus-seeking baseline on both an in-house and external evaluation set. By reframing disagreement as a governance primitive rather than noise, FinCom offers a lightweight, prompt-only recipe for improving accountability, transparency, and epistemic robustness in agentic financial systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
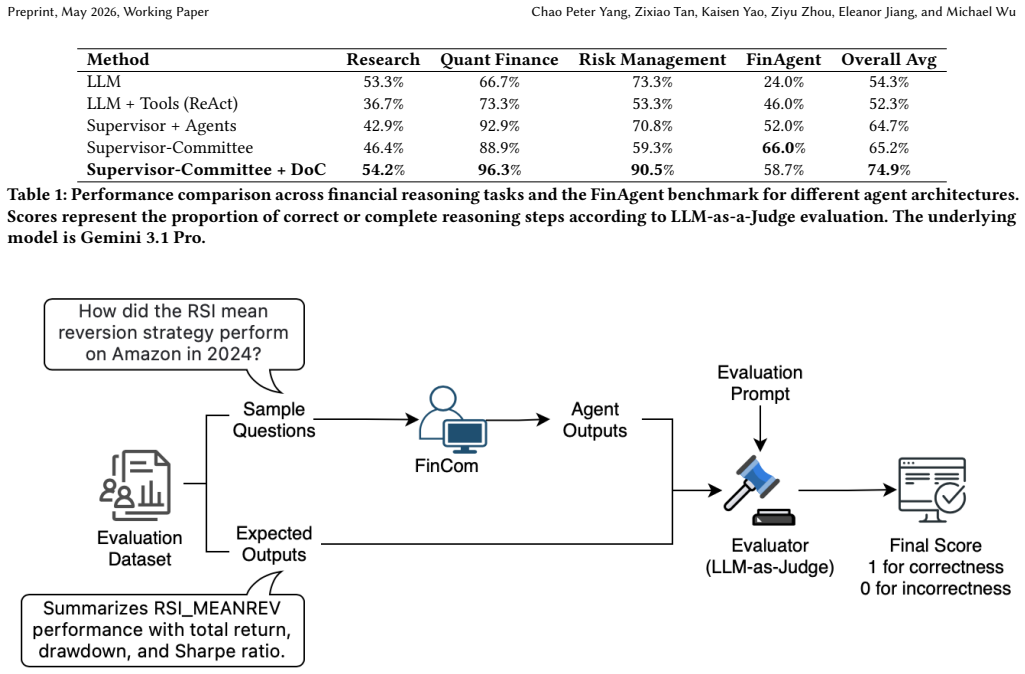
Summary. The paper introduces FinCom, a multi-agent framework for financial analysis that uses a Disagree-or-Commit (DoC) protocol orchestrated by a Supervisor agent over three ReAct specialist agents (Research, Quantitative, Risk) equipped with domain tools. The central claim is that embedding explicit critique-or-commit steps during deliberation reduces sycophancy relative to consensus-seeking baselines, yielding statistically significant gains in reasoning accuracy and risk awareness as measured by an LLM-as-a-Judge protocol on 90 internal handcrafted tasks plus an external financial-agent benchmark.
Significance. A lightweight, prompt-only mechanism that reliably improves epistemic robustness in financial multi-agent systems would be valuable for high-stakes decision support; however, the absence of any quantitative results or judge validation means the claimed gains cannot yet be assessed for practical impact.
major comments (3)
- [Abstract] Abstract: the claim that DoC 'improves reasoning accuracy and risk awareness significantly' is unsupported because the manuscript supplies no numerical scores, confidence intervals, baseline definitions, ablation results, or statistical tests for either the in-house or external evaluation sets.
- [Evaluation] Evaluation protocol (abstract and implied evaluation section): the LLM-as-a-Judge method is used to measure accuracy and risk awareness without any reported judge model, prompt template, inter-rater agreement, human calibration, or correlation with objective ground-truth labels on the handcrafted tasks, leaving open the possibility that reported gains reflect judge artifacts rather than genuine improvement.
- [§3] §3 (Deliberation and DoC protocol): the relationship between the judge model and the three specialist agents is unspecified; if they belong to the same model family or share training data, the comparison between DoC and the consensus baseline risks circularity and cannot substantiate the central claim of reduced sycophancy.
minor comments (2)
- [Abstract] The abstract refers to 'the most recent financial agent benchmark' without a citation or version identifier.
- [System Architecture] Tool descriptions for the ReAct agents are mentioned but lack concrete examples of retrieval, computation, or stress-testing calls that would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the thorough review and valuable feedback. We address each major comment below, agreeing where the manuscript requires additional detail or clarification, and outline planned revisions to strengthen the presentation of results and evaluation protocol.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that DoC 'improves reasoning accuracy and risk awareness significantly' is unsupported because the manuscript supplies no numerical scores, confidence intervals, baseline definitions, ablation results, or statistical tests for either the in-house or external evaluation sets.
Authors: We agree that the abstract states the improvement claim without embedding supporting numerical evidence. The full evaluation section reports results on the 90 handcrafted tasks and external benchmark, but these are not summarized in the abstract. We will revise the abstract to include key metrics (e.g., accuracy deltas, risk awareness scores, p-values from statistical tests, and explicit baseline definitions) to make the claim self-supporting. revision: yes
-
Referee: [Evaluation] Evaluation protocol (abstract and implied evaluation section): the LLM-as-a-Judge method is used to measure accuracy and risk awareness without any reported judge model, prompt template, inter-rater agreement, human calibration, or correlation with objective ground-truth labels on the handcrafted tasks, leaving open the possibility that reported gains reflect judge artifacts rather than genuine improvement.
Authors: We concur that the evaluation protocol requires greater transparency to rule out judge artifacts. We will expand the evaluation section with the specific judge model used, the full prompt template, inter-rater agreement statistics, any human calibration performed, and reported correlations with ground-truth labels on the handcrafted tasks. revision: yes
-
Referee: [§3] §3 (Deliberation and DoC protocol): the relationship between the judge model and the three specialist agents is unspecified; if they belong to the same model family or share training data, the comparison between DoC and the consensus baseline risks circularity and cannot substantiate the central claim of reduced sycophancy.
Authors: We will add explicit clarification in §3 and the evaluation section stating that the judge model is a distinct deployment (different model family or separate instance) from the ReAct specialist agents. This ensures the DoC versus consensus comparison is non-circular and directly supports the reduced-sycophancy claim. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces the FinCom framework and DoC protocol as an empirical system for multi-agent financial analysis, then reports performance gains on an external benchmark plus 90 internal tasks via LLM-as-a-Judge. No equations, fitted parameters, self-citations, or uniqueness theorems appear in the abstract or described content. The evaluation protocol is presented as an independent measurement step rather than a quantity defined in terms of the DoC outcome itself; the improvement claim is therefore an external observation, not a reduction by construction to the paper's own inputs. No load-bearing step matches any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLM agents equipped with role-specific tools can perform retrieval, computation, and stress testing in a coordinated financial setting.
- ad hoc to paper Structured dissent via explicit critique-or-commit steps reduces sycophancy relative to consensus-seeking.
invented entities (2)
-
Disagree-or-Commit (DoC) protocol
no independent evidence
-
Supervisor agent
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Antoine Bigeard, Langston Nashold, Rayan Krishnan, and Shirley Wu. 2025. Fi- nance Agent Benchmark: Benchmarking LLMs on Real-world Financial Research Tasks. Vals AI. https://arxiv.org/abs/2508.00828 4 FinCom: A Financial Multi-Agent Demo with Disagree-or-Commit Deliberation Preprint, May 2026, Working Paper
arXiv 2025
-
[2]
LangChain Community. 2024. LangGraph: Graph-based Orchestration for Multi- Agent LLM Systems.GitHub Repository(2024)
2024
-
[3]
Yilun Du et al. 2023. Improving Factuality and Reasoning in Language Models through Multiagent Debate.arXiv preprint arXiv:2305.14325(2023)
Pith/arXiv arXiv 2023
-
[4]
Ke Hong, Cheng Zhang, and et al. 2024. MetaGPT: Meta Programming for Multi-Agent Collaboration.arXiv preprint arXiv:2404.02582(2024)
arXiv 2024
-
[5]
Geoffrey Irving, Paul Christiano, and Dario Amodei. 2018. AI Safety via Debate. arXiv preprint arXiv:1805.00899(2018)
Pith/arXiv arXiv 2018
-
[6]
Christopher Smit et al. 2024. Should We Be Going MAD? A Look at Multi-Agent Debate Strategies for LLMs. InICML
2024
-
[7]
Yijia Xiao, Edward Sun, Di Luo, and Wei Wang. 2025. TradingAgents: Multi- Agents LLM Financial Trading Framework.arXiv preprint arXiv:2412.20138(2025)
arXiv 2025
-
[8]
Ling Xie, Han Li, and et al. 2023. PIXIU: Multi-Modal LLMs for Financial Analysis. arXiv preprint arXiv:2310.17893(2023)
arXiv 2023
-
[9]
Fei Xiong, Xiang Zhang, Aosong Feng, Siqi Sun, and Chenyu You. 2025. Quan- tAgent: Price-Driven Multi-Agent LLMs for High-Frequency Trading.arXiv preprint arXiv:2509.09995(2025)
arXiv 2025
-
[10]
Zheng Yang, Yong Zhang, et al. 2023. FinGPT: Instruction Tuning Large Language Models for Financial Tasks.arXiv preprint arXiv:2306.06031(2023)
arXiv 2023
-
[11]
Shunyu Yao, Jeffrey Zhao, Dian Yu, and et al. 2022. ReAct: Synergizing Reasoning and Acting in Language Models.arXiv preprint arXiv:2210.03629(2022)
Pith/arXiv arXiv 2022
-
[12]
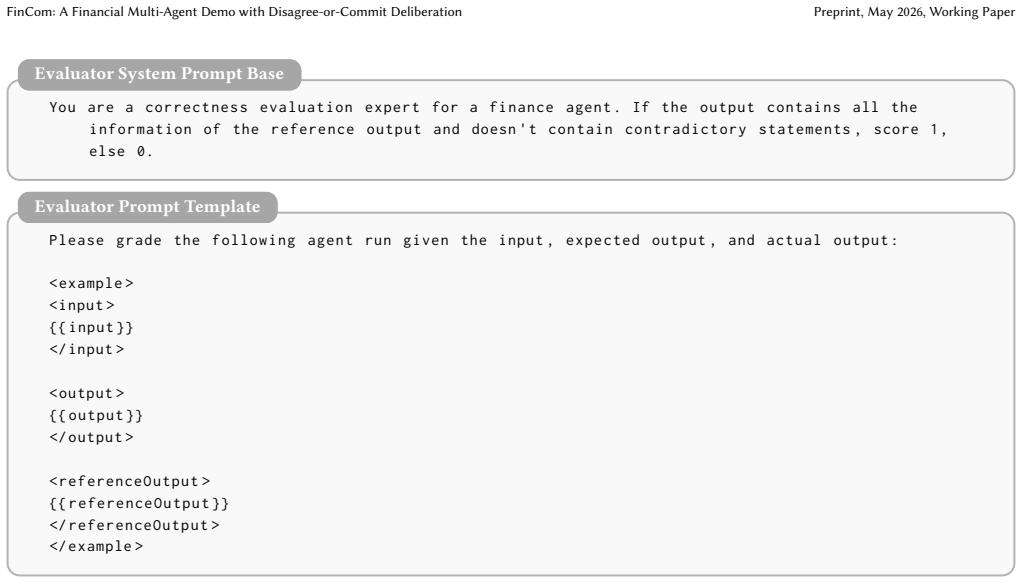
Liang Yu, Ziqi Wang, and et al. 2023. FinMem: Financial Memory-Augmented Agents for Reasoning.arXiv preprint arXiv:2311.09890(2023). A Appendix This appendix provides supplementary evaluation and implementa- tion details omitted from the main paper for space reasons. In partic- ular, we include the LLM-as-a-Judge evaluation pipeline (Figure 3), the full q...
arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.