Fewer, Better Frames: A Compute-Normalized Proof of Concept for Coherence-First World-Model Rendering with Model-Guided FSR4 Frame Generation
Pith reviewed 2026-06-30 22:21 UTC · model grok-4.3
The pith
Coherence-first world-model rendering generates 15 FPS anchors and upsamples to 30 FPS with FSR4, preserving geometry and identity longer than native 30 FPS baselines under matched compute.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Across forest, sword, desert, and snow scenes, the coherence-first branch preserves path geometry, object identity, large silhouettes, and depth layering longer, while the baseline degrades earlier into brightness drift and geometric distortion. LPIPS favors the coherence-first branch across all tested scenes.
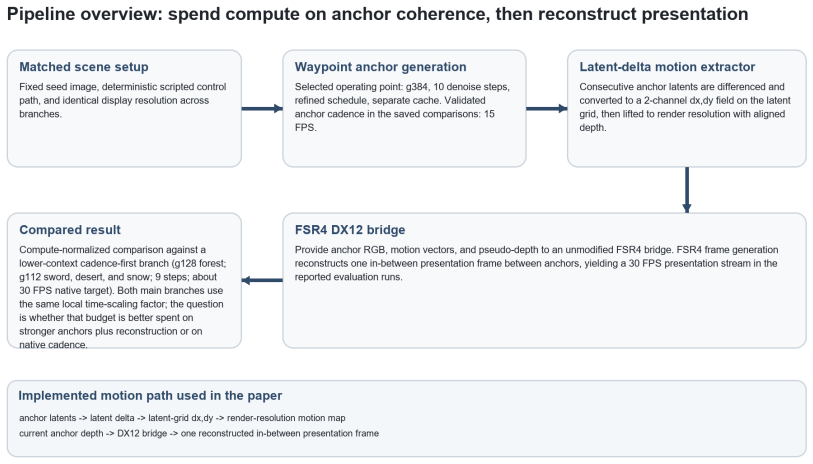
What carries the argument
The coherence-first branch that produces higher-context anchor frames at a 15 FPS cadence and reconstructs presentation to 30 FPS using latent-delta motion guidance and synthesized depth, versus the cadence-first baseline that generates approximately 30 FPS natively.
If this is right
- Under matched GPU and timescale, coherence-first allocation can extend usable scene stability beyond what native high-cadence generation achieves.
- Nominal frame rate alone does not predict long-horizon quality when inference budget is fixed.
- Local non-monotonic effects can appear: adding more context and denoising does not guarantee better results in every scene.
- Lightweight temporal metrics plus paired video inspection can surface stability differences that single-frame quality metrics miss.
Where Pith is reading between the lines
- The same coherence-versus-cadence trade-off may appear in other generative pipelines where temporal consistency is valued over raw output density.
- Extending the test duration or adding scenes with rapid camera motion could reveal where the coherence advantage saturates or reverses.
- The choice of FSR4 bridge and ONNX runtime may interact with the observed stability gap and should be isolated in follow-up runs.
Load-bearing premise
That the four tested scenes, the specific control scripts, and the LPIPS metric together provide a representative test of long-horizon stability under compute-normalized conditions.
What would settle it
A side-by-side run on the same four scenes and control scripts in which the native 30 FPS baseline maintains geometry, identity, and depth layering at least as long as the 15 FPS anchor branch, with equal or better LPIPS scores, would falsify the central claim.
Figures




read the original abstract
World models are often evaluated by native frame cadence, but higher nominal frame rate can trade away long-horizon scene stability. This article reports an independent proof of concept implemented using Overworld's Waypoint-1.5 family and WorldEngine runtime on a Windows fallback stack with ONNX Runtime + DirectML and an FSR4 DX12 bridge. The tested coherence-first branch generates higher-context anchor frames at a 15 FPS presentation-timeline cadence and reconstructs presentation to 30 FPS using latent-delta motion guidance and synthesized depth. It is compared against a lower-context cadence-first baseline that generates about 30 FPS natively under the same seed, route, control script, target presentation duration, and local time-scaling regime. Across forest, sword, desert, and snow scenes, the coherence-first branch preserves path geometry, object identity, large silhouettes, and depth layering longer, while the baseline degrades earlier into brightness drift and geometric distortion. Lightweight temporal metrics and paired videos support the visual comparison, with LPIPS favoring the coherence-first branch across all tested scenes. Here compute-normalized means approximately matched same-GPU, same-timescale operating points, not exact FLOP parity or measured realtime throughput. A separate heavier sword-scene probe suggests local non-monotonicity: more context and denoising did not automatically improve quality. These results support coherence-first allocation as a practical proof-of-concept strategy under limited inference budget, not as a finished realtime renderer.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports a proof-of-concept implementation comparing a coherence-first rendering branch (15 FPS anchor frames reconstructed to 30 FPS via latent-delta FSR4 with synthesized depth) against a native ~30 FPS baseline in Overworld's Waypoint-1.5/WorldEngine runtime. Across four scenes (forest, sword, desert, snow), it claims the coherence-first approach preserves path geometry, object identity, silhouettes, and depth layering longer while the baseline shows earlier brightness drift and distortion; LPIPS favors the coherence-first branch, under approximately compute-normalized same-GPU/same-timescale conditions.
Significance. If the stability advantage is confirmed with rigorous controls, the result would provide a practical demonstration that coherence allocation can outperform higher native frame rates for long-horizon world-model stability under fixed inference budgets. The work is positioned explicitly as a POC rather than a production renderer, and the non-monotonicity probe in the sword scene is noted as a useful caveat.
major comments (3)
- [Abstract] Abstract: LPIPS is stated to favor the coherence-first branch across all scenes, yet no numerical values, per-scene scores, error bars, statistical tests, or description of reference-frame selection and data exclusion criteria are supplied, leaving the magnitude and reliability of the metric advantage unquantified.
- [Abstract] Abstract: Compute normalization is defined only as 'approximately matched same-GPU, same-timescale operating points' with an explicit disclaimer that it is not exact FLOP parity or measured throughput; no FLOP counts, wall-clock timings, or ablation isolating the FSR4 bridge contribution from the coherence allocation are reported, so observed differences could arise from the reconstruction method rather than the 15 FPS anchor strategy.
- [Abstract] Abstract: The evaluation rests on four specific scenes and control scripts with no reported tests of generalization, seed control, or verification that the ONNX/DirectML + FSR4 DX12 runtime does not systematically favor the higher-context branch; this makes the long-horizon stability claim dependent on untested assumptions about scene and runtime representativeness.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and the recommendation for major revision. We address each of the major comments below, providing clarifications and indicating the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: LPIPS is stated to favor the coherence-first branch across all scenes, yet no numerical values, per-scene scores, error bars, statistical tests, or description of reference-frame selection and data exclusion criteria are supplied, leaving the magnitude and reliability of the metric advantage unquantified.
Authors: We acknowledge that the abstract lacks specific numerical LPIPS values and supporting details. As this is a proof-of-concept, the LPIPS evaluation was performed but not fully quantified with error bars or statistical tests in the initial report. We will revise the abstract to include the per-scene LPIPS scores where available and clarify the reference-frame selection process (using the same presentation timeline for both branches) and note the absence of formal statistical analysis as a limitation of the POC. revision: yes
-
Referee: [Abstract] Abstract: Compute normalization is defined only as 'approximately matched same-GPU, same-timescale operating points' with an explicit disclaimer that it is not exact FLOP parity or measured throughput; no FLOP counts, wall-clock timings, or ablation isolating the FSR4 bridge contribution from the coherence allocation are reported, so observed differences could arise from the reconstruction method rather than the 15 FPS anchor strategy.
Authors: The manuscript already includes the disclaimer on the approximate nature of compute normalization. We agree that additional details on FLOP counts or ablations would be ideal but are not feasible in this runtime environment without significant additional engineering effort. We will revise the abstract and methods section to more explicitly state that the observed differences are under the approximate normalization and that isolating the FSR4 contribution is left for future work. revision: partial
-
Referee: [Abstract] Abstract: The evaluation rests on four specific scenes and control scripts with no reported tests of generalization, seed control, or verification that the ONNX/DirectML + FSR4 DX12 runtime does not systematically favor the higher-context branch; this makes the long-horizon stability claim dependent on untested assumptions about scene and runtime representativeness.
Authors: We agree that the evaluation is limited to four scenes and that broader generalization tests are not reported. The paper is positioned as a proof-of-concept, and the same seed and control scripts were used for both branches. We will revise the abstract to emphasize the limited scope and scene-specific nature of the results. Regarding runtime bias, we note that both branches used the same runtime stack, but a systematic verification would require additional controlled experiments beyond the current POC scope. revision: yes
- Systematic verification that the ONNX/DirectML + FSR4 DX12 runtime does not favor the higher-context branch
Circularity Check
No circularity: empirical POC comparison with no derivations or fitted predictions
full rationale
The manuscript is a compute-normalized empirical proof-of-concept that directly compares two frame-generation strategies (15 FPS anchors + FSR4 reconstruction vs. native 30 FPS) on four scenes using LPIPS and visual inspection. No equations, parameter fits, uniqueness theorems, or self-citations are invoked to derive the reported stability advantage; the outcome is presented as an observed result under the stated conditions rather than a quantity forced by construction from the inputs. The abstract and description contain no load-bearing steps matching any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Waypoint-1.5-1B-360P
Overworld, "Waypoint-1.5-1B-360P" model card, Hugging Face, 2026
2026
-
[2]
Waypoint-1.5: Higher-Fidelity Interactive Worlds for Everyday GPUs,
A. Lapp et al., "Waypoint-1.5: Higher-Fidelity Interactive Worlds for Everyday GPUs," Hugging Face blog, Apr. 2026
2026
-
[3]
Introducing Waypoint-1: Real-time Interactive Video Diffusion from Overworld,
L. Castricato et al., "Introducing Waypoint-1: Real-time Interactive Video Diffusion from Overworld," Hugging Face blog, Jan. 2026
2026
-
[4]
Raising A Biome: The Trials and Tribulations of Waypoint At Home,
Overworld, "Raising A Biome: The Trials and Tribulations of Waypoint At Home," over.world blog, Mar. 2026. WorldScale 18
2026
- [5]
- [6]
-
[7]
Diffusion Models Are Real-Time Game Engines
D. Valevski et al., "Diffusion Models Are Real-Time Game Engines," ICLR 2025, arXiv:2408.14837
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
RTFM: A Real-Time Frame Model,
World Labs, "RTFM: A Real-Time Frame Model," research preview, Oct. 2025
2025
-
[9]
InSpatio-WorldFM: An Open-Source Real-Time Generative Frame Model
InSpatio Team et al., "InSpatio-WorldFM: An Open-Source Real-Time Generative Frame Model," arXiv:2603.11911, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
AMD FSR SDK
AMD GPUOpen, "AMD FSR SDK" and FSR Upscaling documentation, 2025-2026
2025
-
[11]
AMD FSR Frame Generation,
AMD GPUOpen, "AMD FSR Frame Generation," API and feature documentation, 2025-2026
2025
-
[12]
Windows support matrices by ROCm version
AMD ROCm Documentation, "Windows support matrices by ROCm version" and Radeon limitations pages, 2026
2026
-
[13]
Radeon RX 9070 XT
AMD, "Radeon RX 9070 XT" official product specifications page, 2025-2026
2025
-
[14]
Generative Inbetweening: Adapting Image-to-Video Models for Keyframe Interpolation,
X. Wang et al., "Generative Inbetweening: Adapting Image-to-Video Models for Keyframe Interpolation," arXiv:2408.15239, 2024
-
[15]
Motion-aware Latent Diffusion Models for Video Frame Interpolation,
Z. Huang et al., "Motion-aware Latent Diffusion Models for Video Frame Interpolation," ACM Multimedia, arXiv:2404.13534, 2024
-
[16]
VIDIM: Video Interpolation with Diffusion Models,
D. Danier et al., "VIDIM: Video Interpolation with Diffusion Models," arXiv:2404.01203, 2024
-
[17]
Arbitrary Generative Video Interpolation,
G. Zhang et al., "Arbitrary Generative Video Interpolation," ICLR 2026, OpenReview, 2026
2026
-
[18]
DLSS Frame Generation / Streamline Programming Guide,
NVIDIA, "DLSS Frame Generation / Streamline Programming Guide," developer documentation, 2025-2026
2025
-
[19]
Neural Supersampling for Real-Time Rendering,
T. Xiao et al., "Neural Supersampling for Real-Time Rendering," ACM Transactions on Graphics, 2020
2020
-
[20]
FlexiDiT: Your Diffusion Transformer Can Easily Generate High-Quality Samples with Less Compute,
S. Anagnostidis et al., "FlexiDiT: Your Diffusion Transformer Can Easily Generate High-Quality Samples with Less Compute," arXiv:2502.20126, 2025
-
[21]
Adaptive caching for faster video generation with diffusion transformers,
K. Kahatapitiya et al., "Adaptive Caching for Faster Video Generation with Diffusion Transformers," arXiv:2411.02397, 2024
-
[22]
Oasis: A Universe in a Transformer,
Decart and Etched, "Oasis: A Universe in a Transformer," project report / technical page, 2024
2024
-
[23]
World and Human Action Models towards Gameplay Ideation
Microsoft Research, "World and Human Action Models towards Gameplay Ideation" and "WHAMM! Real-time World Modelling of Interactive Environments," 2025
2025
-
[24]
INSPATIO-WORLD: A Real-Time 4D World Simulator via Spatiotemporal Autoregressive Modeling
INSPATIO Team et al., "INSPATIO-WORLD: Real-Time 4D World Simulation," arXiv:2604.07209, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[25]
Infinite-World Team et al., "Infinite-World: Long-Horizon Interactive World Generation," arXiv:2602.02393, 2026
-
[26]
Motion-Aware Generative Video Frame Interpolation,
G. Zhang et al., "Motion-Aware Generative Video Frame Interpolation," arXiv:2501.03699, 2025
- [27]
-
[28]
W. Chen et al., "Control-A-Video: Controllable Text-to-Video Generation with Diffusion Models," arXiv:2305.13840, 2023
-
[29]
XeSS-SR and XeSS-FG Developer Guides,
Intel, "XeSS-SR and XeSS-FG Developer Guides," developer documentation, 2025-2026
2025
-
[30]
F. Liu et al., "TeaCache: Timestep Embedding Tells the Cache for Video Diffusion Models," arXiv:2411.19108, 2024
-
[31]
Real-time video generation with pyramid attention broadcast
X. Zhao et al., "Pyramid Attention Broadcast for Diffusion Models," arXiv:2408.12588, 2024
-
[32]
StreamDiffusion: A Pipeline-Level Solution for Real-Time Interactive Generation,
A. Kodaira et al., "StreamDiffusion: A Pipeline-Level Solution for Real-Time Interactive Generation," arXiv:2312.12491, 2023. WorldScale 19
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.