Rashomon-Seeded Annealing for Robust Bayesian Inference in Factorial Designs
Pith reviewed 2026-06-30 16:30 UTC · model grok-4.3
The pith
Rashomon sets initialize annealed importance sampling to recover consistent full posteriors over factorial model spaces without exhaustive enumeration.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Rashomon-seeded annealing initializes annealed importance sampling by anchoring the starting density inside pre-identified Rashomon Partition Sets, then applies the annealing correction to restore unbiased inference over the entire model space, producing consistent self-normalized posterior summaries without enumerating the complete model space.
What carries the argument
Rashomon Partition Sets (RPS) as a certified seed constructor that supplies the initial density for AIS while preserving global support over the model space.
If this is right
- Model-averaged cell means become available as consistent estimators.
- Credible intervals and uncertainty summaries can be formed without visiting the full model space.
- The procedure handles multimodal posteriors that defeat standard MCMC in factorial designs.
- Any high-posterior seed set can serve as a proposal mechanism for AIS-based model averaging.
Where Pith is reading between the lines
- The same seeding idea could be tested in other combinatorial model spaces where Rashomon sets are easy to locate.
- Combining RPS seeds with different annealing schedules might further reduce variance in the self-normalized weights.
- The approach suggests a general template for turning any computationally cheap high-evidence set into a starting distribution for full posterior sampling.
Load-bearing premise
Rashomon sets can be identified as effective high-evidence seeds that let annealed importance sampling restore unbiased full posterior inference while keeping global support.
What would settle it
In a small factorial design where exhaustive enumeration is feasible, the self-normalized cell means or credible intervals obtained from the seeded AIS differ systematically from the exact values computed by enumerating every model.
Figures
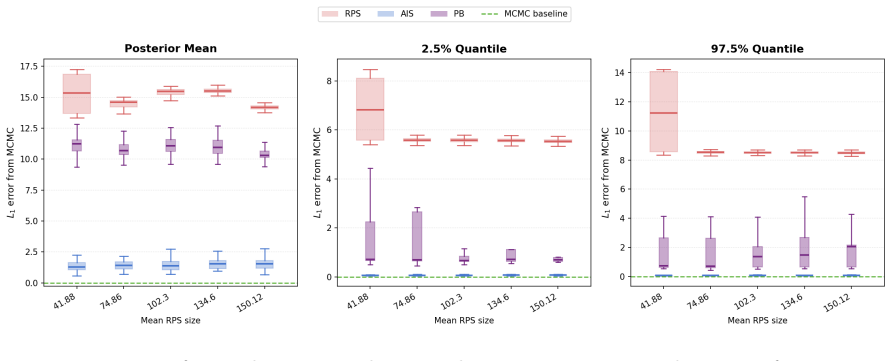
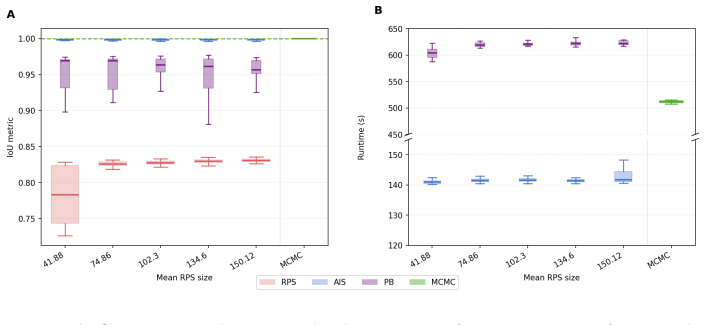
read the original abstract
Integrating over model uncertainty in factorial designs via Bayesian model averaging is hindered by the combinatorial explosion of interpretable interaction effects, often yielding a multimodal posterior, where standard Markov chain Monte Carlo algorithms encounter significant convergence issues. We propose a general computational framework that repurposes Rashomon sets, collections of high-performing models traditionally valued for prediction and interpretability, as a strategic "warm start" for estimating the full posterior. Our method, Rashomon-seeded annealing, initializes annealed importance sampling (AIS) by anchoring the starting density within these pre-identified, high-evidence regions while preserving global support over the entire model space. Rather than restricting inference to the Rashomon set and understating uncertainty, the AIS correction restores full posterior inference, turning the Rashomon certificate from an inferential truncation into a proposal mechanism. We demonstrate this approach using Rashomon Partition Sets (RPS) as a rigorous, certified seed constructor for factorial designs. The resulting algorithm yields consistent self-normalized posterior summaries, such as model-averaged cell means, credible intervals, and uncertainty summaries without exhaustive enumeration of the complete model space. This bridges the gap between high-evidence model discovery and rigorous Bayesian inference, and outlines a general strategy in which any high-posterior seed set can provide computational leverage for AIS-based model averaging.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Rashomon-seeded annealing, a framework that repurposes Rashomon sets (via Rashomon Partition Sets) as high-evidence seeds to initialize annealed importance sampling for Bayesian model averaging over the combinatorially large space of interaction models in factorial designs. It claims that anchoring the starting density in these regions while preserving global support, followed by the standard AIS correction, produces consistent self-normalized posterior summaries (model-averaged cell means, credible intervals) without exhaustive enumeration of the model space.
Significance. If the consistency claim holds and the method is shown to be correctly implemented, the approach would provide a computationally tractable route to full posterior inference in settings where standard MCMC fails due to multimodality, while leveraging existing Rashomon-set machinery for model discovery.
major comments (3)
- [Abstract] Abstract: the assertion that 'the AIS correction restores full posterior inference' and 'yields consistent self-normalized posterior summaries' is made without any derivation, theorem statement, or statement of the required conditions on the annealing schedule and proposal construction.
- [Abstract] Abstract: no simulation study, real-data example, convergence diagnostic, or comparison against standard AIS or MCMC is supplied, leaving the claim that the method 'avoids exhaustive enumeration' and resolves convergence issues unsupported by evidence.
- [Abstract] Abstract: the description of how the Rashomon set supplies a starting density 'while preserving global support over the entire model space' is stated at a conceptual level only; the explicit form of the initial density, the annealing path, and the weight normalization that would guarantee the claimed consistency are absent.
minor comments (1)
- [Abstract] Abstract: the parenthetical '(RPS)' is introduced without a prior definition or citation to the construction of Rashomon Partition Sets.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We address each point below, clarifying the theoretical basis drawn from standard AIS results and outlining planned revisions to strengthen the presentation of both theory and evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that 'the AIS correction restores full posterior inference' and 'yields consistent self-normalized posterior summaries' is made without any derivation, theorem statement, or statement of the required conditions on the annealing schedule and proposal construction.
Authors: The consistency claim rests on the fact that the Rashomon-seeded initial density is constructed to have full support over the model space (via a mixture with a uniform component), after which the standard AIS estimator is consistent under the usual conditions on the annealing schedule (geometric path with sufficient intermediates to bound variance) and the proposal. We will add an explicit statement of these conditions together with a reference to the relevant AIS consistency theorems (e.g., Neal 2001) in both the abstract and the main theoretical section. revision: yes
-
Referee: [Abstract] Abstract: no simulation study, real-data example, convergence diagnostic, or comparison against standard AIS or MCMC is supplied, leaving the claim that the method 'avoids exhaustive enumeration' and resolves convergence issues unsupported by evidence.
Authors: The manuscript contains a demonstration of the RPS-based seed construction on factorial designs that illustrates avoidance of exhaustive enumeration. To address the concern directly, we will expand this demonstration into a fuller simulation study that includes comparisons against standard AIS and MCMC, along with convergence diagnostics such as effective sample size and autocorrelation, in the revised version. revision: yes
-
Referee: [Abstract] Abstract: the description of how the Rashomon set supplies a starting density 'while preserving global support over the entire model space' is stated at a conceptual level only; the explicit form of the initial density, the annealing path, and the weight normalization that would guarantee the claimed consistency are absent.
Authors: The explicit mixture form of the initial density (RPS models plus uniform component), the geometric annealing path, and the standard self-normalized AIS weight computation are defined in the methods section. We will add a concise summary of these explicit constructions to the abstract and ensure all formulas appear with clear notation in the main text. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper proposes a computational method that uses Rashomon sets (or RPS) as seeds to initialize annealed importance sampling while preserving global support over the model space, then applies standard AIS corrections to obtain consistent self-normalized posterior summaries. No equations, derivations, or load-bearing steps are visible in the provided text that reduce by construction to fitted inputs, self-definitions, or self-citation chains. The central claim follows from the known consistency properties of self-normalized AIS under the stated conditions and does not rely on any internal reduction to its own outputs. This is the expected honest finding for a methods paper whose contribution is algorithmic rather than a closed mathematical derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
URLhttps://doi.org/10.1093/molbev/mss084
doi: 10.1093/molbev/mss084. URLhttps://doi.org/10.1093/molbev/mss084. Abhijit Banerjee, Arun G. Chandrasekhar, Suresh Dalpath, Esther Duflo, John Floretta, Matthew O. Jackson, Harini Kannan, Francine Loza, Anirudh Sankar, Anna Schrimpf, and Maheshwor Shrestha. Selecting the most effective nudge: Evidence from a large-scale experi- ment on immunization.Eco...
-
[2]
URL https://doi.org/10.3982/ECTA19739
doi: 10.3982/ECTA19739. URL https://doi.org/10.3982/ECTA19739. Leo Breiman. Statistical Modeling: The Two Cultures (with comments and a rejoinder by the author).Statistical Science, 16(3):199–231,
-
[3]
URLhttps: //doi.org/10.1214/ss/1009213726
doi: 10.1214/ss/1009213726. URLhttps: //doi.org/10.1214/ss/1009213726. Ben Calderhead and Mark Girolami. Estimating Bayes factors via thermodynamic integration and population MCMC.Computational Statistics & Data Analysis, 53(12):4028–4045,
-
[4]
doi: 10.1016/j.csda.2009.07.025
ISSN 0167-9473. doi: 10.1016/j.csda.2009.07.025. URLhttps://doi.org/10.1016/j.csda.2009.07
-
[5]
URLhttps://doi.org/10.3390/e21111109
doi: 10.3390/e21111109. URLhttps://doi.org/10.3390/e21111109. Siddhartha Chib and Xiaming Zeng. Which factors are risk factors in asset pricing? A model scan framework.Journal of Business & Economic Statistics, 38(4):771–783,
-
[6]
Current Principles of Motor Control , with Special Reference to Vertebrate Locomotion
doi: 10.1080/ 07350015.2019.1573684. URLhttps://doi.org/10.1080/07350015.2019.1573684. Jiayun Dong and Cynthia Rudin. Exploring the cloud of variable importance for the set of all good models.Nature Machine Intelligence, 2(12):810–824,
-
[7]
doi: 10.1038/ s42256-020-00264-0
ISSN 2522-5839. doi: 10.1038/ s42256-020-00264-0. URLhttps://doi.org/10.1038/s42256-020-00264-0. Yang Fan, Rongqi Wu, Ming-Hui Chen, Lynn Kuo, and Paul O. Lewis. Choosing among partition models in Bayesian phylogenetics.Molecular Biology and Evolution, 28(1):523–532,
-
[8]
URLhttps://doi.org/10.1093/molbev/msq224
doi: 10.1093/molbev/msq224. URLhttps://doi.org/10.1093/molbev/msq224. Nial Friel and Anthony N. Pettitt. Marginal likelihood estimation via power posteriors.Journal of the Royal Statistical Society: Series B (Statistical Methodology), 70(3):589–607,
-
[9]
Journal of the Royal Statistical Society Series B , author=
1111/j.1467-9868.2007.00650.x. URLhttps://doi.org/10.1111/j.1467-9868.2007.00650.x. Andrew Gelman and Xiao-Li Meng. Simulating normalizing constants: from importance sampling to bridge sampling to path sampling.Statistical Science, 13(2):163–185,
-
[10]
URLhttps://doi.org/10.1214/ss/1028905934
doi: 10.1214/ss/ 1028905934. URLhttps://doi.org/10.1214/ss/1028905934. Edward I. George and Robert E. McCulloch. Variable selection via Gibbs sampling.Journal of the American Statistical Association, 88(423):881–889,
-
[11]
URLhttps://doi.org/10.1080/01621459.1993.10476353
doi: 10.1080/01621459.1993.10476353. URLhttps://doi.org/10.1080/01621459.1993.10476353. Tilmann Gneiting and Adrian E Raftery. Strictly proper scoring rules, prediction, and estima- tion.Journal of the American Statistical Association, 102(477):359–378,
-
[12]
doi: 10.1198/ 016214506000001437. URLhttps://doi.org/10.1198/016214506000001437. Yongtao Guan and Matthew Stephens. Bayesian variable selection regression for genome-wide association studies and other large-scale problems.The Annals of Applied Statistics, 5(3):1780– 1815,
-
[13]
URLhttps://doi.org/10.1214/11-AOAS455
doi: 10.1214/11-AOAS455. URLhttps://doi.org/10.1214/11-AOAS455. 13 Benjamin Guedj. A primer on PAC-Bayesian learning,
-
[14]
A primer on pac-bayesian learning.ArXiv, abs/1901.05353,
URLhttps://doi.org/10.48550/ arXiv.1901.05353. Chris Hans, Adrian Dobra, and Mike West. Shotgun stochastic search for Regression Variable Selection.Journal of the American Statistical Association, 102(478):507–516,
-
[15]
URLhttps://doi.org/10.1198/016214507000000121
doi: 10.1198/ 016214507000000121. URLhttps://doi.org/10.1198/016214507000000121. Jennifer A. Hoeting, David Madigan, Adrian E. Raftery, and Chris T. Volinsky. Bayesian model averaging: a tutorial (with comments by M. Clyde, David Draperand E. I. George, and a rejoinder by the authors).Statistical Science, 14(4):382–417,
-
[16]
URL https://doi.org/10.1214/ss/1009212519
doi: 10.1214/ss/1009212519. URL https://doi.org/10.1214/ss/1009212519. Aliaksandr Hubin and Geir Storvik. Mode-jumping MCMC for Bayesian variable selection in generalized linear models.Computational Statistics & Data Analysis, 127:281–297,
-
[17]
URLhttps://doi.org/10.1016/j.csda.2018.05.020
doi: 10.1016/j.csda.2018.05.020. URLhttps://doi.org/10.1016/j.csda.2018.05.020. Dean Karlan and John A List. Does price matter in charitable giving? evidence from a large-scale natural field experiment.American Economic Review, 97(5):1774–1793,
-
[18]
URLhttps://doi.org/10.7910/DVN/27853
doi: 10.7910/ DVN/27853. URLhttps://doi.org/10.7910/DVN/27853. Nicolas Lartillot and Hervé Philippe. Computing Bayes factors using thermodynamic integration. Systematic Biology, 55(2):195–207,
-
[19]
doi: 10.1080/10635150500433722. URLhttps://doi. org/10.1080/10635150500433722. David Madigan and Adrian E. Raftery. Model selection and accounting for model uncertainty in graphical models using occam’s window.Journal of the American Statistical Association, 89 (428):1535–1546,
-
[20]
Robins, Andrea Rotnitzky, and Lue Ping Zhao
doi: 10.1080/01621459.1994.10476894. URLhttps://doi.org/10.1080/ 01621459.1994.10476894. David Madigan, Adrian E Raftery, C Volinsky, and Jennifer Hoeting. Bayesian model averaging. In Proceedings of the AAAI Workshop on Integrating Multiple Learned Models, Portland, OR, pages 77–83,
-
[21]
URLhttps://doi.org/10.1145/307400.307435
doi: 10.1145/307400.307435. URLhttps://doi.org/10.1145/307400.307435. Radford M. Neal. Annealed importance sampling.Statistics and Computing, 11:125–139,
-
[22]
URLhttps://doi.org/10.1023/A:1008923215028
doi: 10.1023/A:1008923215028. URLhttps://doi.org/10.1023/A:1008923215028. Adrian E. Raftery, David Madigan, and Jennifer A. Hoeting. Bayesian model averaging for linear regression models.Journal of the American Statistical Association, 92(437):179–191,
-
[23]
URLhttps://doi.org/10.1080/01621459.1997.10473615
doi: 10.1080/01621459.1997.10473615. URLhttps://doi.org/10.1080/01621459.1997.10473615. Cynthia Rudin. Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead.Nature Machine Intelligence, 1(5):206–215,
-
[24]
doi: 10.1038/ s42256-019-0048-x. URLhttps://doi.org/10.1038/s42256-019-0048-x. 14 Lesia Semenova, Cynthia Rudin, and Ronald Parr. On the existence of simpler machine learning models. InProceedings of the 2022 ACM Conference on Fairness, Accountability, and Trans- parency, FAccT ’22, page 1827–1858, New York, NY, USA,
-
[25]
Association for Computing Machinery. doi: 10.1145/3531146.3533232. URLhttps://doi.org/10.1145/3531146.3533232. Surya T. Tokdar and Robert E. Kass. Importance sampling: a review.WIREs Computational Statistics, 2(1):54–60,
-
[26]
URLhttps://doi.org/10.1002/wics.56
doi: 10.1002/wics.56. URLhttps://doi.org/10.1002/wics.56. Aparajithan Venkateswaran, Anirudh Sankar, Arun G. Chandrasekhar, and Tyler H. McCormick. Robustly estimating heterogeneity in factorial data using rashomon partitions,
-
[27]
URLhttps: //doi.org/10.48550/arXiv.2404.02141. Chris T. Volinsky, David Madigan, Adrian E. Raftery, and Richard A. Kronmal. Bayesian model averaging in proportional hazard models: Assessing the risk of a stroke.Applied Statistics, 46 (4):433–448,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2404.02141
-
[28]
URLhttps://doi.org/10.1111/1467-9876
doi: 10.1111/1467-9876.00082. URLhttps://doi.org/10.1111/1467-9876. 00082. Rui Xin, Chudi Zhong, Zhi Chen, Takuya Takagi, Margo Seltzer, and Cynthia Rudin. Exploring the whole rashomon set of sparse decision trees. InAdvances in Neu- ral Information Processing Systems, volume 35, pages 14071–14084. Curran Asso- ciates, Inc.,
-
[29]
Yun Yang, Martin J
URLhttps://proceedings.neurips.cc/paper_files/paper/2022/file/ 5afaa8b4dd18eb1eed055d2d821b58ae-Paper-Conference.pdf. Yun Yang, Martin J. Wainwright, and Michael I. Jordan. On the computational complexity of MCMC-based Bayesian variable selection.The Annals of Statistics, 44(5):2025–2053,
2022
-
[30]
doi: 10.1214/15-AOS1417. URLhttps://doi.org/10.1214/15-AOS1417. Arnold Zellner. On assessing prior distributions and Bayesian regression analysis withg-prior distributions. In Prem K. Goel and Arnold Zellner, editors,Bayesian Inference and Decision Techniques: Essays in Honor of Bruno de Finetti, pages 233–243. Elsevier Science Publishers,
-
[31]
URL https://doi.org/10.1007/BF02888369
doi: 10.1007/BF02888369. URL https://doi.org/10.1007/BF02888369. Yan Zhou, Adam M. Johansen, and John A.D. Aston. Toward automatic model comparison: An adaptive sequential Monte Carlo approach.Journal of Computational and Graphical Statistics, 25(3):701–726,
-
[32]
URLhttps://doi.org/10.1080/ 10618600.2015.1060885
doi: 10.1080/10618600.2015.1060885. URLhttps://doi.org/10.1080/ 10618600.2015.1060885. 15 AppendixA1.Proof of the theoretical results We prove the almost-sure consistency of the self-normalized AIS estimator stated in Theorem 1 and its corollaries. The notation is exactly that of Section 2:Qis the joint distribution of a single model–weight pair(M, w)prod...
-
[33]
incremental change
guarantees that there exists a constant C= CT C0 >0, whereC T = P M∈M ˜p(M| D)andC 0 = P M∈M q0(M;S)are the normalizing constants of the unnormalized posterior˜p(· | D)and the unnormalized initial densityq0(·;S), respectively. For any bounded measurable functionζ:M →R p, EQ w ζ(M) =CE M|D ζ(M) .(A1) Settingζas the unit function yieldsE Q[w] =C. A1.2.Proof...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.