MOSAIC: A Workload-Driven Simulation and Design-Space Exploration Framework for Heterogeneous NPUs
Pith reviewed 2026-06-28 03:17 UTC · model grok-4.3
The pith
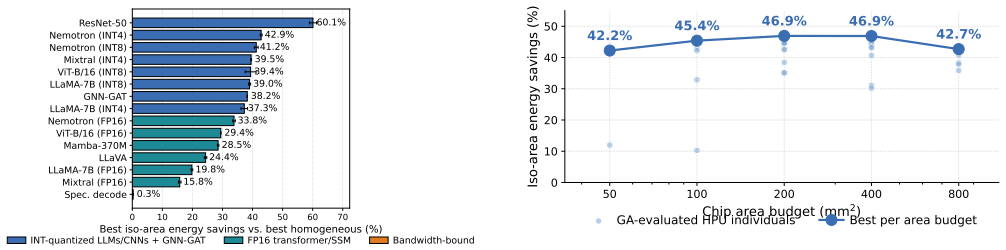
A simulation framework for heterogeneous NPUs discovers mixed-tile designs that deliver 46.91 percent mean iso-area energy savings over the best homogeneous baselines across 20 workloads.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
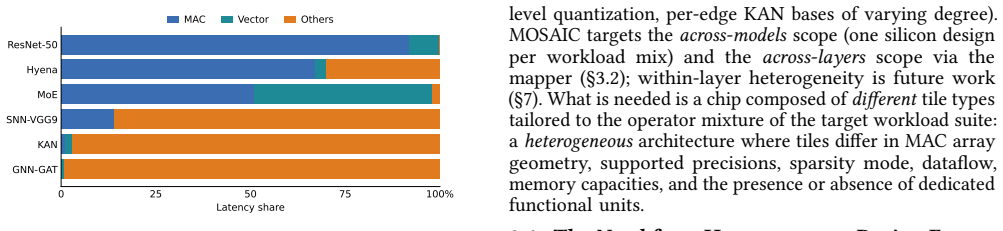
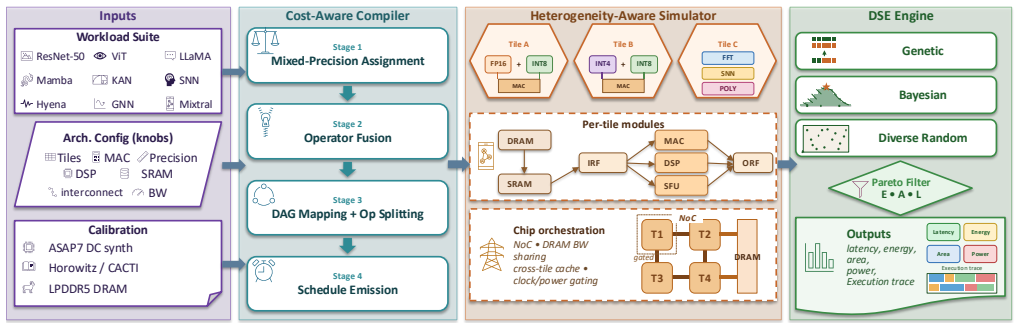
MOSAIC models non-MAC tiles (FFT, spiking-integrate, polynomial) with their own energy, area, and timing models, maps operators across mixed tiles using a heterogeneity-aware compiler, and applies a multi-seed pipeline of stratified sweeps plus genetic-algorithm refinement to return Pareto-optimal designs. Calibrated to a 7 nm node and cross-validated against NVDLA, the search finds that the best general-purpose HPU achieves +46.91% mean iso-area energy savings over the best iso-area homogeneous baseline.
What carries the argument
The MOSAIC analytical simulator and DSE framework, which jointly varies tile-type composition (Big, Little, Special-Function), dataflow, sparsity mode, MAC engine type, and special-function units while modeling each tile class separately.
If this is right
- A heterogeneous design mixing large, small, and non-MAC tiles outperforms any single-tile-type NPU at fixed area on the evaluated workloads.
- Dedicated special-function units for FFT, spiking-integrate, and polynomial operators improve efficiency for non-MAC-dominated models.
- Fine-grained heterogeneity across many dimensions (beyond just precision and array size) yields better designs than prior coarse-knob approaches.
- The multi-seed search pipeline (stratified sweep followed by genetic refinement) produces Pareto fronts that include general-purpose HPUs competitive with workload-specific ones.
Where Pith is reading between the lines
- If the 20-workload suite is representative, similar DSE tools could become routine for sizing future NPUs rather than relying on hand-tuned homogeneous baselines.
- The separation between per-tile cost models and the heterogeneity-aware compiler suggests the framework could be reused for other heterogeneous accelerators outside neural networks.
- Accurate modeling of non-MAC primitives might allow direct quantitative trade-off studies between different emerging operator sets before silicon is built.
Load-bearing premise
The analytical energy, area, and timing models for non-MAC tiles accurately predict real 7 nm hardware behavior.
What would settle it
Fabricate the recommended ~200 mm² Big+Little+Special-Function HPU in 7 nm silicon, execute the 20-workload suite on it, and compare measured energy against the best iso-area homogeneous design to check whether the 46.91% savings appear.
Figures




read the original abstract
AI model architectures are diversifying rapidly. Although dense matrix multiplication underlies today's CNNs and transformers, emerging architectures (state-space models, long convolutions via the fast Fourier transform (FFT), Kolmogorov-Arnold networks, and spiking networks) are not multiply-accumulate (MAC) dominated; they spend much of their computation on vector and non-MAC primitives that homogeneous, MAC-centric neural processing units (NPUs) serve poorly. This has motivated heterogeneous NPUs (HPUs) built from non-identical tiles. Prior heterogeneous designs vary only one or two coarse knobs (typically MAC precision or array size) and are evaluated on narrow workloads; no existing framework supports fine-grained HPU design, where tiles differ across many architectural dimensions at once. We present MOSAIC, an analytical simulator and design-space-exploration (DSE) framework for HPU microarchitecture design. MOSAIC searches the joint space of tile-level heterogeneity: beyond array size and precision, it varies tile-type composition (large Big, small Little, and non-MAC Special-Function tiles), dataflow, sparsity mode, MAC engine type, and special-function units for non-MAC operators (FFT, spiking-integrate, polynomial). Unlike prior simulators that model a single homogeneous tile type, MOSAIC models non-MAC tiles with their own energy, area, and timing models and maps operators across a mix of tiles with a heterogeneity-aware compiler. A multi-seed pipeline pairing a stratified sweep with genetic-algorithm refinement returns Pareto-optimal designs, with cost models calibrated to a 7 nm node and cross-validated against NVIDIA's Deep Learning Accelerator (NVDLA). Across a 20-workload suite, the best general-purpose HPU found by MOSAIC (~200 mm^2 Big+Little+Special-Function) achieves +46.91% mean iso-area energy savings over the best iso-area homogeneous baseline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents MOSAIC, an analytical simulator and design-space-exploration framework for heterogeneous NPUs (HPUs). It supports fine-grained tile heterogeneity (Big/Little/Special-Function tiles for non-MAC operators such as FFT, spiking-integrate, and polynomial), dataflow, sparsity mode, and MAC engine variants. Cost models are calibrated to a 7 nm node and cross-validated against NVDLA. Across a 20-workload suite, the best general-purpose ~200 mm² HPU found by the framework is claimed to deliver +46.91% mean iso-area energy savings relative to the best iso-area homogeneous baseline.
Significance. If the analytical models for non-MAC tiles are shown to be accurate, MOSAIC would be a useful contribution by enabling systematic exploration of heterogeneous designs for emerging non-MAC-dominated AI workloads. The multi-seed pipeline combining stratified sweep with genetic-algorithm refinement is a concrete strength for identifying Pareto fronts in a high-dimensional space.
major comments (2)
- [Abstract] Abstract: The +46.91% mean iso-area energy savings claim is produced entirely by MOSAIC's analytical cost models. The abstract states that non-MAC tiles receive dedicated energy/area/timing models, yet the only calibration referenced is to a 7 nm node and cross-validation against NVDLA (a MAC-only design). No equation set, synthesis results, RTL validation, or measured data for the FFT, spiking-integrate, or polynomial units is provided.
- [Abstract] Abstract: The central quantitative result rests on outputs of analytical models whose accuracy for non-MAC operators is not independently grounded beyond the stated NVDLA cross-validation for MAC paths. No error bars, sensitivity analysis, or post-hoc exclusion criteria are reported for the 46.91% figure.
minor comments (1)
- [Abstract] The composition and representativeness of the 20-workload suite should be described in more detail to allow assessment of coverage for state-space models, long convolutions, and spiking networks.
Simulated Author's Rebuttal
We thank the referee for the detailed comments on model validation. We address each point below and indicate the revisions we will make to strengthen the grounding of the non-MAC models and the reported savings figure.
read point-by-point responses
-
Referee: [Abstract] Abstract: The +46.91% mean iso-area energy savings claim is produced entirely by MOSAIC's analytical cost models. The abstract states that non-MAC tiles receive dedicated energy/area/timing models, yet the only calibration referenced is to a 7 nm node and cross-validation against NVDLA (a MAC-only design). No equation set, synthesis results, RTL validation, or measured data for the FFT, spiking-integrate, or polynomial units is provided.
Authors: The manuscript (Section 4.2) presents the non-MAC tile models as analytical expressions for energy, area, and latency, parameterized from the same 7 nm technology constants used for the MAC paths and drawn from published characterizations of comparable functional units. We agree that the abstract does not reference these equations or any synthesis/RTL details for the special-function units, and that NVDLA cross-validation covers only the MAC datapath. We will revise the abstract to cite the model section and add a dedicated paragraph in the evaluation discussing the derivation assumptions for FFT, spiking-integrate, and polynomial units. We cannot supply new measured silicon data, as none was collected for these units. revision: yes
-
Referee: [Abstract] Abstract: The central quantitative result rests on outputs of analytical models whose accuracy for non-MAC operators is not independently grounded beyond the stated NVDLA cross-validation for MAC paths. No error bars, sensitivity analysis, or post-hoc exclusion criteria are reported for the 46.91% figure.
Authors: We acknowledge that the 46.91% figure is reported without accompanying error bars or sensitivity analysis on the non-MAC parameters. The DSE pipeline already runs multiple genetic-algorithm seeds, but variance across those seeds was not quantified for the headline result. In the revision we will report the range across seeds as error bars on the mean savings and add a sensitivity study that perturbs the non-MAC cost coefficients by ±20% while re-running the DSE on the same workload suite. revision: yes
Circularity Check
No circularity detected in derivation chain
full rationale
MOSAIC's headline result (+46.91% iso-area energy savings) is produced by running its analytical cost models and heterogeneity-aware compiler over the 20-workload suite inside a DSE loop. The models are stated to be calibrated to an external 7 nm node and cross-validated against NVDLA; no equation set defines the savings in terms of itself, no parameter is fitted to a subset and then re-predicted, and no load-bearing premise rests on a self-citation chain. The derivation therefore remains independent of its own outputs.
Axiom & Free-Parameter Ledger
free parameters (2)
- tile-level design knobs
- 7 nm cost-model calibration constants
axioms (2)
- domain assumption Analytical models for energy, area, and timing of non-MAC tiles are sufficiently accurate for design ranking.
- domain assumption The 20-workload suite is representative of future diverse AI architectures.
Reference graph
Works this paper leans on
-
[1]
AMD XDNA architecture,
Advanced Micro Devices, Inc., “AMD XDNA architecture, ” 2025
2025
-
[2]
RT-2: Vision-language-action models transfer web knowledge to robotic control,
A. Brohanet al., “RT-2: Vision-language-action models transfer web knowledge to robotic control, ” inCoRL, 2023
2023
-
[3]
ASAP7: A 7-nm FinFET predictive process design kit,
L. T. Clarket al., “ASAP7: A 7-nm FinFET predictive process design kit, ”Microelectronics J., 2016
2016
-
[4]
A. Daset al., “GraNNite: Enabling high-performance execution of graph neural networks on resource-constrained neural processing units, ”arXiv preprint arXiv:2502.06921, 2025
arXiv 2025
-
[5]
Towards efficient acceleration of Hyena and Kolmogorov–Arnold networks on NPUs,
A. Daset al., “Towards efficient acceleration of Hyena and Kolmogorov–Arnold networks on NPUs, ” inICEdge, 2025
2025
-
[6]
XAMBA: Enabling efficient state space models on resource-constrained neural processing units,
A. Daset al., “XAMBA: Enabling efficient state space models on resource-constrained neural processing units, ”arXiv preprint arXiv:2502.06924, 2025
arXiv 2025
-
[7]
Hymba: A hybrid-head architecture for small language models,
X. Donget al., “Hymba: A hybrid-head architecture for small language models, ”arXiv preprint arXiv:2411.13676, 2024
arXiv 2024
-
[8]
An image is worth 16x16 words: Transformers for image recognition at scale,
A. Dosovitskiyet al., “An image is worth 16x16 words: Transformers for image recognition at scale, ” inICLR, 2021
2021
-
[9]
GPTQ: Accurate post-training quantization for generative pre-trained transformers,
E. Frantaret al., “GPTQ: Accurate post-training quantization for generative pre-trained transformers, ” inICLR, 2023
2023
-
[10]
big.LITTLE processing with ARM Cortex-A15 and Cortex-A7,
P. Greenhalgh, “big.LITTLE processing with ARM Cortex-A15 and Cortex-A7, ” 2011
2011
-
[11]
Efficiently modeling long sequences with structured state spaces,
A. Guet al., “Efficiently modeling long sequences with structured state spaces, ”arXiv preprint arXiv:2111.00396, 2021
Pith/arXiv arXiv 2021
-
[12]
Mamba: Linear-time sequence modeling with selective state spaces,
A. Guet al., “Mamba: Linear-time sequence modeling with selective state spaces, ”arXiv preprint arXiv:2312.00752, 2023
Pith/arXiv arXiv 2023
-
[13]
Deep residual learning for image recognition,
K. Heet al., “Deep residual learning for image recognition, ” inCVPR, 2016
2016
-
[14]
Computing’s energy problem (and what we can do about it),
M. Horowitz, “Computing’s energy problem (and what we can do about it), ” inISSCC, 2014
2014
-
[15]
OpenVINO toolkit,
Intel Corporation, “OpenVINO toolkit, ” 2020
2020
-
[16]
Intel Core Ultra series mobile processors product brief,
Intel Corporation, “Intel Core Ultra series mobile processors product brief, ” 2024
2024
-
[17]
A. Q. Jianget al., “Mixtral of experts, ”arXiv preprint arXiv:2401.04088, 2024
Pith/arXiv arXiv 2024
-
[18]
MAESTRO: A data-centric approach to understand reuse, performance, and hardware cost of DNN mappings,
H. Kwonet al., “MAESTRO: A data-centric approach to understand reuse, performance, and hardware cost of DNN mappings, ”IEEE Micro, 2020
2020
-
[19]
Heterogeneous dataflow accelerators for multi-DNN workloads,
H. Kwonet al., “Heterogeneous dataflow accelerators for multi-DNN workloads, ” inHPCA, 2021
2021
-
[20]
Fast inference from transformers via speculative decoding,
Y. Leviathanet al., “Fast inference from transformers via speculative decoding, ” inICML, 2023
2023
-
[21]
AWQ: Activation-aware weight quantization for LLM compression and acceleration,
J. Linet al., “AWQ: Activation-aware weight quantization for LLM compression and acceleration, ” inMLSys, 2024
2024
-
[22]
Vision transformers are parameter-efficient audio- visual learners,
Y.-B. Linet al., “Vision transformers are parameter-efficient audio- visual learners, ” inCVPR, 2023
2023
-
[23]
Visual instruction tuning,
H. Liuet al., “Visual instruction tuning, ” inNeurIPS, 2023
2023
-
[24]
Hyena hierarchy: Towards larger convolutional language models,
M. Poliet al., “Hyena hierarchy: Towards larger convolutional language models, ”arXiv preprint arXiv:2302.10866, 2023
arXiv 2023
-
[25]
KAN: Kolmogorov–Arnold networks,
Z. Liuet al., “KAN: Kolmogorov–Arnold networks, ”arXiv preprint arXiv:2404.19756, 2024
Pith/arXiv arXiv 2024
-
[26]
Heterogeneous multi-core array-based DNN accelerator,
M. A. Malekiet al., “Heterogeneous multi-core array-based DNN accelerator, ”arXiv preprint arXiv:2206.12605, 2022
arXiv 2022
-
[27]
MediaTek edge AI: The MediaTek NPU (APU),
MediaTek Inc., “MediaTek edge AI: The MediaTek NPU (APU), ” 2025
2025
-
[28]
CACTI 6.0: A tool to model large caches,
N. Muralimanoharet al., “CACTI 6.0: A tool to model large caches, ” HP Labs Tech. Rep., Tech. Rep., 2009
2009
-
[29]
Surrogate gradient learning in spiking neural networks,
E. O. Neftciet al., “Surrogate gradient learning in spiking neural networks, ”IEEE Signal Process. Mag., 2019
2019
-
[30]
A 23.9 TOPS/W @ 0.8 V, 130 TOPS AI accelerator with 16x performance-accelerable pruning in 14 nm heterogeneous embedded MPU for real-time robot applications,
K. Noseet al., “A 23.9 TOPS/W @ 0.8 V, 130 TOPS AI accelerator with 16x performance-accelerable pruning in 14 nm heterogeneous embedded MPU for real-time robot applications, ” inISSCC, 2024
2024
-
[31]
NVDLA: NVIDIA deep learning accelerator,
NVIDIA Corporation, “NVDLA: NVIDIA deep learning accelerator, ” 2017
2017
-
[32]
Nemotron-H: A family of accurate and efficient hybrid Mamba–Transformer models,
NVIDIA Research, “Nemotron-H: A family of accurate and efficient hybrid Mamba–Transformer models, ”arXiv preprint arXiv:2504.03624, 2025
arXiv 2025
-
[33]
SCAR: Scheduling multi-model AI workloads on heterogeneous multi-chiplet module accelerators,
M. Odemaet al., “SCAR: Scheduling multi-model AI workloads on heterogeneous multi-chiplet module accelerators, ” inMICRO, 2024
2024
-
[34]
Open neural network exchange (ONNX),
ONNX Community, “Open neural network exchange (ONNX), ” 2017
2017
-
[35]
Timeloop: A systematic approach to DNN accelerator evaluation,
A. Parasharet al., “Timeloop: A systematic approach to DNN accelerator evaluation, ” inISPASS, 2019
2019
-
[36]
PyTorch: An imperative style, high-performance deep learning library,
A. Paszkeet al., “PyTorch: An imperative style, high-performance deep learning library, ” inNeurIPS, 2019
2019
-
[37]
Voyager: An end-to-end framework for design- space exploration and generation of DNN accelerators,
K. Prabhuet al., “Voyager: An end-to-end framework for design- space exploration and generation of DNN accelerators, ”arXiv preprint arXiv:2509.15205, 2025
arXiv 2025
-
[38]
PICACHU: Plug-in CGRA handling upcoming nonlinear operations in LLMs,
J. Qinet al., “PICACHU: Plug-in CGRA handling upcoming nonlinear operations in LLMs, ” inASPLOS, 2025
2025
-
[39]
Unlocking on-device generative AI with an NPU and heterogeneous computing,
Qualcomm Technologies, Inc., “Unlocking on-device generative AI with an NPU and heterogeneous computing, ” 2024
2024
-
[40]
FlexNPU: A dataflow-aware flexible deep learning accelerator for energy-efficient edge devices,
A. Rahaet al., “FlexNPU: A dataflow-aware flexible deep learning accelerator for energy-efficient edge devices, ”Frontiers in HPC, 2025
2025
-
[41]
A systematic methodology for characterizing scalability of DNN accelerators using SCALE-Sim,
A. Samajdaret al., “A systematic methodology for characterizing scalability of DNN accelerators using SCALE-Sim, ” inISPASS, 2020
2020
-
[42]
DNPU: An energy-efficient deep-learning processor with heterogeneous multi-core architecture,
D. Shinet al., “DNPU: An energy-efficient deep-learning processor with heterogeneous multi-core architecture, ”IEEE Micro, 2018
2018
-
[43]
Targeting DNN inference via efficient utilization of heterogeneous precision DNN accelerators,
O. Spantidiet al., “Targeting DNN inference via efficient utilization of heterogeneous precision DNN accelerators, ”IEEE TETC, 2023
2023
-
[44]
Stream: Design space exploration of layer-fused DNNs on heterogeneous dataflow accelerators,
A. Symonset al., “Stream: Design space exploration of layer-fused DNNs on heterogeneous dataflow accelerators, ”IEEE TC, 2025
2025
-
[45]
Dimensity 9500 debuts Arm C1 cores and dual-NPU,
TechInsights, “Dimensity 9500 debuts Arm C1 cores and dual-NPU, ” TechInsights blog, 2025
2025
-
[46]
LLaMA: Open and efficient foundation language models,
H. Touvronet al., “LLaMA: Open and efficient foundation language models, ”arXiv preprint arXiv:2302.13971, 2023
Pith/arXiv arXiv 2023
-
[47]
Graph attention networks,
P. Veličkovićet al., “Graph attention networks, ” inICLR, 2018
2018
-
[48]
CHARM 2.0: Composing heterogeneous accelerators for deep learning on Versal ACAP architecture,
J. Zhuanget al., “CHARM 2.0: Composing heterogeneous accelerators for deep learning on Versal ACAP architecture, ”ACM TRETS, 2024. 11
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.