Leveraging Soft Distributions of SSL-Derived Discrete Speech Tokens for Downstream Inference
Pith reviewed 2026-06-27 21:20 UTC · model grok-4.3
The pith
Applying soft distributions of discrete SSL speech tokens only at inference improves ASR and speech synthesis over hard assignment, with superior out-of-domain performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that using soft distributions over SSL-derived discrete speech tokens exclusively at the inference stage for downstream tasks preserves the computational benefits of discrete tokens during training while recovering lost information, resulting in improved performance on automatic speech recognition and text-to-speech synthesis, enhanced robustness to domain shifts, and better phoneme-level alignment compared to standard hard token assignment.
What carries the argument
Soft token assignment applied only during downstream inference on discrete representations from SSL models.
If this is right
- The approach outperforms hard assignment on both ASR and speech synthesis tasks.
- It shows particularly strong generalizability to out-of-domain data.
- For ASR of non-native speech, it surpasses models using continuous SSL features.
- Analysis shows the representations align more accurately with phonemes.
Where Pith is reading between the lines
- This suggests that ambiguity in token selection can be resolved more effectively at inference without retraining the models.
- The method could be extended to other SSL-based discrete token systems in speech processing.
- It implies that some information loss from discretization is recoverable through probabilistic assignments at test time.
Load-bearing premise
The soft distributions can be computed and utilized at inference time without significant additional computational cost or modifications to the SSL model and training process.
What would settle it
An experiment where applying soft distributions at inference fails to improve performance on out-of-domain non-native speech ASR relative to hard assignment or continuous features.
Figures
read the original abstract
Discrete speech tokens obtained from self-supervised learning (SSL) models provide efficient data compression while maintaining strong performance, and have been widely used as intermediate representations in various tasks. However, discretization inevitably causes information loss, leading to degraded performance compared with continuous SSL features. In this work, we propose to apply soft token assignment only during downstream inference. This approach preserves the efficiency of hard discretization during training while enhancing the expressiveness of the tokens at inference. The proposed method outperforms conventional hard assignment on both ASR and speech synthesis tasks, and exhibits particularly strong generalizability to out-of-domain data. For ASR of non-native speech, it even surpasses models using continuous SSL features. Moreover, analysis of the resulting representations shows they align more accurately with phonemes compared with conventional hard assignment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes applying soft distributions over SSL-derived discrete speech tokens exclusively at inference time for downstream ASR and speech synthesis tasks. It claims this preserves hard-discretization efficiency during training, improves performance over conventional hard assignment, shows strong out-of-domain generalizability, and in non-native ASR even surpasses continuous SSL features, while also yielding phoneme alignments closer to ground truth.
Significance. If the central empirical claims and the no-training-change assertion hold after verification, the method would offer a low-overhead way to recover expressiveness lost to discretization without retraining or upstream modifications, with particular value for domain-robust speech systems.
major comments (2)
- [Abstract] Abstract: the claim that soft assignment occurs 'only during downstream inference' with 'no changes to the downstream training procedure' is load-bearing for the efficiency argument yet appears inconsistent; any mechanism allowing a model trained exclusively on hard token IDs (via embedding lookup) to ingest soft probability vectors at inference (e.g., expectation over embeddings) requires the forward pass to be defined and differentiable during training, creating an implicit dependency not isolated to inference.
- [Abstract / Experiments] Abstract and Experiments section: performance gains, out-of-domain superiority, and surpassing of continuous features are asserted without reference to specific datasets, baselines, statistical significance tests, or ablation controls; these omissions prevent evaluation of whether the reported improvements are robust or attributable to the proposed inference-only change.
minor comments (1)
- [Abstract] Abstract: the statement that representations 'align more accurately with phonemes' would be strengthened by naming the alignment metric and reporting quantitative values rather than qualitative description.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. Below we respond point-by-point to the major concerns, offering clarifications based on the manuscript while noting where revisions will strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that soft assignment occurs 'only during downstream inference' with 'no changes to the downstream training procedure' is load-bearing for the efficiency argument yet appears inconsistent; any mechanism allowing a model trained exclusively on hard token IDs (via embedding lookup) to ingest soft probability vectors at inference (e.g., expectation over embeddings) requires the forward pass to be defined and differentiable during training, creating an implicit dependency not isolated to inference.
Authors: The downstream models are trained exclusively with hard token IDs fed through a standard embedding lookup; no soft probabilities are ever presented during training or back-propagation. At inference we replace the one-hot selection with an expectation: the input to the first layer becomes the probability-weighted sum of the same embedding vectors. This is a purely linear, post-training computation that uses the identical embedding matrix learned under hard assignment. No architectural change, no additional parameters, and no differentiability requirement arise because the soft path is never executed or differentiated during training. The training code, loss, and optimizer remain untouched. We will add a brief clarifying sentence in the abstract and method section to make this separation explicit. revision: partial
-
Referee: [Abstract / Experiments] Abstract and Experiments section: performance gains, out-of-domain superiority, and surpassing of continuous features are asserted without reference to specific datasets, baselines, statistical significance tests, or ablation controls; these omissions prevent evaluation of whether the reported improvements are robust or attributable to the proposed inference-only change.
Authors: The abstract is intentionally concise. The Experiments section supplies the concrete details: training and test sets (LibriSpeech, Common Voice non-native subsets, etc.), exact baselines (hard k-means tokens, continuous HuBERT features), ablation variants (different SSL layers and vocabulary sizes), and statistical testing (paired t-tests or bootstrap confidence intervals reported alongside WER and MOS tables). All gains are therefore directly attributable to the inference-time soft assignment because every other component of the pipeline is held fixed. If the editor prefers, we can insert one or two dataset names into the abstract without exceeding length limits. revision: partial
Circularity Check
No circularity: purely empirical proposal with no derivation chain
full rationale
The manuscript describes an empirical method (soft token assignment restricted to inference) and reports task performance gains versus hard assignment and continuous features. No equations, fitted parameters, or uniqueness theorems appear in the provided text. The central claim is a performance comparison, not a derivation that reduces to its own inputs by construction. No self-citation load-bearing steps or ansatz smuggling are present. This matches the default expectation of a non-circular empirical paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
pseudo-text
Introduction Self-supervised learning (SSL) models pre-trained on large- scale speech data have been widely used as powerful speech representations that achieve high performance across a vari- ety of downstream tasks [1–5]. While SSL models extract se- quences of features from speech signals, recent studies have ac- tively explored discretizing these cont...
-
[2]
Related work 2.1. HuBERT-Soft HuBERT-Soft [24] is a method that takes into account the un- certainty of token assignment described above. By fine-tuning HuBERT to predict discrete tokens obtained via k-means clus- tering, it has been reported that the resulting representations can more accurately capture linguistic information while preserving the ability...
Pith/arXiv arXiv 2026
-
[3]
Posterior-based soft assignment for downstream inference 3.1. Conventional hard token assignment When discretizing an SSL feature vectorx, the standard ap- proach is to select the nearest centroid from a set of pre-trained k-means centroids{c k}K k=1 based on the distanceD k(x): Dk(x) =∥x−c k∥2 2, q(x) = arg min k∈{1,...,K} Dk(x)(1) The resulting discrete...
-
[4]
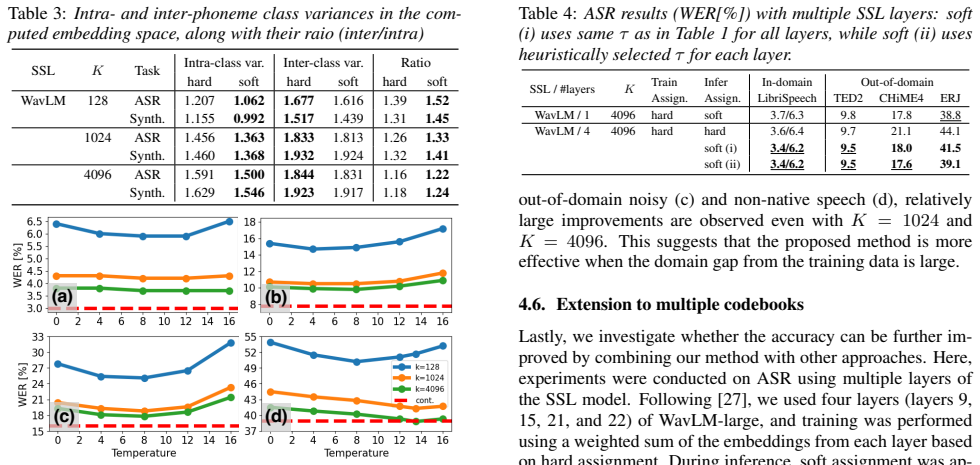
Experiments 4.1. Experimental setup In our experiments, we used HuBERT-large 1 [2] and WavLM- large2 [3], and generated discrete tokens from the outputs of the 21st layer for both models, following [17]. For learning the centroids, we applied k-means clustering to a randomly selected 30-hour subset of LibriSpeech-100h [31]. We evaluated three settings for...
2071
-
[5]
This enables more accurate inference while preserving the training time efficiency provided by hard discretization
Conclusions In this study, we proposed a method that applies soft token as- signment only at inference time for speech tasks that use dis- crete tokens as intermediate representations. This enables more accurate inference while preserving the training time efficiency provided by hard discretization. Experiments on both ASR and speech synthesis confirmed t...
-
[6]
R&D on Generative AI Foundation Models for the Physical Domain
Acknowledgments This work was supported by AIST policy-based budget project “R&D on Generative AI Foundation Models for the Physical Domain” and by JST ACT-X JPMJAX25C7
-
[7]
Generative AI Use Disclosure Generative AI was used to refine the English expressions in this manuscript
-
[8]
wav2vec 2.0: A framework for self-supervised learning of speech representa- tions,
A. Baevski, Y . Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech representa- tions,” inAdvances in Neural Information Processing Systems, vol. 33, 2020, pp. 12 449–12 460
2020
-
[9]
HuBERT: Self-supervised speech representation learning by masked prediction of hidden units,
W.-N. Hsu, B. Bolte, Y .-H. H. Tsai, K. Lakhotia, R. Salakhut- dinov, and A. Mohamed, “HuBERT: Self-supervised speech representation learning by masked prediction of hidden units,” IEEE/ACM Transactions on Audio, Speech, and Language Pro- cessing, vol. 29, pp. 3451–3460, 2021
2021
-
[10]
WavLM: Large-scale self-supervised pre-training for full stack speech processing,
S. Chen, C. Wang, Z. Chen, Y . Wu, S. Liu, Z. Chen, J. Li, N. Kanda, T. Yoshioka, X. Xiao, J. Wu, L. Zhou, S. Ren, Y . Qian, Y . Qian, M. Zeng, and F. Wei, “WavLM: Large-scale self-supervised pre-training for full stack speech processing,”IEEE Journal of Selected Topics in Signal Processing, vol. 16, pp. 1505–1518, 2021. [Online]. Available: https://api.s...
2021
-
[11]
Self-supervised speech representation learning: A review,
A. Mohamed, H.-y. Lee, L. Borgholt, J. D. Havtorn, J. Edin, C. Igel, K. Kirchhoff, S.-W. Li, K. Livescu, L. Maaløe, T. N. Sainath, and S. Watanabe, “Self-supervised speech representation learning: A review,”IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1179–1210, 2022
2022
-
[12]
Superb: Speech pro- cessing universal performance benchmark,
S. wen Yang, P.-H. Chi, Y .-S. Chuang, C.-I. J. Lai, K. Lakhotia, Y . Y . Lin, A. T. Liu, J. Shi, X. Chang, G.-T. Lin, T.-H. Huang, W.-C. Tseng, K. tik Lee, D.-R. Liu, Z. Huang, S. Dong, S.-W. Li, S. Watanabe, A. Mohamed, and H. yi Lee, “Superb: Speech pro- cessing universal performance benchmark,” inInterspeech 2021, 2021, pp. 1194–1198
2021
-
[13]
Recent advances in discrete speech tokens: A review,
Y . Guo, Z. Li, H. Wang, B. Li, C. Shao, H. Zhang, C. Du, X. Chen, S. Liu, and K. Yu, “Recent advances in discrete speech tokens: A review,”IEEE Transactions on Pattern Analysis and Machine Intelligence, pp. 1–20, 2025
2025
-
[14]
Discrete audio tokens: More than a survey!
P. Mousavi, G. Maimon, A. Moumen, D. Petermann, J. Shi, H. Wu, H. Yang, A. Kuznetsova, A. Ploujnikov, R. Marxer, B. Ramabhadran, B. Elizalde, L. Lugosch, J. Li, C. Subakan, P. Woodland, M. Kim, H. yi Lee, S. Watanabe, Y . Adi, and M. Ravanelli, “Discrete audio tokens: More than a survey!” Transactions on Machine Learning Research, 2025. [Online]. Availabl...
2025
-
[15]
On generative spoken language modeling from raw audio,
K. Lakhotia, E. Kharitonov, W.-N. Hsu, Y . Adi, A. Polyak, B. Bolte, T.-A. Nguyen, J. Copet, A. Baevski, A. Mohamed, and E. Dupoux, “On generative spoken language modeling from raw audio,”Transactions of the Association for Computational Lin- guistics, vol. 9, pp. 1336–1354, 2021
2021
-
[16]
Text-free prosody-aware generative spoken language modeling,
E. Kharitonov, A. Lee, A. Polyak, Y . Adi, J. Copet, K. Lakhotia, T. A. Nguyen, M. Riviere, A. Mohamed, E. Dupoux, and W.-N. Hsu, “Text-free prosody-aware generative spoken language modeling,” inProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), 2022, pp. 8666–8681. [Online]. Available: https:...
2022
-
[17]
Generative spoken dialogue language modeling,
T. A. Nguyen, E. Kharitonov, J. Copet, Y . Adi, W.-N. Hsu, A. Elkahky, P. Tomasello, R. Algayres, B. Sagot, A. Mohamed, and E. Dupoux, “Generative spoken dialogue language modeling,”Transactions of the Association for Computational Linguistics, vol. 11, pp. 250–266, 2023. [Online]. Available: https://aclanthology.org/2023.tacl-1.15/
2023
-
[18]
Audiolm: A language modeling approach to audio generation,
Z. Borsos, R. Marinier, D. Vincent, E. Kharitonov, O. Pietquin, M. Sharifi, D. Roblek, O. Teboul, D. Grangier, M. Tagliasacchi, and N. Zeghidour, “Audiolm: A language modeling approach to audio generation,”IEEE/ACM Trans. Audio, Speech and Lang. Proc., vol. 31, p. 2523–2533, Jun. 2023. [Online]. Available: https://doi.org/10.1109/TASLP.2023.3288409
-
[19]
Speechgpt: Empowering large language models with intrinsic cross-modal conversational abilities,
D. Zhang, S. Li, X. Zhang, J. Zhan, P. Wang, Y . Zhou, and X. Qiu, “Speechgpt: Empowering large language models with intrinsic cross-modal conversational abilities,” inFindings of the Associ- ation for Computational Linguistics: EMNLP 2023, 2023, pp. 15 757–15 773
2023
-
[20]
On the landscape of spoken language models: A comprehensive survey,
S. Arora, K.-W. Chang, C.-M. Chien, Y . Peng, H. Wu, Y . Adi, E. Dupoux, H. yi Lee, K. Livescu, and S. Watanabe, “On the landscape of spoken language models: A comprehensive survey,” Transactions on Machine Learning Research, 2025. [Online]. Available: https://openreview.net/forum?id=BvxaP3sVbA
2025
-
[21]
Towards universal speech discrete tokens: A case study for ASR and TTS,
Y . Yang, F. Shen, C. Du, Z. Ma, K. Yu, D. Povey, and X. Chen, “Towards universal speech discrete tokens: A case study for ASR and TTS,” inICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2024, pp. 10 401–10 405
2024
-
[22]
How should we extract discrete audio tokens from self-supervised models?
P. Mousavi, J. Duret, S. Zaiem, L. Della Libera, A. Ploujnikov, C. Subakan, and M. Ravanelli, “How should we extract discrete audio tokens from self-supervised models?” inInterspeech 2024, 2024, pp. 2554–2558
2024
-
[23]
The Interspeech 2024 challenge on speech processing using discrete units,
X. Chang, J. Shi, J. Tian, Y . Wu, Y . Tang, Y . Wu, S. Watanabe, Y . Adi, X. Chen, and Q. Jin, “The Interspeech 2024 challenge on speech processing using discrete units,” inInterspeech 2024, 2024, pp. 2559–2563
2024
-
[24]
Exploring speech recognition, translation, and understanding with discrete speech units: A comparative study,
X. Chang, B. Yan, K. Choi, J.-W. Jung, Y . Lu, S. Maiti, R. Sharma, J. Shi, J. Tian, S. Watanabe, Y . Fujita, T. Maekaku, P. Guo, Y .-F. Cheng, P. Denisov, K. Saijo, and H.-H. Wang, “Exploring speech recognition, translation, and understanding with discrete speech units: A comparative study,” inICASSP 2024 - 2024 IEEE Inter- national Conference on Acousti...
2024
-
[25]
Speech discrete tokens or continuous features? a comparative analysis for spoken language understanding in SpeechLLMs,
D. Wang, J. Li, M. Cui, D. Yang, X. Chen, and H. M. Meng, “Speech discrete tokens or continuous features? a comparative analysis for spoken language understanding in SpeechLLMs,” in Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025, pp. 24 924–24 935. [Online]. Available: https://aclanthology.org/2025.emnlp-main.1266/
2025
-
[26]
Ex- ploration of efficient end-to-end ASR using discretized input from self-supervised learning,
X. Chang, B. Yan, Y . Fujita, T. Maekaku, and S. Watanabe, “Ex- ploration of efficient end-to-end ASR using discretized input from self-supervised learning,” inInterspeech 2023, 2023, pp. 1399– 1403
2023
-
[27]
Acoustic bpe for speech generation with discrete tokens,
F. Shen, Y . Guo, C. Du, X. Chen, and K. Yu, “Acoustic bpe for speech generation with discrete tokens,” inICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2024, pp. 11 746–11 750
2024
-
[28]
Exploring the Benefits of Tokeniza- tion of Discrete Acoustic Units,
A. Dekel and R. Fernandez, “Exploring the Benefits of Tokeniza- tion of Discrete Acoustic Units,” inInterspeech 2024, 2024, pp. 2780–2784
2024
-
[29]
Speech resynthesis from dis- crete disentangled self-supervised representations,
A. Polyak, Y . Adi, J. Copet, E. Kharitonov, K. Lakhotia, W.-N. Hsu, A. Mohamed, and E. Dupoux, “Speech resynthesis from dis- crete disentangled self-supervised representations,” inInterspeech 2021, 2021, pp. 3615–3619
2021
-
[30]
Any-to-one sequence- to-sequence voice conversion using self-supervised discrete speech representations,
W.-C. Huang, Y .-C. Wu, and T. Hayashi, “Any-to-one sequence- to-sequence voice conversion using self-supervised discrete speech representations,” inICASSP 2021-2021 IEEE Interna- tional Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021, pp. 5944–5948
2021
-
[31]
A comparison of discrete and soft speech units for improved voice conversion,
B. Van Niekerk, M.-A. Carbonneau, J. Za ¨ıdi, M. Baas, H. Seut´e, and H. Kamper, “A comparison of discrete and soft speech units for improved voice conversion,” inICASSP 2022-2022 IEEE In- ternational Conference on Acoustics, Speech and Signal Process- ing (ICASSP), 2022, pp. 6562–6566
2022
-
[32]
Phonetic Analysis of Self- supervised Representations of English Speech,
D. Wells, H. Tang, and K. Richmond, “Phonetic Analysis of Self- supervised Representations of English Speech,” inInterspeech 2022, 2022, pp. 3583–3587
2022
-
[33]
Analysing discrete self supervised speech representation for spoken language modeling,
A. Sicherman and Y . Adi, “Analysing discrete self supervised speech representation for spoken language modeling,” inICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023, pp. 1–5
2023
-
[34]
MMM: Multi-layer multi-residual multi-stream discrete speech represen- tation from self-supervised learning model,
J. Shi, X. Ma, H. Inaguma, A. Sun, and S. Watanabe, “MMM: Multi-layer multi-residual multi-stream discrete speech represen- tation from self-supervised learning model,” inInterspeech 2024, 2024, pp. 2569–2573
2024
-
[35]
Discrete speech unit extraction via independent component analysis,
T. Nakamura, K. Choi, K. Hojo, Y . Bando, S. Fukayama, and S. Watanabe, “Discrete speech unit extraction via independent component analysis,” inSALMA: Speech and Audio Language Models - Architectures, Data Sources, and Training Paradigms, IEEE International Conference on Acoustics, Speech, and Signal Processing Workshops, 2025
2025
-
[36]
Exploring the Effect of Segmentation and V ocabulary Size on Speech Tokenization for Speech Language Models,
S. Kando, Y . Miyao, and S. Takamichi, “Exploring the Effect of Segmentation and V ocabulary Size on Speech Tokenization for Speech Language Models,” inInterspeech 2025, 2025, pp. 5728– 5732
2025
-
[37]
Bench- marking prosody encoding in discrete speech tokens,
K. Onda, S. Fukayama, D. Saito, and N. Minematsu, “Bench- marking prosody encoding in discrete speech tokens,” in2025 IEEE workshop on automatic speech recognition and understand- ing (ASRU), 2025, pp. 1–8
2025
-
[38]
Lib- rispeech: An ASR corpus based on public domain audio books,
V . Panayotov, G. Chen, D. Povey, and S. Khudanpur, “Lib- rispeech: An ASR corpus based on public domain audio books,” in2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2015, pp. 5206–5210
2015
-
[39]
Joint CTC-attention based end-to-end speech recognition using multi-task learning,
S. Kim, T. Hori, and S. Watanabe, “Joint CTC-attention based end-to-end speech recognition using multi-task learning,” in2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2017, pp. 4835–4839
2017
-
[40]
ESPnet: End-to-end speech processing toolkit,
S. Watanabe, T. Hori, S. Karita, T. Hayashi, J. Nishitoba, Y . Unno, N. Enrique Yalta Soplin, J. Heymann, M. Wiesner, N. Chen, A. Renduchintala, and T. Ochiai, “ESPnet: End-to-end speech processing toolkit,” inInterspeech 2018, 2018, pp. 2207–2211
2018
-
[41]
Enhancing the TED-LIUM corpus with selected data for language modeling and more TED talks,
A. Rousseau, P. Del ´eglise, and Y . Est `eve, “Enhancing the TED-LIUM corpus with selected data for language modeling and more TED talks,” inProceedings of the Ninth International Conference on Language Resources and Evaluation (LREC’14), 2014, pp. 3935–3939. [Online]. Available: https://aclanthology. org/L14-1079/
2014
-
[42]
An analysis of environment, microphone and data simulation mismatches in robust speech recognition,
E. Vincent, S. Watanabe, A. A. Nugraha, J. Barker, and R. Marxer, “An analysis of environment, microphone and data simulation mismatches in robust speech recognition,”Computer Speech & Language, vol. 46, pp. 535–557, 2017
2017
-
[43]
Development of English speech database read by Japanese to support CALL research,
N. Minematsu, Y . Tomiyama, K. Yoshimoto, K. Shimizu, S. Nak- agawa, M. Dantsuji, and S. Makino, “Development of English speech database read by Japanese to support CALL research,” in ICA 2004, 2004, pp. 557–560
2004
-
[44]
The lj speech dataset,
K. Ito and L. Johnson, “The lj speech dataset,” https://keithito. com/LJ-Speech-Dataset/, 2017
2017
-
[45]
Hifi-gan: Generative adversarial net- works for efficient and high fidelity speech synthesis,
J. Kong, J. Kim, and J. Bae, “Hifi-gan: Generative adversarial net- works for efficient and high fidelity speech synthesis,”Advances in Neural Information Processing Systems, vol. 33, pp. 17 022– 17 033, 2020
2020
-
[46]
Timit acoustic-phonetic continuous speech corpus,
J. Garofolo, L. Lamel, W. Fisher, J. Fiscus, D. Pallett, N. Dahlgren, and V . Zue, “Timit acoustic-phonetic continuous speech corpus,”Linguistic Data Consortium, 11 1992
1992
-
[47]
UTMOS: UTokyo-SaruLab System for V oice- MOS Challenge 2022,
T. Saeki, D. Xin, W. Nakata, T. Koriyama, S. Takamichi, and H. Saruwatari, “UTMOS: UTokyo-SaruLab System for V oice- MOS Challenge 2022,” inInterspeech 2022, 2022, pp. 4521– 4525
2022
-
[48]
Robust speech recognition via large-scale weak supervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. Mcleavey, and I. Sutskever, “Robust speech recognition via large-scale weak supervision,” inProceedings of the 40th International Conference on Machine Learning, vol. 202, 2023, pp. 28 492– 28 518. [Online]. Available: https://proceedings.mlr.press/v202/ radford23a.html
2023
-
[49]
High-fidelity neural phonetic posteriorgrams,
C. Churchwell, M. Morrison, and B. Pardo, “High-fidelity neural phonetic posteriorgrams,” in2024 IEEE International Conference on Acoustics, Speech, and Signal Processing Workshops (ICAS- SPW), 2024, pp. 823–827
2024
-
[50]
ESPnet-SPK: full pipeline speaker embedding toolkit with reproducible recipes, self-supervised front-ends, and off-the-shelf models,
J. weon Jung, W. Zhang, J. Shi, Z. Aldeneh, T. Higuchi, A. Gichamba, B.-J. Theobald, A. Hussen Abdelaziz, and S. Watanabe, “ESPnet-SPK: full pipeline speaker embedding toolkit with reproducible recipes, self-supervised front-ends, and off-the-shelf models,” inInterspeech 2024, 2024, pp. 4278–4282
2024
-
[51]
The use of multiple measurements in taxonomic problems,
R. A. Fisher, “The use of multiple measurements in taxonomic problems,”Annals of eugenics, vol. 7, no. 2, pp. 179–188, 1936
1936
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.