FAWAM: Force-Aware World Action Models for Closed-Loop Contact-Rich Manipulation
Pith reviewed 2026-06-27 18:19 UTC · model grok-4.3
The pith
FAWAM encodes force signals at perception, prediction, and closed-loop execution to raise success rates in contact-rich robotic tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
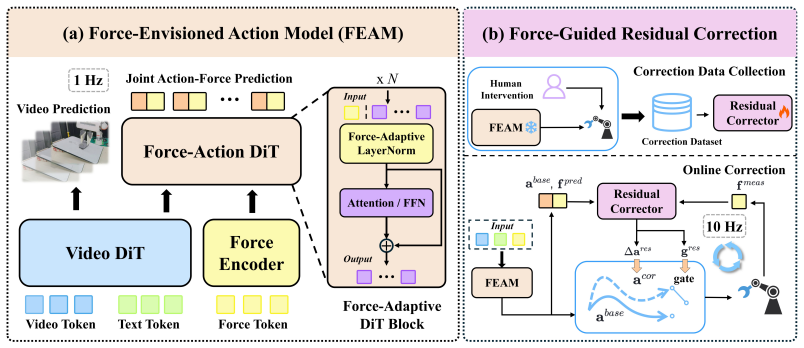
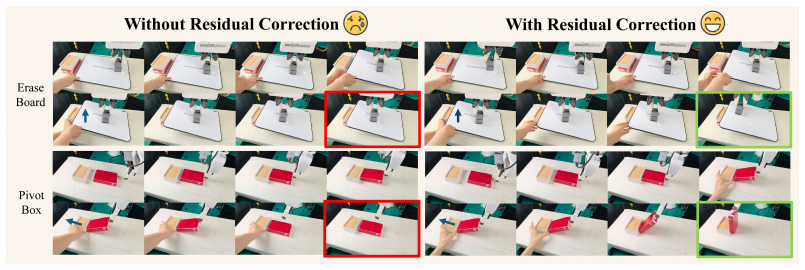
FAWAM first encodes historical 6-axis force/torque signals to modulate action generation, then jointly predicts future actions and end-effector wrenches to explicitly model contact evolution, and finally applies a residual correction module that uses the predicted wrench trajectory as an execution-time reference to refine actions online based on real-time force feedback.
What carries the argument
The residual correction module, which treats the predicted wrench trajectory as a real-time reference signal to adjust actions during execution.
If this is right
- Joint prediction of actions and wrenches produces an explicit model of how contacts evolve over time.
- Real-time force feedback drives online refinement of planned actions without retraining.
- The same architecture delivers measurable gains on multiple distinct contact-rich manipulation tasks.
- Performance exceeds both pure vision baselines and earlier force-augmented approaches by the reported margins.
Where Pith is reading between the lines
- If the wrench-prediction head remains accurate on unseen objects, the method could support rapid adaptation to new contact-rich tasks with minimal additional data.
- The three-level force integration could be tested in simulation-to-real transfer settings to check whether predicted wrenches help close the reality gap.
- Scaling the residual correction to multi-finger or dual-arm systems would reveal whether the same reference-signal approach remains stable at higher degrees of freedom.
Load-bearing premise
The residual correction module will generate stable online refinements without introducing instability or needing task-specific tuning that was not reported.
What would settle it
A controlled ablation that disables the residual correction module and measures whether success rates fall back to baseline levels or whether action execution becomes unstable on the same contact-rich tasks.
Figures











read the original abstract
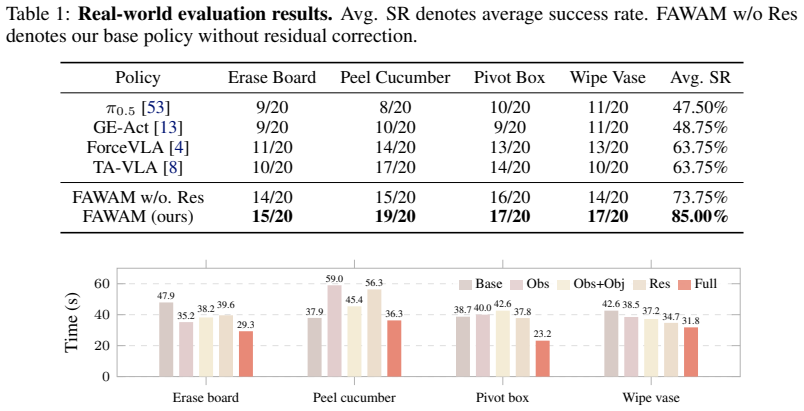
Force signals provide critical interaction cues for contact-rich robotic manipulation. However, existing methods mostly use force as an additional observation modality, without fully exploiting its role in modeling future interaction dynamics or guiding execution-time feedback correction. In this paper, we propose FAWAM, a force-aware world action model that incorporates force information at three levels: perception, prediction, and closed-loop execution. FAWAM first encodes historical 6-axis force/torque signals to modulate action generation, then jointly predicts future actions and end-effector wrenches to explicitly model contact evolution. It further introduces a residual correction module that uses the predicted wrench trajectory as an execution-time reference to refine actions online based on real-time force feedback. Real-world experiments across multiple contact-rich tasks show that FAWAM improves the average success rate by 36.25% over vision-only baselines and 21.25% over existing force-aware baselines, demonstrating the effectiveness of our force-aware framework for robust contact-rich manipulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FAWAM, a force-aware world action model for closed-loop contact-rich robotic manipulation. Force information is incorporated at three levels: perception (encoding historical 6-axis force/torque signals to modulate action generation), prediction (jointly forecasting future actions and end-effector wrenches to model contact evolution), and execution (a residual correction module that uses the predicted wrench trajectory as an online reference to refine actions based on real-time force feedback). Real-world experiments across multiple tasks claim average success-rate improvements of 36.25% over vision-only baselines and 21.25% over existing force-aware baselines.
Significance. If the empirical claims hold under rigorous validation, the explicit modeling of wrench trajectories for closed-loop residual correction represents a meaningful step toward more reliable force-aware control in contact-rich tasks, where vision-only methods often fail due to unmodeled dynamics.
major comments (2)
- [Abstract] Abstract: the headline success-rate gains (36.25% / 21.25%) are presented without any reported trial counts, statistical tests, variance measures, task definitions, or failure-mode analysis, rendering it impossible to assess whether the data support the central empirical claim.
- [Method (residual correction)] Residual correction module: no stability analysis, ablation on feedback gains, or evidence of fixed-hyperparameter generalization across tasks is supplied, which is load-bearing for the claim that the module delivers the reported improvements without introducing instability.
minor comments (1)
- [Abstract] The abstract would be clearer if it briefly named the specific contact-rich tasks evaluated.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and indicate where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline success-rate gains (36.25% / 21.25%) are presented without any reported trial counts, statistical tests, variance measures, task definitions, or failure-mode analysis, rendering it impossible to assess whether the data support the central empirical claim.
Authors: We agree that the abstract, due to length constraints, omits these supporting details. The full manuscript reports trial counts, variance, task definitions, and failure modes in the Experiments section. To address the concern directly in the abstract, we will revise it to include trial counts and variance measures. revision: yes
-
Referee: [Method (residual correction)] Residual correction module: no stability analysis, ablation on feedback gains, or evidence of fixed-hyperparameter generalization across tasks is supplied, which is load-bearing for the claim that the module delivers the reported improvements without introducing instability.
Authors: The referee is correct that the current manuscript supplies no formal stability analysis, gain ablations, or explicit generalization evidence for the residual correction module. While experiments show consistent gains without instability, this constitutes a gap in the supporting analysis. We will add an ablation on feedback gains and a discussion of hyperparameter generalization in the revised version. revision: yes
Circularity Check
No circularity; purely empirical claims with no derivations
full rationale
The paper's central claims rest on real-world experimental success rates (36.25% and 21.25% improvements) across contact-rich tasks. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided abstract or method description. The residual correction module is presented as a component of the architecture, but its performance is evaluated empirically rather than derived from prior self-referential steps. This is a standard non-finding for an applied robotics paper whose contributions are measured by hardware results rather than theoretical reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
M. A. Lee, Y . Zhu, K. Srinivasan, P. Shah, S. Savarese, L. Fei-Fei, A. Garg, and J. Bohg. Making sense of vision and touch: Self-supervised learning of multimodal representations for contact-rich tasks. In2019 International conference on robotics and automation (ICRA), pages 8943–8950. IEEE, 2019
2019
-
[2]
Z. Zhao, S. Haldar, J. Cui, L. Pinto, and R. Bhirangi. Touch begins where vision ends: Gener- alizable policies for contact-rich manipulation, 2025
2025
- [3]
-
[4]
J. Yu, H. Liu, Q. Yu, J. Ren, C. Hao, H. Ding, G. Huang, G. Huang, Y . Song, P. Cai, C. Lu, and W. Zhang. ForceVLA: Enhancing vla models with a force-aware moe for contact-rich manipulation, 2025
2025
-
[5]
C. Chen, Z. Yu, H. Choi, M. Cutkosky, and J. Bohg. Dexforce: Extracting force-informed actions from kinesthetic demonstrations for dexterous manipulation.IEEE Robotics and Au- tomation Letters, 2025
2025
-
[6]
H. Fang, S. Tang, M. Mei, H. Qin, Z. He, J. Chen, Y . Feng, C. Wang, W. Liu, Z. He, C. Lu, and S. Wang. Force policy: Learning hybrid force-position control policy under interaction frame for contact-rich manipulation, 2026
2026
-
[7]
Z. He, H. Fang, J. Chen, H.-S. Fang, and C. Lu. FoAR: Force-aware reactive policy for contact- rich robotic manipulation, 2024
2024
-
[8]
Zhang, H
Z. Zhang, H. Xu, Z. Yang, C. Yue, Z. Lin, H.-a. Gao, Z. Wang, and H. Zhao. TA-VLA: Elucidating the design space of torque-aware vision-language-action models. In9th Annual Conference on Robot Learning, 2025
2025
-
[9]
Z. Sun, Y . Wang, D. Held, and Z. Erickson. Force-constrained visual policy: Safe robot- assisted dressing via multi-modal sensing.IEEE Robotics and Automation Letters, 9(5):4178– 4185, 2024
2024
-
[10]
Y . Hou, Z. Liu, C. Chi, E. Cousineau, N. Kuppuswamy, S. Feng, B. Burchfiel, and S. Song. Adaptive compliance policy: Learning approximate compliance for diffusion guided control, 2024
2024
-
[11]
H. Xue, J. Ren, W. Chen, G. Zhang, Y . Fang, G. Gu, H. Xu, and C. Lu. Reactive diffusion policy: Slow-fast visual-tactile policy learning for contact-rich manipulation, 2025
2025
-
[12]
Y . Li, P. Tang, W. Zhang, C. Zhu, Y . Duan, W. Shi, X. Zhang, Z. Yang, J. Ji, and Y . Zhang. FA VLA: A force-adaptive fast-slow vla model for contact-rich robotic manipulation, 2026
2026
-
[13]
Y . Liao, P. Zhou, S. Huang, D. Yang, S. Chen, Y . Jiang, Y . Hu, J. Cai, S. Liu, J. Luo, et al. Genie envisioner: A unified world foundation platform for robotic manipulation.arXiv preprint arXiv:2508.05635, 2025
Pith/arXiv arXiv 2025
-
[14]
L. Li, Q. Zhang, Y . Luo, S. Yang, R. Wang, F. Han, M. Yu, Z. Gao, N. Xue, X. Zhu, Y . Shen, and Y . Xu. Causal world modeling for robot control, 2026
2026
-
[15]
J. Pai, L. Achenbach, V . Montesinos, B. Forrai, O. Mees, and E. Nava. mimic-video: Video- action models for generalizable robot control beyond vlas.arXiv preprint arXiv:2512.15692, 2025. 9
Pith/arXiv arXiv 2025
-
[16]
H. Bi, H. Tan, S. Xie, Z. Wang, S. Huang, H. Liu, R. Zhao, Y . Feng, C. Xiang, Y . Rong, et al. Motus: A unified latent action world model.arXiv preprint arXiv:2512.13030, 2025
Pith/arXiv arXiv 2025
-
[17]
T. Yuan, Z. Dong, Y . Liu, and H. Zhao. Fast-wam: Do world action models need test-time future imagination?arXiv preprint arXiv:2603.16666, 2026
Pith/arXiv arXiv 2026
-
[18]
Buamanee, M
T. Buamanee, M. Kobayashi, Y . Uranishi, and H. Takemura. Bi-act: Bilateral control-based imitation learning via action chunking with transformer. In2024 IEEE International Confer- ence on Advanced Intelligent Mechatronics (AIM), pages 410–415. IEEE, 2024
2024
-
[19]
J. Seo, A. Kruthiventy, S. Lee, M. Teng, S. Choi, X. Zhang, J. Choi, and R. Horowitz. Equicon- tact: A hierarchical se (3) vision-to-force equivariant policy for spatially generalizable contact- rich tasks.arXiv preprint arXiv:2507.10961, 2025
arXiv 2025
-
[20]
B. Zhou, R. Jiao, Y . Li, X. Yuan, F. Fang, and S. Li. Admittance visuomotor policy learning for general-purpose contact-rich manipulations.IEEE Transactions on Industrial Electronics, 2025
2025
-
[21]
J. J. Liu, Y . Li, K. Shaw, T. Tao, R. Salakhutdinov, and D. Pathak. FACTR: Force-attending curriculum training for contact-rich policy learning, 2025
2025
-
[22]
Hafner, J
D. Hafner, J. Pasukonis, J. Ba, and T. Lillicrap. Mastering diverse domains through world models, 2023
2023
-
[23]
S. Wang, J. Shi, Z. Fu, X. He, F. Liu, C. Yang, Y . Zhou, Z. Fei, J. Gong, J. Fu, M. Z. Shou, X. Huang, X. Qiu, and Y .-G. Jiang. World action models: The next frontier in embodied ai, 2026
2026
-
[24]
Y . Shen, F. Wei, Z. Du, Y . Liang, Y . Lu, J. Yang, N. Zheng, and B. Guo. Videovla: Video generators can be generalizable robot manipulators.Advances in neural information processing systems, 38:95597–95621, 2026
2026
-
[25]
B. Hou, G. Li, J. Jia, T. An, X. Guo, S. Leng, H. Geng, Y . Ze, T. Harada, P. Torr, et al. World model for robot learning: A comprehensive survey.arXiv preprint arXiv:2605.00080, 2026
Pith/arXiv arXiv 2026
-
[26]
J. Lyu, Z. Li, X. Shi, C. Xu, Y . Wang, and H. Wang. Dywa: Dynamics-adaptive world ac- tion model for generalizable non-prehensile manipulation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 11058–11068, 2025
2025
-
[27]
X. Liu, Z. Bai, H. Ci, K. Y . Ma, and M. Z. Shou. World-vla-loop: Closed-loop learning of video world model and vla policy.arXiv preprint arXiv:2602.06508, 2026
Pith/arXiv arXiv 2026
-
[28]
A. L. Chandra, I. Nematollahi, C. Huang, T. Welschehold, W. Burgard, and A. Valada. Diwa: Diffusion policy adaptation with world models. InConference on Robot Learning, pages 3378–
-
[29]
Zheng, J
R. Zheng, J. Wang, S. Reed, J. Bjorck, Y . Fang, F. Hu, J. Jang, K. Kundalia, Z. Lin, L. Magne, et al. Flare: Robot learning with implicit world modeling. InConference on Robot Learning, pages 3952–3971. PMLR, 2025
2025
-
[30]
A. Ye, B. Wang, C. Ni, G. Huang, G. Zhao, H. Li, H. Li, J. Li, J. Lv, J. Liu, et al. Gigaworld- policy: An efficient action-centered world–action model.arXiv preprint arXiv:2603.17240, 2026
arXiv 2026
-
[31]
Y . Hu, Y . Guo, P. Wang, X. Chen, Y .-J. Wang, J. Zhang, K. Sreenath, C. Lu, and J. Chen. Video prediction policy: A generalist robot policy with predictive visual representations.arXiv preprint arXiv:2412.14803, 2024. 10
Pith/arXiv arXiv 2024
-
[32]
J. Cen, C. Yu, H. Yuan, Y . Jiang, S. Huang, J. Guo, X. Li, Y . Song, H. Luo, F. Wang, et al. Worldvla: Towards autoregressive action world model.arXiv preprint arXiv:2506.21539, 2025
Pith/arXiv arXiv 2025
-
[33]
M. J. Kim, Y . Gao, T.-Y . Lin, Y .-C. Lin, Y . Ge, G. Lam, P. Liang, S. Song, M.-Y . Liu, C. Finn, and J. Gu. Cosmos policy: Fine-tuning video models for visuomotor control and planning, 2026
2026
-
[34]
S. Ye, Y . Ge, K. Zheng, S. Gao, S. Yu, G. Kurian, S. Indupuru, Y . L. Tan, C. Zhu, J. Xi- ang, A. Malik, K. Lee, W. Liang, N. Ranawaka, J. Gu, Y . Xu, G. Wang, F. Hu, A. Narayan, J. Bjorck, J. Wang, G. Kim, D. Niu, R. Zheng, Y . Xie, J. Wu, Q. Wang, R. Julian, D. Xu, Y . Du, Y . Chebotar, S. Reed, J. Kautz, Y . Zhu, L. Fan, and J. Jang. World action mode...
2026
-
[35]
S. Li, Y . Gao, D. Sadigh, and S. Song. Unified video action model.arXiv preprint arXiv:2503.00200, 2025
Pith/arXiv arXiv 2025
-
[36]
C. Zhu, R. Yu, S. Feng, B. Burchfiel, P. Shah, and A. Gupta. Unified world models: Cou- pling video and action diffusion for pretraining on large robotic datasets.arXiv preprint arXiv:2504.02792, 2025
Pith/arXiv arXiv 2025
-
[37]
Seo, B.-J
S. Seo, B.-J. Lee, J. Lee, H. Hwang, H. Yang, and K.-E. Kim. Mitigating covariate shift in behavioral cloning via robust stationary distribution correction. InAdvances in Neural Infor- mation Processing Systems, volume 37, 2024
2024
-
[38]
S. Ross, G. J. Gordon, and J. A. Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. InProceedings of the Fourteenth International Confer- ence on Artificial Intelligence and Statistics, volume 15 ofProceedings of Machine Learning Research, pages 627–635, 2011
2011
-
[39]
Kelly, C
M. Kelly, C. Sidrane, K. Driggs-Campbell, and M. J. Kochenderfer. Hg-dagger: Interactive imitation learning with human experts. In2019 International Conference on Robotics and Automation (ICRA), pages 8077–8083. IEEE, 2019
2019
-
[40]
Spencer, S
J. Spencer, S. Choudhury, M. Barnes, M. Schmittle, M. Chiang, P. Ramadge, and S. Srinivasa. Learning from interventions: Human-robot interaction as both explicit and implicit feedback. InRobotics: Science and Systems, 2020
2020
-
[41]
Mandlekar, D
A. Mandlekar, D. Xu, R. Mart ´ın-Mart´ın, Y . Zhu, L. Fei-Fei, and S. Savarese. Human-in-the- loop imitation learning using remote teleoperation, 2020
2020
-
[42]
H. Liu, S. Nasiriany, L. Zhang, Z. Bao, and Y . Zhu. Robot learning on the job: Human-in- the-loop autonomy and learning during deployment.The International Journal of Robotics Research, 2022
2022
-
[43]
Hoque, A
R. Hoque, A. Balakrishna, C. Putterman, M. Luo, D. S. Brown, D. Seita, B. Thananjeyan, E. Novoseller, and K. Goldberg. LazyDAgger: Reducing context switching in interactive imitation learning. InIEEE International Conference on Automation Science and Engineering, pages 502–509, 2021
2021
-
[44]
Hoque, A
R. Hoque, A. Balakrishna, E. Novoseller, A. Wilcox, D. S. Brown, and K. Goldberg. ThriftyDAgger: Budget-aware novelty and risk gating for interactive imitation learning, 2021
2021
-
[45]
P. Wu, Y . Shentu, Q. Liao, D. Jin, M. Guo, K. Sreenath, X. Lin, and P. Abbeel. Robocopi- lot: Human-in-the-loop interactive imitation learning for robot manipulation.arXiv preprint arXiv:2503.07771, 2025
arXiv 2025
-
[46]
X. Xu, Y . Hou, C. Xin, Z. Liu, and S. Song. Compliant residual DAgger: Improving real- world contact-rich manipulation with human corrections. InAdvances in Neural Information Processing Systems, 2025. 11
2025
-
[47]
Johannink, S
T. Johannink, S. Bahl, A. Nair, J. Luo, A. Kumar, M. Loskyll, J. A. Ojea, E. Solowjow, and S. Levine. Residual reinforcement learning for robot control. InIEEE International Conference on Robotics and Automation, pages 6023–6029, 2019
2019
-
[48]
Ankile, A
L. Ankile, A. Simeonov, I. Shenfeld, M. Torne, and P. Agrawal. From imitation to refinement: Residual RL for precise assembly, 2024
2024
-
[49]
X. Yuan, T. Mu, S. Tao, Y . Fang, M. Zhang, and H. Su. Policy decorator: Model-agnostic online refinement for large policy model, 2024
2024
-
[50]
T. He, J. Gao, W. Xiao, Y . Zhang, Z. Wang, J. Wang, Z. Luo, G. He, N. Sobanbab, C. Pan, et al. Asap: Aligning simulation and real-world physics for learning agile humanoid whole- body skills.arXiv preprint arXiv:2502.01143, 2025
arXiv 2025
- [51]
-
[52]
Guzey, Y
I. Guzey, Y . Dai, B. Evans, S. Chintala, and L. Pinto. See to touch: Learning tactile dexterity through visual incentives. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 13825–13832. IEEE, 2024
2024
-
[53]
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, et al.π 0.5: A vision-language-action model with open-world generalization. arXiv preprint arXiv:2504.16054, 2025. 12 A Appendix A.1 Hardware and Training Details Hardware.Figure 6 shows the physical layout of the follower robot, FACTR leader ...
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.