Probing Token Spaces under Generator Shift in AI-Generated Music Detection
Pith reviewed 2026-06-27 18:02 UTC · model grok-4.3
The pith
Codec-style token spaces vary sharply in performance when AI music detectors face new generators not seen in training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Using source-restricted evaluation on the MoM-open dataset, the experiments demonstrate that fake-source restriction exposes large differences between token spaces, with X-Codec tokens strongest when training on Udio alone and MERT-derived tokens stronger when training on Suno-v3.5 alone, while standard splits are nearly saturated.
What carries the argument
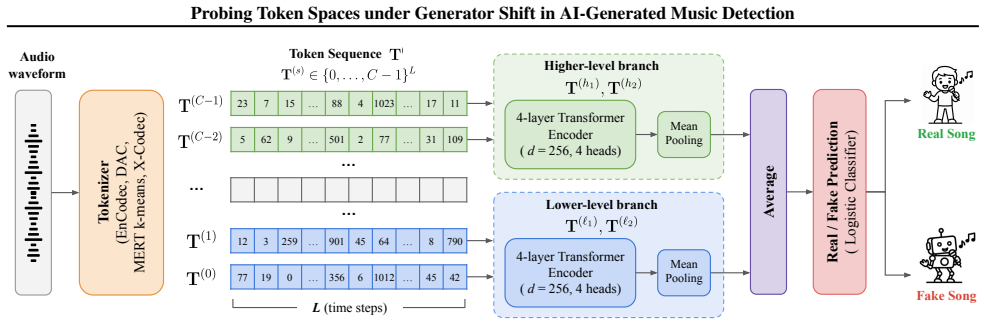
CoMoE, a compact fixed classifier designed to compare heterogeneous audio token spaces while holding the downstream architecture and training recipe constant.
If this is right
- Standard and real-source-restricted evaluation splits saturate and fail to distinguish token spaces.
- Fake-source restriction reveals that X-Codec tokens excel for Udio shifts while MERT tokens excel for Suno-v3.5 shifts.
- Codec-style discrete token spaces should be treated as a primary experimental axis when studying generator shift in detection.
- The choice of token representation affects generalization more than the classifier architecture in this setting.
Where Pith is reading between the lines
- Future detectors may need to ensemble multiple token spaces to cover different generator shifts.
- Similar token-space sensitivity could appear in other generative media like images or video when facing new generators.
- Open reconstructions like MoM-open enable community testing of transfer without relying on restricted data.
Load-bearing premise
The open reconstruction MoM-open using FMA and MTG-Jamendo keeps the fake-generator protocol close enough to the original to separate token effects from data differences.
What would settle it
A direct comparison showing that the performance gaps between token spaces disappear when the same models are evaluated on the original non-open MoM-CLAM splits would falsify the isolation of token-space effects.
Figures
read the original abstract
AI-generated music detectors can appear robust on standard benchmark splits, yet their deployments require transfer to generator sources absent during training. We study this problem with source-restricted evaluation on \textsc{MoM-open}, an open reconstruction of MoM-CLAM that replaces the non-redistributable real corpus with FMA and MTG-Jamendo while preserving the fake-generator protocol. To isolate the role of representation, we introduce \textsc{CoMoE}, a compact fixed classifier for comparing heterogeneous audio token spaces while keeping the downstream architecture and training recipe unchanged. Experiments show that standard and real-source-restricted splits are nearly saturated, whereas fake-source restriction exposes large differences between token spaces: X-Codec tokens are strongest when training on Udio alone, while MERT-derived tokens are stronger when training on Suno-v3.5 alone. These results suggest that codec-style discrete token spaces should be treated as a primary experimental axis under generator shift in AI-generated music detection. Our code and data are available at https://github.com/MAAP-LAB/CoMoE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that standard and real-source-restricted splits for AI-generated music detection are nearly saturated, but fake-source restriction on the introduced MoM-open dataset (an open reconstruction of MoM-CLAM using FMA/MTG-Jamendo) reveals large performance gaps between token spaces when using the fixed CoMoE classifier: X-Codec tokens perform best under Udio-only training while MERT-derived tokens are stronger under Suno-v3.5-only training. This leads to the suggestion that codec-style discrete token spaces should be treated as a primary experimental axis under generator shift.
Significance. If the isolation of token-space effects from corpus artifacts holds, the results would identify representation choice as a key factor in robustness to unseen generators, with implications for detector design in music audio tasks. The public availability of code and data strengthens the work's reproducibility.
major comments (2)
- [Abstract] Abstract and §3 (MoM-open construction): the central claim that observed gaps are attributable to token-space properties rather than dataset artifacts requires that the FMA/MTG-Jamendo replacement preserves the original real-corpus distribution with respect to token-extractor behavior, yet no validation (acoustic feature overlap, genre/length statistics, or spectral bias checks) is reported to support this isolation.
- [Experiments] Experiments section: performance differences are reported as 'large' without error bars, statistical significance tests, multiple runs, or full training details (learning rate, epochs, batch size), which is load-bearing for the claim that X-Codec is strongest on Udio-only and MERT on Suno-v3.5-only.
minor comments (1)
- The description of CoMoE as a 'compact fixed classifier' for comparing heterogeneous token spaces would benefit from an explicit architecture diagram or parameter count to clarify how the downstream recipe remains unchanged across extractors.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our work. We address the major comments point by point below, indicating planned revisions where applicable.
read point-by-point responses
-
Referee: [Abstract] Abstract and §3 (MoM-open construction): the central claim that observed gaps are attributable to token-space properties rather than dataset artifacts requires that the FMA/MTG-Jamendo replacement preserves the original real-corpus distribution with respect to token-extractor behavior, yet no validation (acoustic feature overlap, genre/length statistics, or spectral bias checks) is reported to support this isolation.
Authors: We agree that validating the distribution preservation is important for isolating token-space effects. Since the original MoM-CLAM real corpus is non-redistributable, direct acoustic feature overlap checks with it are not feasible. However, we will add genre distribution, track length statistics, and basic spectral feature comparisons (e.g., mean spectral centroid and rolloff) for the FMA/MTG-Jamendo real sources in the revised §3 to provide transparency on the replacement corpus. The core findings focus on performance gaps under fake-source restriction, where the real data acts as a fixed negative class. revision: partial
-
Referee: [Experiments] Experiments section: performance differences are reported as 'large' without error bars, statistical significance tests, multiple runs, or full training details (learning rate, epochs, batch size), which is load-bearing for the claim that X-Codec is strongest on Udio-only and MERT on Suno-v3.5-only.
Authors: This is a valid concern regarding the robustness of the reported differences. In the revised manuscript, we will rerun the experiments with multiple random seeds (at least 3-5), include error bars on the performance metrics, conduct statistical significance tests (e.g., paired t-tests) between token spaces, and provide complete training details including learning rate, number of epochs, batch size, and other hyperparameters in the Experiments section or a dedicated appendix. revision: yes
- Direct validation of token-extractor behavior equivalence between the original non-redistributable real corpus and the FMA/MTG-Jamendo replacement, due to lack of access to the original data.
Circularity Check
Empirical study with independent dataset and fixed classifier; no circular derivation
full rationale
The paper conducts an empirical comparison of audio token spaces using a newly constructed open dataset (MoM-open) and a fixed downstream classifier (CoMoE) whose architecture and training recipe are held constant. Performance differences under fake-source restriction are reported directly from cross-generator experiments rather than derived from any fitted parameter, self-citation chain, or definitional equivalence. No equations, uniqueness theorems, or ansatzes are invoked that reduce the central claim to its inputs by construction. The recommendation to treat codec-style spaces as a primary axis follows from the observed experimental gaps and is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard supervised learning assumptions for audio classification hold for the CoMoE setup.
invented entities (1)
-
CoMoE
no independent evidence
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2405.04181 , year=
Detecting music deepfakes is easy but actually hard , author=. arXiv preprint arXiv:2405.04181 , year=
-
[2]
AI-Generated Music Detection and its Challenges , year=
Afchar, Darius and Meseguer-Brocal, Gabriel and Hennequin, Romain , booktitle=. AI-Generated Music Detection and its Challenges , year=
-
[3]
Transactions on Machine Learning Research , issn=
Melody or Machine: Detecting Synthetic Music with Dual-Stream Contrastive Learning , author=. Transactions on Machine Learning Research , issn=
-
[4]
Bogdanov, Dmitry and Won, Minz and Tovstogan, Philip and Porter, Alastair and Serra, Xavier , booktitle=. The
-
[5]
Cros Vila, Laura and Sturm, Bob L. T. and Casini, Luca and Dalmazzo, David , journal=. The
-
[6]
Proceedings of the International Society for Music Information Retrieval Conference (ISMIR) , pages=
Defferrard, Micha. Proceedings of the International Society for Music Information Retrieval Conference (ISMIR) , pages=
-
[7]
Transactions on Machine Learning Research , year=
High Fidelity Neural Audio Compression , author=. Transactions on Machine Learning Research , year=
-
[8]
2022 , howpublished=
Riffusion: Stable Diffusion for Real-Time Music Generation , author=. 2022 , howpublished=
2022
-
[9]
High-Fidelity Audio Compression with Improved
Kumar, Rithesh and Seetharaman, Prem and Luebs, Alejandro and Kumar, Ishaan and Kumar, Kundan , booktitle=. High-Fidelity Audio Compression with Improved
-
[10]
Li, Xinfeng and Li, Kai and Zheng, Yifan and Yan, Chen and Ji, Xiaoyu and Xu, Wenyuan , booktitle=
-
[11]
and Liu, Ruibo and Chen, Wenhu and Xia, Gus and Shi, Yemin and Huang, Wenhao and Wang, Yike and Guo, Yike and Fu, Jie , booktitle=
Li, Yizhi and Yuan, Ruibin and Zhang, Ge and Ma, Yinghao and Chen, Xingran and Yin, Hanzhi and Xiao, Chenghao and Lin, Chenghua and Ragni, Anton and Benetos, Emmanouil and Gyenge, Norbert and Dannenberg, Roger B. and Liu, Ruibo and Chen, Wenhu and Xia, Gus and Shi, Yemin and Huang, Wenhao and Wang, Yike and Guo, Yike and Fu, Jie , booktitle=
-
[12]
arXiv preprint arXiv:2412.00571 , year=
From Audio Deepfake Detection to AI-Generated Music Detection--A Pathway and Overview , author=. arXiv preprint arXiv:2412.00571 , year=
-
[13]
Proceedings of the International Conference on Learning Representations (ICLR) , year=
Decoupled Weight Decay Regularization , author=. Proceedings of the International Conference on Learning Representations (ICLR) , year=
-
[14]
arXiv preprint arXiv:2503.01183 , year=
Diffrhythm: Blazingly fast and embarrassingly simple end-to-end full-length song generation with latent diffusion , author=. arXiv preprint arXiv:2503.01183 , year=
-
[15]
Proceedings of the International Conference on Machine Learning , volume=
Learning Transferable Visual Models from Natural Language Supervision , author=. Proceedings of the International Conference on Machine Learning , volume=
-
[16]
Rahman, Md Awsafur and Hakim, Zaber Ibn Abdul and Sarker, Najibul Haque and Paul, Bishmoy and Fattah, Shaikh Anowarul , booktitle=
-
[17]
2024 , howpublished=
Suno. 2024 , howpublished=
2024
-
[18]
2024 , howpublished=
Udio. 2024 , howpublished=
2024
-
[19]
Wu, Haibin and Tseng, Yuan and Lee, Hung-yi , booktitle=
-
[20]
IEEE Transactions on Multimedia , volume=
Music popularity: Metrics, characteristics, and audio-based prediction , author=. IEEE Transactions on Multimedia , volume=
-
[21]
arXiv preprint arXiv:2603.16914 , year=
Quantizer-Aware Hierarchical Neural Codec Modeling for Speech Deepfake Detection , author=. arXiv preprint arXiv:2603.16914 , year=
-
[22]
A Sanity Check for
Yan, Shilin and Li, Ouxiang and Cai, Jiayin and Hao, Yanbin and Jiang, Xiaolong and Hu, Yao and Xie, Weidi , booktitle=. A Sanity Check for
-
[23]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Codec Does Matter: Exploring the Semantic Shortcoming of Codec for Audio Language Model , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[24]
Proceedings of the International Conference on Learning Representations (ICLR) , year=
YuE: Scaling Open Foundation Models for Long-Form Music Generation , author=. Proceedings of the International Conference on Learning Representations (ICLR) , year=
-
[25]
IEEE/ACM Transactions on Audio, Speech, and Language Processing , volume=
SoundStream: An End-to-End Neural Audio Codec , author=. IEEE/ACM Transactions on Audio, Speech, and Language Processing , volume=
-
[26]
, booktitle=
Sculley, D. , booktitle=. Web-Scale
-
[27]
Comanducci, Luca and Bestagini, Paolo and Tubaro, Stefano , journal=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.