Teach Multimodal Recommendation Model to See via Personalized Visual Extraction and Adaptive Learning
Pith reviewed 2026-06-27 14:55 UTC · model grok-4.3
The pith
REVEAL improves multimodal sequential recommendations by using feedback to extract better visuals and balance text and image learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
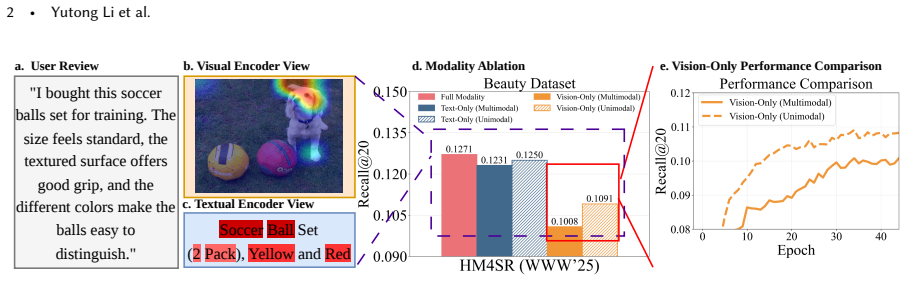
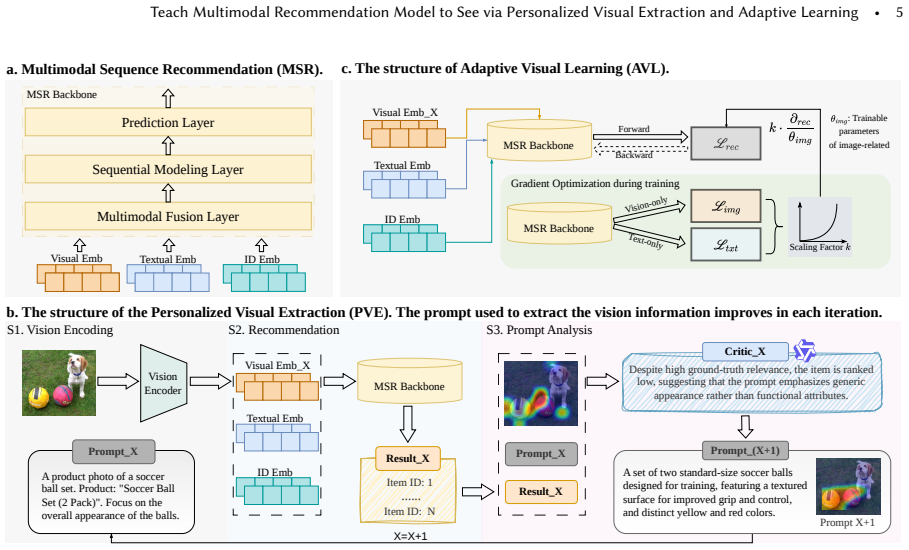
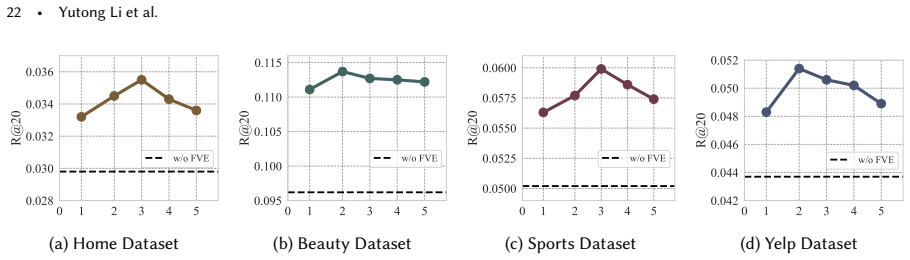
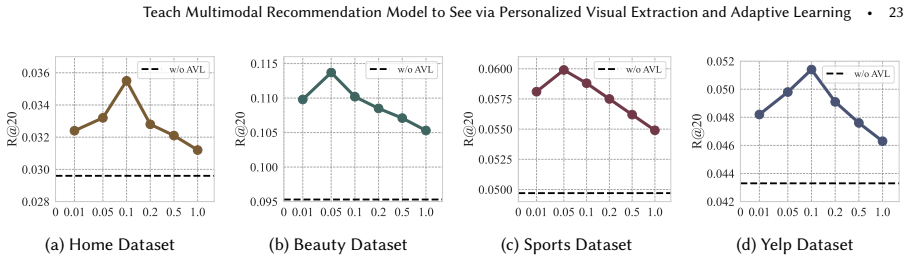
The central discovery is that a framework called REVEAL, with Feedback-Guided Visual Extraction to refine visual features using task feedback and Adaptive Visual Learning to dynamically balance modality contributions, leads to more effective use of visual information and higher recommendation performance across datasets.
What carries the argument
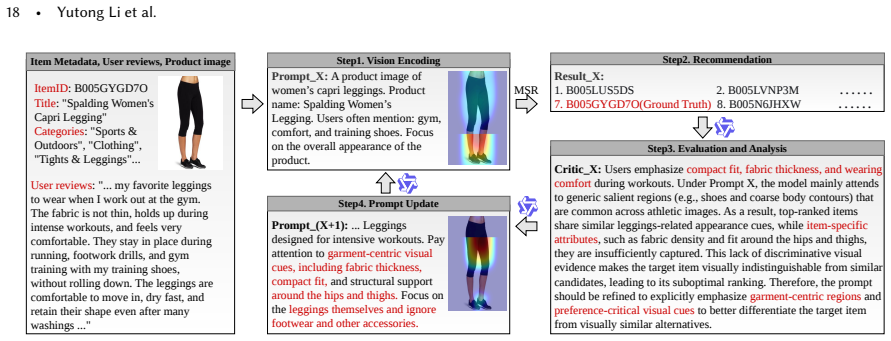
The Feedback-Guided Visual Extraction module that uses recommendation task feedback to adjust prompt-based visual feature pulling from pretrained models, paired with the Adaptive Visual Learning module that reweights the visual loss dynamically.
If this is right
- Greater focus on preference-relevant regions in visual data.
- More balanced contribution from visual and textual features in optimization.
- Performance gains on various real-world datasets without backbone modifications.
- Increased overall visual utilization in the learning process.
Where Pith is reading between the lines
- The method could be adapted to improve other underutilized modalities in multimodal systems.
- It suggests that external feedback loops can enhance pretrained encoders in recommendation settings.
- Potential for applying similar adaptive techniques to address imbalances in other machine learning tasks involving multiple data types.
Load-bearing premise
The recommendation task's output can provide useful signals to improve visual feature extraction from fixed pretrained encoders without direct access to the backbone's training process.
What would settle it
An experiment showing that models with REVEAL achieve the same or lower accuracy metrics than the original MSR models on the same datasets would falsify the improvement claim.
Figures
read the original abstract
Multimodal sequential recommendation (MSR) incorporates textual and visual information to improve recommendation quality. However, recent studies and our empirical analysis show that visual features are often underutilized, thereby contributing far less than textual signals. We attribute this issue to two factors: insufficient visual representation learning (pretrained encoders fail to capture preference-relevant cues) and unbalanced visual-text optimization (textual features dominate the learning process). To address these issues, we propose Teach Multimodal Recommendation Model to See via Personalized Visual Extraction and Adaptive Learning (REVEAL), a plug-and-play framework that enhances visual representation learning and cross-modal optimization without modifying the original recommendation backbone. REVEAL consists of Feedback-Guided Visual Extraction (FVE), which refines prompt-guided visual extraction through task-level feedback, and Adaptive Visual Learning (AVL), which dynamically reweights visual learning to alleviate modality imbalance. Experiments on multiple real-world datasets and MSR backbones demonstrate that REVEAL consistently improves recommendation performance. Further analysis shows that these gains arise from more effective attention to preference-relevant visual regions and better visual utilization during training. The code is available at https://github.com/YutongLi2024/REVEAL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that visual features are underutilized in multimodal sequential recommendation (MSR) due to insufficient representation learning from pretrained encoders and modality imbalance favoring text. It proposes REVEAL, a plug-and-play framework with two components: Feedback-Guided Visual Extraction (FVE), which refines prompt-guided visual extraction from pretrained encoders using task-level feedback, and Adaptive Visual Learning (AVL), which dynamically reweights visual learning. Experiments on multiple real-world datasets and MSR backbones show consistent performance gains attributed to better attention on preference-relevant visual regions and improved visual utilization, without modifying the original recommendation backbone. Code is released.
Significance. If the decoupling of FVE from the backbone holds and the reported gains are robust, the framework could offer a practical, modular way to boost visual contribution in existing MSR systems. The plug-and-play design and release of code are positive for reproducibility.
major comments (2)
- [Abstract / Method description of FVE] Abstract and method overview: The central claim that FVE 'refines prompt-guided visual extraction through task-level feedback' without 'modifying the original recommendation backbone' or requiring 'access to its internal training dynamics' is load-bearing for the plug-and-play assertion. No derivation or pseudocode shows how recommendation loss feedback updates visual prompt/extraction parameters in a fully decoupled manner (e.g., via detached gradients, separate optimizer, or non-gradient mechanism); if backpropagation is used, it either alters effective backbone training or requires gradient exposure, contradicting the stated independence.
- [Experiments] Experiments section: The abstract states 'consistent improvements' and attributes them to 'more effective attention to preference-relevant visual regions,' but provides no quantitative details on baselines, effect sizes, statistical significance, or error analysis. Without these, it is impossible to assess whether gains exceed what could be obtained by stronger visual encoders or simple reweighting alone.
minor comments (2)
- [Method] Notation for prompt-guided extraction and reweighting parameters should be introduced with explicit equations rather than prose descriptions.
- [AVL description] The claim of 'parameter-free' aspects (if any) in AVL should be checked against the actual implementation details.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and indicate planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / Method description of FVE] Abstract and method overview: The central claim that FVE 'refines prompt-guided visual extraction through task-level feedback' without 'modifying the original recommendation backbone' or requiring 'access to its internal training dynamics' is load-bearing for the plug-and-play assertion. No derivation or pseudocode shows how recommendation loss feedback updates visual prompt/extraction parameters in a fully decoupled manner (e.g., via detached gradients, separate optimizer, or non-gradient mechanism); if backpropagation is used, it either alters effective backbone training or requires gradient exposure, contradicting the stated independence.
Authors: We thank the referee for highlighting the need for explicit technical detail on decoupling. In our design, FVE maintains a separate set of visual prompt parameters updated by a dedicated optimizer on the recommendation loss; gradients flowing back to the backbone are explicitly detached so that backbone parameters and training dynamics are untouched and no internal states are accessed. We will add a formal derivation, algorithmic steps, and pseudocode to Section 3.2 in the revision to demonstrate this mechanism clearly. revision: yes
-
Referee: [Experiments] Experiments section: The abstract states 'consistent improvements' and attributes them to 'more effective attention to preference-relevant visual regions,' but provides no quantitative details on baselines, effect sizes, statistical significance, or error analysis. Without these, it is impossible to assess whether gains exceed what could be obtained by stronger visual encoders or simple reweighting alone.
Authors: The experiments section already reports results on multiple datasets and backbones against several baselines using HR@K and NDCG@K. We agree that additional quantitative support is warranted. In the revision we will insert statistical significance tests (paired t-tests with p-values), effect-size calculations, error bars, and extra ablation rows that directly compare against stronger visual encoders and simple reweighting variants to isolate the contributions of FVE and AVL. revision: yes
Circularity Check
No circularity: framework additions are independent of backbone.
full rationale
The paper presents REVEAL as an external plug-and-play module (FVE + AVL) that operates on task-level feedback without altering the MSR backbone or exposing its internals. No equations, derivations, or parameter-fitting steps are described that reduce by construction to the inputs or to self-citations. Claims rest on empirical gains across datasets and backbones rather than any self-definitional prediction or renamed known result. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al . 2025. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923(2025)
Pith/arXiv arXiv 2025
-
[2]
Shuqing Bian, Xingyu Pan, Wayne Xin Zhao, Jinpeng Wang, Chuyuan Wang, and Ji-Rong Wen. 2023. Multi-modal Mixture of Experts Represetation Learning for Sequential Recommendation. InProceedings of the 32nd ACM International Conference on Information and Knowledge Management (CIKM ’23). Association for Computing Machinery, New York, NY, USA, 110–119
2023
-
[3]
Jianxin Chang, Chen Gao, Yu Zheng, Yiqun Hui, Yanan Niu, Yang Song, Depeng Jin, and Yong Li. 2021. Sequential Recommendation with Graph Neural Networks. InProceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’21). Association for Computing Machinery, New York, NY, USA, 378–387
2021
-
[4]
Qile Fan, Penghang Yu, Zhiyi Tan, Bing-Kun Bao, and Guanming Lu. 2025. BeFA: a general behavior-driven feature adapter for multimedia recommendation. InProceedings of the Thirty-Ninth AAAI Conference on Artificial Intelligence (AAAI’25). AAAI Press, Article 1293, 11 pages
2025
-
[5]
Ziwei Fan, Zhiwei Liu, Yu Wang, Alice Wang, Zahra Nazari, Lei Zheng, Hao Peng, and Philip S. Yu. 2022. Sequential Recommendation via Stochastic Self-Attention. InProceedings of the ACM Web Conference 2022 (WWW ’22). Association for Computing Machinery, New York, NY, USA, 2036–2047
2022
-
[6]
Ramin Giahi, Kehui Yao, Sriram Kollipara, Kai Zhao, Vahid Mirjalili, Jianpeng Xu, Topojoy Biswas, Evren Korpeoglu, and Kannan Achan
-
[7]
InProceedings of the Nineteenth ACM Conference on Recommender Systems (RecSys ’25)
VL-CLIP: Enhancing Multimodal Recommendations via Visual Grounding and LLM-Augmented CLIP Embeddings. InProceedings of the Nineteenth ACM Conference on Recommender Systems (RecSys ’25). Association for Computing Machinery, New York, NY, USA, 482–491
-
[8]
Ruining He and Julian McAuley. 2016. Fusing similarity models with markov chains for sparse sequential recommendation. In2016 IEEE 16th international conference on data mining (ICDM). IEEE, 191–200
2016
-
[9]
Ruining He and Julian McAuley. 2016. VBPR: visual Bayesian Personalized Ranking from implicit feedback. InProceedings of the Thirtieth AAAI Conference on Artificial Intelligence (AAAI’16). AAAI Press, Phoenix, Arizona, 144–150
2016
-
[10]
Xiangnan He, Kuan Deng, Xiang Wang, Yan Li, YongDong Zhang, and Meng Wang. 2020. LightGCN: Simplifying and Powering Graph Convolution Network for Recommendation. InProceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’20). Association for Computing Machinery, New York, NY, USA, 639–648
2020
-
[11]
Balázs Hidasi, Alexandros Karatzoglou, Linas Baltrunas, and Domonkos Tikk. 2016. Session-based Recommendations with Recurrent Neural Networks. In4th International Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, May 2-4, 2016, Conference Track Proceedings, Yoshua Bengio and Yann LeCun (Eds.). ICLR, San Juan, Puerto Rico
2016
-
[12]
Yupeng Hou, Shanlei Mu, Wayne Xin Zhao, Yaliang Li, Bolin Ding, and Ji-Rong Wen. 2022. Towards Universal Sequence Representation Learning for Recommender Systems. InProceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD ’22). Association for Computing Machinery, New York, NY, USA, 585–593
2022
-
[13]
Hengchang Hu, Wei Guo, Yong Liu, and Min-Yen Kan. 2023. Adaptive Multi-Modalities Fusion in Sequential Recommendation Systems. In Proceedings of the 32nd ACM International Conference on Information and Knowledge Management (CIKM ’23). Association for Computing Machinery, New York, NY, USA, 843–853
2023
-
[14]
Hyunsik Jeon, Satoshi Koide, Yu Wang, Zhankui He, and Julian McAuley. 2025. Adapting Large Vision-Language Models to Visually- Aware Conversational Recommendation. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.2 (KDD ’25). Association for Computing Machinery, New York, NY, USA, 1037–1048
2025
-
[15]
Mengyuan Jing, Yanmin Zhu, Tianzi Zang, and Ke Wang. 2023. Contrastive Self-supervised Learning in Recommender Systems: A Survey.ACM Trans. Inf. Syst.42, 2 (2023), 39 pages
2023
-
[16]
Wang-Cheng Kang and Julian J. McAuley. 2018. Self-Attentive Sequential Recommendation. InIEEE International Conference on Data Mining, ICDM 2018, Singapore, November 17-20, 2018. IEEE Computer Society, Singapore, 197–206
2018
-
[17]
Jing Li, Pengjie Ren, Zhumin Chen, Zhaochun Ren, Tao Lian, and Jun Ma. 2017. Neural Attentive Session-based Recommendation. InProceedings of the 2017 ACM on Conference on Information and Knowledge Management (CIKM ’17). Association for Computing Machinery, New York, NY, USA, 1419–1428
2017
-
[18]
Jiacheng Li, Ming Wang, Jin Li, Jinmiao Fu, Xin Shen, Jingbo Shang, and Julian McAuley. 2023. Text Is All You Need: Learning Language Representations for Sequential Recommendation. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data , Vol. 1, No. 1, Article . Publication date: June 2018. 26•Yutong Li et al. Mining (KDD ’23). As...
2023
-
[19]
Xuewei Li, Aitong Sun, Mankun Zhao, Jian Yu, Kun Zhu, Di Jin, Mei Yu, and Ruiguo Yu. 2023. Multi-Intention Oriented Contrastive Learning for Sequential Recommendation. InProceedings of the Sixteenth ACM International Conference on Web Search and Data Mining (WSDM ’23). Association for Computing Machinery, New York, NY, USA, 411–419
2023
-
[20]
Yuanzi Li, Xuri Ge, Jingyu Zhao, Yidan Wang, Jiyuan Yang, Zhumin Chen, Zhaochun Ren, and Xin Xin. 2026. R2NS: Recall and Re-ranking of Negative Samples for Sequential Recommendation. InProceedings of the ACM Web Conference 2026 (WWW ’26). Association for Computing Machinery, New York, NY, USA, 6331–6341
2026
-
[21]
Yutong Li and Xinyi Zhang. 2025. MDSBR: Multimodal Denoising for Session-based Recommendation. InProceedings of the Nineteenth ACM Conference on Recommender Systems (RecSys ’25). Association for Computing Machinery, New York, NY, USA, 268–278
2025
-
[22]
Zihao Li, Aixin Sun, and Chenliang Li. 2023. DiffuRec: A Diffusion Model for Sequential Recommendation.ACM Trans. Inf. Syst.42, 3, Article 66 (Dec. 2023), 28 pages
2023
-
[23]
Jiahao Liang, Xiangyu Zhao, Muyang Li, Zijian Zhang, Wanyu Wang, Haochen Liu, and Zitao Liu. 2023. Mmmlp: Multi-modal multilayer perceptron for sequential recommendations. InProceedings of the ACM Web Conference 2023 (WWW ’23). Association for Computing Machinery, New York, NY, USA, 1109–1117
2023
-
[24]
Qidong Liu, Jiaxi Hu, Yutian Xiao, Xiangyu Zhao, Jingtong Gao, Wanyu Wang, Qing Li, and Jiliang Tang. 2024. Multimodal Recommender Systems: A Survey.ACM Comput. Surv.57, 2 (2024), 17 pages
2024
-
[25]
Xiaokang Peng, Yake Wei, Andong Deng, Dong Wang, and Di Hu. 2022. Balanced multimodal learning via on-the-fly gradient modulation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 8238–8247
2022
-
[26]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. 2021. Learning transferable visual models from natural language supervision. InInternational conference on machine learning. PMLR, Virtual, 8748–8763
2021
-
[27]
Steffen Rendle, Christoph Freudenthaler, Zeno Gantner, and Lars Schmidt-Thieme. 2009. BPR: Bayesian personalized ranking from implicit feedback. InProceedings of the Twenty-Fifth Conference on Uncertainty in Artificial Intelligence (UAI ’09). AUAI Press, Arlington, Virginia, USA, 452–461
2009
-
[28]
Steffen Rendle, Christoph Freudenthaler, and Lars Schmidt-Thieme. 2010. Factorizing personalized Markov chains for next-basket recommendation. InProceedings of the 19th International Conference on World Wide Web (WWW ’10). Association for Computing Machinery, 811–820
2010
-
[29]
Rumelhart, Geoffrey E
David E. Rumelhart, Geoffrey E. Hinton, and Ronald J. Williams. 1988.Learning representations by back-propagating errors. MIT Press, Cambridge, MA, USA, 696–699
1988
-
[30]
Fei Sun, Jun Liu, Jian Wu, Changhua Pei, Xiao Lin, Wenwu Ou, and Peng Jiang. 2019. BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer. InProceedings of the 28th ACM International Conference on Information and Knowledge Management (CIKM ’19). Association for Computing Machinery, New York, NY, USA, 1441–1450
2019
-
[31]
Zuoli Tang, Zhaoxin Huan, Zihao Li, Xiaolu Zhang, Jun Hu, Chilin Fu, Jun Zhou, Lixin Zou, and Chenliang Li. 2025. One Model for All: Large Language Models Are Domain-Agnostic Recommendation Systems.ACM Trans. Inf. Syst.43, 5, Article 118 (July 2025), 27 pages
2025
-
[32]
Jinpeng Wang, Ziyun Zeng, Yunxiao Wang, Yuting Wang, Xingyu Lu, Tianxiang Li, Jun Yuan, Rui Zhang, Hai-Tao Zheng, and Shu-Tao Xia. 2023. MISSRec: Pre-training and Transferring Multi-modal Interest-aware Sequence Representation for Recommendation. In Proceedings of the 31st ACM International Conference on Multimedia (MM ’23). Association for Computing Mach...
2023
-
[33]
Yake Wei, Di Hu, Henghui Du, and Ji-Rong Wen. 2025. On-the-Fly Modulation for Balanced Multimodal Learning.IEEE Trans. Pattern Anal. Mach. Intell.47, 1 (2025), 469–485
2025
-
[34]
Yake Wei, Siwei Li, Ruoxuan Feng, and Di Hu. 2024. Diagnosing and re-learning for balanced multimodal learning. InEuropean Conference on Computer Vision. Springer, 71–86
2024
-
[35]
Liwei Wu, Shuqing Li, Cho-Jui Hsieh, and James Sharpnack. 2020. SSE-PT: Sequential Recommendation Via Personalized Transformer. InProceedings of the 14th ACM Conference on Recommender Systems (RecSys ’20). Association for Computing Machinery, New York, NY, USA, 328–337
2020
-
[36]
Shiguang Wu, Xin Xin, Pengjie Ren, Zhumin Chen, Jun Ma, Maarten de Rijke, and Zhaochun Ren. 2024. Learning Robust Sequential Recommenders through Confident Soft Labels.ACM Trans. Inf. Syst.43, 1, Article 21 (Dec. 2024), 27 pages
2024
-
[37]
Jinfeng Xu, Zheyu Chen, Shuo Yang, Jinze Li, Wei Wang, Xiping Hu, Steven Hoi, and Edith Ngai. 2025. A Survey on Multimodal Recommender Systems: Recent Advances and Future Directions.arXiv preprint arXiv:2502.15711(2025)
arXiv 2025
-
[38]
Zhengyi Yang, Jiancan Wu, Yanchen Luo, Jizhi Zhang, Yancheng Yuan, An Zhang, Xiang Wang, and Xiangnan He. 2026. Large Language Model Can Interpret Latent Space of Sequential Recommender.ACM Trans. Inf. Syst.44, 3, Article 59 (March 2026), 38 pages
2026
-
[39]
Yu Ye, Junchen Fu, Yu Song, Kaiwen Zheng, and Joemon M Jose. 2025. Are Multimodal Embeddings Truly Beneficial for Recommendation? A Deep Dive into Whole vs. Individual Modalities.arXiv preprint arXiv:2508.07399(2025)
arXiv 2025
-
[40]
Jinghao Zhang, Guofan Liu, Qiang Liu, Shu Wu, and Liang Wang. 2024. Modality-Balanced Learning for Multimedia Recommendation. InProceedings of the 32nd ACM International Conference on Multimedia (MM ’24). Association for Computing Machinery, New York, NY, , Vol. 1, No. 1, Article . Publication date: June 2018. Teach Multimodal Recommendation Model to See ...
2024
-
[41]
Jinghao Zhang, Yanqiao Zhu, Qiang Liu, Mengqi Zhang, Shu Wu, and Liang Wang. 2023. Latent Structure Mining With Contrastive Modality Fusion for Multimedia Recommendation.IEEE Trans. on Knowl. and Data Eng.35, 9 (2023), 9154–9167
2023
-
[42]
Shengzhe Zhang, Liyi Chen, Dazhong Shen, Chao Wang, and Hui Xiong. 2025. Hierarchical Time-Aware Mixture of Experts for Multi-Modal Sequential Recommendation. InProceedings of the ACM on Web Conference 2025 (WWW ’25). Association for Computing Machinery, New York, NY, USA, 3672–3682
2025
-
[43]
Shuai Zhang, Lina Yao, Aixin Sun, and Yi Tay. 2019. Deep Learning Based Recommender System: A Survey and New Perspectives.ACM Comput. Surv.52, 1, Article 5 (Feb. 2019), 38 pages
2019
-
[44]
Xiaokun Zhang, Bo Xu, Fenglong Ma, Chenliang Li, Liang Yang, and Hongfei Lin. 2024. Beyond Co-Occurrence: Multi-Modal Session- Based Recommendation.IEEE Transactions on Knowledge and Data Engineering36, 4 (2024), 1450–1462
2024
-
[45]
Xiaokun Zhang, Bo Xu, Youlin Wu, Yuan Zhong, Hongfei Lin, and Fenglong Ma. 2024. FineRec: Exploring Fine-grained Sequential Recommendation. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’24). Association for Computing Machinery, New York, NY, USA, 1599–1608
2024
-
[46]
Zhilu Zhang and Mert R. Sabuncu. 2018. Generalized cross entropy loss for training deep neural networks with noisy labels. In Proceedings of the 32nd International Conference on Neural Information Processing Systems (NIPS’18). Curran Associates Inc., Red Hook, NY, USA, 8792–8802
2018
-
[47]
Wayne Xin Zhao, Yupeng Hou, et al. 2022. RecBole 2.0: Towards a More Up-to-Date Recommendation Library. InProceedings of the 31st ACM International Conference on Information & Knowledge Management (CIKM ’22). Association for Computing Machinery, New York, NY, USA, 4722–4726
2022
-
[48]
Guorui Zhou, Na Mou, Ying Fan, Qi Pi, Weijie Bian, Chang Zhou, Xiaoqiang Zhu, and Kun Gai. 2019. Deep interest evolution network for click-through rate prediction. InProceedings of the Thirty-Third AAAI Conference on Artificial Intelligence and Thirty-First Innovative Applications of Artificial Intelligence Conference and Ninth AAAI Symposium on Education...
2019
-
[49]
Guorui Zhou, Xiaoqiang Zhu, Chenru Song, Ying Fan, Han Zhu, Xiao Ma, Yanghui Yan, Junqi Jin, Han Li, and Kun Gai. 2018. Deep Interest Network for Click-Through Rate Prediction. InProceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD ’18). Association for Computing Machinery, New York, NY, USA, 1059–1068
2018
-
[50]
Hongyu Zhou, Yinan Zhang, Aixin Sun, and Zhiqi Shen. 2025. Does Multimodality Improve Recommender Systems as Expected? A Critical Analysis and Future Directions.arXiv preprint arXiv:2508.05377(2025)
arXiv 2025
-
[51]
Kun Zhou, Hui Wang, Wayne Xin Zhao, Yutao Zhu, Sirui Wang, Fuzheng Zhang, Zhongyuan Wang, and Ji-Rong Wen. 2020. S3-Rec: Self-Supervised Learning for Sequential Recommendation with Mutual Information Maximization. InProceedings of the 29th ACM International Conference on Information & Knowledge Management (CIKM ’20). Association for Computing Machinery, N...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.