GC-LoRA: Gated Convolutional LoRA for Parameter-Efficient Acoustic Adaptation
Pith reviewed 2026-06-27 12:01 UTC · model grok-4.3
The pith
GC-LoRA attaches a gated convolutional adapter to attention outputs so pretrained speech transformers can model local acoustic patterns with few added parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
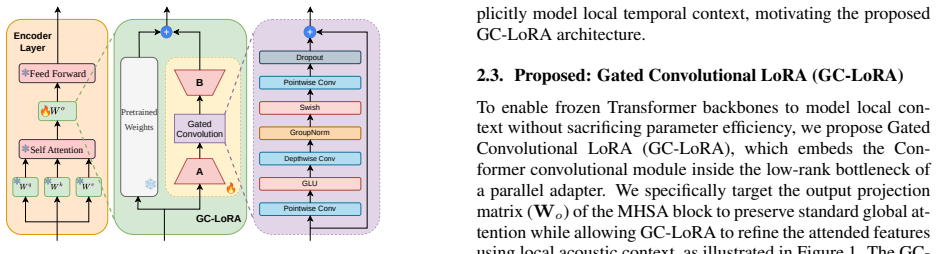
GC-LoRA injects Conformer-style local convolutional processing into pretrained Transformer encoders by means of a lightweight gated adapter applied to the output projections of the attention layers; this captures domain-specific acoustic dependencies without disturbing the pretrained global representations and yields up to 10.9 percent relative WER reduction on acoustically degraded, band-limited, dialectal, and child-speech data while adding only a minimal number of trainable parameters.
What carries the argument
The GC-LoRA adapter: a gated convolutional module placed on attention output projections that supplies local context modeling while the original LoRA handles global attention.
If this is right
- The method produces up to 10.9 percent relative WER reduction on acoustically degraded, band-limited, dialectal, and child speech while adding only a small number of trainable parameters.
- Global attention representations learned during pretraining remain intact because the adapter is added after the attention computation.
- No architectural modifications to the underlying Transformer encoder are required.
- The same adapter design works across multiple acoustic mismatch types without dataset-specific hyperparameter retuning.
Where Pith is reading between the lines
- The same gated-convolution attachment could be tested on other sequence tasks where both local and global structure matter, such as machine translation or music modeling.
- If the adapter proves stable across model scales, it could lower the barrier to deploying a single foundation model on many specialized acoustic conditions.
- One could measure whether the same technique improves performance on non-ASR speech tasks such as speaker verification or emotion recognition under domain shift.
Load-bearing premise
Local convolutional processing can be injected through a lightweight gated adapter attached only to attention outputs without any change to the base model or extensive retuning for each new acoustic domain.
What would settle it
A controlled ablation that removes only the gated convolutional branch from GC-LoRA and measures whether the reported WER gains on the four mismatched test sets disappear.
Figures

read the original abstract
Transformer-based Speech Foundation Models excel in most Automatic Speech Recognition tasks but often suffer performance degradation when applied to domains with mismatched acoustic characteristics. While Parameter Efficient Fine-Tuning (PEFT) methods, such as Low-Rank Adaptation (LoRA), adjust global attention, they lack the local context modeling crucial for capturing domain-specific variations. We propose GC-LoRA, a novel adapter architecture that injects Conformer-style local convolutional processing into pretrained Transformer encoders. By integrating a lightweight adapter to encoder attention output projections, our method efficiently captures local acoustic dependencies without disrupting pretrained global representations. Experiments across diverse datasets (acoustically-degraded, bandlimited, dialectal, child) demonstrate the efficacy of our approach, achieving Word Error Rate (WER) reductions of up to 10.9% compared to baselines while adding minimal trainable parameters.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes GC-LoRA, a gated convolutional adapter inserted into the output projections of attention layers in pretrained Transformer encoders. The method aims to inject Conformer-style local acoustic modeling into global attention representations for domain adaptation in ASR while keeping the number of trainable parameters low. Experiments on four acoustically distinct datasets (degraded, bandlimited, dialectal, child speech) report WER reductions of up to 10.9% relative to baselines.
Significance. If the central claim holds under fixed hyperparameters, the work would offer a practical PEFT technique that augments LoRA with local convolutional processing without base-model changes. The explicit comparison to standard LoRA and the emphasis on minimal added parameters are strengths; however, the absence of statistical testing and hyperparameter controls in the reported results limits the immediate impact.
major comments (3)
- [§4] §4 (Experimental Setup): No information is provided on whether the LoRA rank, convolutional kernel size, gating scale, or learning rate were held constant across the four test regimes or optimized independently for each; this directly affects the load-bearing claim that GC-LoRA functions as a plug-and-play adapter without extensive per-domain retuning.
- [Table 2] Table 2 (Main Results): The reported WER reductions lack accompanying standard deviations, number of runs, or statistical significance tests, making it impossible to determine whether the gains exceed baseline variability.
- [§3.2] §3.2 (Adapter Architecture): The description of how the gated convolution is integrated with the attention output projection does not include an ablation isolating the contribution of the gating mechanism versus a plain convolutional adapter, which is needed to substantiate the design choice.
minor comments (2)
- [Abstract] The abstract states 'up to 10.9%' but does not identify which dataset achieves this figure; adding the specific dataset name would improve clarity.
- [Figure 1] Figure 1 caption should explicitly state the dimensions of the input/output tensors to the GC-LoRA module.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and indicate the revisions that will be incorporated.
read point-by-point responses
-
Referee: §4 (Experimental Setup): No information is provided on whether the LoRA rank, convolutional kernel size, gating scale, or learning rate were held constant across the four test regimes or optimized independently for each; this directly affects the load-bearing claim that GC-LoRA functions as a plug-and-play adapter without extensive per-domain retuning.
Authors: All hyperparameters (LoRA rank, convolutional kernel size, gating scale, and learning rate) were held fixed across the four datasets. We will revise §4 to state this explicitly, list the specific values, and emphasize that no per-domain retuning was performed. revision: yes
-
Referee: Table 2 (Main Results): The reported WER reductions lack accompanying standard deviations, number of runs, or statistical significance tests, making it impossible to determine whether the gains exceed baseline variability.
Authors: Multiple independent runs were not conducted owing to computational constraints. We will add a limitations paragraph noting that all results are from single runs and that statistical significance testing was not performed; the consistent relative gains across acoustically dissimilar domains nevertheless support the reported trends. revision: partial
-
Referee: §3.2 (Adapter Architecture): The description of how the gated convolution is integrated with the attention output projection does not include an ablation isolating the contribution of the gating mechanism versus a plain convolutional adapter, which is needed to substantiate the design choice.
Authors: We will add an ablation study comparing GC-LoRA against an otherwise identical adapter that replaces the gated convolution with a plain convolution, thereby isolating the contribution of the gating mechanism. revision: yes
Circularity Check
No circularity: architectural proposal validated by independent experiments
full rationale
The paper presents GC-LoRA as an architectural modification (gated convolutional adapter on attention projections) whose performance is measured via WER on held-out acoustic domains. No equations, derivations, or first-principles claims appear that reduce reported gains to quantities defined by the fitted parameters themselves. The method is not justified by self-citation chains or uniqueness theorems; it is an empirical engineering proposal whose central claim (local context capture without base-model changes) is tested directly against baselines on distinct datasets. No load-bearing step reduces by construction to its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introduction Recent advances in Automatic Speech Recognition (ASR) have been driven by Speech Foundation Models (SFMs) [1, 2, 3, 4]. SFMs trained on massive datasets, such as Whisper [5], ex- hibit strong zero-shot robustness and establish state-of-the-art performance on standard benchmarks. However, performance often degrades in target domains that diver...
Pith/arXiv arXiv 2026
-
[2]
Methodology We first review the Conformer architecture in Section 2.1 and LoRA in Section 2.2, then introduce the proposed Gated Con- volutional LoRA (GC-LoRA) in Section 2.3. 2.1. The Conformer Block While standard Transformers rely exclusively on multi-head self-attention (MHSA) to capture global sequence context, the Conformer architecture [12] demonst...
-
[3]
L” and “GC
Experiments 3.1. Datasets •AMI [37]:The AMI Meeting Corpus consists of approxi- mately 100 hours of multi-speaker meeting recordings cap- tured with close-talking and far-field microphones, exhibit- ing overlapping speech, background noise, and reverbera- tion. We include AMI to evaluate robustness to environmen- tal acoustic degradation. We utilize the K...
-
[4]
All experi- ments are implemented using the Hugging Face Transformers library [44]
GC-LoRA utilizes a kernel size ofk= 31. All experi- ments are implemented using the Hugging Face Transformers library [44]. Decoding is performed using greedy search, and the Whisper English text normalizer is applied prior to scoring. Statistical significance is computed using the NIST SCTK scor- ing toolkit [45], employing a Matched-Pairs Sentence-Segme...
-
[5]
Results 4.1. Effectiveness of GC-LoRA To evaluate GC-LoRA across acoustic distribution shifts, we se- lect four datasets: MyST (child), AMI (acoustically-degraded), CORAAL (dialectal), and Switchboard (SWBD) (narrowband). Table 1 reports Word Error Rate (WER) using the Whisper- medium backbone. Across all datasets, GC-LoRA consis- tently improves over the...
-
[6]
Conclusion In this work, we introduce GC-LoRA, a structurally informed Parameter Efficient Fine-Tuning approach designed to miti- gate the vulnerability of Transformer-based Speech Founda- tion Models to acoustic distribution shifts. By embedding Conformer-style depthwise-separable convolutions and gating mechanisms directly into the attention output proj...
-
[7]
Department of Education (DoE), through Grant R305C240046 to the U
Acknowledgements This research is supported in part by the National Science Foun- dation (NSF) and the Institute of Education Sciences (IES), U.S. Department of Education (DoE), through Grant R305C240046 to the U. at Buffalo. The opinions expressed are those of the authors and do not represent views of the IES, DoE, or the NSF
-
[8]
All technical content, experimental design, results, and conclusions were produced and verified by the authors
Generative AI Use Disclosure During the preparation of this work, the authors used ChatGPT (GPT-5.2 Thinking) for language editing, including proofread- ing and improving clarity and readability of the manuscript. All technical content, experimental design, results, and conclusions were produced and verified by the authors. After the use of Gen- erative A...
-
[9]
Wavlm: Large-scale self-supervised pre-training for full stack speech processing,
S. Chenet al., “Wavlm: Large-scale self-supervised pre-training for full stack speech processing,”IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1505–1518, 2022
2022
-
[10]
Hubert: Self-supervised speech representation learning by masked prediction of hidden units,
W.-N. Hsuet al., “Hubert: Self-supervised speech representation learning by masked prediction of hidden units,”IEEE/ACM Trans- actions on Audio, Speech, and Language Processing, vol. 29, pp. 3451–3460, 2021
2021
-
[11]
Less is more: Accurate speech recognition & translation without web-scale data,
K. C. Puvvadaet al., “Less is more: Accurate speech recognition & translation without web-scale data,” inINTERSPEECH. ISCA, 2024
2024
-
[12]
OWSM v3.1: Better and faster open whisper-style speech models based on e-branchformer,
Y . Penget al., “OWSM v3.1: Better and faster open whisper-style speech models based on e-branchformer,” inINTERSPEECH. ISCA, 2024
2024
-
[13]
Robust speech recognition via large-scale weak supervision,
A. Radfordet al., “Robust speech recognition via large-scale weak supervision,” inProc. ICML, 2023
2023
-
[14]
Self-supervised Speech Representations Still Struggle with African American Vernacular English,
K. Changet al., “Self-supervised Speech Representations Still Struggle with African American Vernacular English,” inInter- speech 2024, 2024, pp. 4643–4647
2024
-
[15]
The reverb challenge: A common evalua- tion framework for dereverberation and recognition of reverber- ant speech,
K. Kinoshitaet al., “The reverb challenge: A common evalua- tion framework for dereverberation and recognition of reverber- ant speech,” in2013 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics. IEEE, 2013, pp. 1–4
2013
-
[16]
Model synthesis for band-limited speech recognition,
Y . He and J. Han, “Model synthesis for band-limited speech recognition,” inInterspeech 2010, 2010, pp. 558–561
2010
-
[17]
Lanehartet al.,Language use in African American communi- ties
S. Lanehartet al.,Language use in African American communi- ties. Oxford University Press, 2015
2015
-
[18]
Prosodic features of african american english,
E. R. Thomas and S. L. Lanehart, “Prosodic features of african american english,”The Oxford handbook of African American language, pp. 420–438, 2015
2015
-
[19]
Acoustics of children’s speech: Developmental changes of temporal and spectral parameters,
S. Leeet al., “Acoustics of children’s speech: Developmental changes of temporal and spectral parameters,”The Journal of the Acoustical Society of America, vol. 105, no. 3, pp. 1455–1468, 1999
1999
-
[20]
Conformer: Convolution-augmented Trans- former for Speech Recognition,
A. Gulatiet al., “Conformer: Convolution-augmented Trans- former for Speech Recognition,” inInterspeech 2020, 2020, pp. 5036–5040
2020
-
[21]
Open automatic speech recogni- tion leaderboard,
V . Srivastavet al., “Open automatic speech recogni- tion leaderboard,” https://huggingface.co/spaces/hf-audio/ open asr leaderboard, 2023
2023
-
[22]
Parameter-efficient transfer learning for nlp,
N. Houlsbyet al., “Parameter-efficient transfer learning for nlp,” International Conference on Machine Learning, pp. 2790–2799, 2019
2019
-
[23]
DRAFT: A Novel Framework to Reduce Domain Shifting in Self-supervised Learning and Its Application to Children’s ASR,
R. Fan and A. Alwan, “DRAFT: A Novel Framework to Reduce Domain Shifting in Self-supervised Learning and Its Application to Children’s ASR,” inInterspeech 2022, 2022, pp. 4900–4904
2022
-
[24]
Chapter: Exploiting convolutional neural net- work adapters for self-supervised speech models,
Z.-C. Chenet al., “Chapter: Exploiting convolutional neural net- work adapters for self-supervised speech models,”2023 IEEE In- ternational Conference on Acoustics, Speech, and Signal Process- ing Workshops (ICASSPW), pp. 1–5, 2023
2023
-
[25]
A parameter-efficient multi-scale convolu- tional adapter for synthetic speech detection,
Y . E. Kheiret al., “A parameter-efficient multi-scale convolu- tional adapter for synthetic speech detection,”2026 IEEE Inter- national Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2026
2026
-
[26]
Adapter Learning from Pre-trained Model for Ro- bust Spoof Speech Detection,
H. Wuet al., “Adapter Learning from Pre-trained Model for Ro- bust Spoof Speech Detection,” inInterspeech 2024, 2024, pp. 2095–2099
2024
-
[27]
Lora: Low-rank adaptation of large language models,
E. J. Huet al., “Lora: Low-rank adaptation of large language models,”International Conference on Learning Representations, 2021
2021
-
[28]
Bottleneck Low-rank Transform- ers for Low-resource Spoken Language Understanding,
P. Wang and H. Van hamme, “Bottleneck Low-rank Transform- ers for Low-resource Spoken Language Understanding,” inInter- speech 2022, 2022, pp. 1248–1252
2022
-
[29]
Don’t Stop Self-Supervision: Accent Adaptation of Speech Representations via Residual Adapters,
A. Bhatiaet al., “Don’t Stop Self-Supervision: Accent Adaptation of Speech Representations via Residual Adapters,” inInterspeech 2023, 2023, pp. 3362–3366
2023
-
[30]
Sparsely shared lora on whisper for child speech recognition,
W. Liuet al., “Sparsely shared lora on whisper for child speech recognition,”2024 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2024
2024
-
[31]
Ssvd: Structured svd for parameter-efficient fine-tuning and benchmarking under domain shift in asr,
P. Wanget al., “Ssvd: Structured svd for parameter-efficient fine-tuning and benchmarking under domain shift in asr,”arXiv preprint arXiv:2509.02830, 2025
arXiv 2025
-
[32]
Exploring adapters with conformers for children’s automatic speech recognition,
T. Rolland and A. Abad, “Exploring adapters with conformers for children’s automatic speech recognition,” in2024 IEEE Inter- national Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 12 747–12 751
2024
-
[33]
Towards Rehearsal-Free Multilingual ASR: A LoRA-based Case Study on Whisper ,
T. Xuet al., “Towards Rehearsal-Free Multilingual ASR: A LoRA-based Case Study on Whisper ,” inInterspeech 2024, 2024, pp. 2534–2538
2024
-
[34]
LoRA-Whisper: Parameter-Efficient and Exten- sible Multilingual ASR,
Z. Songet al., “LoRA-Whisper: Parameter-Efficient and Exten- sible Multilingual ASR,” inInterspeech 2024, 2024, pp. 3934– 3938
2024
-
[35]
Adaptive budget allocation for parameter- efficient fine-tuning,
Q. Zhanget al., “Adaptive budget allocation for parameter- efficient fine-tuning,” inThe Eleventh International Conference on Learning Representations, 2023
2023
-
[36]
Dora: Weight-decomposed low-rank adapta- tion,
S.-Y . Liuet al., “Dora: Weight-decomposed low-rank adapta- tion,” inForty-first International Conference on Machine Learn- ing, 2024
2024
-
[37]
Flylora: Boosting task decoupling and parameter efficiency via implicit rank-wise mixture-of-experts,
H. Zou, Y . Zang, W. Xu, Y . Zhu, and X. Ji, “Flylora: Boosting task decoupling and parameter efficiency via implicit rank-wise mixture-of-experts,”Advances in Neural Information Processing Systems, vol. 38, pp. 10 386–10 419, 2026
2026
-
[38]
Zipper-lora: Dy- namic parameter decoupling for speech-llm based multilingual speech recognition,
Y . Mei, D. Qiu, S. Liu, J. Liang, and Y . Long, “Zipper-lora: Dy- namic parameter decoupling for speech-llm based multilingual speech recognition,”arXiv preprint arXiv:2603.17558, 2026
arXiv 2026
-
[39]
Convolution-Augmented Parameter-Efficient Fine-Tuning for Speech Recognition,
K. Kim, S. Shon, Y .-T. Hsu, P. Sridhar, K. Livescu, and S. Watan- abe, “Convolution-Augmented Parameter-Efficient Fine-Tuning for Speech Recognition,” inInterspeech 2024, 2024, pp. 2830– 2834
2024
-
[40]
Convolution meets loRA: Parameter efficient finetuning for segment anything model,
Z. Zhonget al., “Convolution meets loRA: Parameter efficient finetuning for segment anything model,” inThe Twelfth Interna- tional Conference on Learning Representations, 2024
2024
-
[41]
Convlora and adabn based domain adaptation via self-training,
S. Aleemet al., “Convlora and adabn based domain adaptation via self-training,” in2024 IEEE International Symposium on Biomed- ical Imaging (ISBI). IEEE, 2024, pp. 1–5
2024
-
[42]
Language modeling with gated convolu- tional networks,
Y . N. Dauphinet al., “Language modeling with gated convolu- tional networks,” inInternational conference on machine learn- ing. PMLR, 2017, pp. 933–941
2017
-
[43]
Searching for activation functions,
P. Ramachandranet al., “Searching for activation functions,” arXiv preprint arXiv:1710.05941, 2017
Pith/arXiv arXiv 2017
-
[44]
Group normalization,
Y . Wu and K. He, “Group normalization,” inProceedings of the European conference on computer vision (ECCV), 2018, pp. 3– 19
2018
-
[45]
The ami meeting corpus,
J. Carletta, “The ami meeting corpus,” inLanguage Resources and Evaluation, vol. 41, no. 2. Springer Science and Business Media LLC, 2005, pp. 181–190
2005
-
[46]
Switchboard: Telephone speech corpus for research and development,
J. J. Godfreyet al., “Switchboard: Telephone speech corpus for research and development,” in1992 IEEE International Con- ference on Acoustics, Speech, and Signal Processing (ICASSP), vol. 1. IEEE, 1992, pp. 517–520
1992
-
[47]
The Corpus of Regional African American Language,
T. Kendall and C. Farrington, “The Corpus of Regional African American Language,” Eugene, OR, 2023. [Online]. Available: https://doi.org/10.7264/1ad5-6t35
-
[48]
An exploratory study on dialect density es- timation for children and adult’s african american english,
A. Johnsonet al., “An exploratory study on dialect density es- timation for children and adult’s african american english,”The Journal of the Acoustical Society of America, vol. 155, no. 4, pp. 2836–2848, 2024
2024
-
[49]
Compositional domain adaptation for auto- matic speech recognition with headwise selective attention merg- ing,
N. B. Shankaret al., “Compositional domain adaptation for auto- matic speech recognition with headwise selective attention merg- ing,”Computer Speech & Language, p. 102012, 2026
2026
-
[50]
My science tutor: A conversational multimedia virtual tutor for elementary school science,
W. Wardet al., “My science tutor: A conversational multimedia virtual tutor for elementary school science,”ACM Transactions on Speech and Language Processing (TSLP), vol. 7, no. 4, pp. 1–29, 2011
2011
-
[51]
Kid-whisper: Towards bridging the performance gap in automatic speech recognition for children vs. adults,
A. Attiaet al., “Kid-whisper: Towards bridging the performance gap in automatic speech recognition for children vs. adults,” in Proc. AAAI/ACM Conference on AI, Ethics, and Society, 2024
2024
-
[52]
Transformers: State-of-the-art natural language processing,
T. Wolfet al., “Transformers: State-of-the-art natural language processing,” inProc. EMNLP: System Demonstrations, 2020
2020
-
[53]
SCTK: The NIST Scoring Toolkit,
J. Fiscus, “SCTK: The NIST Scoring Toolkit,” National Institute of Standards and Technology, 2007, [Software]
2007
-
[54]
Benchmarking children’s asr with supervised and self-supervised speech foundation models,
R. Fanet al., “Benchmarking children’s asr with supervised and self-supervised speech foundation models,” inProc. Interspeech, 2024
2024
-
[55]
Benchmarking Training Paradigms, Dataset Com- position, and Model Scaling for Child ASR in ESPnet,
A. Yinget al., “Benchmarking Training Paradigms, Dataset Com- position, and Model Scaling for Child ASR in ESPnet,” inWork- shop on Child Computer Interaction - WOCCI 2025. ISCA, 2025, pp. 6–10
2025
-
[56]
Analyzing the structure of attention in a transformer language model,
J. Vig and Y . Belinkov, “Analyzing the structure of attention in a transformer language model,” inProceedings of the 2019 ACL Workshop BlackboxNLP: Analyzing and Interpreting Neural Net- works for NLP, Aug. 2019, pp. 63–76
2019
-
[57]
Understanding Self- Attention of Self-Supervised Audio Transformers,
S. wen Yang, A. T. Liu, and H. yi Lee, “Understanding Self- Attention of Self-Supervised Audio Transformers,” inInterspeech 2020, 2020, pp. 3785–3789
2020
-
[58]
Branchformer: Parallel mlp-attention architectures to capture local and global context for speech recognition and un- derstanding,
Y . Penget al., “Branchformer: Parallel mlp-attention architectures to capture local and global context for speech recognition and un- derstanding,” inInternational Conference on Machine Learning. PMLR, 2022, pp. 17 627–17 643
2022
-
[59]
Understanding the role of self attention for efficient speech recognition,
K. Shim, J. Choi, and W. Sung, “Understanding the role of self attention for efficient speech recognition,” inInternational Con- ference on Learning Representations, 2022
2022
-
[60]
MULTI- CONVFORMER: Extending Conformer with Multiple Convolu- tion Kernels,
D. Prabhu, Y . Peng, P. Jyothi, and S. Watanabe, “MULTI- CONVFORMER: Extending Conformer with Multiple Convolu- tion Kernels,” inInterspeech 2024, 2024, pp. 232–236
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.