Efficient Graph Indexing for Interval-Aware Vector Search
Pith reviewed 2026-06-27 07:48 UTC · model grok-4.3
The pith
A single graph index can handle multiple interval-aware vector search workloads by preserving both monotonic searchability and structural heredity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
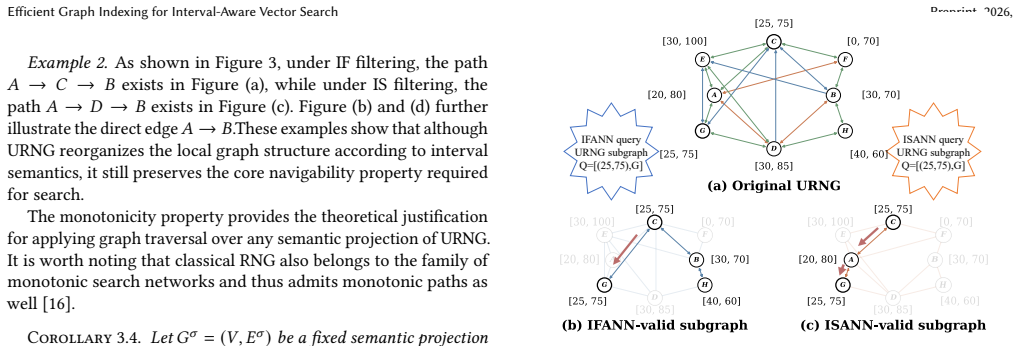
URNG is a graph structure that maintains the monotonic searchability of relative-neighborhood-graph indexes while additionally ensuring structural heredity over query-induced subgraphs. This property lets one index support multiple interval-aware query semantics. UG approximates URNG via unified interval-aware pruning and iterative repair, and a matching query algorithm delivers the results.
What carries the argument
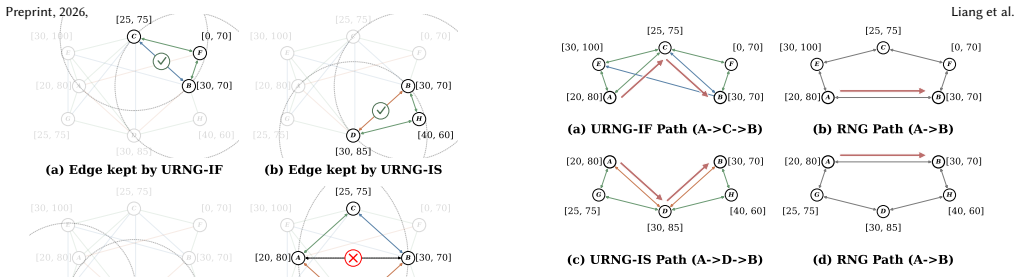
URNG (Unified Interval-aware Relative Neighborhood Graph), which adds structural heredity to standard RNG monotonicity so that subgraphs induced by interval constraints remain searchable.
If this is right
- Applications no longer need to store and maintain multiple graph indexes for different interval query types.
- Index construction time and memory footprint remain comparable to a conventional RNG index.
- The same index structure works for interval-filtered, interval-range, and other interval-aware workloads without retraining.
- Query processing can switch semantics at runtime by selecting the appropriate subgraph.
Where Pith is reading between the lines
- The heredity property might allow the same index to support dynamic addition of new interval constraints without full reconstruction.
- If the repair process scales linearly, the method could apply to streaming data settings where intervals arrive online.
- Similar unification might be possible for other constraint families such as categorical or spatial filters.
Load-bearing premise
The proposed pruning and repair steps preserve structural heredity without hurting accuracy or speed for the tested workloads.
What would settle it
A direct comparison on one of the five datasets where UG returns measurably lower recall than a specialized single-semantics index at the same latency.
Figures






read the original abstract
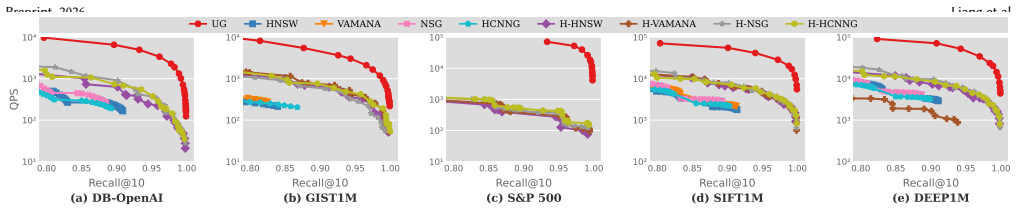
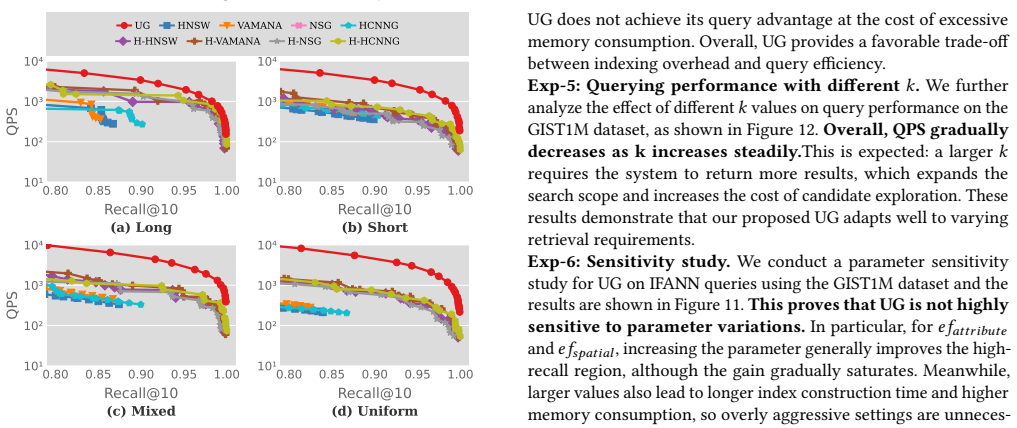
Interval-aware Approximate Nearest Neighbor (ANN) search arises in applications where each object is associated with a numeric value or interval, and queries must satisfy both vector-similarity and interval constraints. Existing methods are typically tailored to a single query semantics, such as interval-filtered ANN search, and therefore require multiple specialized indexes to support diverse workloads, leading to substantial indexing and memory overhead. To address this limitation, we propose the Unified Interval-aware Relative Neighborhood Graph (URNG), a unified graph framework for interval-aware ANN search. URNG preserves the monotonic searchability of relative-neighborhood-graph based ANN indexes while additionally ensuring structural heredity over query-induced subgraphs, enabling a single index to support multiple interval-aware query semantics. Building on this framework, we develop UG, a practical graph index that efficiently approximates URNG through unified interval-aware pruning and iterative repair, together with a query algorithm for interval-aware ANN search. Extensive experiments on 5 datasets show that UG consistently achieves a strong accuracy-efficiency trade-off across diverse interval-aware workloads while maintaining competitive index construction cost and memory usage.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Unified Interval-aware Relative Neighborhood Graph (URNG) framework for interval-aware approximate nearest neighbor search. URNG is claimed to preserve the monotonic searchability of standard RNG-based ANN indexes while adding structural heredity over query-induced subgraphs, enabling a single index to support multiple interval-aware query semantics. A practical approximation called UG is constructed via unified interval-aware pruning and iterative repair, accompanied by a query algorithm. Experiments on 5 datasets are reported to demonstrate a strong accuracy-efficiency trade-off across workloads with competitive construction cost and memory usage.
Significance. If the central claims on preservation of monotonic searchability and maintenance of structural heredity hold under the proposed construction, the work is significant for database systems handling hybrid vector and interval queries. It directly addresses the overhead of deploying multiple specialized indexes by offering a unified graph structure, which could reduce memory footprint and construction time in relevant applications. The experimental support across multiple datasets, if methodologically sound, adds practical value to the contribution.
minor comments (3)
- [Abstract] Abstract: The central notion of 'structural heredity' is referenced as enabling support for multiple query semantics but lacks even a brief formal characterization or property statement; adding this would clarify the load-bearing distinction from standard RNG indexes.
- The description of UG construction via 'unified interval-aware pruning and iterative repair' is high-level; a concrete algorithmic outline or pseudocode in an early section would help verify that the approximation does not violate the heredity property.
- Experiments are stated to cover 5 datasets with competitive results, but without naming the datasets, their sizes, interval distributions, or baseline methods, assessing the generality of the accuracy-efficiency claims is difficult.
Simulated Author's Rebuttal
We thank the referee for the positive summary of our work on the URNG framework and UG index, as well as for recognizing its potential significance in supporting hybrid vector and interval queries with a single index structure. The recommendation for minor revision is noted. However, the report contains no specific major comments requiring point-by-point response.
Circularity Check
No significant circularity
full rationale
The paper introduces URNG as a new unified graph framework that extends monotonic searchability from RNG-based indexes with the additional property of structural heredity over query-induced subgraphs. No equations, parameter fits, or definitions are shown that reduce the claimed properties to inputs by construction. The derivation relies on the stated framework design, unified pruning, iterative repair, and experimental results on 5 datasets rather than self-referential reductions, self-citation chains, or renamed known results. The central claim remains independent of its own outputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Akhil Arora, Sakshi Sinha, Piyush Kumar, and Arnab Bhattacharya. 2018. Hd- index: Pushing the scalability-accuracy boundary for approximate knn search in high-dimensional spaces.arXiv preprint arXiv:1804.06829(2018)
Pith/arXiv arXiv 2018
-
[2]
Martin Aumüller, Erik Bernhardsson, and Alexander Faithfull. 2020. ANN- Benchmarks: A benchmarking tool for approximate nearest neighbor algorithms. Information Systems87 (2020), 101374
2020
-
[3]
Ilias Azizi, Karima Echihabi, and Themis Palpanas. 2025. Graph-based vector search: An experimental evaluation of the state-of-the-art.Proceedings of the ACM on Management of Data3, 1 (2025), 1–31
2025
-
[4]
nearest neighbor
Kevin Beyer, Jonathan Goldstein, Raghu Ramakrishnan, and Uri Shaft. 1999. When is “nearest neighbor” meaningful?. InInternational Conference on Database Theory. Springer, 217–235
1999
-
[5]
Alina Beygelzimer, Sham Kakade, and John Langford. 2006. Cover trees for nearest neighbor. InProceedings of the 23rd International Conference on Machine Efficient Graph Indexing for Interval-Aware Vector Search Preprint, 2026, Learning. 97–104
2006
-
[6]
Markus M Breunig, Hans-Peter Kriegel, Raymond T Ng, and Jörg Sander. 2000. LOF: identifying density-based local outliers. InProceedings of the 2000 ACM SIGMOD International Conference on Management of Data. 93–104
2000
-
[7]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners.Advances in Neural Information Processing Systems33 (2020), 1877–1901
2020
-
[8]
Yannis Chronis, Helena Caminal, Yannis Papakonstantinou, Fatma Özcan, and Anastasia Ailamaki. 2025. Filtered vector search: State-of-the-art and research opportunities.Proceedings of the VLDB Endowment18, 12 (2025), 5488–5492
2025
-
[9]
Thomas Cover and Peter Hart. 1967. Nearest neighbor pattern classification. IEEE Transactions on Information Theory13, 1 (1967), 21–27
1967
-
[10]
Magdalen Dobson, Zheqi Shen, Guy E Blelloch, Laxman Dhulipala, Yan Gu, Har- sha Vardhan Simhadri, and Yihan Sun. 2023. Scaling graph-based anns algorithms to billion-size datasets: A comparative analysis.arXiv preprint arXiv:2305.04359 (2023)
arXiv 2023
-
[11]
Matthijs Douze, Alexandr Guzhva, Chengqi Deng, Jeff Johnson, Gergely Szilvasy, Pierre-Emmanuel Mazaré, Maria Lomeli, Lucas Hosseini, and Hervé Jégou. 2025. The faiss library.IEEE Transactions on Big Data(2025)
2025
-
[12]
Joshua Engels, Benjamin Landrum, Shangdi Yu, Laxman Dhulipala, and Julian Shun. 2024. Approximate nearest neighbor search with window filters.arXiv preprint arXiv:2402.00943(2024)
arXiv 2024
-
[13]
Martin Ester, Hans-Peter Kriegel, Jörg Sander, Xiaowei Xu, et al. 1996. A density- based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining (KDD-96), Vol. 96. 226–231
1996
-
[14]
Steven Fortune. 2017. Voronoi diagrams and Delaunay triangulations. InHand- book of Discrete and Computational Geometry. Chapman and Hall/CRC, 705–721
2017
-
[15]
Cong Fu, Changxu Wang, and Deng Cai. 2021. High dimensional similarity search with satellite system graph: Efficiency, scalability, and unindexed query compatibility.IEEE Transactions on Pattern Analysis and Machine Intelligence44, 8 (2021), 4139–4150
2021
-
[16]
Cong Fu, Chao Xiang, Changxu Wang, and Deng Cai. 2017. Fast approximate nearest neighbor search with the navigating spreading-out graph.arXiv preprint arXiv:1707.00143(2017)
arXiv 2017
-
[17]
Jianyang Gao and Cheng Long. 2024. Rabitq: Quantizing high-dimensional vectors with a theoretical error bound for approximate nearest neighbor search. Proceedings of the ACM on Management of Data2, 3 (2024), 1–27
2024
-
[18]
Tiezheng Ge, Kaiming He, Qifa Ke, and Jian Sun. 2013. Optimized product quantization.IEEE Transactions on Pattern Analysis and Machine Intelligence36, 4 (2013), 744–755
2013
-
[19]
Siddharth Gollapudi, Neel Karia, Varun Sivashankar, Ravishankar Krishnaswamy, Nikit Begwani, Swapnil Raz, Yiyong Lin, Yin Zhang, Neelam Mahapatro, Premku- mar Srinivasan, et al. 2023. Filtered-diskann: Graph algorithms for approximate nearest neighbor search with filters. InProceedings of the ACM Web Conference
2023
-
[20]
Yunchao Gong, Svetlana Lazebnik, Albert Gordo, and Florent Perronnin. 2012. Iterative quantization: A procrustean approach to learning binary codes for large-scale image retrieval.IEEE Transactions on Pattern Analysis and Machine Intelligence35, 12 (2012), 2916–2929
2012
-
[21]
Gaurav Gupta, Jonah Yi, Benjamin Coleman, Chen Luo, Vihan Lakshman, and An- shumali Shrivastava. 2023. Caps: A practical partition index for filtered similarity search.arXiv preprint arXiv:2308.15014(2023)
arXiv 2023
-
[22]
Ben Harwood and Tom Drummond. 2016. Fanng: Fast approximate nearest neighbour graphs. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 5713–5722
2016
-
[23]
Piotr Indyk and Rajeev Motwani. 1998. Approximate nearest neighbors: towards removing the curse of dimensionality. InProceedings of the Thirtieth Annual ACM Symposium on Theory of Computing. 604–613
1998
-
[24]
Suhas Jayaram Subramanya, Fnu Devvrit, Harsha Vardhan Simhadri, Ravishankar Krishnawamy, and Rohan Kadekodi. 2019. DiskANN: Fast Accurate Billion-point Nearest Neighbor Search on a Single Node. InAdvances in Neural Information Processing Systems, H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alché-Buc, E. Fox, and R. Garnett (Eds.), Vol. 32. Curran Asso...
2019
-
[25]
Herve Jegou, Matthijs Douze, and Cordelia Schmid. 2010. Product quantization for nearest neighbor search.IEEE Transactions on Pattern Analysis and Machine Intelligence33, 1 (2010), 117–128
2010
-
[26]
Joseph B Kruskal. 1956. On the shortest spanning subtree of a graph and the traveling salesman problem.Proc. Amer. Math. Soc.7, 1 (1956), 48–50
1956
-
[27]
Yann LeCun, Yoshua Bengio, and Geoffrey Hinton. 2015. Deep learning.Nature 521, 7553 (2015), 436–444
2015
-
[28]
Jie Li, Haifeng Liu, Chuanghua Gui, Jianyu Chen, Zhenyuan Ni, Ning Wang, and Yuan Chen. 2018. The design and implementation of a real time visual search system on JD E-commerce platform. InProceedings of the 19th International Middleware Conference Industry. 9–16
2018
-
[29]
Mocheng Li, Xiao Yan, Baotong Lu, Yue Zhang, James Cheng, and Chenhao Ma
-
[30]
Attribute Filtering in Approximate Nearest Neighbor Search: An In-depth Experimental Study.Proceedings of the ACM on Management of Data3, 6 (2025), 1–26
2025
-
[31]
Wen Li, Ying Zhang, Yifang Sun, Wei Wang, Mingjie Li, Wenjie Zhang, and Xuemin Lin. 2019. Approximate nearest neighbor search on high dimensional data—experiments, analyses, and improvement.IEEE Transactions on Knowledge and Data Engineering32, 8 (2019), 1475–1488
2019
-
[32]
Anqi Liang, Pengcheng Zhang, Bin Yao, Zhongpu Chen, Yitong Song, and Guangxu Cheng. 2024. Unify: Unified index for range filtered approximate nearest neighbors search.arXiv preprint arXiv:2412.02448(2024)
arXiv 2024
-
[33]
Siyuan Liang, Ziqi Yin, Qi Zhang, Rong hua Li, Guoren Wang, Kaiwen Xue, Daiyin Wang, and Xubin Li. 2026. One Index is All You Need: A Unified Graph Index for Interval-Aware Approximate Nearest Neighbor Search: Full Version. https://github.com/bbtsrr/UG-submit. Full version
2026
-
[34]
Ying Liu, Dengsheng Zhang, Guojun Lu, and Wei-Ying Ma. 2007. A survey of content-based image retrieval with high-level semantics.Pattern Recognition40, 1 (2007), 262–282
2007
-
[35]
Yury Malkov, Alexander Ponomarenko, Andrey Logvinov, and Vladimir Krylov
-
[36]
Approximate nearest neighbor algorithm based on navigable small world graphs.Information Systems45 (2014), 61–68
2014
-
[37]
Yu A Malkov and Dmitry A Yashunin. 2018. Efficient and robust approximate nearest neighbor search using hierarchical navigable small world graphs.IEEE Transactions on Pattern Analysis and Machine Intelligence42, 4 (2018), 824–836
2018
-
[38]
Yusuke Matsui, Yusuke Uchida, Hervé Jégou, and Shin’ichi Satoh. 2018. A survey of product quantization.ITE Transactions on Media Technology and Applications 6, 1 (2018), 2–10
2018
-
[39]
James Jie Pan, Jianguo Wang, and Guoliang Li. 2023. Survey of vector database management systems.arXiv preprint arXiv:2310.14021(2023)
arXiv 2023
-
[40]
James Jie Pan, Jianguo Wang, and Guoliang Li. 2024. Vector database management techniques and systems. InCompanion of the 2024 International Conference on Management of Data. 597–604
2024
-
[41]
Rodrigo Paredes and Edgar Chávez. 2005. Using the k-nearest neighbor graph for proximity searching in metric spaces. InInternational Symposium on String Processing and Information Retrieval. Springer, 127–138
2005
-
[42]
Liana Patel, Peter Kraft, Carlos Guestrin, and Matei Zaharia. 2024. Acorn: Perfor- mant and predicate-agnostic search over vector embeddings and structured data. Proceedings of the ACM on Management of Data2, 3 (2024), 1–27
2024
-
[43]
Zhencan Peng, Miao Qiao, Wenchao Zhou, Feifei Li, and Dong Deng. 2025. Dy- namic Range-Filtering Approximate Nearest Neighbor Search.Proceedings of the VLDB Endowment18, 10 (2025)
2025
-
[44]
Ninh Pham and Tao Liu. 2022. Falconn++: A locality-sensitive filtering approach for approximate nearest neighbor search.Advances in Neural Information Pro- cessing Systems35 (2022), 31186–31198
2022
-
[45]
Parikshit Ram and Kaushik Sinha. 2019. Revisiting kd-tree for nearest neigh- bor search. InProceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 1378–1388
2019
-
[46]
Nils Reimers and Iryna Gurevych. 2019. Sentence-bert: Sentence embeddings using siamese bert-networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 3982–3992
2019
-
[47]
Badrul Sarwar, George Karypis, Joseph Konstan, and John Riedl. 2001. Item-based collaborative filtering recommendation algorithms. InProceedings of the 10th International Conference on World Wide Web. 285–295
2001
-
[48]
Godfried T Toussaint. 1980. The relative neighbourhood graph of a finite planar set.Pattern Recognition12, 4 (1980), 261–268
1980
-
[49]
Gonçalves, Zanoni Dias, and Ricardo da S
Javier Vargas Muñoz, Marcos A. Gonçalves, Zanoni Dias, and Ricardo da S. Torres
-
[50]
Pattern Recognition40, 2110–2117 (2007).https://doi.org/10.1016/j.patcog
Hierarchical Clustering-Based Graphs for Large Scale Approximate Nearest Neighbor Search.Pattern Recognition96 (2019), 106970. doi:10.1016/j.patcog. 2019.106970
-
[51]
Jingdong Wang, Heng Tao Shen, Jingkuan Song, and Jianqiu Ji. 2014. Hashing for similarity search: A survey.arXiv preprint arXiv:1408.2927(2014)
Pith/arXiv arXiv 2014
-
[52]
Jianguo Wang, Xiaomeng Yi, Rentong Guo, Hai Jin, Peng Xu, Shengjun Li, Xi- angyu Wang, Xiangzhou Guo, Chengming Li, Xiaohai Xu, et al. 2021. Milvus: A purpose-built vector data management system. InProceedings of the 2021 International Conference on Management of Data. 2614–2627
2021
-
[53]
Jingdong Wang, Ting Zhang, Nicu Sebe, Heng Tao Shen, et al. 2017. A survey on learning to hash.IEEE Transactions on Pattern Analysis and Machine Intelligence 40, 4 (2017), 769–790
2017
-
[54]
Mengzhao Wang, Xiaoliang Xu, Qiang Yue, and Yuxiang Wang. 2021. A com- prehensive survey and experimental comparison of graph-based approximate nearest neighbor search.arXiv preprint arXiv:2101.12631(2021)
arXiv 2021
-
[55]
Yuxiang Wang, Ziyuan He, Yongxin Tong, Zimu Zhou, and Yiman Zhong. 2025. Timestamp Approximate Nearest Neighbor Search over High-Dimensional Vector Data. In2025 IEEE 41st International Conference on Data Engineering (ICDE). IEEE, 3043–3055
2025
-
[56]
Roger Weber, Hans-Jörg Schek, Stephen Blott, et al. 1998. A quantitative analysis and performance study for similarity-search methods in high-dimensional spaces. InVLDB ’98: Proceedings of the 24th International Conference on Very Large Data Bases, Vol. 98. 194–205. Preprint, 2026, Liang et al
1998
-
[57]
Chuangxian Wei, Bin Wu, Sheng Wang, Renjie Lou, Chaoqun Zhan, Feifei Li, and Yuanzhe Cai. 2020. AnalyticDB-V: A Hybrid Analytical Engine Towards Query Fusion for Structured and Unstructured Data.Proceedings of the VLDB Endowment13, 12 (2020), 3152–3165
2020
-
[58]
Jiadong Xie, Jeffrey Xu Yu, Siyi Teng, and Yingfan Liu. 2025. Beyond Vector Search: Querying With and Without Predicates.Proceedings of the ACM on Management of Data3, 6 (2025), 1–26
2025
-
[59]
Yuexuan Xu, Jianyang Gao, Yutong Gou, Cheng Long, and Christian S Jensen
-
[60]
irangegraph: Improvising range-dedicated graphs for range-filtering nearest neighbor search.Proceedings of the ACM on Management of Data2, 6 (2024), 1–26
2024
-
[61]
Ming Yang, Yuzheng Cai, and Weiguo Zheng. 2025. Hi-PNG: Efficient Interval- Filtering ANNS via Hierarchical Interval Partition Navigating Graph. InProceed- ings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 3518–3529
2025
-
[62]
Ziqi Yin, Gao Cong, Kai Zeng, Jinwei Zhu, and Bin Cui. 2026. BBC: Improv- ing Large-k Approximate Nearest Neighbor Search with a Bucket-based Result Collector. arXiv:2604.01960 [cs.DB] https://arxiv.org/abs/2604.01960
Pith/arXiv arXiv 2026
-
[63]
Ziqi Yin, Shanshan Feng, Shang Liu, Gao Cong, Yew Soon Ong, and Bin Cui
-
[64]
arXiv:2403.07331 [cs.IR] https://arxiv.org/abs/2403.07331
LIST: Learning to Index Spatio-Textual Data for Embedding based Spatial Keyword Queries. arXiv:2403.07331 [cs.IR] https://arxiv.org/abs/2403.07331
-
[65]
Ziqi Yin, Jianyang Gao, Pasquale Balsebre, Gao Cong, and Cheng Long. 2025. DEG: Efficient Hybrid Vector Search Using the Dynamic Edge Navigation Graph. Proc. ACM Manag. Data3, 1, Article 29 (Feb. 2025), 28 pages. doi:10.1145/3709679
-
[66]
Fangyuan Zhang, Mengxu Jiang, Guanhao Hou, Jieming Shi, Hua Fan, Wenchao Zhou, Feifei Li, and Sibo Wang. 2025. Efficient Dynamic Indexing for Range Filtered Approximate Nearest Neighbor Search.Proceedings of the ACM on Management of Data3, 3 (2025), 1–26
2025
-
[67]
Qianxi Zhang, Shuotao Xu, Qi Chen, Guoxin Sui, Jiadong Xie, Zhizhen Cai, Yaoqi Chen, Yinxuan He, Yuqing Yang, Fan Yang, Mao Yang, and Lidong Zhou. 2023. VBASE: Unifying Online Vector Similarity Search and Relational Queries via Relaxed Monotonicity. In17th USENIX Symposium on Operating Systems Design and Implementation (OSDI 23). USENIX Association, Bosto...
2023
-
[68]
Penghao Zhao, Hailin Zhang, Qinhan Yu, Zhengren Wang, Yunteng Geng, Fangcheng Fu, Ling Yang, Wentao Zhang, Jie Jiang, and Bin Cui. 2026. Retrieval- augmented generation for ai-generated content: A survey.Data Science and Engineering(2026), 1–29
2026
-
[69]
Zhiqiu Zou, Ziqi Yin, Rong-Hua Li, Hongchao Qin, Qiangqiang Dai, and Guoren Wang. 2026. RNSG: A Range-Aware Graph Index for Efficient Range-Filtered Approximate Nearest Neighbor Search. arXiv:2603.12913 [cs.DB] https://arxiv. org/abs/2603.12913
Pith/arXiv arXiv 2026
-
[70]
Chaoji Zuo, Miao Qiao, Wenchao Zhou, Feifei Li, and Dong Deng. 2024. Serf: Seg- ment graph for range-filtering approximate nearest neighbor search.Proceedings of the ACM on Management of Data2, 1 (2024), 1–26. A Proofs for the Complexity Analysis Lemma A.1 (Expected length of a monotonic path).For any starting node 𝑥∈𝑉 and the interval-aware nearest neigh...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.