Action-Effect Memory Pretraining for Robot Manipulation
Pith reviewed 2026-06-27 09:20 UTC · model grok-4.3
The pith
AEM pretraining learns compact temporal representations from vision-action histories via masked modeling to improve robot manipulation under partial observability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
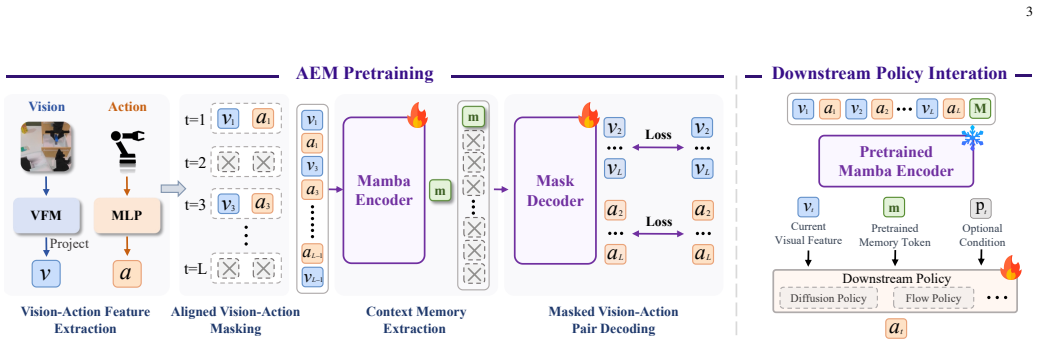
AEM is an Action-Effect Memory pretraining framework that models manipulation as an action-driven interaction process. By interleaving visual and action features and applying masked modeling to recover missing content from incomplete histories, it learns compact temporal representations. The Mamba-encoded output of the final vision token is used as a compact history representation serving as the global context for decoding and downstream control with Diffusion Policy and Flow Policy, consistently improving performance over baselines.
What carries the argument
Action-Effect Memory (AEM) pretraining: interleaving visual and action features with masked modeling on incomplete histories, where the Mamba-encoded final vision token provides the compact single-vector temporal representation for global context.
If this is right
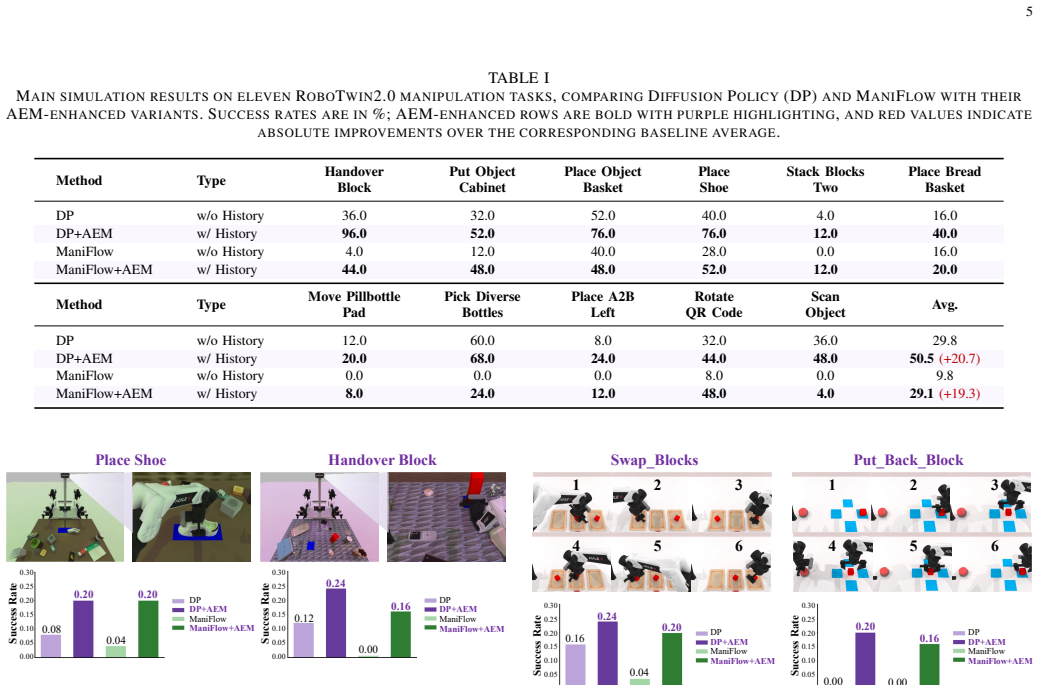
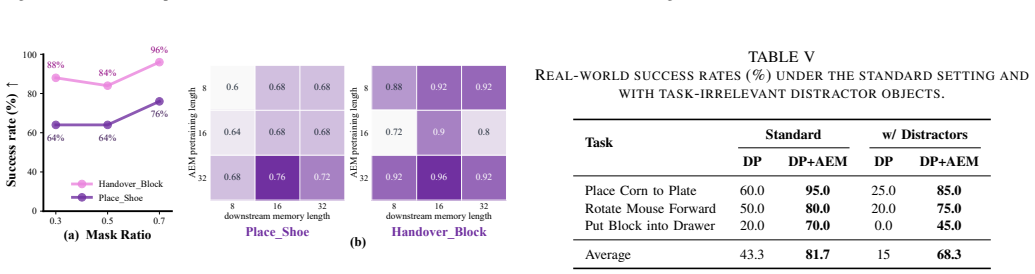
- AEM improves manipulation performance in both simulation and real-world settings with Diffusion Policy and Flow Policy.
- It outperforms baselines across clean scenes, cluttered and random scenes, and non-Markovian tasks.
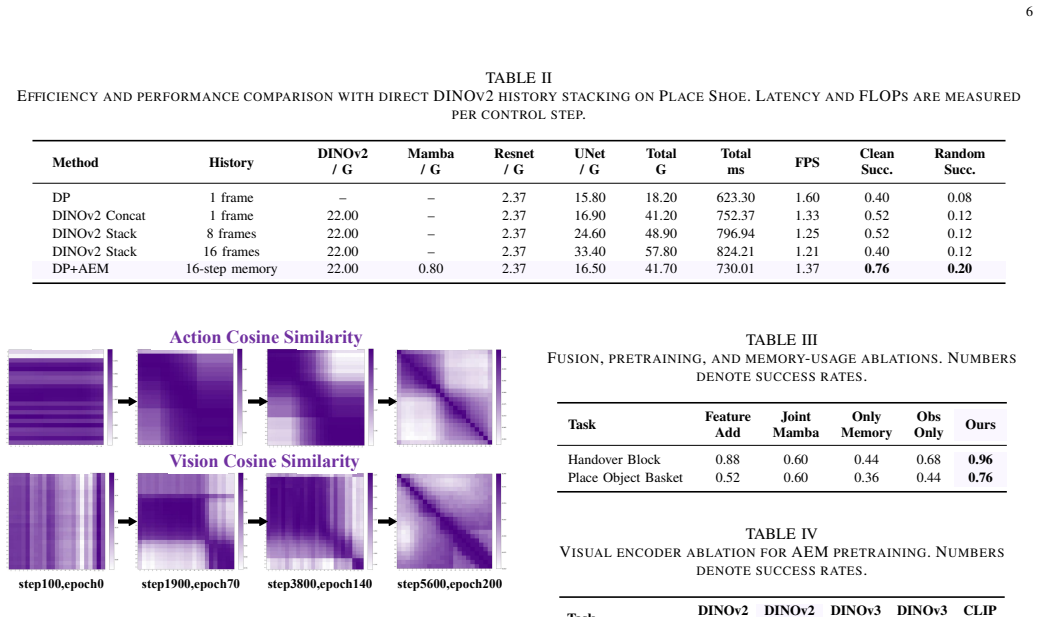
- History-aware pretraining surpasses single-frame pretraining and direct frame stacking.
- The approach reduces inference latency and computational cost while preserving a single-vector temporal bottleneck.
Where Pith is reading between the lines
- The compact representation might scale to longer action sequences or multi-robot coordination where memory of past effects is critical.
- Similar interleaving and masking could be tested on other sequence architectures to compare efficiency with Mamba.
- Integration with online fine-tuning might address distribution shifts in real deployments not covered in the evaluations.
Load-bearing premise
The design choice that the Mamba-encoded output of the final vision token after masked modeling on interleaved histories provides an effective global context for decoding and downstream control without losing critical temporal information.
What would settle it
A controlled experiment showing no improvement or a performance drop for AEM-pretrained policies versus single-frame baselines on a non-Markovian task requiring recall of action effects over multiple timesteps.
Figures



read the original abstract
We present AEM, an Action-Effect Memory pretraining framework for robot manipulation that learns compact temporal representations from vision-action history. Unlike prior robot representation pretraining methods that mainly focus on single-frame visual encoding, AEM targets the temporal nature of manipulation, where the current observation alone is often insufficient under partial observability. AEM models manipulation as an action-driven interaction process by interleaving visual and action features and applying masked modeling to recover missing content from incomplete histories, thereby learning action-conditioned state evolution. The Mamba-encoded output of the final vision token is used as a compact history representation, serving as the global context for decoding and downstream control. This design preserves a single-vector temporal bottleneck while keeping inference efficient. We evaluate AEM with Diffusion Policy and Flow Policy. AEM consistently improves manipulation performance in both simulation and real-world settings, outperforming baselines across clean scenes, cluttered and random scenes, and non-Markovian tasks. Ablation studies further show that history-aware pretraining surpasses single-frame pretraining and direct frame stacking, while reducing inference latency and computational cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AEM, an Action-Effect Memory pretraining framework for robot manipulation. It interleaves visual and action features from history, applies masked modeling to recover missing content and learn action-conditioned state evolution, then uses the Mamba-encoded output of the final vision token as a compact single-vector temporal representation for global context in decoding and downstream control with Diffusion Policy and Flow Policy. The central claim is that this history-aware pretraining consistently improves manipulation performance over baselines in both simulation and real-world settings across clean, cluttered/random scenes and non-Markovian tasks, while also reducing inference latency compared to single-frame pretraining or direct frame stacking.
Significance. If the empirical gains and efficiency claims hold with proper controls, the work could advance representation learning for partially observable manipulation by explicitly modeling action-driven temporal evolution rather than relying on single-frame encodings, offering a practical single-vector bottleneck that preserves efficiency for real-time policies.
major comments (2)
- [Abstract] Abstract: the central claim that 'AEM consistently improves manipulation performance... outperforming baselines' is stated without any quantitative metrics, success rates, dataset sizes, number of trials, or ablation numbers. This absence makes the performance improvement unverifiable from the supplied text and prevents assessment of effect sizes or statistical significance.
- [Abstract] Abstract: the design choice that 'the Mamba-encoded output of the final vision token is used as a compact history representation' is presented as effective for preserving temporal information without loss, but no supporting derivation, loss formulation, or comparison to alternatives (e.g., full-sequence encoding or attention-based aggregation) is supplied to evaluate whether critical temporal details are retained under partial observability.
Simulated Author's Rebuttal
We thank the referee for their review and constructive feedback on the abstract of our manuscript. We address each major comment below with specific responses and indicate whether revisions will be made.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'AEM consistently improves manipulation performance... outperforming baselines' is stated without any quantitative metrics, success rates, dataset sizes, number of trials, or ablation numbers. This absence makes the performance improvement unverifiable from the supplied text and prevents assessment of effect sizes or statistical significance.
Authors: We acknowledge that the abstract, constrained by length, omits specific numerical results. The full manuscript reports these details in Sections 4 and 5, including success rates across simulation and real-world tasks, dataset sizes, trial counts, and ablation outcomes with comparisons to baselines. To improve verifiability, we will revise the abstract to include one or two key quantitative improvements (e.g., average success rate gains) while preserving readability. revision: yes
-
Referee: [Abstract] Abstract: the design choice that 'the Mamba-encoded output of the final vision token is used as a compact history representation' is presented as effective for preserving temporal information without loss, but no supporting derivation, loss formulation, or comparison to alternatives (e.g., full-sequence encoding or attention-based aggregation) is supplied to evaluate whether critical temporal details are retained under partial observability.
Authors: The abstract summarizes the approach; the full paper details the masked modeling objective on interleaved vision-action sequences to learn action-conditioned state evolution (Section 3), the Mamba choice for efficient long-range temporal modeling, and the single-vector bottleneck rationale for downstream policy efficiency. Ablations in Section 5 compare against single-frame pretraining and frame stacking, showing benefits for non-Markovian and partially observable tasks. Direct comparisons to full-sequence encoding or attention aggregation are not included, but the provided baselines address the core efficiency and temporal modeling questions. revision: no
Circularity Check
No significant circularity identified
full rationale
The abstract and available description present AEM as an independent pretraining architecture choice (interleaved vision-action masked modeling, Mamba-encoded final vision token as history bottleneck) whose performance gains are reported as empirical outcomes on downstream policies. No equations, parameter-fitting steps, or self-citations appear that would reduce any claimed prediction or result to a quantity defined by the method itself. The framework is not shown to be tautological with its inputs; the central modeling decisions remain external to the reported improvements.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Masked modeling on incomplete vision-action histories learns useful action-conditioned state representations.
Reference graph
Works this paper leans on
-
[1]
Dynamo: In- domain dynamics pretraining for visuo-motor control,
Z. J. Cui, H. Pan, A. Iyer, S. Haldar, and L. Pinto, “Dynamo: In- domain dynamics pretraining for visuo-motor control,”Advances in Neural Information Processing Systems, pp. 33 933–33 961, 2024
2024
-
[2]
Hrp: Human affordances for robotic pre-training,
M. K. Srirama, S. Dasari, S. Bahl, and A. Gupta, “Hrp: Human affordances for robotic pre-training,”arXiv preprint arXiv:2407.18911, 2024
arXiv 2024
-
[3]
3d- mvp: 3d multiview pretraining for manipulation,
S. Qian, K. Mo, V . Blukis, D. F. Fouhey, D. Fox, and A. Goyal, “3d- mvp: 3d multiview pretraining for manipulation,” inProceedings of the Computer Vision and Pattern Recognition Conference (CVPR), 2025, pp. 22 530–22 539
2025
-
[4]
Vip: Towards universal visual reward and representation via value- implicit pre-training,
Y . J. Ma, S. Sodhani, D. Jayaraman, O. Bastani, V . Kumar, and A. Zhang, “Vip: Towards universal visual reward and representation via value- implicit pre-training,”arXiv preprint arXiv:2210.00030, 2022
Pith/arXiv arXiv 2022
-
[5]
Robot learning with sensorimotor pre-training,
I. Radosavovic, B. Shi, L. Fu, K. Goldberg, T. Darrell, and J. Malik, “Robot learning with sensorimotor pre-training,” inConference on Robot Learning (CoRL), 2023, pp. 683–693
2023
-
[6]
R3m: A universal visual representation for robot manipulation,
S. Nair, A. Rajeswaran, V . Kumar, C. Finn, and A. Gupta, “R3m: A universal visual representation for robot manipulation,” inConference on Robot Learning (CoRL), 2023, pp. 892–909
2023
-
[7]
G. Jiang, Y . Sun, T. Huang, H. Li, Y . Liang, and H. Xu, “Robots pre- train robots: Manipulation-centric robotic representation from large-scale robot datasets,”arXiv preprint arXiv:2410.22325, 2024
arXiv 2024
-
[8]
Spa: 3d spatial- awareness enables effective embodied representation,
H. Zhu, H. Yang, Y . Wang, J. Yang, L. Wang, and T. He, “Spa: 3d spatial- awareness enables effective embodied representation,” inInternational Conference on Learning Representations, 2025, pp. 26 361–26 391
2025
-
[9]
Mtil: Encoding full history with mamba for temporal imitation learning,
Y . Zhou, Y . Lin, F. Peng, J. Chen, K. Huang, H. Yang, and Z. Yin, “Mtil: Encoding full history with mamba for temporal imitation learning,”IEEE Robotics and Automation Letters, 2025
2025
-
[10]
Mem: Multi-scale embodied memory for vision language action models,
M. Torne, K. Pertsch, H. Walke, K. Vedder, S. Nair, B. Ichter, A. Z. Ren, H. Wang, J. Tang, K. Stachowiczet al., “Mem: Multi-scale embodied memory for vision language action models,”arXiv preprint arXiv:2603.03596, 2026
arXiv 2026
-
[11]
π 0.7: A Steerable Generalist Robotic Foundation Model with Emergent Capabilities,
P. Intelligence, B. Ai, A. Amin, R. Aniceto, A. Balakrishna, G. Balke, K. Black, G. Bokinsky, S. Cao, T. Charbonnieret al., “π 0.7: A Steerable Generalist Robotic Foundation Model with Emergent Capabilities,” arXiv preprint arXiv:2604.15483, 2026
Pith/arXiv arXiv 2026
-
[12]
Hif-vla: Hindsight, insight and foresight through motion representation for vision-language-action models,
M. Lin, P. Ding, S. Wang, Z. Zhuang, Y . Liu, X. Tong, W. Song, S. Lyu, S. Huang, and D. Wang, “Hif-vla: Hindsight, insight and foresight through motion representation for vision-language-action models,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2026, pp. 20 732–20 742
2026
-
[13]
Bootstrap dynamic-aware 3d visual representation for scalable robot learning,
Q. Liang, B. Cai, M. Lai, S. Zhuang, T. Lin, Y . Qin, Y . Ye, J. Liang, and R. Xu, “Bootstrap dynamic-aware 3d visual representation for scalable robot learning,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2026, pp. 13 419–13 429
2026
-
[14]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in neural information processing systems, 2017
2017
-
[15]
Mamba: Linear-time sequence modeling with selective state spaces,
A. Gu and T. Dao, “Mamba: Linear-time sequence modeling with selective state spaces,”arXiv preprint arXiv:2312.00752, 2023
Pith/arXiv arXiv 2023
-
[16]
Masked au- toencoders are scalable vision learners,
K. He, X. Chen, S. Xie, Y . Li, P. Doll ´ar, and R. Girshick, “Masked au- toencoders are scalable vision learners,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 16 000–16 009
2022
-
[17]
T. Chen, Z. Chen, B. Chen, Z. Cai, Y . Liu, Z. Li, Q. Liang, X. Lin, Y . Ge, Z. Guet al., “Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation,”arXiv preprint arXiv:2506.18088, 2025
Pith/arXiv arXiv 2025
-
[18]
Diffusion policy: Visuomotor policy learning via action diffusion,
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song, “Diffusion policy: Visuomotor policy learning via action diffusion,”The International Journal of Robotics Research, pp. 1684– 1704, 2025
2025
-
[19]
Maniflow: A general robot manipulation policy via consistency flow training,
G. Yan, J. Zhu, Y . Deng, S. Yang, R.-Z. Qiu, X. Cheng, M. Mem- mel, R. Krishna, A. Goyal, X. Wanget al., “Maniflow: A general robot manipulation policy via consistency flow training,”arXiv preprint arXiv:2509.01819, 2025
arXiv 2025
-
[20]
Rmbench: Memory-dependent robotic ma- nipulation benchmark with insights into policy design,
T. Chen, Y . Wang, M. Li, Y . Qin, H. Shi, Z. Li, Y . Hu, Y . Zhang, K. Wang, Y . Chenet al., “Rmbench: Memory-dependent robotic ma- nipulation benchmark with insights into policy design,”arXiv preprint arXiv:2603.01229, 2026
arXiv 2026
-
[21]
Theia: Distilling diverse vision foundation models for robot learning,
J. Shang, K. Schmeckpeper, B. B. May, M. V . Minniti, T. Kelestemur, D. Watkins, and L. Herlant, “Theia: Distilling diverse vision foundation models for robot learning,”arXiv preprint arXiv:2407.20179, 2024
arXiv 2024
-
[22]
Masquerade: Learning from in-the-wild human videos using data-editing,
M. Lepert, J. Fang, and J. Bohg, “Masquerade: Learning from in-the-wild human videos using data-editing,”arXiv preprint arXiv:2508.09976, 2025
Pith/arXiv arXiv 2025
-
[23]
Masked visual pre- training for motor control,
T. Xiao, I. Radosavovic, T. Darrell, and J. Malik, “Masked visual pre- training for motor control,”arXiv preprint arXiv:2203.06173, 2022
arXiv 2022
-
[24]
Real-world robot learning with masked visual pre-training,
I. Radosavovic, T. Xiao, S. James, P. Abbeel, J. Malik, and T. Darrell, “Real-world robot learning with masked visual pre-training,” inConfer- ence on Robot Learning, 2023
2023
-
[25]
4d visual pre-training for robot learning,
C. Hou, Y . Ze, Y . Fu, Z. Gao, S. Hu, Y . Yu, S. Zhang, and H. Xu, “4d visual pre-training for robot learning,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025
2025
-
[26]
Y . Jia, J. Liu, S. Chen, C. Gu, Z. Wang, L. Luo, L. Lee, P. Wang, Z. Wang, R. Zhanget al., “Lift3d foundation policy: Lifting 2d large- scale pretrained models for robust 3d robotic manipulation,”arXiv preprint arXiv:2411.18623, 2024
arXiv 2024
-
[27]
Robouniview: Visual-language model with unified view representation for robotic manipulation,
F. Liu, F. Yan, L. Zheng, C. Feng, Y . Huang, and L. Ma, “Robouniview: Visual-language model with unified view representation for robotic manipulation,”arXiv preprint arXiv:2406.18977, 2024
arXiv 2024
-
[28]
Multi-view masked world models for visual robotic manipulation,
Y . Seo, J. Kim, S. James, K. Lee, J. Shin, and P. Abbeel, “Multi-view masked world models for visual robotic manipulation,” inInternational Conference on Machine Learning, 2023
2023
-
[29]
Lava-man: Learning visual action representations for robot manipulation,
C. Zhu, H. Wang, Y . L. Pang, and C. Oh, “Lava-man: Learning visual action representations for robot manipulation,”arXiv preprint arXiv:2508.19391, 2025
arXiv 2025
-
[30]
Dynarend: Learning 3d dynamics via masked future rendering for robotic manipulation,
J. Tian, L. Wang, S. Zhou, S. Wang, and G. Hua, “Dynarend: Learning 3d dynamics via masked future rendering for robotic manipulation,” Advances in Neural Information Processing Systems, 2026
2026
-
[31]
Spatiotempo- ral predictive pre-training for robotic motor control,
J. Yang, B. Liu, J. Fu, B. Pan, G. Wu, and L. Wang, “Spatiotempo- ral predictive pre-training for robotic motor control,”arXiv preprint arXiv:2403.05304, 2024
arXiv 2024
-
[32]
Learning manipulation by predicting interaction,
J. Zeng, Q. Bu, B. Wang, W. Xia, L. Chen, H. Dong, H. Song, D. Wang, D. Hu, P. Luoet al., “Learning manipulation by predicting interaction,” arXiv preprint arXiv:2406.00439, 2024
arXiv 2024
-
[33]
Roboact-clip: Video-driven pre-training of atomic action understanding for robotics,
Z. Zhang, Y . He, Y . Sun, J. Shi, L. Liu, and Q. Nie, “Roboact-clip: Video-driven pre-training of atomic action understanding for robotics,” arXiv preprint arXiv:2504.02069, 2025
arXiv 2025
-
[34]
Lola: Long horizon latent action learning for general robot manipulation,
X. Wang, X. Gao, J. Fu, Z. Li, D. Fortier, G. Mullins, A. Kolobov, and B. Guo, “Lola: Long horizon latent action learning for general robot manipulation,”arXiv preprint arXiv:2512.20166, 2025
arXiv 2025
-
[35]
History- aware visuomotor policy learning via point tracking,
J. Chen, H. Fang, C. Wang, S. Wang, and C. Lu, “History- aware visuomotor policy learning via point tracking,”arXiv preprint arXiv:2509.17141, 2025
arXiv 2025
-
[36]
Cyclemanip: Enabling cycle-based manipulation via effective history perception and understanding,
Y .-L. Wei, H. Liao, Y . Lin, P. Wang, Z. Liang, G. Liu, and W.-S. Zheng, “Cyclemanip: Enabling cycle-based manipulation via effective history perception and understanding,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2026, pp. 20 780–20 789
2026
-
[37]
Contextvla: Vision-language-action model with amortized multi-frame context,
H. Jang, S. Yu, H. Kwon, H. Jeon, Y . Seo, and J. Shin, “Contextvla: Vision-language-action model with amortized multi-frame context,” arXiv preprint arXiv:2510.04246, 2025
arXiv 2025
-
[38]
Memoryvla: Perceptual-cognitive memory in vision-language-action models for robotic manipulation,
H. Shi, B. Xie, Y . Liu, L. Sun, F. Liu, T. Wang, E. Zhou, H. Fan, X. Zhang, and G. Huang, “Memoryvla: Perceptual-cognitive memory in vision-language-action models for robotic manipulation,”arXiv preprint arXiv:2508.19236, 2025
Pith/arXiv arXiv 2025
-
[39]
M. Lin, X. Liang, B. Lin, L. Jingzhi, Z. Jiao, K. Li, Y . Ma, Y . Liu, S. Zhao, Y . Zhuanget al., “Echovla: Robotic vision-language-action model with synergistic declarative memory for mobile manipulation,” arXiv preprint arXiv:2511.18112, 2025
arXiv 2025
-
[40]
Hamlet: Switch your vision-language-action model into a history-aware policy,
M. Koo, D. Choi, T. Kim, K. Lee, C. Kim, Y . Seo, and J. Shin, “Hamlet: Switch your vision-language-action model into a history-aware policy,” arXiv preprint arXiv:2510.00695, 2025
Pith/arXiv arXiv 2025
-
[41]
Sam2act: Integrating visual foundation model with a memory architecture for robotic manipulation,
H. Fang, M. Grotz, W. Pumacay, Y . R. Wang, D. Fox, R. Krishna, and J. Duan, “Sam2act: Integrating visual foundation model with a memory architecture for robotic manipulation,”arXiv preprint arXiv:2501.18564, 2025. 9
arXiv 2025
-
[42]
Dinov2: Learning robust visual features without supervision,
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. Haziza, F. Massa, A. El-Noubyet al., “Dinov2: Learning robust visual features without supervision,”arXiv preprint arXiv:2304.07193, 2023
Pith/arXiv arXiv 2023
-
[43]
O. Sim ´eoni, H. V . V o, M. Seitzer, F. Baldassarre, M. Oquab, C. Jose, V . Khalidov, M. Szafraniec, S. Yi, M. Ramamonjisoaet al., “Dinov3,” arXiv preprint arXiv:2508.10104, 2025
Pith/arXiv arXiv 2025
-
[44]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning, 2021, pp. 8748–8763
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.