Work Stealing for the 2D-Mesh Topology of Satellite Constellations in Low Earth Orbit
Pith reviewed 2026-06-27 05:42 UTC · model grok-4.3
The pith
Neighbor-only work stealing in LEO satellite meshes reduces per-attempt latency with growing advantage as size increases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
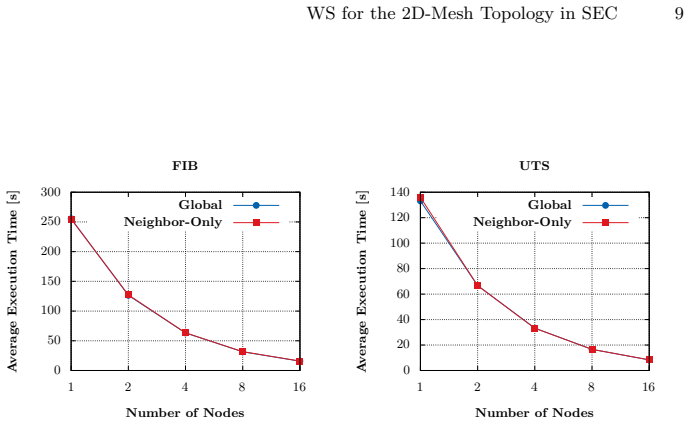
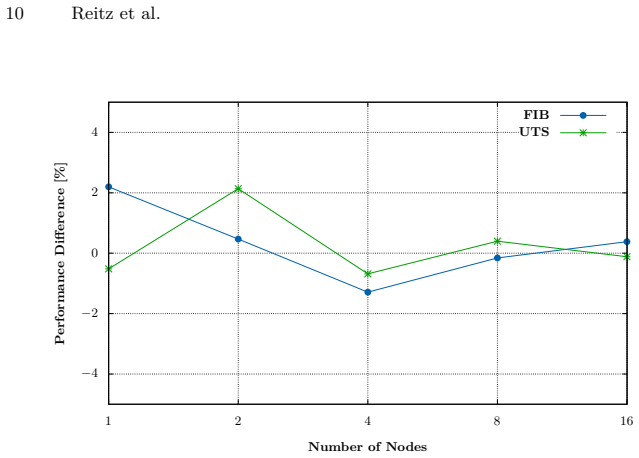
Restricting work stealing to directly connected neighbors in the 2D-mesh topology of satellite constellations yields a per-attempt latency advantage that grows with constellation size. The neighbor-only strategy performs within approximately 2.2% of global stealing on both balanced and irregular workloads in emulation, indicating that restricting the victim set does not harm load balancing.
What carries the argument
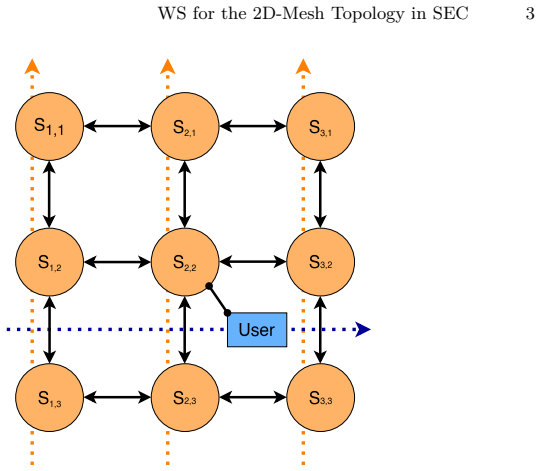
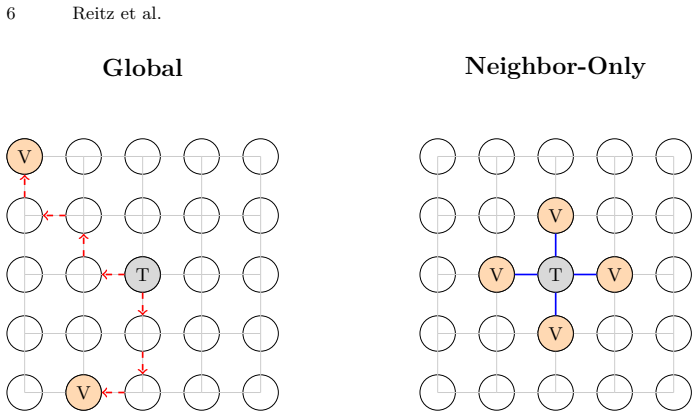
The neighbor-only work stealing strategy, which limits victim selection to directly connected satellites via inter-satellite links.
Load-bearing premise
The HPC cluster emulation with uniform low-latency links accurately represents the load-balancing outcomes from victim selection in real LEO mesh networks that have variable multi-hop latencies.
What would settle it
Direct comparison of task throughput and steal latencies in a real or high-fidelity simulated LEO satellite network with actual inter-satellite link delays would confirm if neighbor-only stealing maintains its performance parity.
Figures
read the original abstract
Asynchronous Many-Task (AMT) is a parallel programming model used in High Performance Computing (HPC). An AMT runtime can distribute fine-grained tasks across processing units called workers, through work stealing: when a worker has no tasks left to process, it tries to steal tasks from other workers. Workers are not restricted to a single compute node but can also be distributed across multiple nodes of an HPC cluster. Existing AMT runtimes assume a fully connected network with low, uniform latency and perform global work stealing, selecting another worker at random from all workers in the system. Space Edge Computing (SEC) uses constellations of satellites in Low Earth Orbit (LEO) as distributed compute clusters. Unlike HPC clusters, LEO satellites communicate through inter-satellite links that form a sparse mesh topology. Reaching a distant satellite requires multiple hops, each adding latency. As a step toward adapting AMT to SEC, this paper proposes a neighbor-only work stealing strategy in which workers steal exclusively from directly connected neighbors, avoiding multi-hop communication. An analytical model shows that restricting stealing this way yields a per-attempt latency advantage that grows with constellation size. Preliminary experiments on an HPC cluster with an emulated mesh over uniform low-latency links isolate the effect of victim selection: the neighbor-only strategy performs within ~2.2% of global stealing on both balanced and irregular workloads, indicating that restricting the victim set does not harm load balancing in this setting. Taken together, the experiments suggest that neighbor-only stealing can be on a par with global stealing, and the model suggests that neighbor-only stealing becomes preferable at scale.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a neighbor-only work stealing strategy for Asynchronous Many-Task (AMT) runtimes on the 2D-mesh topology of LEO satellite constellations. An analytical model is claimed to show a per-attempt latency advantage that grows with constellation size when restricting steals to direct neighbors. Preliminary emulation on an HPC cluster with an emulated mesh using uniform low-latency links reports that the neighbor-only strategy performs within ~2.2% of global stealing on both balanced and irregular workloads, suggesting the restriction does not harm load balancing.
Significance. If the latency advantage and performance parity hold, the work provides a concrete step toward adapting HPC AMT models to space edge computing environments with sparse, multi-hop topologies. The separation of the analytical model from the emulation experiments and the direct measurement approach are positive features that could support falsifiable predictions at larger scales.
major comments (2)
- [preliminary experiments / emulation results] Emulation results: the setup applies uniform low-latency links to all pairs, which isolates the victim-selection effect but does not model the multi-hop delays that global steals would incur in a real 2D mesh; this leaves untested whether longer steal completion times would change the rate of imbalance correction and thus the observed ~2.2% gap, which is load-bearing for the claim that neighbor-only performs on a par with global stealing.
- [analytical model] Analytical model description: the model is stated to be independent of the experiments and to quantify a latency advantage that grows with size, but the equations, workload assumptions, and derivation are not provided, preventing verification that the advantage is not an artifact of the model construction.
minor comments (1)
- Workload definitions and error bars are not reported for the emulation results, which would be needed to assess the statistical significance of the ~2.2% figure.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address the two major comments point by point below and indicate the revisions we will make.
read point-by-point responses
-
Referee: Emulation results: the setup applies uniform low-latency links to all pairs, which isolates the victim-selection effect but does not model the multi-hop delays that global steals would incur in a real 2D mesh; this leaves untested whether longer steal completion times would change the rate of imbalance correction and thus the observed ~2.2% gap, which is load-bearing for the claim that neighbor-only performs on a par with global stealing.
Authors: We agree that the emulation deliberately uses uniform low-latency links across all pairs and therefore does not capture the multi-hop latency penalty that global steals would experience on a real 2D mesh. The experimental design was chosen to isolate the effect of restricting the victim set, as stated in the manuscript. This choice means the observed performance parity is demonstrated only under uniform latency; whether the ~2.2% gap would widen, shrink, or reverse when global steals incur additional hops remains untested. In the revised manuscript we will add an explicit limitations paragraph that qualifies the parity claim accordingly and will outline a concrete plan for follow-on experiments that inject per-hop delays. revision: partial
-
Referee: Analytical model description: the model is stated to be independent of the experiments and to quantify a latency advantage that grows with size, but the equations, workload assumptions, and derivation are not provided, preventing verification that the advantage is not an artifact of the model construction.
Authors: The manuscript states that an analytical model exists and is independent of the experiments, yet the referee is correct that the full equations, workload assumptions, and derivation steps are not supplied in sufficient detail. We will revise the model section to include the complete mathematical formulation, the precise workload and topology assumptions, and the step-by-step derivation so that readers can reproduce and verify the claimed latency advantage. revision: yes
Circularity Check
No circularity: model and measurements are independent of inputs
full rationale
The paper's central claims rest on an analytical model quantifying per-attempt latency advantage (growing with size) and direct emulation measurements showing neighbor-only stealing within 2.2% of global on balanced/irregular workloads. No equations, fitted parameters, or self-citations are shown that would reduce any prediction to its inputs by construction. The emulation isolates victim selection via uniform links and reports measured outcomes rather than fitted results. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LEO satellite constellations communicate via inter-satellite links forming a sparse 2D mesh with multi-hop latency
Reference graph
Works this paper leans on
-
[1]
IEEE Communications Magazine pp
Garcia-Cabeza, J., Albert-Smet, J., Frias, Z., Mendo, L., Azcoitia, S.A., Yraola, E.: Direct-to-Cell: A First Look into Starlink’s Direct Satellite-to-Device Radio Access Network through Crowdsourced Measurements. IEEE Communications Magazine pp. 1–7 (2025), https://doi.org/10.1109/MCOM.001.2500350 14 Reitz et al
-
[2]
In: Euro-Par 2024: Parallel Processing Workshops
Chenet, D., Lorandel, J., Moy, C., Ramirez-Gallego, S., Alvarez, R.R.: Space Edge Computing for Satellite Systems: Definition and Key Enabling Technolo- gies. In: Euro-Par 2024: Parallel Processing Workshops. Lecture Notes in Com- puter Science, vol. 15386, pp. 399–404. Springer (2024), https://doi.org/10.1007/ 978-3-031-90203-1_48
2024
-
[3]
Mousist, A.D.: Real-Time Blind Defocus Deblurring for Earth Observation: The IMAGIN-e Mission Approach (2025), arXiv preprint arXiv:2505.22128, https://doi. org/10.48550/arXiv.2505.22128
-
[4]
Fohry, C.: TaPP: An Overview of Task-Based Parallel Programming Models. Tuto- rial at European Network on High-performance Embedded Architecture and Com- pilation Conference (HiPEAC) (2020), https://doi.org/10.5281/zenodo.8425959
-
[5]
Journal of the ACM (JACM) 46(5), 720–748 (1999), https://doi.org/10
Blumofe, R.D., Leiserson, C.E.: Scheduling Multithreaded Computations by Work Stealing. Journal of the ACM (JACM) 46(5), 720–748 (1999), https://doi.org/10. 1145/324133.324234
arXiv 1999
-
[6]
In: Euro-Par 2024: Parallel Processing Workshops
Reitz, M., Gerhards, B., Hundhausen, J., Fohry, C.: Investigating the Performance Difference of Task Communication via Futures or Side Effects. In: Euro-Par 2024: Parallel Processing Workshops. pp. 255–267. Lecture Notes in Computer Science, Springer (2024), https://doi.org/10.1007/978-3-031-90200-0_21
-
[7]
In: International Conference for High Performance Com- puting, Networking, Storage and Analysis (SC)
Shiina, S., Taura, K.: Itoyori: Reconciling Global Address Space and Global Fork- Join Task Parallelism. In: International Conference for High Performance Com- puting, Networking, Storage and Analysis (SC). pp. 1–15. ACM (2023), https: //doi.org/10.1145/3581784.3607049
-
[8]
Radhakrishnan, R., Edmonson, W.W., Afghah, F., Rodriguez-Osorio, R.M., Pinto, F., Burleigh, S.C.: Survey of inter-satellite communication for small satellite sys- tems: Physical layer to network layer view. IEEE Communications Surveys & Tu- torials 18(4), 2442–2473 (2016), https://doi.org/10.1109/COMST.2016.2564990
-
[9]
Tiwari, G., Chauhan, R.C.S.: A review on inter-satellite links free space optical communication. Indian Journal of Science and Technology 13(6), 712–724 (2020), https://doi.org/10.17485/ijst/2020/v13i06/147998
-
[10]
In: IEEE International Conference on Communications (ICC)
Soret, B., Ravikanti, S., Popovski, P.: Latency and timeliness in multi-hop satellite networks. In: IEEE International Conference on Communications (ICC). pp. 1–6. IEEE (2020), https://doi.org/10.1109/ICC40277.2020.9149009
-
[11]
Yang, H., Guo, B., Xue, X., Deng, X., Zhao, Y., Cui, X., Pang, C., Ren, H., Huang, S.: Interruption tolerance strategy for LEO constellation with optical inter-satellite link. IEEE Transactions on Network and Service Management 20(4), 4815–4830 (2023), https://doi.org/10.1109/TNSM.2023.3274638
-
[12]
https://www
MPI Forum: MPI: A Message-Passing Interface Standard Version 5.0. https://www. mpi-forum.org/docs/mpi-5.0/mpi50-report.pdf (2025), accessed: 2026-04-21
2025
-
[13]
Reitz, M.: Source Code of paper "Work Stealing for the 2D-Mesh Topology of Satel- lite Constellations in Low Earth Orbit" (2026), https://doi.org/10.5281/zenodo. 20643665
-
[14]
https://www.top500.org/system/179588 (2018), accessed: 2026- 04-21
TOP500.org: GOETHE-HLR cluster (MEGW ARE MiriQuid, Xeon Gold 6148, In- finiBand EDR). https://www.top500.org/system/179588 (2018), accessed: 2026- 04-21
2018
-
[15]
In: Languages and Compilers for Parallel Computing (LCPC), Lecture Notes in Computer Science, vol
Olivier, S., Huan, J., Liu, J., Prins, J., Dinan, J., Sadayappan, P., Tseng, C.W.: UTS: An Unbalanced Tree Search Benchmark. In: Languages and Compilers for Parallel Computing (LCPC), Lecture Notes in Computer Science, vol. 4382, pp. 235–250. Springer (2007), https://doi.org/10.1007/978-3-540-72521-3_18
-
[16]
IEEE Access 10, 100584–100593 (2022), https://doi.org/10.1109/ ACCESS.2022.3207293
Wang, Y., Che, J., Wang, N., Liu, L., Wu, N., Zhong, X., Han, X.: Load-Balancing Method for LEO Satellite Edge-Computing Networks Based on the Maximum Flow WS for the 2D-Mesh Topology in SEC 15 of Virtual Links. IEEE Access 10, 100584–100593 (2022), https://doi.org/10.1109/ ACCESS.2022.3207293
arXiv 2022
-
[17]
In: International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS)
Denby, B., Lucia, B.: Orbital Edge Computing: Nanosatellite Constellations as a New Class of Computer System. In: International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS). pp. 939–
-
[18]
ACM (2020), https://doi.org/10.1145/3373376.3378473
-
[19]
In: Conference on Partitioned Global Address Space Programming Models (PGAS)
Min, S.J., Iancu, C., Yelick, K.: Hierarchical Work Stealing on Manycore Clusters. In: Conference on Partitioned Global Address Space Programming Models (PGAS). ACM (2011)
2011
-
[20]
In: ACM Symposium on Principles and Practice of Parallel Programming (PPoPP)
Saraswat, V.A., Kambadur, P., Kodali, S., Grove, D., Krishnamoorthy, S.: Lifeline- based Global Load Balancing. In: ACM Symposium on Principles and Practice of Parallel Programming (PPoPP). pp. 201–212. ACM (2011), https://doi.org/10. 1145/1941553.1941582
arXiv 2011
-
[21]
IEEE Internet of Things Journal 3(5), 637–646 (2016), https://doi.org/10.1109/ JIOT.2016.2579198
Shi, W., Cao, J., Zhang, Q., Li, Y., Xu, L.: Edge Computing: Vision and Challenges. IEEE Internet of Things Journal 3(5), 637–646 (2016), https://doi.org/10.1109/ JIOT.2016.2579198
arXiv 2016
-
[22]
Mao, Y., You, C., Zhang, J., Huang, K., Letaief, K.B.: A Survey on Mobile Edge Computing: The Communication Perspective. IEEE Communications Surveys & Tutorials 19(4), 2322–2358 (2017), https://doi.org/10.1109/COMST.2017.2745201
-
[23]
Par- allel Processing Letters (PPL) 23(4), 1340011 (2013), https://doi.org/10.1142/ s0129626413400112
Shahzad, F., Wittmann, M., Kreutzer, M., Zeiser, T., Hager, G., Wellein, G.: A survey of checkpoint/restart techniques on distributed memory systems. Par- allel Processing Letters (PPL) 23(4), 1340011 (2013), https://doi.org/10.1142/ s0129626413400112
2013
-
[24]
Posner, J., Reitz, M., Fohry, C.: A Comparison of Application-Level Fault Toler- ance Schemes for Task Pools. Future Generation Computer Systems (FGCS) 105, 119–134 (2020), https://doi.org/10.1016/j.future.2019.11.031
-
[25]
Posner, J., Reitz, M., Fohry, C.: Task-Level Resilience: Checkpointing vs. Super- vision. International Journal of Networking and Computing (IJNC) 12(1), 47–72 (2022), https://doi.org/10.15803/ijnc.12.1_47
-
[26]
Fohry, C., Bungart, M., Plock, P.: Fault Tolerance for Lifeline-Based Global Load Balancing. Journal of Software Engineering and Applications (JSEA) 10(13), 925– 958 (2017), https://doi.org/10.4236/jsea.2017.1013053
-
[27]
In: IEEE International Parallel and Distributed Processing Symposium (IPDPS)
Kestor, G., Krishnamoorthy, S., Ma, W.: Localized Fault Recovery for Nested Fork-Join Programs. In: IEEE International Parallel and Distributed Processing Symposium (IPDPS). pp. 397–408. IEEE (2017), https://doi.org/10.1109/ipdps. 2017.75
-
[28]
In: International Conference on Parallel Processing Workshops (ICPP Workshops)
Posner, J., Fohry, C.: Transparent Resource Elasticity for Task-Based Cluster Envi- ronments with Work Stealing. In: International Conference on Parallel Processing Workshops (ICPP Workshops). pp. 1–10. ACM (2021), https://doi.org/10.1145/ 3458744.3473361
arXiv 2021
-
[29]
SN Computer Science 6(8) (2025), https://doi.org/10.1007/s42979-025-04405-3
Posner, J., Ellersiek, T., Bietendorf, N., Huber, D., Schreiber, M., Schulz, M.: Toward Dynamic Resource Management: An Asynchronous Many-Task (AMT) Runtime System leveraging Dynamic Processes with PSets (DPP). SN Computer Science 6(8) (2025), https://doi.org/10.1007/s42979-025-04405-3
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.