HNPclassifier: An R Package for Hierarchical Neyman-Pearson Classification
Pith reviewed 2026-06-27 04:47 UTC · model grok-4.3
The pith
The HNPclassifier package implements the H-NP umbrella algorithm to deliver high-probability control over under-classification errors at user-specified levels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The H-NP umbrella algorithm provides high-probability control of under-classification errors at user-specified levels, and the HNPclassifier package implements this algorithm for constructing classifiers in ordered multi-class settings.
What carries the argument
The Hierarchical Neyman-Pearson (H-NP) umbrella algorithm, which enforces high-probability bounds on under-classification errors for ordered classes.
Load-bearing premise
The R package correctly implements the theoretical H-NP framework of Wang et al. (2024) when using the listed learners and user-supplied scoring functions.
What would settle it
Running the package on simulated data with known distributions and observing that the under-classification error rate exceeds the specified level more often than the claimed high-probability bound would falsify the claim.
Figures
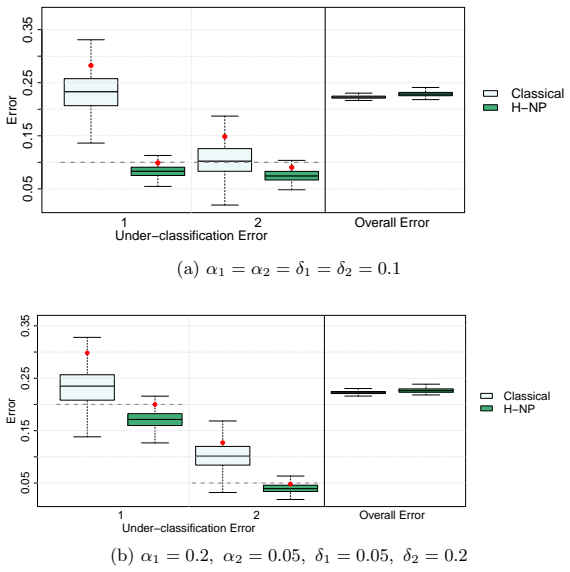
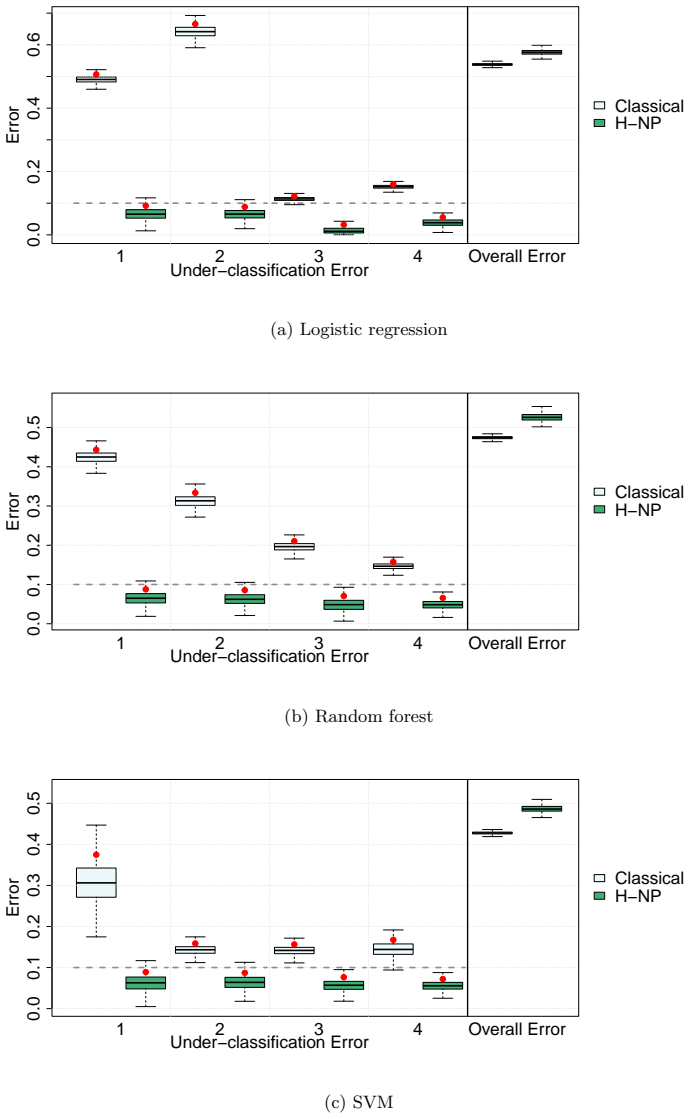
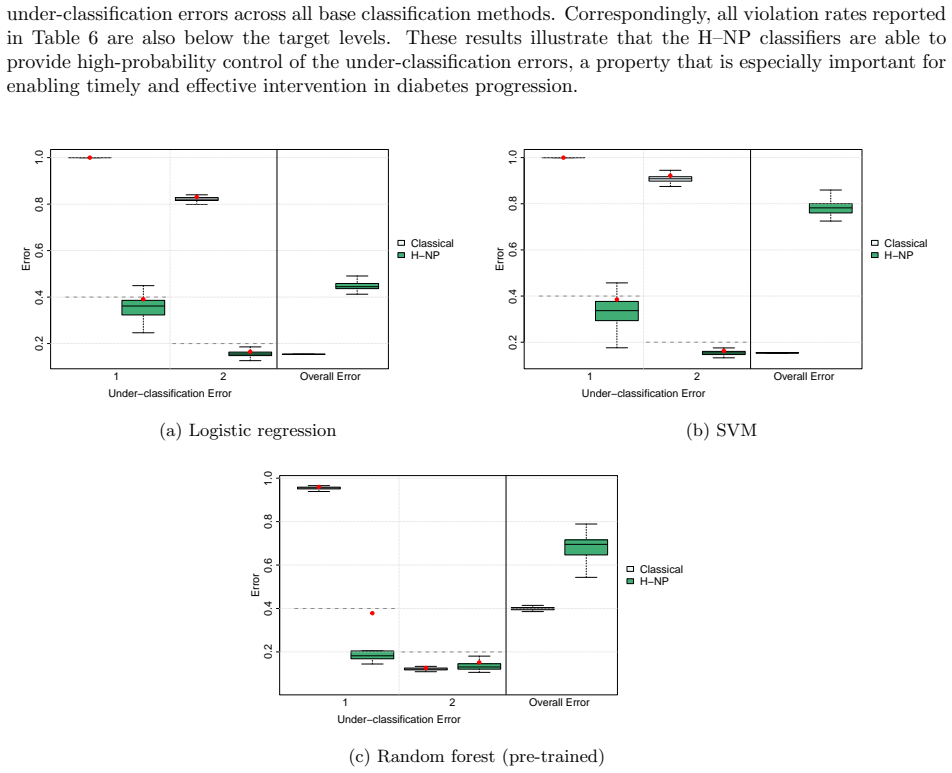
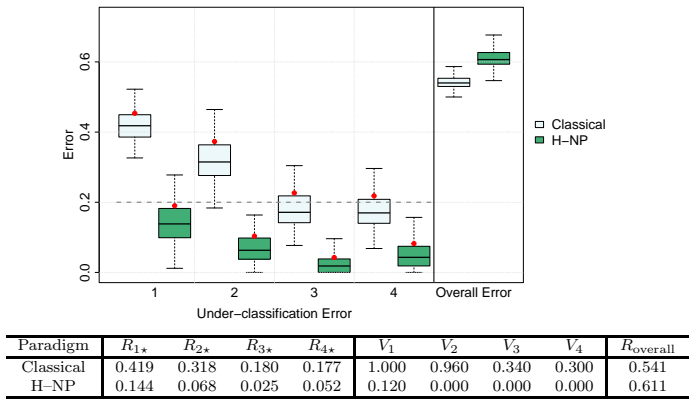
read the original abstract
In multi-class classification problems, classes often have a natural priority ordering (e.g., cancer stages, COVID-19 severity levels, or air-quality categories). In such settings, it is important to prioritize correct identification of more severe classes and to control under-classification errors, which occur when an observation from a higher-priority class is misclassified into a lower-priority one. The Hierarchical Neyman-Pearson (H-NP) framework of Wang et al. (2024) was developed for ordered multi-class settings to prioritize under-classification error control; its H-NP umbrella algorithm provides high-probability control of under-classification errors at user-specified levels. This paper introduces the R package HNPclassifier, which implements H-NP umbrella algorithms to construct H-NP classifiers using built-in learners such as logistic regression, random forests, and support vector machines, as well as user-supplied scoring functions, thereby enabling effective error control for ordered multi-class classification tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the R package HNPclassifier, which implements the Hierarchical Neyman-Pearson (H-NP) umbrella algorithm from Wang et al. (2024) for ordered multi-class classification. It supports built-in learners (logistic regression, random forests, SVMs) and user-supplied scoring functions to achieve high-probability control of under-classification errors at user-specified levels.
Significance. If the implementation is correct, the package would provide a practical R tool for applying the H-NP framework in domains requiring prioritized error control, such as medical staging or environmental categories. The significance is currently constrained by the absence of any verification that the delivered functions match the theoretical guarantees.
major comments (2)
- [Abstract] Abstract: the central claim that the package 'implements H-NP umbrella algorithms to construct H-NP classifiers' and thereby delivers 'high-probability control of under-classification errors at user-specified levels' is asserted solely by reference to Wang et al. (2024); no code, pseudocode comparison, unit tests, or simulation results are supplied to confirm that the R functions achieve the promised control.
- The manuscript provides no validation experiments, error analysis, or side-by-side checks against the theoretical H-NP umbrella algorithm, leaving the weakest assumption (correct implementation for the listed learners and user-supplied scorers) unexamined and load-bearing for the paper's contribution as a software description.
minor comments (1)
- [Abstract] Abstract: the phrasing 'thereby enabling effective error control' is vague; a concrete statement of what 'effective' means in terms of the user-specified levels would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the detailed review and for highlighting the need to verify the implementation against the theoretical guarantees of Wang et al. (2024). We address the major comments point by point below and will revise the manuscript to incorporate additional verification material.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the package 'implements H-NP umbrella algorithms to construct H-NP classifiers' and thereby delivers 'high-probability control of under-classification errors at user-specified levels' is asserted solely by reference to Wang et al. (2024); no code, pseudocode comparison, unit tests, or simulation results are supplied to confirm that the R functions achieve the promised control.
Authors: We agree that the abstract and main text would be strengthened by explicit linkage between the package functions and the H-NP umbrella algorithm. In the revised manuscript we will add a dedicated subsection that reproduces the high-level steps of the H-NP umbrella algorithm (with pseudocode) and maps each step to the corresponding exported functions in HNPclassifier. We will also document the unit tests already present in the package that check error-rate control on synthetic data, and we will expand the package vignette to include these checks. revision: yes
-
Referee: The manuscript provides no validation experiments, error analysis, or side-by-side checks against the theoretical H-NP umbrella algorithm, leaving the weakest assumption (correct implementation for the listed learners and user-supplied scorers) unexamined and load-bearing for the paper's contribution as a software description.
Authors: The referee is correct that the current manuscript contains no empirical verification of the delivered error control. Because the paper is a software description, the original emphasis was on API documentation and usage examples. To address the concern we will add a new 'Numerical verification' section containing simulation results. These experiments will report empirical under-classification error rates for the three built-in learners across a range of target levels and sample sizes, and will include an example with a user-supplied scoring function. The section will also contain a brief error analysis comparing observed versus nominal control levels. revision: yes
Circularity Check
No circularity: software description references independent prior theory
full rationale
The manuscript is a package description paper whose central claim is that HNPclassifier implements the H-NP umbrella algorithm from the separately published Wang et al. (2024) framework. No derivation, prediction, or first-principles result is presented in this text; the error-control guarantee is asserted by citation to the prior theoretical work rather than derived or fitted here. No self-definitional steps, fitted-input predictions, or load-bearing self-citation chains appear. The single reference to Wang et al. (2024) supplies external theoretical content and does not reduce any claim in the present paper to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The H-NP umbrella algorithm from Wang et al. (2024) delivers the stated high-probability error control when applied to the listed learners.
Reference graph
Works this paper leans on
-
[1]
and Al-Turaiki, I
Alballa, N. and Al-Turaiki, I. (2021). Machine learning approaches in covid-19 diagnosis, mortality, and severity risk prediction: A review. Informatics in medicine unlocked , 24:100564
2021
-
[2]
Cannon, A., Howse, J., et al. (2002). Learning with the neyman-pearson and min-max criteria. Los Alamos National Laboratory, Tech. Rep. LA-UR , pages 02--2951
2002
-
[3]
and Chen, X.-w
Casasent, D. and Chen, X.-w. (2003). Radial basis function neural networks for nonlinear fisher discrimination and neyman--pearson classification. Neural networks , 16(5-6):529--535
2003
-
[4]
Han, M., Chen, D., and Sun, Z. (2008). Analysis to neyman-pearson classification with convex loss function. Analysis in Theory and Applications , 24(1):18--28
2008
-
[5]
Hofmann, H. (1994). Statlog (German Credit Data) . UCI Machine Learning Repository. DOI : https://doi.org/10.24432/C5NC77
-
[6]
Meyer, K. B. and Pauker, S. G. (1987). Screening for hiv: can we afford the false positive rate? New England journal of medicine , 317(4):238--241
1987
-
[7]
Scott, C. (2005). Comparison and design of neyman-pearson classifiers. Department of Statistics, Rice University, Houston, TX , 20
2005
-
[8]
Teboul, A. (2021). Diabetes health indicators dataset. Kaggle. Accessed: 2025-01-24
2021
-
[9]
and Feng, Y
Tian, Y. and Feng, Y. (2025). Neyman-pearson multi-class classification via cost-sensitive learning. Journal of the American Statistical Association , 120(550):1164--1177
2025
-
[10]
Tong, X. (2013). A plug-in approach to neyman-pearson classification. Journal of Machine Learning Research , 14(1):3011--3040
2013
-
[11]
Tong, X., Feng, Y., and Li, J. J. (2018). Neyman-pearson classification algorithms and np receiver operating characteristics. Science advances , 4(2):eaao1659
2018
-
[12]
R., Li, J
Wang, L., Wang, Y. R., Li, J. J., and Tong, X. (2024). Hierarchical neyman-pearson classification for prioritizing severe disease categories in covid-19 patient data. Journal of the American Statistical Association , 119(545):39--51
2024
-
[13]
Xie, Z., Nikolayeva, O., Luo, J., and Li, D. (2019). Building risk prediction models for type 2 diabetes using machine learning techniques. Preventing chronic disease , 16:E130
2019
-
[14]
Xiong, C., van Belle, G., et al. (2006). Measuring and estimating diagnostic accuracy when there are three ordinal diagnostic groups. Statistics in Medicine , 25(7):1251--1273
2006
-
[15]
Zhao, A., Feng, Y., et al. (2016). Neyman-pearson classification under high-dimensional settings. Journal of Machine Learning Research , 17(1):7469--7507
2016
-
[16]
Preventing chronic disease , volume=
Building risk prediction models for type 2 diabetes using machine learning techniques , author=. Preventing chronic disease , volume=. 2019 , pages=
2019
-
[17]
1994 , howpublished =
Hofmann, Hans , title =. 1994 , howpublished =
1994
-
[18]
2021 , howpublished =
Teboul, Alex , title =. 2021 , howpublished =
2021
-
[19]
2016 , note =
R: A Language and Environment for Statistical Computing , author =. 2016 , note =
2016
-
[20]
R: A Language for Data Analysis and Graphics , Volume = 5, Year = 1996, url =
Ihaka, Ross and Gentleman, Robert , Journal =. R: A Language for Data Analysis and Graphics , Volume = 5, Year = 1996, url =
1996
-
[21]
International joint conference on artificial intelligence , volume=
The foundations of cost-sensitive learning , author=. International joint conference on artificial intelligence , volume=. 2001 , organization=
2001
-
[22]
European Conference on Machine Learning , pages=
Class probability estimation and cost-sensitive classification decisions , author=. European Conference on Machine Learning , pages=. 2002 , organization=
2002
-
[23]
Journal of the American Statistical Association , volume=
Neyman-pearson multi-class classification via cost-sensitive learning , author=. Journal of the American Statistical Association , volume=. 2025 , publisher=
2025
-
[24]
Proceedings 16th Annual Symposium of the Pattern Recognition Association of South Africa
On Neyman-Pearson optimisation for multiclass classifiers , author=. Proceedings 16th Annual Symposium of the Pattern Recognition Association of South Africa. PRASA , pages=
-
[25]
Journal of the American Statistical Association , volume=
Hierarchical neyman-pearson classification for prioritizing severe disease categories in COVID-19 patient data , author=. Journal of the American Statistical Association , volume=. 2024 , publisher=
2024
-
[26]
Available at SSRN 3945980 , volume=
Targeted Crisis Risk Control: A Neyman-Pearson Approach , author=. Available at SSRN 3945980 , volume=
-
[27]
Journal of the American Statistical Association , volume=
Intentional control of type I error over unconscious data distortion: A Neyman--Pearson approach to text classification , author=. Journal of the American Statistical Association , volume=. 2021 , publisher=
2021
-
[28]
Science advances , volume=
Neyman-Pearson classification algorithms and NP receiver operating characteristics , author=. Science advances , volume=. 2018 , publisher=
2018
-
[29]
New England journal of medicine , volume=
Screening for HIV: can we afford the false positive rate? , author=. New England journal of medicine , volume=. 1987 , publisher=
1987
-
[30]
Bioinformatics , volume=
Boosting for tumor classification with gene expression data , author=. Bioinformatics , volume=. 2003 , publisher=
2003
-
[31]
Statistics in Medicine , volume=
Measuring and estimating diagnostic accuracy when there are three ordinal diagnostic groups , author=. Statistics in Medicine , volume=. 2006 , publisher=
2006
-
[32]
Los Alamos National Laboratory, Tech
Learning with the Neyman-Pearson and min-max criteria , author=. Los Alamos National Laboratory, Tech. Rep. LA-UR , pages=
-
[33]
IEEE Trans
A Neyman-Pearson approach to statistical learning , author=. IEEE Trans. Inf. Theory , volume=. 2005 , publisher=
2005
-
[34]
Journal of Machine Learning Research , year=
Neyman-pearson classification, convexity and stochastic constraints , author=. Journal of Machine Learning Research , year=
-
[35]
Neural networks , volume=
Radial basis function neural networks for nonlinear Fisher discrimination and Neyman--Pearson classification , author=. Neural networks , volume=. 2003 , publisher=
2003
-
[36]
Department of Statistics, Rice University, Houston, TX , volume=
Comparison and design of neyman-pearson classifiers , author=. Department of Statistics, Rice University, Houston, TX , volume=
-
[37]
Analysis in Theory and Applications , volume=
Analysis to Neyman-Pearson classification with convex loss function , author=. Analysis in Theory and Applications , volume=. 2008 , publisher=
2008
-
[38]
Journal of Machine Learning Research , volume=
A plug-in approach to Neyman-Pearson classification , author=. Journal of Machine Learning Research , volume=. 2013 , publisher=
2013
-
[39]
, author=
Neyman-Pearson classification: parametrics and sample size requirement. , author=. Journal of Machine Learning Research , volume=
-
[40]
JASA , volume=
Intentional control of type i error over unconscious data distortion: A neyman--pearson approach to text classification , author=. JASA , volume=. 2021 , publisher=
2021
-
[41]
Available at SSRN 3945980 , year=
Targeted Crisis Risk Control: A Neyman-Pearson Approach , author=. Available at SSRN 3945980 , year=
-
[42]
Travel Med Infect Dis , volume=
Clinical, laboratory and imaging features of COVID-19: A systematic review and meta-analysis , author=. Travel Med Infect Dis , volume=. 2020 , publisher=
2020
-
[43]
JRSSB , volume=
The regression analysis of binary sequences , author=. JRSSB , volume=. 1958 , publisher=
1958
-
[44]
Machine learning , volume=
Random forests , author=. Machine learning , volume=. 2001 , publisher=
2001
-
[45]
Machine learning , volume=
Support-vector networks , author=. Machine learning , volume=. 1995 , publisher=
1995
-
[46]
IEEE Trans
Efficient multiclass ROC approximation by decomposition via confusion matrix perturbation analysis , author=. IEEE Trans. on Pattern Analysis and Machine Intelligence , volume=. 2008 , publisher=
2008
-
[47]
arXiv preprint arXiv:2111.04597 , year=
Neyman-Pearson Multi-class Classification via Cost-sensitive Learning , author=. arXiv preprint arXiv:2111.04597 , year=
-
[48]
Systems immunology: just getting started , author=. Nat. Immunol. , volume=. 2017 , publisher=
2017
-
[49]
An updated guide for the perplexed: cytometry in the high-dimensional era , author=. Nat. Immunol. , volume=. 2021 , publisher=
2021
-
[50]
Single-cell multi-omics analysis of the immune response in COVID-19 , author=. Nat. Med. , volume=. 2021 , publisher=
2021
-
[51]
Cell , volume=
COVID-19 immune features revealed by a large-scale single-cell transcriptome atlas , author=. Cell , volume=. 2021 , publisher=
2021
-
[52]
Front Immunol
Differential dynamics of the maternal immune system in healthy pregnancy and preeclampsia , author=. Front Immunol. , pages=. 2019 , publisher=
2019
-
[53]
VoPo leverages cellular heterogeneity for predictive modeling of single-cell data , author=. Nat. Commun. , volume=. 2020 , publisher=
2020
-
[54]
Preferential inhibition of adaptive immune system dynamics by glucocorticoids in patients after acute surgical trauma , author=. Nat. Commun. , volume=. 2020 , publisher=
2020
-
[55]
2021 , institution=
Machine learning in rare disease , author=. 2021 , institution=
2021
-
[56]
Proceedings of the 12th ACM Conference on Bioinformatics, Computational Biology, and Health Informatics , pages=
CytoSet: Predicting clinical outcomes via set-modeling of cytometry data , author=. Proceedings of the 12th ACM Conference on Bioinformatics, Computational Biology, and Health Informatics , pages=
-
[57]
Department of Computer Science
A review of dimension reduction techniques , author=. Department of Computer Science. University of Sheffield. Tech. Rep. CS-96-09 , volume=. 1997 , publisher=
1997
-
[58]
World Health Organization , pages=
WHO R&D blueprint novel coronavirus COVID-19 therapeutic trial synopsis , author=. World Health Organization , pages=
-
[59]
Cell , volume=
Multi-omics resolves a sharp disease-state shift between mild and moderate COVID-19 , author=. Cell , volume=. 2020 , publisher=
2020
-
[60]
A single-cell atlas of the peripheral immune response in patients with severe COVID-19 , author=. Nat. Med. , volume=. 2020 , publisher=
2020
-
[61]
Immunity , volume=
Single-cell sequencing of peripheral mononuclear cells reveals distinct immune response landscapes of COVID-19 and influenza patients , author=. Immunity , volume=. 2020 , publisher=
2020
-
[62]
Science , volume=
Systems biological assessment of immunity to mild versus severe COVID-19 infection in humans , author=. Science , volume=. 2020 , publisher=
2020
-
[63]
Sci Immunol , volume=
Immunophenotyping of COVID-19 and influenza highlights the role of type I interferons in development of severe COVID-19 , author=. Sci Immunol , volume=. 2020 , publisher=
2020
-
[64]
Cell , volume=
Time-resolved systems immunology reveals a late juncture linked to fatal COVID-19 , author=. Cell , volume=. 2021 , publisher=
2021
-
[65]
Cell , volume=
Severe COVID-19 is marked by a dysregulated myeloid cell compartment , author=. Cell , volume=. 2020 , publisher=
2020
-
[66]
JASA , volume=
The interplay of demographic variables and social distancing scores in deep prediction of US COVID-19 cases , author=. JASA , volume=. 2021 , publisher=
2021
-
[67]
Int J Epidemiol , volume=
Accounting for incomplete testing in the estimation of epidemic parameters , author=. Int J Epidemiol , volume=. 2020 , publisher=
2020
-
[68]
JASA , pages=
Is a Classification Procedure Good Enough?—A Goodness-of-Fit Assessment Tool for Classification Learning , author=. JASA , pages=. 2021 , publisher=
2021
-
[69]
Peter Kramlinger and Tatyana Krivobokova and Stefan Sperlich , title =. JASA , volume =. 2022 , publisher =. doi:10.1080/01621459.2022.2044826 , URL =
-
[70]
Diagnostics , volume=
Detection and severity classification of COVID-19 in CT images using deep learning , author=. Diagnostics , volume=. 2021 , publisher=
2021
-
[71]
PLoS Comp Biol , volume=
Scalable workflow for characterization of cell-cell communication in COVID-19 patients , author=. PLoS Comp Biol , volume=. 2022 , publisher=
2022
-
[72]
PNAS , volume=
scMerge leverages factor analysis, stable expression, and pseudoreplication to merge multiple single-cell RNA-seq datasets , author=. PNAS , volume=. 2019 , publisher=
2019
-
[73]
Mol Syst Biol , volume=
scClassify: sample size estimation and multiscale classification of cells using single and multiple reference , author=. Mol Syst Biol , volume=
-
[74]
F1000Research , volume=
A step-by-step workflow for low-level analysis of single-cell RNA-seq data with Bioconductor , author=. F1000Research , volume=. 2016 , publisher=
2016
-
[75]
Bioinformatics , volume=
Scater: pre-processing, quality control, normalization and visualization of single-cell RNA-seq data in R , author=. Bioinformatics , volume=. 2017 , publisher=
2017
-
[76]
Radiol Cardiothorac Imaging , volume=
Chest CT severity score: an imaging tool for assessing severe COVID-19 , author=. Radiol Cardiothorac Imaging , volume=. 2020 , publisher=
2020
-
[77]
Chaos , volume=
COVID-19 second wave mortality in Europe and the United States , author=. Chaos , volume=. 2021 , publisher=
2021
-
[78]
JASA , volume=
Regression Models for Understanding COVID-19 Epidemic Dynamics With Incomplete Data , author=. JASA , volume=. 2021 , publisher=
2021
-
[79]
International Institute of Forecasters , year=
Comparing ensemble approaches for short-term probabilistic COVID-19 forecasts in the US , author=. International Institute of Forecasters , year=
-
[80]
PNAS , volume=
Can auxiliary indicators improve COVID-19 forecasting and hotspot prediction? , author=. PNAS , volume=. 2021 , publisher=
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.