DDPO-VC: Speaker De-Identification via Diffusion Denoising Policy Optimization
Pith reviewed 2026-07-03 23:34 UTC · model grok-4.3
The pith
Reinforcement learning post-training of diffusion models enables speaker de-identification while preserving correlated cognitive utility.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
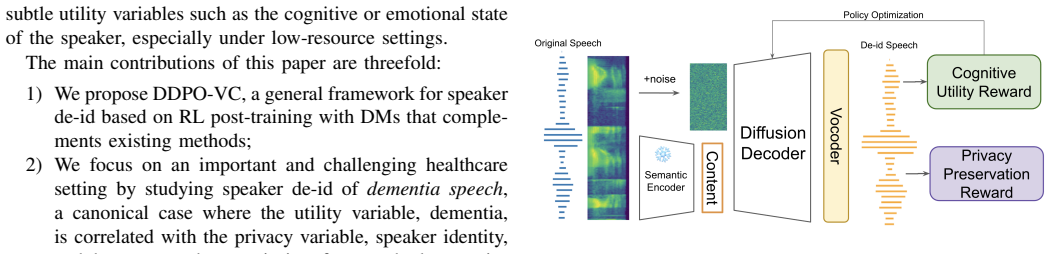
DDPO-VC performs speaker de-identification through reinforcement learning-based post-training of diffusion models for voice conversion, learning from combined reward signals supplied by privacy-focused and utility-focused teachers to manage correlations between speaker identity and cognitive status without leakage or utility loss.
What carries the argument
Diffusion denoising policy optimization (DDPO) for post-training voice conversion models with combined privacy and utility teacher rewards.
If this is right
- The approach outperforms strong de-identification baselines in privacy preservation on dementia speech benchmarks.
- Cognitive utility is maintained at higher levels than baselines on the same benchmarks.
- Correlations between identity and health status are handled without producing leakage or utility loss.
- The framework offers a general post-training recipe for diffusion-based conversion tasks facing similar trade-offs.
Where Pith is reading between the lines
- The same reward-combination strategy could extend to other modalities where identity correlates with sensitive attributes.
- Tuning the relative weighting of the two teacher rewards may allow controllable privacy-utility operating points.
- The method might apply to non-speech biometric data where identity and diagnostic signals are entangled.
Load-bearing premise
Reward signals from separate privacy-focused and utility-focused teachers can be combined during RL post-training without causing private information leakage or loss of downstream utility.
What would settle it
Running the method on the two dementia speech benchmarks and observing no gains over disentanglement baselines in both privacy and cognitive utility metrics would falsify the performance claim.
Figures
read the original abstract
A key challenge of speaker de-identification is the balance between privacy and utility. Many utility variables, such as the cognitive health status of the speaker, are correlated with the privacy variable, such as the speaker identity, violating the independence assumption held by the disentanglement-based approaches, causing leakage of private information and the loss of useful information for downstream tasks. To tackle this challenge, we propose a general framework, DDPO-VC, for speaker de-identification through reinforcement learning-based post-training with diffusion models. Learning from reward signals combining knowledge from privacy-focused and utility-focused teachers, our method outperforms various strong \deid/ methods in both privacy preservation and cognitive utility on two commonly used dementia speech benchmarks. Please check out our code\footnote{\href{https://github.com/cactuswiththoughts/DDPO-VC}{https://github.com/cactuswiththoughts/DDPO-VC}} and demo\footnote{\href{https://cactuswiththoughts.github.io/SpeakerDeID-Demo/}{https://cactuswiththoughts.github.io/SpeakerDeID-Demo/}}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DDPO-VC, a general framework for speaker de-identification that applies reinforcement learning-based post-training to diffusion models. It combines reward signals from separate privacy-focused and utility-focused teachers to address correlations between speaker identity and cognitive status (e.g., dementia-related attributes), claiming superior performance over strong de-identification baselines in both privacy preservation and downstream cognitive utility on two dementia speech benchmarks. Code and a demo are provided for reproducibility.
Significance. If the empirical results hold, the work offers a practical alternative to disentanglement-based de-identification methods by directly optimizing a combined reward that respects attribute correlations without explicit independence assumptions. The RL post-training formulation on diffusion models and the open code repository constitute verifiable strengths that could support follow-up work in privacy-preserving speech processing for clinical applications.
minor comments (3)
- The abstract states outperformance on benchmarks but does not name the specific metrics, baselines, or experimental design; adding a concise summary of these (e.g., EER for privacy, accuracy for cognitive utility) would improve readability without altering the technical content.
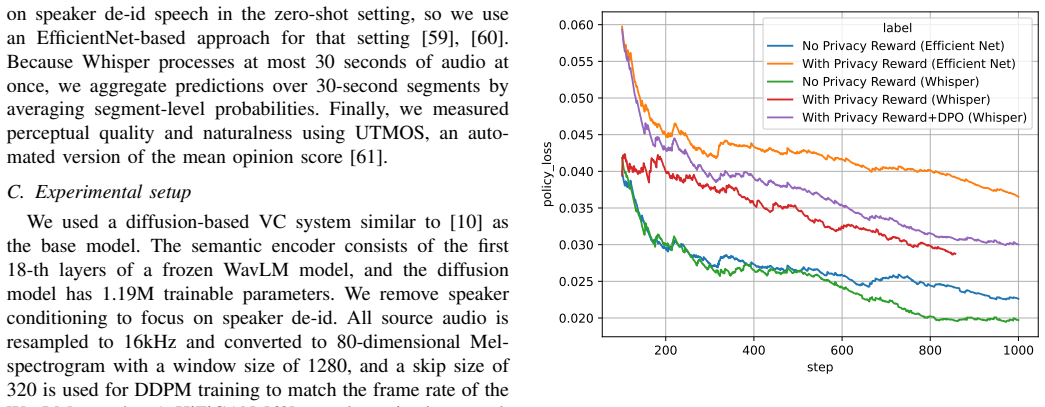
- Notation for the combined reward (privacy + utility teachers) should be introduced with an explicit equation in the method section to clarify how the two signals are weighted or fused during policy optimization.
- The paper references a GitHub repository and demo page; confirming that the released code includes the exact training configurations and evaluation scripts used for the reported benchmark numbers would strengthen reproducibility claims.
Simulated Author's Rebuttal
We thank the referee for the positive summary and recommendation of minor revision. No major comments were provided in the report, so we have no points to address point-by-point at this stage. We will incorporate any minor suggestions in the revised manuscript.
Circularity Check
No significant circularity detected
full rationale
The paper's central contribution is an empirical RL post-training framework (DDPO-VC) that combines reward signals from separate privacy and utility teachers to optimize a diffusion model for de-identification. Claims of outperformance are grounded in benchmark results on dementia speech datasets rather than any closed derivation, self-referential definition, or fitted parameter renamed as prediction. No equations, uniqueness theorems, or self-citations are invoked in a load-bearing way within the provided text; the method is presented as a direct response to disentanglement limitations, with reproducible code supplied as an independent verification path. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Consumer sentinel network data book 2024,
Federal Trade Commission, “Consumer sentinel network data book 2024,” Federal Trade Commission, Tech. Rep., Mar. 2025, includes identity theft report categories, including medical services identity theft reports for calendar year 2024. [Online]. Available: https: //www.ftc.gov/reports/consumer-sentinel-network-data-book-2024
2024
-
[2]
AutoVC: Zero-shot voice style transfer with only autoencoder loss,
K. Qian, Y . Zhang, S. Chang, X. Yang, and M. Hasegawa-Johnson, “AutoVC: Zero-shot voice style transfer with only autoencoder loss,” inICML, 2019, pp. 5210–5219. [Online]. Available: http: //proceedings.mlr.press/v97/qian19c.html
2019
-
[3]
W. Wanget al., “Vqmivc: Vector quantization and mutual information- based unsupervised speech representation disentanglement for one- shot voice conversion,” inInterspeech, 2021. [Online]. Available: https://arxiv.org/pdf/2106.10132
-
[4]
Can diffusion models disentangle? a theoretical perspective,
L. Wang, M. J. Mirza, Y . Gong, Y . Gong, J. Zhang, B. H. Tracey, K. Placek, M. Vilela, and J. R. Glass, “Can diffusion models disentangle? a theoretical perspective,” inNeurIPS, 2025. [Online]. Available: https://arxiv.org/abs/2504.00220
-
[5]
Generative modeling by estimating gradients of the data distribution,
Y . Song and S. Ermon, “Generative modeling by estimating gradients of the data distribution,” inNeural Information Processing System,
-
[6]
Generative Modeling by Estimating Gradients of the Data Distribution
[Online]. Available: https://arxiv.org/pdf/1907.05600
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[7]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” inAdvances in Neural Information Processing Systems, vol. 33, 2020, pp. 6840–6851
2020
-
[8]
Grad- TTS: A diffusion probabilistic model for text-to-speech,
V . Popov, I. V ovk, V . Gogoryan, T. Sadekova, and M. Kudinov, “Grad- TTS: A diffusion probabilistic model for text-to-speech,” inICML, ser. Proceedings of Machine Learning Research, vol. 139. PMLR, 2021
2021
-
[9]
Diffusion-based voice conversion with fast maximum likelihood sampling scheme,
V . Popov, I. V ovk, V . Gogoryan, T. Sadekova, M. S. Kudinov, and J. Wei, “Diffusion-based voice conversion with fast maximum likelihood sampling scheme,” inICLR, 2022. [Online]. Available: https://openreview.net/forum?id=8c50f-DoW Au
2022
-
[10]
Vevo: Control- lable zero-shot voice imitation with self-supervised disentanglement,
X. Zhang, X. Zhang, K. Peng, Z. Tang, V . Manohar, Y . Liu, J. Hwang, D. Li, Y . Wang, J. Chan, Y . Huang, Z. Wu, and M. Ma, “Vevo: Control- lable zero-shot voice imitation with self-supervised disentanglement,” in ICLR, 2025
2025
-
[11]
DiffVC+: Improving Diffusion-based V oice Conversion for Speaker Anonymization,
F. Huang, K. Zeng, and W. Zhu, “DiffVC+: Improving Diffusion-based V oice Conversion for Speaker Anonymization,” inInterspeech 2024, 2024, pp. 4453–4457
2024
-
[12]
Diffusion model alignment using direct preference optimization,
B. Wallace, M. Dang, R. Rafailov, L. Zhou, A. Lou, S. Purushwalkam, S. Ermon, C. Xiong, S. Joty, and N. Naik, “Diffusion model alignment using direct preference optimization,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024, pp. 8228–8238
2024
-
[13]
TriAAN- VC: Triple Adaptive Attention Normalization for Any-to-Any V oice Conversion,
H. J. Park, S. W. Yang, J. S. Kim, W. Shin, and S. W. Han, “TriAAN- VC: Triple Adaptive Attention Normalization for Any-to-Any V oice Conversion,” inICASSP, 2023
2023
-
[14]
LM-VC: Zero- shot voice conversion via speech generation based on language models,
Z. Wang, Y . Chen, L. Xie, Q. Tian, and Y . Wang, “LM-VC: Zero- shot voice conversion via speech generation based on language models,” IEEE Signal Processing Letters, vol. 30, pp. 1157–1161, 2023
2023
-
[15]
Emo-stargan: A semi-supervised any-to-many non-parallel emotion- preserving voice conversion,
S. Ghosh, A. Das, Y . Sinha, I. Siegert, T. Polzehl, and S. Stober, “Emo-stargan: A semi-supervised any-to-many non-parallel emotion- preserving voice conversion,” inProceedings of Interspeech 2023, 2023, pp. 1498–1502. [Online]. Available: https://arxiv.org/abs/2309.07586
-
[16]
Available: https://arxiv.org/abs/2403.03100
Z. Ju, Y . Wang, K. Shen, X. Tan, D. Xin, D. Yang, Y . Liu, Y . Leng, K. Song, S. Tanget al., “Naturalspeech 3: Zero-shot speech syn- thesis with factorized codec and diffusion models,”arXiv preprint arXiv:2403.03100, 2024
-
[17]
Speaker anonymisation using the mcadams coefficient,
J. Patino, N. Tomashenko, M. Todisco, A. Nautsch, and N. Evans, “Speaker anonymisation using the mcadams coefficient,” inInterspeech 2021, 2021, pp. 1099–1103
2021
-
[18]
Speaker anonymization using x-vector and neural waveform models,
F. Fang, X. Wang, J. Yamagishi, I. Echizen, M. Todisco, N. Evans, and J.-F. Bonastre, “Speaker anonymization using x-vector and neural waveform models,” inProceedings of the 10th ISCA Speech Synthesis Workshop, 2019
2019
-
[19]
Evaluating voice conversion-based privacy protection against informed attackers,
B. M. L. Srivastava, N. Vauquier, M. Sahidullah, A. Bellet, M. Tommasi, and E. Vincent, “Evaluating voice conversion-based privacy protection against informed attackers,” inICASSP, 2020, pp. 2802–2806
2020
-
[20]
Design choices for x-vector based speaker anonymization,
B. M. L. Srivastava, N. Tomashenko, X. Wang, E. Vincent, J. Yamagishi, M. Maouche, A. Bellet, and M. Tommasi, “Design choices for x-vector based speaker anonymization,” inInterspeech 2020, 2020, pp. 1693– 1697
2020
-
[21]
Speaker anonymization with distribution-preserving x-vector generation for the voiceprivacy challenge 2020,
H. Turner, G. Lovisotto, and I. Martinovic, “Speaker anonymization with distribution-preserving x-vector generation for the voiceprivacy challenge 2020,” inProceedings of the V oicePrivacy 2020 Challenge Workshop, 2020, challenge system description / preprint
2020
-
[22]
Asynchronous voice anonymization by learning from speaker-adversarial speech,
R. Wang, L. Chen, K. A. Lee, and Z.-H. Ling, “Asynchronous voice anonymization by learning from speaker-adversarial speech,”IEEE Signal Processing Letters, vol. 32, pp. 1905–1909, 2025
1905
-
[23]
Are disentangled repre- sentations all you need to build speaker anonymization systems?
P. Champion, D. Jouvet, and A. Larcher, “Are disentangled repre- sentations all you need to build speaker anonymization systems?” in Interspeech 2022, 2022, pp. 821–825
2022
-
[24]
Speaker anonymization using neural audio codec language models,
M. Panariello, F. Nespoli, M. Todisco, and N. Evans, “Speaker anonymization using neural audio codec language models,” inICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing, 2024, pp. 4725–4729
2024
-
[25]
Speaker anonymization with phonetic intermediate representations,
S. Meyer, F. Lux, P. Denisov, J. Koch, P. Tilli, and N. T. Vu, “Speaker anonymization with phonetic intermediate representations,” inInter- speech 2022, 2022, pp. 1983–1987
2022
-
[26]
EASY: Emotion-aware speaker anonymization via factorized distillation,
J. Yao, H. Liu, E. S. Chng, and L. Xie, “EASY: Emotion-aware speaker anonymization via factorized distillation,” inInterspeech 2025, 2025
2025
-
[27]
Anonymiz- ing speech with generative adversarial networks to preserve speaker privacy,
S. Meyer, P. Tilli, P. Denisov, F. Lux, J. Koch, and N. T. Vu, “Anonymiz- ing speech with generative adversarial networks to preserve speaker privacy,” in2022 IEEE Spoken Language Technology Workshop, 2022, pp. 912–919
2022
-
[28]
Private kNN-VC: Interpretable Anonymization of Converted Speech,
C. Franzreb, A. Das, T. Polzehl, and S. M ¨oller, “Private kNN-VC: Interpretable Anonymization of Converted Speech,” inInterspeech, 2025, pp. 3224–3228
2025
-
[29]
Differentially private speaker anonymization,
A. S. Shamsabadi, B. M. L. Srivastava, A. Bellet, N. Vauquier, E. Vin- cent, M. Maouche, M. Tommasi, and N. Papernot, “Differentially private speaker anonymization,”Proceedings on Privacy Enhancing Technolo- gies, vol. 2023, no. 1, pp. 98–114, 2023
2023
-
[30]
The third voiceprivacy challenge: Preserving emotional expressiveness and linguistic content in voice anonymization,
N. Tomashenko, X. Miao, P. Champion, S. Meyer, M. Panariello, X. Wang, N. Evans, E. Vincent, J. Yamagishi, and M. Todisco, “The third voiceprivacy challenge: Preserving emotional expressiveness and linguistic content in voice anonymization,” 2026
2026
-
[31]
Why disentanglement-based speaker anonymization systems fail at preserving emotions?
¨U. E. Gaznepoglu and N. Peters, “Why disentanglement-based speaker anonymization systems fail at preserving emotions?” inICASSP 2025 - 2025 IEEE International Conference on Acoustics, Speech and Signal Processing, 2025, pp. 1–5
2025
-
[32]
Ad- dressing challenges in speaker anonymization to maintain utility while ensuring privacy of pathological speech,
S. T. Arasteh, T. Arias-Vergara, P. A. P ´erez-Toro, T. Weise, K. Packh¨auser, M. Schuster, E. Noeth, A. Maier, S. H. Yanget al., “Ad- dressing challenges in speaker anonymization to maintain utility while ensuring privacy of pathological speech,”Communications Medicine, vol. 4, p. 182, 2024
2024
-
[33]
Distinctive and natural speaker anonymization via singular value transformation-assisted matrix,
J. Yao, Q. Wang, P. Guo, Z. Ning, and L. Xie, “Distinctive and natural speaker anonymization via singular value transformation-assisted matrix,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 32, pp. 2944–2956, 2024
2024
-
[34]
Deep reinforcement learning from human preferences,
P. F. Christiano, J. Leike, T. Brown, M. Martic, S. Legg, and D. Amodei, “Deep reinforcement learning from human preferences,” inAdvances in Neural Information Processing Systems, 2017
2017
-
[35]
Direct preference optimization: Your language model is secretly a reward model,
R. Rafailov, A. Sharma, E. Mitchell, C. D. Manning, S. Ermon, and C. Finn, “Direct preference optimization: Your language model is secretly a reward model,” inAdvances in Neural Information Processing Systems, 2023
2023
-
[36]
Reinforcement learning for emotional text-to-speech synthesis with improved emotion discriminability,
R. Liu, B. Sisman, and H. Li, “Reinforcement learning for emotional text-to-speech synthesis with improved emotion discriminability,” in Interspeech, 2021
2021
-
[37]
S. Hussain, P. Neekhara, X. Yang, E. Casanova, S. Ghosh, M. T. Desta, R. Fejgin, R. Valle, and J. Li, “Koel-TTS: Enhancing LLM based speech generation with preference alignment and classifier free guidance,”arXiv preprint arXiv:2502.05236, 2025
-
[38]
Robust zero- shot text-to-speech synthesis with reverse inference optimization,
Y . Hu, C. Chen, S. Wang, E. S. Chng, and C. Zhang, “Robust zero- shot text-to-speech synthesis with reverse inference optimization,”arXiv preprint arXiv:2407.02243, 2024
-
[39]
Re-ENACT: Reinforcement learn- ing for emotional speech generation using actor-critic strategy,
R. Shankar and A. Venkataraman, “Re-ENACT: Reinforcement learn- ing for emotional speech generation using actor-critic strategy,”arXiv preprint arXiv:2408.01892, 2024
-
[40]
Pref- erence alignment improves language model-based tts,
J. Tian, C. Zhang, J. Shi, H. Zhang, J. Yu, S. Watanabe, and D. Yu, “Pref- erence alignment improves language model-based tts,”arXiv preprint arXiv:2409.12403, 2024
-
[41]
Speechalign: Aligning speech generation to human preferences,
D. Zhang, Z. Li, S. Li, X. Zhang, P. Wang, Y . Zhou, and X. Qiu, “Speechalign: Aligning speech generation to human preferences,” in NeurIPS, 2024
2024
-
[42]
Differentiable reward optimization for llm based tts system,
C. Gao, Z. Du, and S. Zhang, “Differentiable reward optimization for llm based tts system,” inInterspeech, 2025
2025
-
[43]
Fine-grained preference optimization improves zero-shot text- to-speech,
J. Yao, Y . Yang, Y . Pan, Y . Feng, Z. Ning, J. Ye, H. Zhou, and L. Xie, “Fine-grained preference optimization improves zero-shot text- to-speech,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2025
2025
-
[44]
Align-slm: Textless spoken language models with reinforcement learning from ai feedback,
G.-T. Lin, P. G. Shivakumar, A. Gourav, Y . Gu, A. Gandhe, H. yi Lee, and I. Bulyko, “Align-slm: Textless spoken language models with reinforcement learning from ai feedback,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics, 2025
2025
-
[45]
Advancing zero-shot text-to-speech intelligibility across diverse domains via pref- erence alignment,
X. Zhang, Y . Wang, C. Wang, Z. Li, Z. Chen, and Z. Wu, “Advancing zero-shot text-to-speech intelligibility across diverse domains via pref- erence alignment,” inACL, 2025
2025
-
[46]
MPO: Multidimensional preference optimization for language model-based text-to-speech,
K. Xia, X. Zhu, J. Yao, and L. Xie, “MPO: Multidimensional preference optimization for language model-based text-to-speech,”arXiv preprint arXiv:2509.00685, 2025
-
[47]
Speechjudge: Towards human- level judgment for speech naturalness,
X. Zhang, C. Wang, H. Liao, Z. Li, Y . Wang, L. Wang, D. Jia, Y . Chen, X. Li, Z. Chen, and Z. Wu, “Speechjudge: Towards human- level judgment for speech naturalness,” inInternational Conference on Learning Representations, 2026
2026
-
[48]
GSRM: Generative speech reward model for speech rlhf,
M. Shen, T. Jayashankar, O. Hanna, N. Kanda, Y . Wang, K. ˇZmol´ıkov´a, R. Xie, N. Moritz, A. Xu, Y . Gaur, G. Wornell, Q. He, and J. Wu, “GSRM: Generative speech reward model for speech rlhf,”arXiv preprint arXiv:2602.13891, 2026
-
[49]
FlexiV oice: Enabling flexible style control in zero-shot TTS with natural language instructions,
D. Chen, X. Zhang, Y . Wang, K. Dai, L. Ma, and Z. Wu, “FlexiV oice: Enabling flexible style control in zero-shot TTS with natural language instructions,” inICLR, 2026
2026
-
[50]
VGPO: Fine-tuning speech autoregressive diffusion models with value guided policy optimization,
Z. Liu, D. Jia, Y . A. Li, C. Du, X. Zhuang, Z. Chen, Y . Wang, Y . Wang, S. Wang, and H. Li, “VGPO: Fine-tuning speech autoregressive diffusion models with value guided policy optimization,” 2026, submitted to International Conference on Learning Representations. [Online]. Available: https://openreview.net/pdf?id=LLWIaUZvEu
2026
-
[51]
Training diffusion models with reinforcement learning,
K. Black, M. Janner, Y . Du, I. Kostrikov, and S. Levine, “Training diffusion models with reinforcement learning,” inInternational Conference on Learning Representations, 2024. [Online]. Available: https://openreview.net/forum?id=YCWjhGrJFD
2024
-
[52]
J. Chen, J.-S. Byun, M. Elsner, and A. Perrault, “DLPO: Diffusion model loss-guided reinforcement learning for fine-tuning text-to-speech diffusion models,”arXiv preprint arXiv:2405.14632, 2024
-
[53]
Wavlm: Large-scale self-supervised pre-training for full stack speech processing,
S. Chen, C. Wang, Z. Chen, Y . Wu, S. Liu, Z. Chen, J. Li, N. Kanda, T. Yoshioka, X. Xiao, J. Wu, L. Zhou, S. Ren, Y . Qian, Y . Qian, J. Wu, M. Zeng, and F. Wei, “Wavlm: Large-scale self-supervised pre-training for full stack speech processing,”arXiv, 2021
2021
-
[54]
Ecapa-tdnn: Em- phasized channel attention, propagation and aggregation in tdnn based speaker verification,
B. Desplanques, J. Thienpondt, and K. Demuynck, “Ecapa-tdnn: Em- phasized channel attention, propagation and aggregation in tdnn based speaker verification,” inInterspeech, 2020
2020
-
[55]
Recognizing dementia from neuropsychological tests with state space models,
L. Wang, S. Bhati, C. Karjadi, R. Au, and J. Glass, “Recognizing dementia from neuropsychological tests with state space models,” in 2025 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU). Honolulu, HI, USA: IEEE, 2025, pp. 1–7
2025
-
[56]
Alzheimer’s dementia recognition through spontaneous speech: The ADReSS Challenge,
S. Luz, F. Haider, S. de la Fuente, D. Fromm, and B. MacWhinney, “Alzheimer’s dementia recognition through spontaneous speech: The ADReSS Challenge,” inInterspeech, Shanghai, China, 2020. [Online]. Available: https://arxiv.org/abs/2004.06833
-
[57]
Role-specific language models for processing recorded neuropsychological exams,
T. Al Hanai, R. Au, and J. Glass, “Role-specific language models for processing recorded neuropsychological exams,” inProceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, V olume 2 (Short Papers), M. Walker, H. Ji, and A. Stent, Eds. New Orleans, Louisiana: Associat...
2018
-
[58]
Leveraging pretrained representations with task-related keywords for alzheimer’s disease detection,
J. Li, K. Song, J. Li, B. Zheng, D. Li, X. Wu, X. Liu, and H. Meng, “Leveraging pretrained representations with task-related keywords for alzheimer’s disease detection,” inArXiv, 2023. [Online]. Available: https://arxiv.org/pdf/2303.08019.pdf
-
[59]
Robust speech recognition via large-scale weak super- vision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak super- vision,” inICML, 2023
2023
-
[60]
Efficientnet: Rethinking model scaling for convolutional neural networks,
M. Tan and Q. V . Le, “Efficientnet: Rethinking model scaling for convolutional neural networks,” inICML, vol. 97. PMLR, 2019, pp. 6105–6114. [Online]. Available: http://proceedings.mlr.press/v97/ tan19a.html
2019
-
[61]
Detecting dementia from long neuropsychological interviews,
N. Dawalatabad, Y . Gong, S. Khurana, R. Au, and J. Glass, “Detecting dementia from long neuropsychological interviews,” inFindings of the Association for Computational Linguistics: EMNLP 2022. Abu Dhabi, United Arab Emirates: Association for Computational Linguistics, 2022, pp. 5270–5283. [Online]. Available: https://aclanthology.org/ 2022.findings-emnlp.386/
2022
-
[62]
The t05 system for the VoiceMOS Challenge 2024: Transfer learning from deep image classifier to naturalness MOS prediction of high-quality synthetic speech,
K. Baba, W. Nakata, Y . Saito, and H. Saruwatari, “The t05 system for the VoiceMOS Challenge 2024: Transfer learning from deep image classifier to naturalness MOS prediction of high-quality synthetic speech,” inIEEE Spoken Language Technology Workshop (SLT), 2024, pp. 818–824
2024
-
[63]
HiFi-GAN: Generative adversarial networks for efficient and high fidelity speech synthesis,
J. Kong, J. Kim, and J. Bae, “HiFi-GAN: Generative adversarial networks for efficient and high fidelity speech synthesis,” inNeural Information Processing System, vol. 33, 2020, pp. 17 022–17 033
2020
-
[64]
V oice Conversion With Just Nearest Neighbors,
M. Baas, B. van Niekerk, and H. Kamper, “V oice Conversion With Just Nearest Neighbors,” inInterspeech, 2023
2023
-
[65]
LinearVC: Linear transformations of self-supervised features through the lens of voice conversion,
H. Kamper, B. van Niekerk, J. Za ¨ıdi, and M.-A. Carbonneau, “LinearVC: Linear transformations of self-supervised features through the lens of voice conversion,” inInterspeech, 2025
2025
-
[66]
Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers
C. Wang, S. Chen, Y . Wu, Z. Zhang, L. Zhou, S. Liu, Z. Chen, Y . Liu, H. Wang, J. Li, L. He, S. Zhao, and F. Wei, “Neural codec language models are zero-shot text to speech synthesizers,”arXiv preprint arXiv:2301.02111, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.