Anytime-valid Optimal Policy Identification
Pith reviewed 2026-06-26 23:46 UTC · model grok-4.3
The pith
A time-indexed set retains the true optimal policy with high probability at every time step, allowing data-dependent stopping for identification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
When the optimal policy is unique, we define a stopping time for its identification and derive a sample-complexity bound scaling as O((log |Π| + log log(1/Δ_min))/Δ_min²), where Δ_min is the gap between the best and second-best policy values. The construction rests on a time-indexed set S_t that retains the true optimal policy set uniformly over time with high probability under a fixed but uncontrolled logging policy.
What carries the argument
The time-indexed set S_t that retains the true optimal policy set uniformly over time with high probability under a fixed logging policy.
If this is right
- The analyst can monitor policy values continuously and eliminate clearly suboptimal policies while preserving valid inference.
- When the optimum is unique the procedure stops at a data-dependent time whose expected size is bounded by O((log |Π| + log log(1/Δ_min))/Δ_min²).
- Simulations show the anytime-valid rule can produce substantial sample savings relative to any fixed-N design.
- The same construction supplies a dynamic view of accumulating evidence in an applied adaptive experiment on misinformation reduction.
Where Pith is reading between the lines
- The uniform-over-time guarantee may extend to slowly changing logging policies if the construction of S_t is adapted to track the instantaneous logging distribution.
- The sample-complexity bound suggests the method could be competitive with fixed-sample optimal-policy identification when the number of candidate policies is moderate and gaps are not tiny.
- Because the procedure eliminates policies sequentially, it may reduce computational cost in large policy classes by avoiding evaluation of already-eliminated candidates at later times.
Load-bearing premise
The time-indexed set S_t can be constructed to retain the true optimal policy set uniformly over time with high probability under a fixed but uncontrolled logging policy.
What would settle it
In repeated simulations with a known unique optimum and known gap Δ_min, the fraction of runs in which S_t fails to contain the optimum at the claimed stopping time exceeds the nominal error probability.
Figures
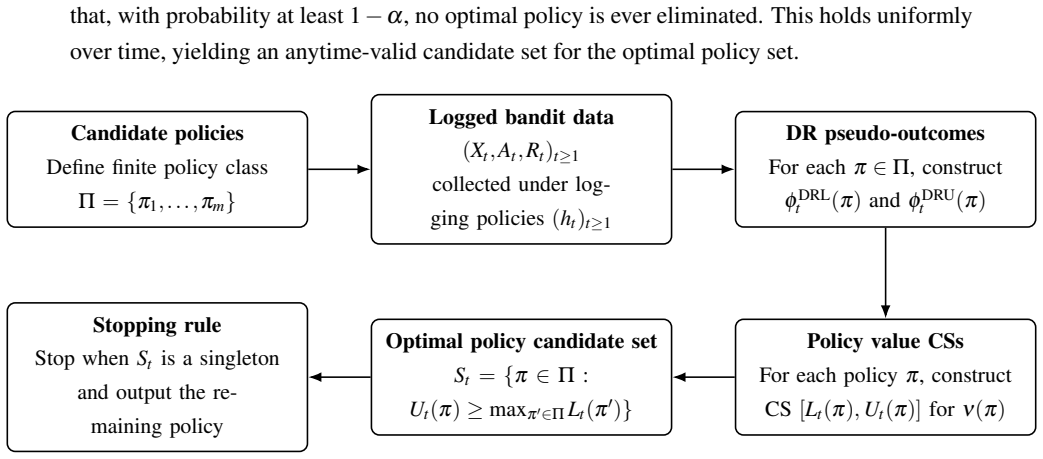
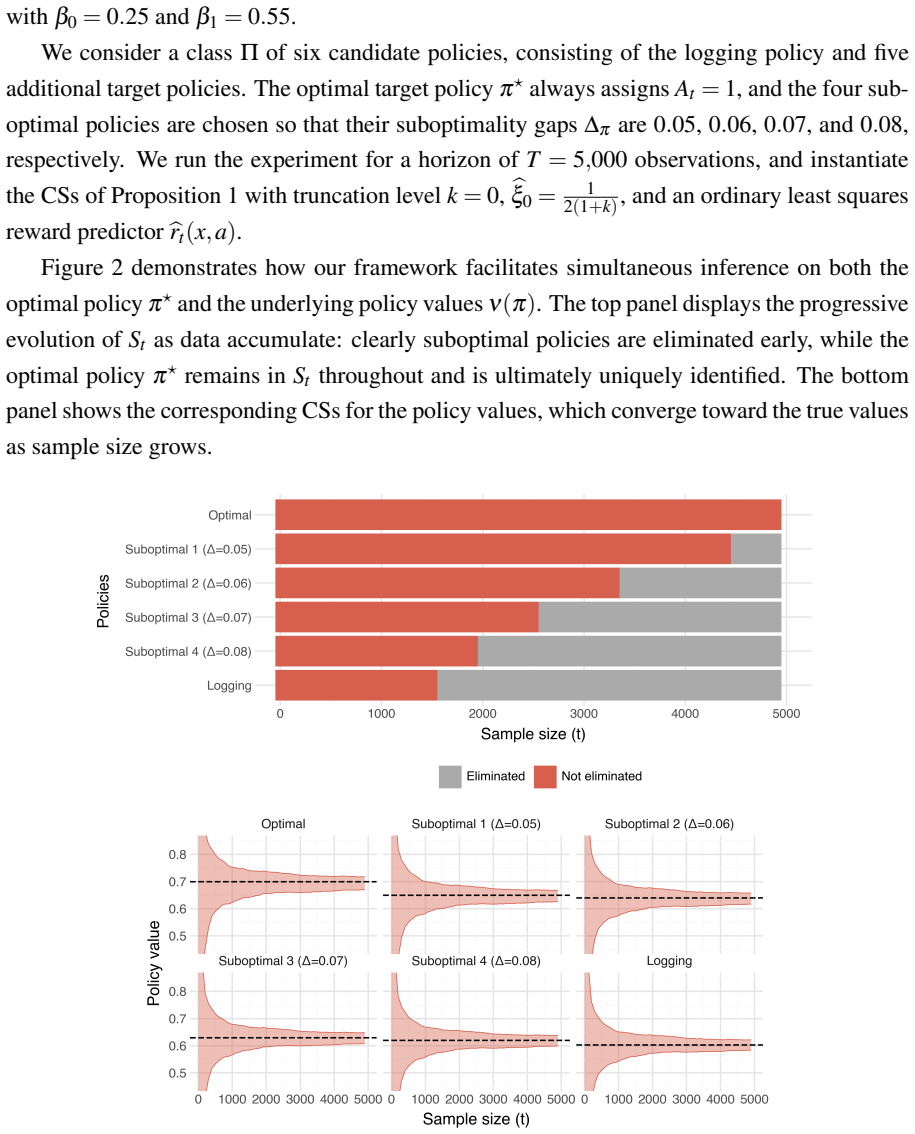
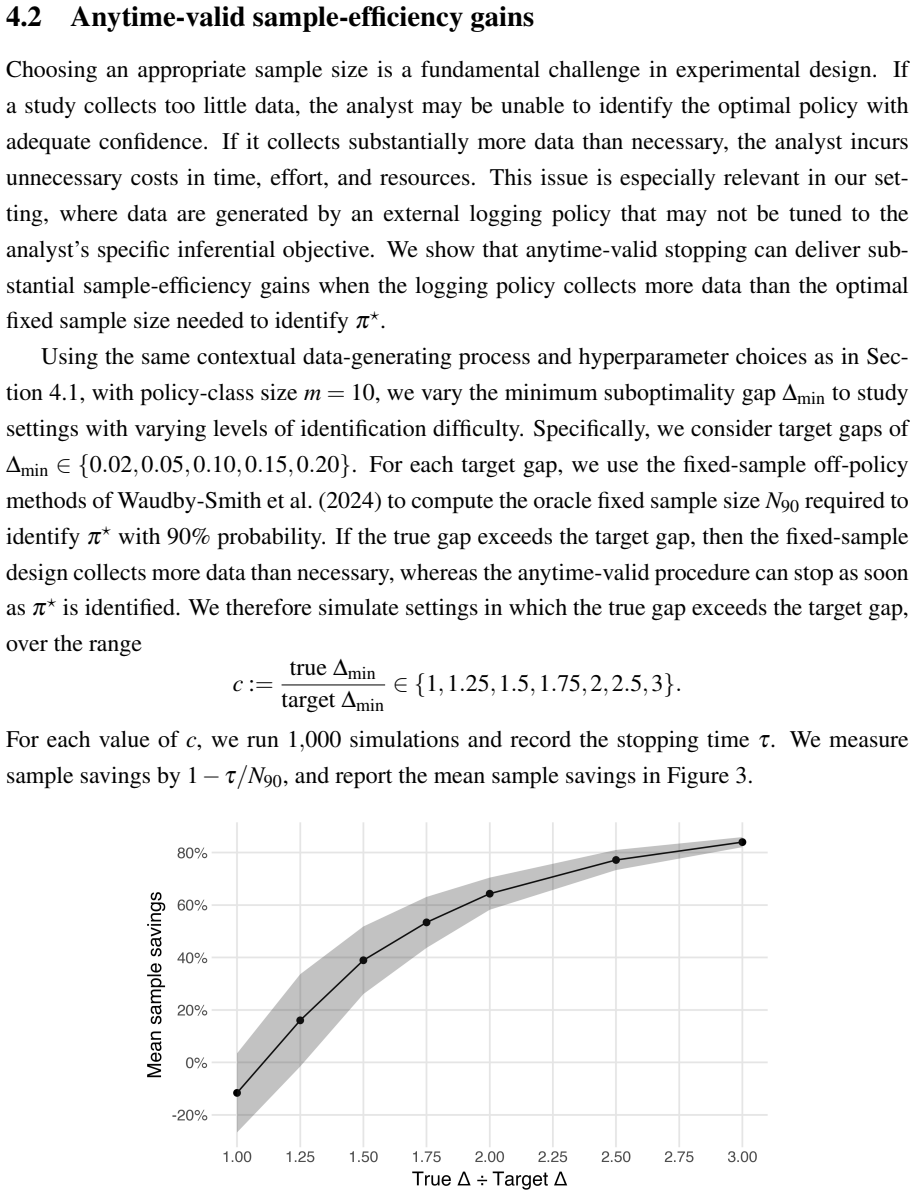
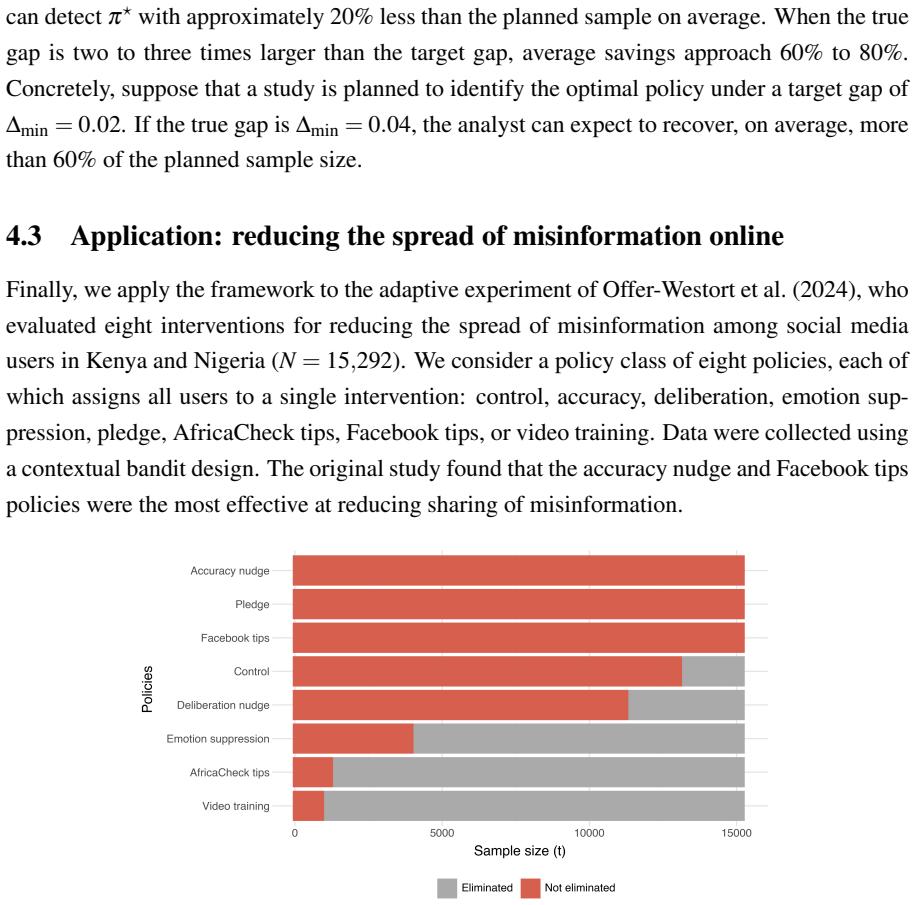
read the original abstract
We develop an anytime-valid framework for optimal policy identification from logged contextual bandit data. In many applied settings, the analyst wants to select the optimal policy from a candidate policy class $\Pi$, but data are generated by an externally determined logging policy that they do not control. The analyst may also wish to monitor evidence continuously, stopping once the optimal policy is clear rather than committing to a fixed sample size in advance. This paper addresses these challenges by constructing a time-indexed set $S_t$ that retains the true optimal policy set uniformly over time with high probability. The resulting procedure allows the analyst to monitor policy values, eliminate clearly suboptimal policies, and stop at data-dependent times without invalidating inference. When the optimal policy is unique, we define a stopping time for its identification and derive a sample-complexity bound scaling as $O\!\left(\frac{\log |\Pi|+\log\log(1/\Delta_{\min})}{\Delta_{\min}^2}\right)$, where $\Delta_{\min}$ is the gap between the best and second-best policy values. Simulations demonstrate that the anytime-valid approach can yield substantial sample savings relative to fixed-$N$ designs. An application to a large adaptive experiment on reducing misinformation online illustrates how the method provides a dynamic view as evidence on the optimal policy accumulates.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops an anytime-valid framework for optimal policy identification from logged contextual bandit data generated by an uncontrolled logging policy. It constructs a time-indexed set S_t that retains the true optimal policy set uniformly over time with high probability, enabling continuous monitoring, elimination of suboptimal policies, and data-dependent stopping without invalidating inference. When the optimal policy is unique, a stopping time is defined with sample-complexity bound O((log |Π| + log log(1/Δ_min))/Δ_min²), where Δ_min is the gap to the second-best policy. The claims are supported by simulations showing sample savings over fixed-N designs and an application to an adaptive experiment on reducing online misinformation.
Significance. If the uniform retention property of S_t and the derived bound hold under the stated conditions, the work would be significant for sequential policy learning in settings where sample sizes cannot be fixed in advance. The bound recovers the standard dependence on 1/Δ_min² up to logarithmic factors, with the extra log log term arising naturally from anytime validity; this is a reasonable tradeoff. The empirical components (simulations and real-data application) provide concrete evidence of practical utility in adaptive experiments.
major comments (2)
- [Abstract] The central construction of the time-indexed set S_t (abstract, paragraph 2) is asserted to retain the true optimal policy uniformly over t with high probability under a fixed logging policy, but the abstract provides no derivation, assumptions on reward variance or context distribution, or proof sketch. This property is load-bearing for both the stopping time and the sample-complexity bound; the full manuscript must supply the explicit construction and the uniform concentration argument.
- [Abstract] The sample-complexity bound O((log |Π| + log log(1/Δ_min))/Δ_min²) is stated for the unique-optimum case (abstract, final paragraph), but it is unclear whether the log log term arises from a standard union-bound or from a more refined anytime-valid martingale argument; the manuscript should clarify the precise inequality used and confirm that the bound remains valid when the logging policy is fixed and uncontrolled.
minor comments (2)
- [Abstract] Notation for the policy class Π and the gap Δ_min should be introduced with explicit definitions before the bound is stated.
- The simulations section would benefit from reporting the exact logging policy used and the number of Monte Carlo replications to allow reproducibility.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and recommendation of minor revision. We address the two major comments below with clarifications and targeted revisions to improve readability of the abstract and main text.
read point-by-point responses
-
Referee: [Abstract] The central construction of the time-indexed set S_t (abstract, paragraph 2) is asserted to retain the true optimal policy uniformly over t with high probability under a fixed logging policy, but the abstract provides no derivation, assumptions on reward variance or context distribution, or proof sketch. This property is load-bearing for both the stopping time and the sample-complexity bound; the full manuscript must supply the explicit construction and the uniform concentration argument.
Authors: The full manuscript supplies the explicit construction of S_t in Section 3 (Definition 1 and Algorithm 1), the uniform concentration argument via a time-uniform Freedman-type martingale inequality (Theorem 1), and the required assumptions (bounded rewards with variance proxy 1/4, fixed uncontrolled logging policy, and context distribution in Assumption 1). The abstract is intentionally concise per journal norms, but we have revised it to include a parenthetical pointer to Section 3 and the key assumption of bounded rewards. No derivation is added to the abstract itself due to length constraints, but the load-bearing property is now cross-referenced. revision: yes
-
Referee: [Abstract] The sample-complexity bound O((log |Π| + log log(1/Δ_min))/Δ_min²) is stated for the unique-optimum case (abstract, final paragraph), but it is unclear whether the log log term arises from a standard union-bound or from a more refined anytime-valid martingale argument; the manuscript should clarify the precise inequality used and confirm that the bound remains valid when the logging policy is fixed and uncontrolled.
Authors: The log log(1/Δ_min) term arises from the refined anytime-valid martingale argument (a peeling argument over dyadic time scales combined with a Freedman-type inequality, see the proof of Theorem 3), not a naive union bound. We have revised the manuscript to state the precise inequality (the time-uniform bound in Equation (4) of Section 3) and explicitly confirm validity under the fixed uncontrolled logging policy, as all concentration holds conditionally on the observed contexts and actions generated by that policy. The bound derivation is unchanged. revision: yes
Circularity Check
No significant circularity; derivation self-contained
full rationale
The abstract presents the construction of the time-indexed set S_t as a methodological step that yields a uniform high-probability guarantee, from which the stopping time and the O((log |Π| + log log(1/Δ_min))/Δ_min²) sample-complexity bound are then derived when the optimum is unique. This bound takes the standard form arising from concentration inequalities under a fixed gap Δ_min and policy class size, without any indication that it reduces by construction to a fitted parameter or to a self-referential definition of S_t itself. No load-bearing self-citation, ansatz smuggling, or renaming of known results is visible in the provided description. The central claim therefore retains independent content from the uniform guarantee and does not collapse to its inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Anytime-valid off-policy inference for contextual bandits , url =
Waudby-Smith, Ian and Wu, Lili and Ramdas, Aaditya and Karampatziakis, Nikos and Mineiro, Paul , month = aug, year =. Anytime-valid off-policy inference for contextual bandits , url =. doi:10.48550/arXiv.2210.10768 , abstract =
-
[2]
Karampatziakis, Nikos and Mineiro, Paul and Ramdas, Aaditya , month = feb, year =. Off-policy. doi:10.48550/arXiv.2102.09540 , abstract =
-
[3]
Off-policy estimation with adaptively collected data: the power of online learning , isbn =
Lee, Jeonghwan and Ma, Cong , year =. Off-policy estimation with adaptively collected data: the power of online learning , isbn =. Advances in. doi:10.52202/079017-4255 , urldate =
-
[4]
Li, Zhaoqi and Ratliff, Lillian and Nassif, Houssam and Jamieson, Kevin and Jain, Lalit , month = jul, year =. Instance-optimal. doi:10.48550/arXiv.2207.02357 , abstract =
-
[5]
Garivier, Aurélien and Kaufmann, Emilie , month = jun, year =. Optimal. doi:10.48550/arXiv.1602.04589 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1602.04589
-
[6]
Tirinzoni, Andrea and Degenne, Rémy , month = oct, year =. On. doi:10.48550/arXiv.2205.10936 , abstract =
-
[7]
Molitor, Daniel and Gold, Samantha , month = jun, year =. Anytime-. doi:10.48550/arXiv.2506.20523 , abstract =
-
[8]
Jamieson, Kevin and Malloy, Matthew and Nowak, Robert and Bubeck, Sébastien , month = dec, year =. lil'. doi:10.48550/arXiv.1312.7308 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1312.7308
-
[9]
Kuzborskij, Ilja and Vernade, Claire and György, András and Szepesvári, Csaba , month = mar, year =. Confident. doi:10.48550/arXiv.2006.10460 , abstract =
-
[10]
Uehara, Masatoshi and Shi, Chengchun and Kallus, Nathan , month = dec, year =. A. doi:10.48550/arXiv.2212.06355 , abstract =
-
[11]
Time-uniform, nonparametric, nonasymptotic confidence sequences , volume =. The Annals of Statistics , author =. 2021 , note =. doi:10.1214/20-AOS1991 , abstract =
-
[12]
Wagenmaker, Andrew and Jamieson, Kevin , month = jul, year =. Instance-. doi:10.48550/arXiv.2207.02575 , abstract =
-
[13]
Al-Marjani, Aymen and Tirinzoni, Andrea and Kaufmann, Emilie , month = oct, year =. Towards. doi:10.48550/arXiv.2311.05638 , abstract =
-
[14]
Lindon, Michael and Ham, Dae Woong and Tingley, Martin and Bojinov, Iavor , month = jul, year =. Anytime-. doi:10.48550/arXiv.2210.08589 , abstract =
-
[15]
Mason, Blake and Jain, Lalit and Tripathy, Ardhendu and Nowak, Robert , month = sep, year =. Finding. doi:10.48550/arXiv.2006.08850 , abstract =
-
[16]
Bibaut, Aurélien and Chambaz, Antoine and Dimakopoulou, Maria and Kallus, Nathan and Laan, Mark van der , month = jun, year =. Post-. doi:10.48550/arXiv.2106.00418 , abstract =
-
[17]
and Zhan, Ruohan and Wager, Stefan and Athey, Susan , month = feb, year =
Hadad, Vitor and Hirshberg, David A. and Zhan, Ruohan and Wager, Stefan and Athey, Susan , month = feb, year =. Confidence. doi:10.48550/arXiv.1911.02768 , abstract =
-
[18]
and Janson, Lucas and Murphy, Susan A
Zhang, Kelly W. and Janson, Lucas and Murphy, Susan A. , month = nov, year =. Statistical. doi:10.48550/arXiv.2104.14074 , abstract =
-
[19]
Zanette, Andrea and Dong, Kefan and Lee, Jonathan and Brunskill, Emma , month = jul, year =. Design of. doi:10.48550/arXiv.2107.09912 , abstract =
-
[20]
Jedra, Yassir and Proutiere, Alexandre , month = jun, year =. Optimal. doi:10.48550/arXiv.2006.16073 , abstract =
-
[21]
Dudik, Miroslav and Langford, John and Li, Lihong , month = may, year =. Doubly. doi:10.48550/arXiv.1103.4601 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1103.4601
-
[22]
Sequential Experimental Design for Transductive Linear Bandits
Fiez, Tanner and Jain, Lalit and Jamieson, Kevin and Ratliff, Lillian , month = jun, year =. Sequential. doi:10.48550/arXiv.1906.08399 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1906.08399 1906
-
[23]
Nature Human Behaviour , author =
Battling the coronavirus ‘infodemic’ among social media users in. Nature Human Behaviour , author =. 2024 , pages =. doi:10.1038/s41562-023-01810-7 , language =
-
[24]
Journal of Human Resources , author =
More. Journal of Human Resources , author =. 2019 , pages =. doi:10.3368/jhr.54.3.0317-8637R , language =
-
[25]
Li, Lihong and Chu, Wei and Langford, John and Schapire, Robert E. , month = apr, year =. A. Proceedings of the 19th international conference on. doi:10.1145/1772690.1772758 , abstract =
-
[26]
Soare, Marta and Lazaric, Alessandro and Munos, Rémi , month = nov, year =. Best-. doi:10.48550/arXiv.1409.6110 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1409.6110
-
[27]
Degenne, Rémy and Ménard, Pierre and Shang, Xuedong and Valko, Michal , month = jul, year =. Gamification of. doi:10.48550/arXiv.2007.00953 , abstract =
-
[28]
Athey, Susan and Wager, Stefan , month = sep, year =. Policy. doi:10.48550/arXiv.1702.02896 , abstract =
-
[29]
Operations Research , author =
Always. Operations Research , author =. 2022 , pages =. doi:10.1287/opre.2021.2135 , abstract =
-
[30]
Optimal and Adaptive Off-policy Evaluation in Contextual Bandits
Wang, Yu-Xiang and Agarwal, Alekh and Dudik, Miroslav , month = nov, year =. Optimal and. doi:10.48550/arXiv.1612.01205 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1612.01205
-
[31]
Leiner, James and Dunn, Robin and Ramdas, Aaditya , month = feb, year =. Adaptive. doi:10.48550/arXiv.2509.14218 , abstract =
-
[32]
Proceedings of the AAAI Conference on Artificial Intelligence , author =
High-. Proceedings of the AAAI Conference on Artificial Intelligence , author =. 2015 , file =. doi:10.1609/aaai.v29i1.9541 , abstract =
-
[33]
Multiple Identifications in Multi-Armed Bandits
Bubeck, Sébastien and Wang, Tengyao and Viswanathan, Nitin , month = may, year =. Multiple. doi:10.48550/arXiv.1205.3181 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1205.3181
-
[34]
Top-m identification for linear bandits , url =
Réda, Clémence and Kaufmann, Emilie and Delahaye-Duriez, Andrée , month = mar, year =. Top-m identification for linear bandits , url =. doi:10.48550/arXiv.2103.10070 , abstract =
-
[35]
Jun, Kwang-Sung and Nowak, Robert , editor =. Anytime. Proceedings of. 2016 , pages =
2016
-
[36]
An optimal algorithm for the Thresholding Bandit Problem
Locatelli, Andrea and Gutzeit, Maurilio and Carpentier, Alexandra , month = may, year =. An optimal algorithm for the. doi:10.48550/arXiv.1605.08671 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1605.08671
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.