Characterizing Opinion Evolution of Networked LLMs
Pith reviewed 2026-06-27 20:09 UTC · model grok-4.3
The pith
A bias term representing regression to an innate opinion lets opinion dynamics models track LLM networks with up to 88 percent lower error.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
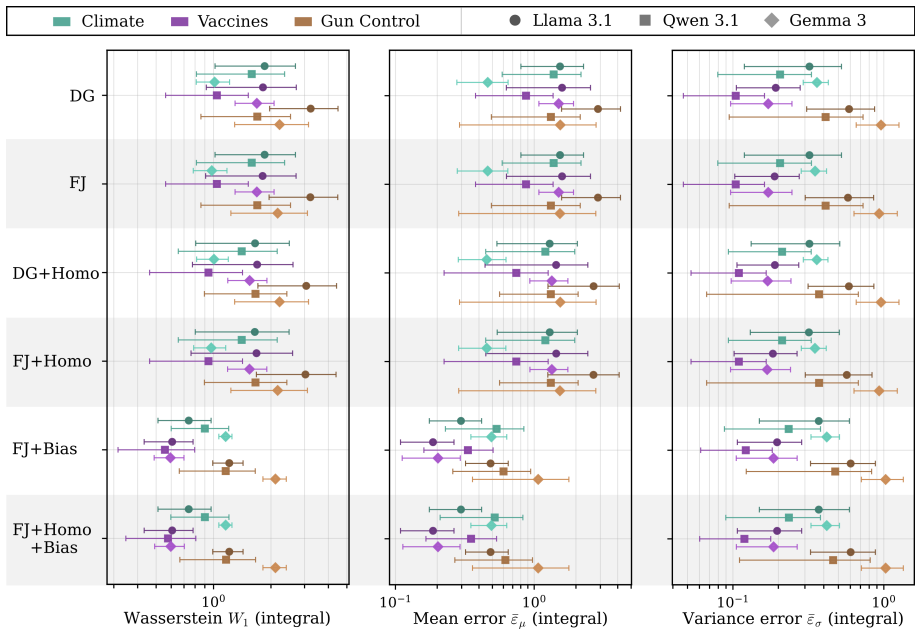
While naive averaging-style opinion dynamics models fail to track the opinion evolution of networked large language models, the addition of a bias term—an innate opinion toward which agents regress—yields substantial improvements, reducing cumulative estimated mean opinion error by up to 88 percent, with the result generalizing across model families, discussion topics, and networks.
What carries the argument
A bias term added to averaging-based opinion dynamics models that captures each agent's regression toward a fixed innate opinion.
If this is right
- Naive averaging rules are insufficient for modeling LLM opinion changes.
- Bias acts as a primary driver of opinion dynamics in LLM networks.
- Modified models with the bias term generalize across model families, topics, and network structures.
- Opinion forecasts in multi-agent LLM systems should account for regression to innate opinions.
Where Pith is reading between the lines
- Designers of LLM-driven social platforms may need to monitor or adjust innate biases to shape collective outcomes.
- The bias finding could guide prompt engineering that deliberately sets or counters regression points in multi-agent simulations.
- Extending the models to include time-varying bias might capture how LLMs update their innate opinions during prolonged interactions.
Load-bearing premise
The experimental interactions and opinion measurements used in the study are representative of LLM behavior in broader networked settings rather than being shaped by prompt design or evaluation choices specific to the tested conditions.
What would settle it
Running the same interaction protocol on a new LLM family or network topology and finding that the bias term produces no comparable reduction in prediction error.
Figures
read the original abstract
Large language models (LLMs) increasingly interact with one another in multi-agent systems, from simulations of human discourse to influence operations and fully LLM-driven social platforms. These interactions give rise to new regimes of opinion propagation that are not yet well understood. We investigate whether classical opinion dynamics models, which have long been used to explain how interactions shape collective beliefs in human societies, can capture the behavior of LLM networks. We find that, while naive averaging-style models fail to track LLMs' opinion dynamics, simple modifications yield substantial gains in modeling fidelity. In particular, bias, an innate opinion toward which agents regress, emerges as a significant driver of LLM opinion dynamics, with its inclusion reducing cumulative estimated mean opinion error by up to 88%. We additionally find that these conclusions generalize across model families, discussion topics, and networks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that classical averaging-based opinion dynamics models fail to capture the evolution of opinions in networks of interacting LLMs, but that augmenting them with an innate per-agent bias term (to which opinions regress) yields substantial improvements, reducing cumulative mean opinion error by up to 88%. These conclusions are reported to generalize across LLM families, discussion topics, and network topologies.
Significance. If the empirical results hold after addressing identifiability concerns, the work would indicate that LLM opinion trajectories contain a strong regressive component absent from standard models, with direct relevance to multi-agent LLM simulations and influence operations. The reported generalization across models and topics is a positive feature that strengthens the case for broader applicability.
major comments (2)
- [Experimental results] Experimental results (presumably §4 or equivalent): the abstract and results claim up to 88% error reduction from adding the bias term, yet provide no comparisons against other single-parameter modifications (e.g., global scaling of interaction weights or additive noise) and no use of cross-validation or information criteria. This is load-bearing for the central claim that bias specifically, rather than added flexibility, drives the improvement.
- [Methods] Methods and experimental protocol sections: the manuscript reports quantitative gains but supplies no information on whether the 88% figure reflects a pre-specified analysis, the precise definition of cumulative mean opinion error, statistical controls for multiple comparisons, or robustness to prompt variations. These omissions prevent assessment of whether the experimental interactions are representative or shaped by evaluation choices.
minor comments (1)
- [Model definition] Notation for the bias term and its integration into the update rule should be made fully explicit with an equation number, as the current description leaves the functional form of regression ambiguous.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below with clarifications on our experimental design and indicate planned revisions where appropriate.
read point-by-point responses
-
Referee: Experimental results (presumably §4 or equivalent): the abstract and results claim up to 88% error reduction from adding the bias term, yet provide no comparisons against other single-parameter modifications (e.g., global scaling of interaction weights or additive noise) and no use of cross-validation or information criteria. This is load-bearing for the central claim that bias specifically, rather than added flexibility, drives the improvement.
Authors: The bias term is theoretically motivated by the observed regressive behavior in LLM opinion trajectories, which is distinct from arbitrary flexibility. We acknowledge that explicit comparisons would better isolate its contribution. In the revision we will add single-parameter baselines using global scaling of interaction weights and additive noise, along with cross-validation and information criteria (AIC/BIC) to evaluate whether the bias term provides unique explanatory power. revision: yes
-
Referee: Methods and experimental protocol sections: the manuscript reports quantitative gains but supplies no information on whether the 88% figure reflects a pre-specified analysis, the precise definition of cumulative mean opinion error, statistical controls for multiple comparisons, or robustness to prompt variations. These omissions prevent assessment of whether the experimental interactions are representative or shaped by evaluation choices.
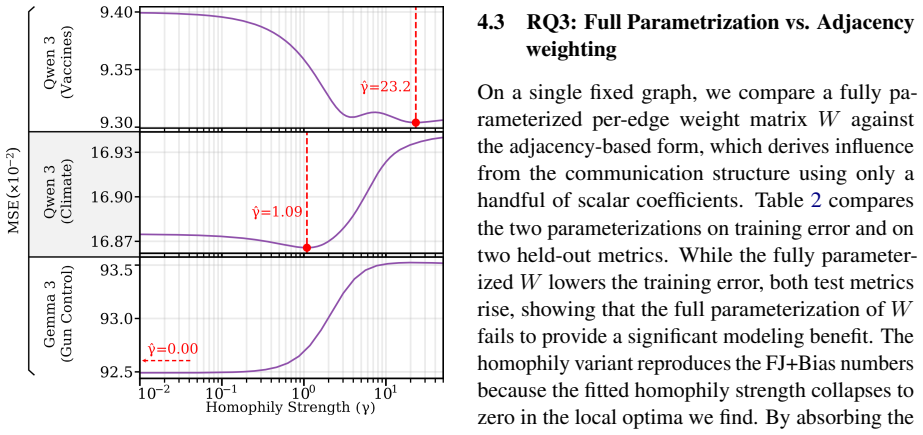
Authors: The cumulative mean opinion error is defined in Section 3.2 as the time-integrated absolute deviation between predicted and observed opinions. The reported 88% figure is the maximum reduction across configurations. The protocol was pre-specified from the model derivations. No multiple-comparison correction was applied because the primary contrast was between the baseline averaging model and the bias-augmented model, with generalization tested across independent factors. We will add explicit robustness checks to prompt variations in the revision. revision: partial
Circularity Check
No circularity: empirical error reduction from model variants
full rationale
The paper reports an empirical finding that adding a bias term to opinion dynamics models reduces observed error on LLM interaction data by up to 88%. This is a direct comparison of fitted models against measured trajectories rather than any derivation in which the target quantity is defined in terms of the fitted bias or obtained by renaming inputs. No equations, self-citations, or uniqueness claims are presented that would reduce the central result to its own inputs by construction. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- bias term
Reference graph
Works this paper leans on
-
[1]
Generative language models and automated influence operations: Emerging threats and potential mitigations.arXiv preprint arXiv:2301.04246, 1. Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al- Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, and 1 others. 2024. The llama 3 herd of models.arXiv pr...
arXiv 2024
-
[2]
Matteo Marchi, João Pedro Silvestre, Stefano Soatto, Pratik Chaudhari, and Paulo Tabuada
Springer. Matteo Marchi, João Pedro Silvestre, Stefano Soatto, Pratik Chaudhari, and Paulo Tabuada. 2025. Boil- ing frogs: Generative models, synthetic data, and the opinions of their users. In2025 IEEE 64th Confer- ence on Decision and Control (CDC), pages 1112–
2025
-
[3]
IEEE. Xinyi Mou, Zhongyu Wei, and Xuan-Jing Huang. 2024. Unveiling the truth and facilitating change: Towards agent-based large-scale social movement simulation. InFindings of the Association for Computational Linguistics: ACL 2024, pages 4789–4809. Mark Newman. 2018.Networks. Oxford University Press. OpenAI. text-embedding-3-small. https: //developers.op...
Pith/arXiv arXiv 2024
-
[4]
Reaffirm the existing prompt template used for initial opinion assignment
-
[5]
Sample up to 10 posts uniformly at random from neighboring agents that influence the current agent according to the graph structure
-
[6]
Append stylistic constraints to the prompt, in- cluding instructions to avoid emojis, excessive special characters, hashtags, and engagement- bait phrasing
-
[7]
Retrieve the agent’s rolling history of inter- nal justifications generated during previous posting steps
-
[8]
The agent is encouraged to produce new reasoning, examples, or claims while avoiding repetition of earlier arguments
Generate a short internal justification condi- tioned on the initialization opinion, sampled neighboring posts, and prior justification his- tory. The agent is encouraged to produce new reasoning, examples, or claims while avoiding repetition of earlier arguments. The generated justification is appended to the rolling history, which is truncated to retain...
-
[9]
Llama 3.1 on climate change:
Generate the final social media post condi- tioned on the internal justification generated in the previous step. We next give examples of generated posts. A.2.3 Example posts Gemma 3 on vaccines and autism: "The numbers don’t lie. A recent Ger- man study of 92 children who died be- fore age five, all vaccinated within 12 months, revealed an average alumin...
2020
-
[10]
interface to solve the quadratic programs required to fit the opinion dynamics model. For the non-linear program required to fit a fully parameterized Friedkin-Johnsen model with bias and homophily effects, we used a SciPy (Virtanen et al., 2020) implementation of a sequential least-squares quadratic program solver5. To initialize the solver, we used 1.10...
2020
-
[11]
The optimal solution found when fitting the model without homophily
-
[12]
A.3.2 Convex reformulations for opinion dynamics fitting problems We reformulate some of the model-fitting problems to remove non-convex components
The optimal solution found when fitting the model without homophily, along with an initial γ value of0.1. A.3.2 Convex reformulations for opinion dynamics fitting problems We reformulate some of the model-fitting problems to remove non-convex components. In particular, consider the following optimization problem in which we want to fit a Friedkin-Johnsen ...
-
[13]
Optimization problem(12)is convex
-
[14]
5https://docs.scipy.org/doc/scipy/reference/optimize.minimize-slsqp.html 15
Optimization problems(11)and(12)have the same optimal value. 5https://docs.scipy.org/doc/scipy/reference/optimize.minimize-slsqp.html 15
-
[15]
Then ( ˜W ∗/(1−λ ∗ 1 −λ ∗ 2), λ∗ 1, λ∗ 2,˜b∗/λ∗ 2)is an optimal solution to(11)
Let ( ˜W ∗, λ∗ 1, λ∗ 2,˜b∗) be an optimal solution to (12) such that λ∗ 1 +λ ∗ 2 <1 and λ∗ 2 >0 . Then ( ˜W ∗/(1−λ ∗ 1 −λ ∗ 2), λ∗ 1, λ∗ 2,˜b∗/λ∗ 2)is an optimal solution to(11). Proof:1) The optimization problem (12) is a quadratic program (QP) and is thus convex
-
[16]
Let (W, λ1, λ2, b) be a feasible solution to (11)
We prove this statement by constructing mappings between the feasible sets of these problems that preserve value. Let (W, λ1, λ2, b) be a feasible solution to (11). The tuple ( ˜W , λ1, λ2,˜b) = ((1−λ 1 − λ2)W, λ1, λ2, λ2b) is then a feasible solution to (12), and the objective value at this solution for problem (12) is X r∈R H−1X t=1 ||z(r)(t+ 1)−(λ 1z(r...
-
[17]
By the above argument, we know that the objective value of the solution ( ˜W ∗/(1−λ ∗ 1 −λ ∗ 2), λ∗ 1, λ∗ 2,˜b∗/λ∗
Let ( ˜W ∗, λ∗ 1, λ∗ 2,˜b∗) be an optimal solution to (12) such that λ∗ 1 +λ ∗ 2 <1 and λ∗ 2 >0 , and let the objective value be f ∗ convex. By the above argument, we know that the objective value of the solution ( ˜W ∗/(1−λ ∗ 1 −λ ∗ 2), λ∗ 1, λ∗ 2,˜b∗/λ∗
-
[18]
in (11) is equal to f ∗ convex. Additionally, letting f ∗ non-convex denote the optimal value for (12), and using the fact that f ∗ convex =f ∗ non-convex, we conclude that ( ˜W ∗/(1−λ ∗ 1 − λ∗ 2), λ∗ 1, λ∗ 2,˜b∗/λ∗ 2)is an optimal solution to (11).□ Remark 1.In the case where λ∗ 1 +λ ∗ 2 = 1, the social interaction component is zero, and we can simply se...
arXiv 2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.