Evaluating Learned Spatial Indexes
Pith reviewed 2026-06-26 18:55 UTC · model grok-4.3
The pith
A workload-based decision tree selects learned spatial indexes that achieve near-optimal query performance on real data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Through experiments with a common storage backend and standardized pipelines, the study shows that a workload-based decision tree synthesized from findings on block size, skew, cost balances, and generalization recommends indexes which, on real OpenStreetMap point sets, exhibit minimal decision regret and typically yield near-optimal query performance.
What carries the argument
The workload-based decision tree for index selection, which encodes comparative experimental results on learned spatial indexes under controlled variations in skew, selectivity, and storage.
Load-bearing premise
The representative set of learned indexes and the common storage backend framework capture the dominant performance trade-offs that would appear in production spatial database deployments.
What would settle it
Applying the decision tree to additional real-world spatial point sets and finding that its recommendations frequently produce high decision regret or query times far from optimal would falsify the generalization result.
Figures

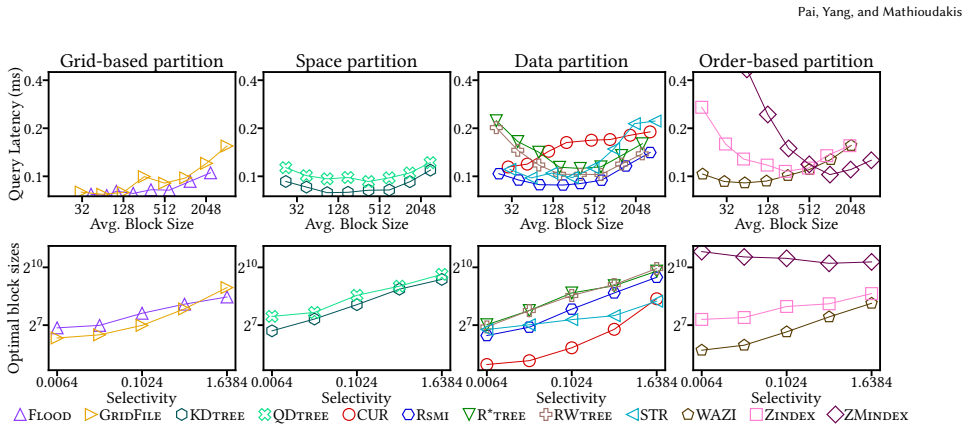
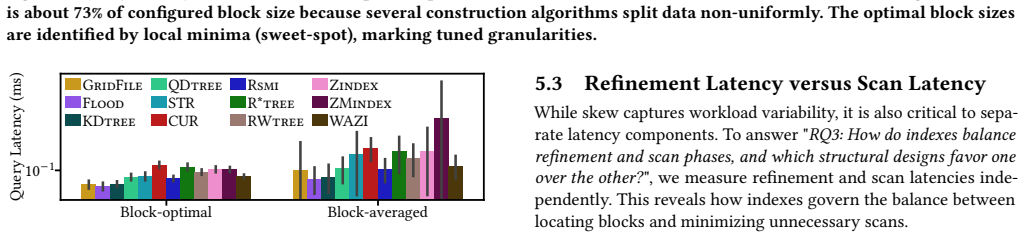
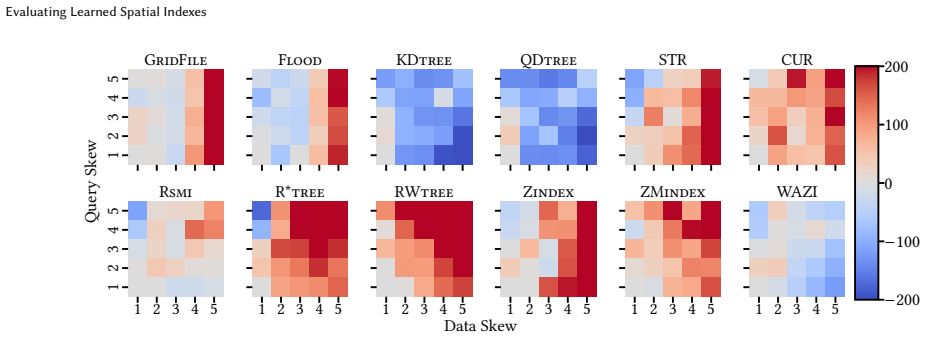
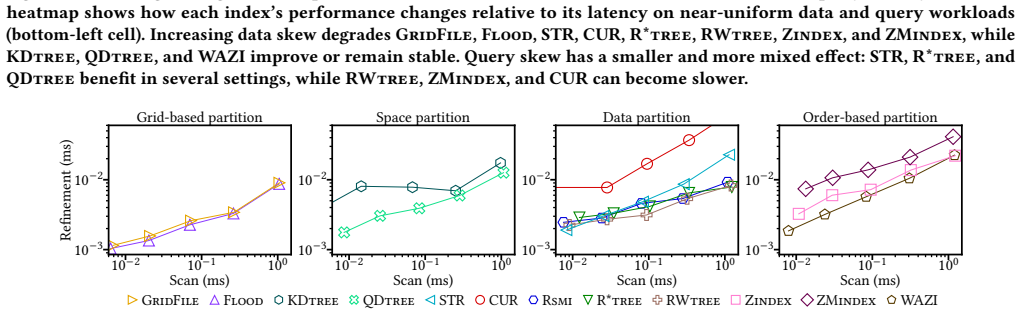
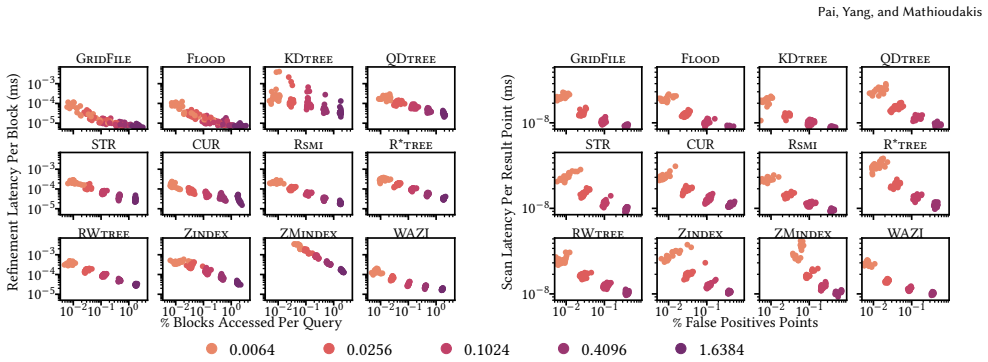
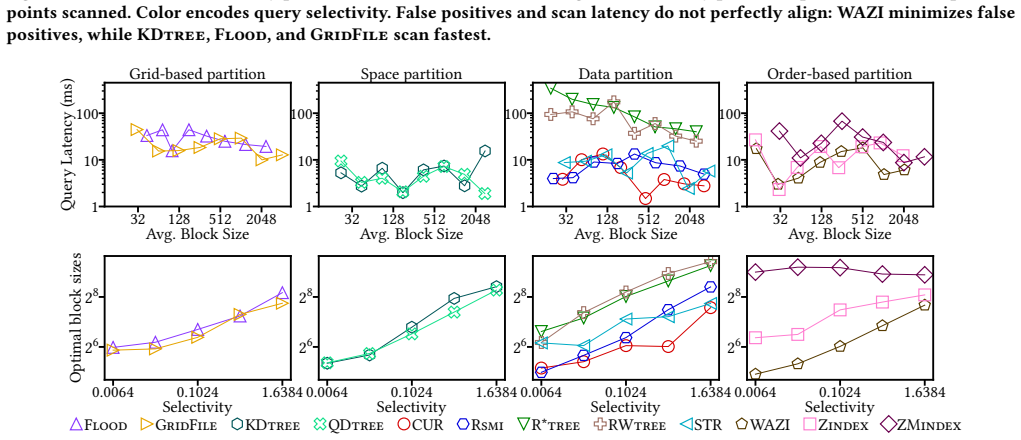


read the original abstract
Learned indexes improve query performance by adapting search structures to data and workload distributions. Although many learned indexes have been proposed, their trade-offs remain insufficiently understood for spatial range queries, where performance depends not only on model accuracy but also on data and query skew, layout granularity, selectivity, and storage behavior. In this work, we perform an experimental study of learned indexes for spatial range queries. We examine a representative set of indexes and address seven fundamental questions: (1) How does block size influence query latency, and what configurations yield optimal performance under varying selectivities? (2) How do skewed data and query distributions impact index performance? (3) How do indexes balance refinement and scan costs, and which designs favor one over the other? (4) How do disk-based storage conditions alter optimal block size and latency trade-offs compared to in-memory settings? (5) What are the construction costs of different indexes, and under what query volumes are these costs amortized? (6) For a given data and query workload, which index is expected to perform best? (7) Do index-selection insights learned from synthetic data generalize to real-world data distributions? To enable the analysis, we use a framework with a common storage backend, standardized query execution pipelines, and controlled variations in data and query skew. Our experiments reveal critical insights into refinement vs. scan trade-offs, the impact of block size, and the interplay between selectivity and layout effectiveness. We synthesize these findings into a workload-based decision tree for index selection and validate it on real OpenStreetMap point sets with synthetic queries, confirming that its recommendations exhibit minimal decision regret and typically yield near-optimal query performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript performs a controlled experimental study of learned indexes for spatial range queries. Using a unified framework with a common storage backend and standardized query pipelines, it addresses seven questions on block-size effects, data/query skew, refinement-vs-scan trade-offs, disk vs. in-memory behavior, construction-cost amortization, workload-specific index selection, and generalization from synthetic to real data. The authors synthesize the results into a workload-based decision tree and validate the tree on real OpenStreetMap point sets with synthetic queries, claiming that its recommendations exhibit minimal decision regret and typically yield near-optimal performance.
Significance. If the framework's observed trade-offs prove representative, the decision tree offers a concrete, workload-driven heuristic that could guide index selection in spatial databases. The controlled variation of skew and selectivity plus the real-data validation step are positive elements that move beyond purely synthetic micro-benchmarks.
major comments (2)
- [Abstract / experimental framework] Abstract and the section describing the experimental framework: the central claim that the synthesized decision tree produces near-optimal performance on real OSM data rests on the assumption that the chosen representative indexes plus the single common storage backend surface the dominant latency, refinement/scan, and amortization trade-offs that appear in production spatial DB deployments. No external anchor (comparison to a production engine such as PostGIS or to omitted index families) is provided to show that the observed orderings and optimal block sizes would persist outside the framework.
- [Validation on real OpenStreetMap data] Validation section (real OSM experiments): the claim of 'minimal decision regret' is load-bearing for the utility of the decision tree, yet the manuscript does not report how regret is quantified, the number of distinct workloads evaluated, variance across runs, or any statistical test establishing that the observed performance is reliably near-optimal rather than an artifact of post-hoc workload selection.
minor comments (2)
- [Abstract] The abstract states that queries are 'synthetic' even on real point sets; a brief description of the query-generation procedure (distribution, selectivity sampling) would improve clarity without altering the central claims.
- [Figures] Figure captions and axis labels should explicitly state whether reported latencies are means, medians, or 95th percentiles and whether error bars represent standard deviation or confidence intervals.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. Below we provide point-by-point responses to the two major comments.
read point-by-point responses
-
Referee: [Abstract / experimental framework] Abstract and the section describing the experimental framework: the central claim that the synthesized decision tree produces near-optimal performance on real OSM data rests on the assumption that the chosen representative indexes plus the single common storage backend surface the dominant latency, refinement/scan, and amortization trade-offs that appear in production spatial DB deployments. No external anchor (comparison to a production engine such as PostGIS or to omitted index families) is provided to show that the observed orderings and optimal block sizes would persist outside the framework.
Authors: Our experimental design intentionally employs a unified storage backend and standardized query pipelines to isolate the effects of learned index structures, data skew, query selectivity, and block size. This controlled setting enables the derivation of the decision tree by systematically varying the factors listed in the seven research questions. We selected a representative set of learned indexes based on prior literature to cover the main design axes (model-based vs. tree-based, refinement vs. scan). We acknowledge that the absence of direct comparisons to production systems such as PostGIS or to additional index families limits claims about absolute generalizability; the observed orderings are specific to the studied configurations. In the revision we will add an explicit limitations paragraph stating that the decision tree is a heuristic derived within this framework and that validating its recommendations against full-featured spatial database engines remains future work. revision: partial
-
Referee: [Validation on real OpenStreetMap data] Validation section (real OSM experiments): the claim of 'minimal decision regret' is load-bearing for the utility of the decision tree, yet the manuscript does not report how regret is quantified, the number of distinct workloads evaluated, variance across runs, or any statistical test establishing that the observed performance is reliably near-optimal rather than an artifact of post-hoc workload selection.
Authors: We agree that the validation section requires additional quantitative detail. Decision regret will be defined as the relative latency increase of the decision-tree recommendation versus the empirically best index for each workload. The validation comprises 50 distinct workloads constructed from OpenStreetMap point sets by varying query selectivity and spatial distribution. In the revised manuscript we will report mean regret together with standard deviation across the 50 workloads and include a non-parametric statistical test (Wilcoxon signed-rank) comparing the decision tree against the per-workload oracle. These additions will be placed in a new subsection of the validation section. revision: yes
Circularity Check
No significant circularity; empirical derivation from measurements
full rationale
The paper conducts controlled experiments on a representative set of learned spatial indexes within a shared storage backend and query pipeline. Performance metrics (latency, refinement/scan costs, construction overhead) are measured under variations in block size, selectivity, data/query skew. The workload-based decision tree is synthesized directly from these observed trade-offs and then validated on independent real OpenStreetMap point sets with synthetic queries, reporting minimal decision regret. No equation, parameter fit, or self-citation reduces the central claim to its own inputs by construction. The study is self-contained against external benchmarks and does not invoke uniqueness theorems or ansatzes from prior author work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Chi, Lyric Doshi, Tim Kraska, Xiaozhou Li, Andy Ly, and Christopher Olston
Hussam Abu-Libdeh, Deniz Altinbüken, Alex Beutel, Ed H. Chi, Lyric Doshi, Tim Kraska, Xiaozhou Li, Andy Ly, and Christopher Olston. 2020. Learned Indexes for a Google-scale Disk-based Database.CoRRabs/2012.12501 (2020). arXiv:2012.12501 https://arxiv.org/abs/2012.12501
arXiv 2020
-
[2]
Rudolf Bayer. 1997. The Universal B-Tree for Multidimensional Indexing: General Concepts. InWorldwide Computing and Its Applications, International Conference, WWCA ’97, Tsukuba, Japan, March 10-11, 1997, Proceedings (Lecture Notes in Com- puter Science, Vol. 1274), Takashi Masuda, Yoshifumi Masunaga, and Michiharu Tsukamoto (Eds.). Springer, 198–209. doi...
-
[3]
Norbert Beckmann, Hans-Peter Kriegel, Ralf Schneider, and Bernhard Seeger
-
[4]
The R*-Tree: An Efficient and Robust Access Method for Points and Rectangles. InProceedings of the 1990 ACM SIGMOD International Conference on Management of Data, Atlantic City, NJ, USA, May 23-25, 1990, Hector Garcia- Molina and H. V. Jagadish (Eds.). ACM Press, 322–331. doi:10.1145/93597.98741
-
[5]
Norbert Beckmann and Bernhard Seeger. 2009. A Revised R*-Tree in Comparison with Related Index Structures. InProceedings of the 2009 ACM SIGMOD Interna- tional Conference on Management of Data. ACM, Providence Rhode Island USA, 799–812. doi:10.1145/1559845.1559929
-
[6]
Jon Louis Bentley. 1975. Multidimensional Binary Search Trees Used for Associa- tive Searching.Commun. ACM18, 9 (Sept. 1975), 509–517. doi:10.1145/361002. 361007
-
[7]
Minguk Choi, Seehwan Yoo, and Jongmoo Choi. 2024. Can Learned Indexes Be Built Efficiently? A Deep Dive into Sampling Trade-offs.Proceedings of the ACM on Management of Data2, 3 (May 2024), 1–25. doi:10.1145/3654919
-
[8]
Haowen Dong, Chengliang Chai, Yuyu Luo, Jiabin Liu, Jianhua Feng, and Chao- qun Zhan. 2022. RW-Tree: A Learned Workload-aware Framework for R-tree Construction. In2022 IEEE 38th International Conference on Data Engineering (ICDE). 2073–2085. doi:10.1109/ICDE53745.2022.00201
-
[9]
Paolo Ferragina and Giorgio Vinciguerra. 2020. The PGM-index: A Fully- Dynamic Compressed Learned Index with Provable Worst-Case Bounds.Pro- ceedings of the VLDB Endowment13, 8 (April 2020), 1162–1175. doi:10.14778/ 3389133.3389135
arXiv 2020
-
[10]
Jiake Ge, Boyu Shi, Yanfeng Chai, Yuanhui Luo, Yunda Guo, Yinxuan He, and Yunpeng Chai. 2023. Cutting Learned Index into Pieces: An In-depth Inquiry into Updatable Learned Indexes. In2023 IEEE 39th International Conference on Data Engineering (ICDE). 315–327. doi:10.1109/ICDE55515.2023.00031
-
[11]
Tu Gu, Kaiyu Feng, Gao Cong, Cheng Long, Zheng Wang, and Sheng Wang. 2023. The RLR-Tree: A Reinforcement Learning Based R-Tree for Spatial Data.Proc. ACM Manag. Data1, 1, Article 63 (May 2023), 26 pages. doi:10.1145/3588917
-
[12]
Antonin Guttman. 1984. R-Trees: A Dynamic Index Structure for Spatial Search- ing. InSIGMOD’84, Proceedings of Annual Meeting, Boston, Massachusetts, USA, June 18-21, 1984, Beatrice Yormark (Ed.). ACM Press, 47–57. doi:10.1145/602259. 602266
-
[13]
Fuma Hidaka and Yusuke Matsui. 2024. FlexFlood: Efficiently Updatable Learned Multi-dimensional Index.CoRRabs/2411.09205 (2024). arXiv:2411.09205 doi:10. 48550/ARXIV.2411.09205
arXiv 2024
-
[14]
Andreas Kipf, Ryan Marcus, Alexander van Renen, Mihail Stoian, Alfons Kemper, Tim Kraska, and Thomas Neumann. 2019. SOSD: A Benchmark for Learned Indexes.CoRRabs/1911.13014 (2019). arXiv:1911.13014 http://arxiv.org/abs/ 1911.13014
arXiv 2019
-
[15]
Chi, Jeffrey Dean, and Neoklis Polyzotis
Tim Kraska, Alex Beutel, Ed H. Chi, Jeffrey Dean, and Neoklis Polyzotis. 2018. The Case for Learned Index Structures. InProceedings of the 2018 International Conference on Management of Data (SIGMOD ’18). Association for Computing Machinery, New York, NY, USA, 489–504. doi:10.1145/3183713.3196909
-
[16]
Shane Culpepper, and Renata Borovica-Gajic
Hai Lan, Zhifeng Bao, J. Shane Culpepper, and Renata Borovica-Gajic. 2023. Updatable Learned Indexes Meet Disk-Resident DBMS - From Evaluations to Design Choices.Proceedings of the ACM on Management of Data1, 2 (June 2023), 1–22. doi:10.1145/3589284
-
[17]
Leutenegger, Jeffrey Edgington, and Mario Alberto López
S.T. Leutenegger, M.A. Lopez, and J. Edgington. 1997. STR: A Simple and Efficient Algorithm for R-tree Packing. InProceedings 13th International Conference on Data Engineering. 497–506. doi:10.1109/ICDE.1997.582015
-
[18]
Pengfei Li, Hua Lu, Qian Zheng, Long Yang, and Gang Pan. 2020. LISA: A Learned Index Structure for Spatial Data. InProceedings of the 2020 International Conference on Management of Data, SIGMOD Conference 2020, online conference [Portland, OR, USA], June 14-19, 2020, David Maier, Rachel Pottinger, AnHai Doan, Wang-Chiew Tan, Abdussalam Alawini, and Hung Q...
-
[19]
Lingbo Liu, Zhenghong Peng, Hao Wu, Hongzan Jiao, Yang Yu, and Jie Zhao
-
[20]
Fast Identification of Urban Sprawl Based on K-Means Clustering with Population Density and Local Spatial Entropy.Sustainability10, 8 (July 2018),
2018
-
[21]
doi:10.3390/su10082683
-
[22]
Pingping Liu, Zhuang Miao, Huili Guo, Yeran Wang, and Ni Ai. 2018. Adding Spatial Distribution Clue to Aggregated Vector in Image Retrieval.EURASIP Journal on Image and Video Processing2018, 1 (Feb. 2018), 9. doi:10.1186/s13640- 018-0247-0
-
[23]
Qiyu Liu, Maocheng Li, Yuxiang Zeng, Yanyan Shen, and Lei Chen. 2025. How Good Are Multi-Dimensional Learned Indexes? An Experimental Survey.The VLDB Journal34, 2 (Jan. 2025), 17. doi:10.1007/s00778-024-00893-6
-
[24]
Marcel Maltry and Jens Dittrich. 2022. A Critical Analysis of Recursive Model Indexes.Proceedings of the VLDB Endowment15, 5 (Jan. 2022), 1079–1091. doi:10. 14778/3510397.3510405
arXiv 2022
-
[25]
Ryan Marcus, Andreas Kipf, Alexander van Renen, Mihail Stoian, Sanchit Misra, Alfons Kemper, Thomas Neumann, and Tim Kraska. 2020. Benchmarking Learned Indexes.Proceedings of the VLDB Endowment14, 1 (Sept. 2020), 1–13. arXiv:2006.12804 doi:10.14778/3421424.3421425
-
[26]
Volker Markl. 2000. Mistral - Processing Relational Queries using a Multidimen- sional Access Technique.Datenbank Rundbr.26 (2000), 24–25
2000
-
[27]
Vikram Nathan, Jialin Ding, Mohammad Alizadeh, and Tim Kraska. 2020. Learn- ing Multi-Dimensional Indexes. InProceedings of the 2020 International Conference on Management of Data, SIGMOD Conference 2020, online conference [Portland, OR, USA], June 14-19, 2020, David Maier, Rachel Pottinger, AnHai Doan, Wang- Chiew Tan, Abdussalam Alawini, and Hung Q. Ngo...
-
[28]
Mathias Neufang, Emma Pajak, Damien van de Berg, Ye Seol Lee, and Ehecatl Antonio del Rio Chanona. 2024. Surrogate-Based Optimization Techniques for Process Systems Engineering. arXiv:2412.13948 doi:10.48550/arXiv.2412.13948
-
[29]
Jürg Nievergelt, Hans Hinterberger, and Kenneth C. Sevcik. 1981. The Grid File: An Adaptable, Symmetric Multi-Key File Structure. InTrends in Information Processing Systems, 3rd Conference of the European Cooperation in Informatics, Munich, Germany, October 20-22, 1981, Proceedings (Lecture Notes in Computer Science, Vol. 123), A. J. W. Duijvestijn and Pe...
-
[30]
OpenStreetMap contributors. 2025. OpenStreetMap Planet Dump. https://www. openstreetmap.org
2025
-
[31]
Sachith Pai, Michael Mathioudakis, and Yanhao Wang. 2024. WaZI: A Learned and Workload-aware Z-Index. InProceedings 27th International Conference on Extending Database Technology, EDBT 2024, Paestum, Italy, March 25 - March 28, Letizia Tanca, Qiong Luo, Giuseppe Polese, Loredana Caruccio, Xavier Oriol, and Donatella Firmani (Eds.). OpenProceedings.org, 55...
-
[32]
Jianzhong Qi, Guanli Liu, Christian S. Jensen, and Lars Kulik. 2020. Effectively Learning Spatial Indices.Proceedings of the VLDB Endowment13, 12 (Aug. 2020), 2341–2354. doi:10.14778/3407790.3407829
-
[33]
Nestor V. Queipo, Raphael T. Haftka, Wei Shyy, Tushar Goel, Rajkumar Vaidyanathan, and P. Kevin Tucker. 2005. Surrogate-Based Analysis and Opti- mization.Progress in Aerospace Sciences41, 1 (Jan. 2005), 1–28. doi:10.1016/j. paerosci.2005.02.001
work page doi:10.1016/j 2005
-
[34]
K.A. Ross, I. Sitzmann, and P.J. Stuckey. 2001. Cost-Based Unbalanced R-trees. InProceedings Thirteenth International Conference on Scientific and Statistical Database Management. SSDBM 2001. 203–212. doi:10.1109/SSDM.2001.938552
-
[35]
Zhaoyan Sun, Xuanhe Zhou, and Guoliang Li. 2023. Learned Index: A Compre- hensive Experimental Evaluation.Proc. VLDB Endow.16, 8 (2023), 1992–2004. doi:10.14778/3594512.3594528
-
[36]
TPC, Transaction Processing Performance Council. 2025. TPC-H: Decision Support Benchmark. https://www.tpc.org/tpch/
2025
-
[37]
Herbert Tropf and Helmut Herzog. 1981. Multidimensional Range Search in Dynamically Balanced Trees.Angewandte Info.2 (1981), 71–77
1981
-
[38]
Haixin Wang, Xiaoyi Fu, Jianliang Xu, and Hua Lu. 2019. Learned Index for Spatial Queries. In2019 20th IEEE International Conference on Mobile Data Management (MDM). 569–574. doi:10.1109/MDM.2019.00121
-
[39]
Hongwei Wen and Hanyuan Hang. 2022. Random Forest Density Estimation. InProceedings of the 39th International Conference on Machine Learning. PMLR, 23701–23722
2022
-
[40]
Chaichon Wongkham, Baotong Lu, Chris Liu, Zhicong Zhong, Eric Lo, and Tianzheng Wang. 2022. Are Updatable Learned Indexes Ready?Proceedings of Pai, Yang, and Mathioudakis the VLDB Endowment15, 11 (July 2022), 3004–3017. arXiv:2207.02900 doi:10. 14778/3551793.3551848
arXiv 2022
-
[41]
Zongheng Yang, Badrish Chandramouli, Chi Wang, Johannes Gehrke, Yinan Li, Umar Farooq Minhas, Per-Åke Larson, Donald Kossmann, and Rajeev Acharya
-
[42]
InProceedings of the 2020 ACM SIGMOD International Conference on Management of Data
Qd-Tree: Learning Data Layouts for Big Data Analytics. InProceedings of the 2020 ACM SIGMOD International Conference on Management of Data. ACM, Portland OR USA, 193–208. doi:10.1145/3318464.3389770
-
[43]
Peng Yongxin, Zhou Wei, Zhang Lin, and Du Hongle. 2020. A Study of Learned KD Tree Based on Learned Index. In2020 International Conference on Networking and Network Applications (NaNA). 355–360. doi:10.1109/NaNA51271.2020.00067
-
[44]
Jiaoyi Zhang and Yihan Gao. 2022. CARMI: A Cache-Aware Learned Index with a Cost-Based Construction Algorithm.Proceedings of the VLDB Endowment15, 11 (July 2022), 2679–2691. doi:10.14778/3551793.3551823
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.