S-JEPA : Soft Clustering Anchors for Self-Supervised Speech Representation Learning
Pith reviewed 2026-06-26 19:44 UTC · model grok-4.3
The pith
S-JEPA trains speech encoders by matching soft GMM posteriors instead of hard cluster labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
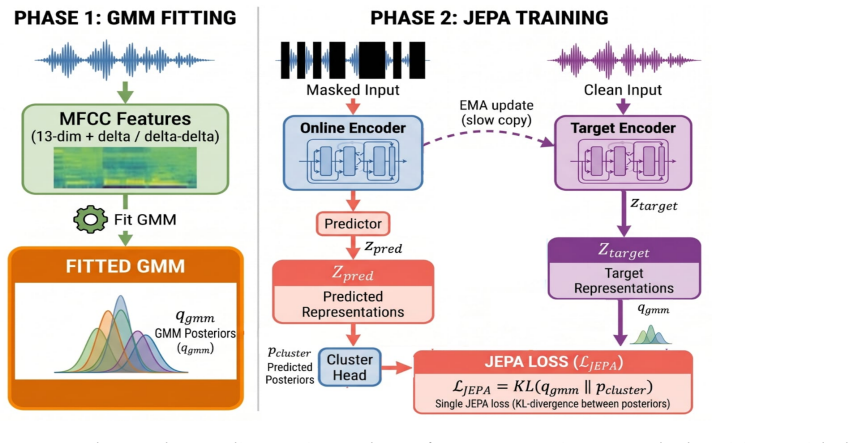
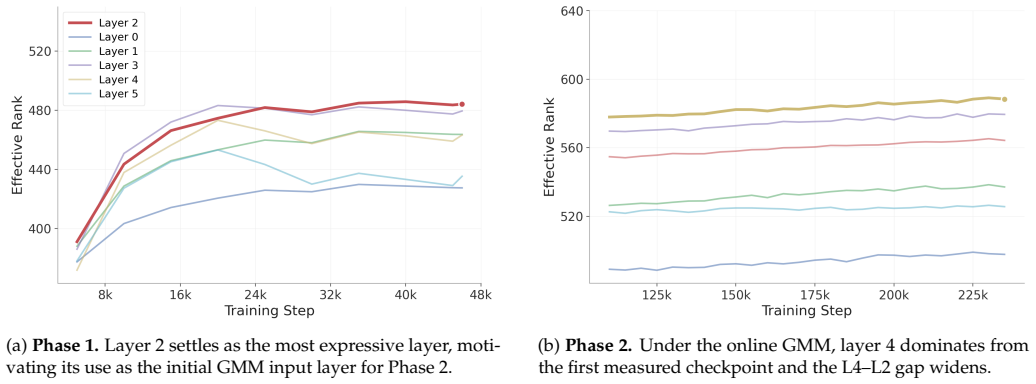
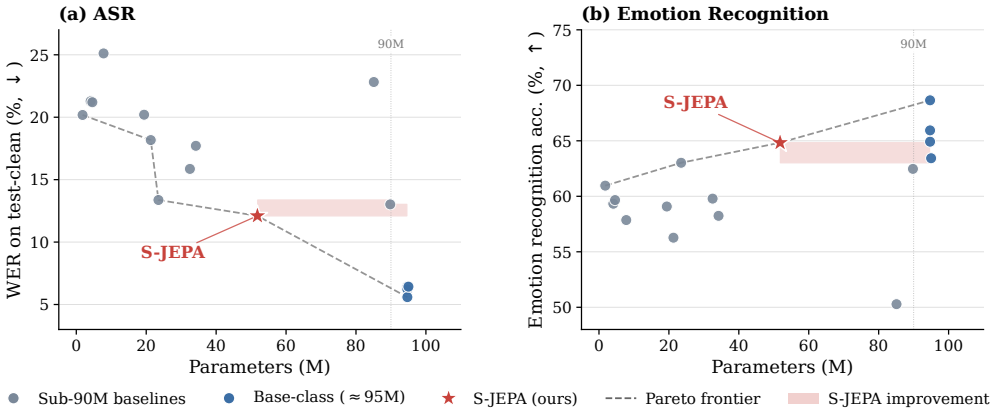
S-JEPA is a JEPA-style encoder-predictor pair trained to match the soft posteriors of a Gaussian Mixture Model at masked positions via KL divergence. Training runs continuously in two phases: a fixed GMM over MFCC features, then an online GMM over encoder features, with the input layer selected adaptively from a label-free signal. This removes both the offline re-cluster step and the hand-tuned choice of which transformer layer to cluster on. Under the SUPERB protocol, S-JEPA achieves the lowest WER among evaluated SSL methods below 90M parameters and matches HuBERT-Base on emotion recognition at roughly half its parameter count.
What carries the argument
Soft posterior matching to GMM anchors via KL divergence in a two-phase continuous training process with adaptive layer selection.
If this is right
- Lowest WER among evaluated SSL methods below 90M parameters on SUPERB.
- Matches HuBERT-Base on emotion recognition at roughly half the parameter count.
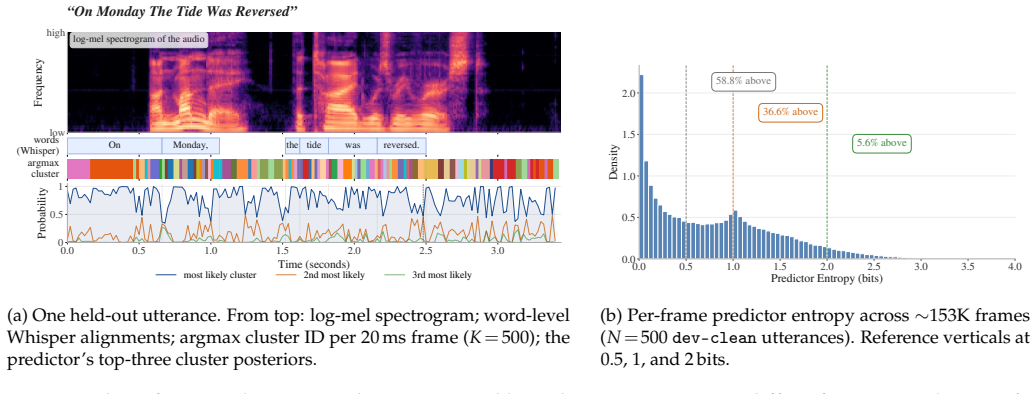
- Predictor per-frame entropy on held-out speech shows a bimodal distribution with frames near perfect two-cluster tie.
- Enables single continuous optimization trajectory without offline re-clustering or teacher distillation.
Where Pith is reading between the lines
- The method could apply to other sequence domains where category boundaries carry real uncertainty, such as audio events or prosody labeling.
- Removing periodic re-clustering steps would lower the total compute needed to reach a given performance level in large-scale pretraining runs.
- Explicit modeling of per-frame ambiguity might improve calibration on downstream tasks that involve noisy or accented speech.
Load-bearing premise
The two-phase GMM with adaptive layer selection produces stable and representative soft posteriors that better capture acoustic ambiguity than hard clustering across diverse speech data.
What would settle it
An ablation that applies the identical two-phase continuous schedule and adaptive layer selection but replaces soft posteriors with hard cluster assignments, then measures whether WER and emotion recognition scores stay competitive.
Figures
read the original abstract
Self-supervised speech encoders are predominantly trained by predicting discrete hard cluster IDs at masked positions, a recipe that collapses acoustic ambiguity at category boundaries and requires interrupting training to re-cluster the entire corpus between iterations. We introduce S-JEPA, a JEPA-style encoder-predictor pair trained to match the soft posteriors of a Gaussian Mixture Model at masked positions via KL divergence. Training runs as one continuous optimization trajectory in two phases: a fixed GMM over MFCC features, then an online GMM over encoder features, with the input layer selected adaptively from a label-free signal, removing both the offline re-cluster step and the hand-tuned choice of which transformer layer to cluster on. Under the SUPERB protocol, S-JEPA achieves the lowest WER among evaluated SSL methods below 90M parameters and matches HuBERT-Base on emotion recognition at roughly half its parameter count, establishing a new Pareto frontier without offline re-clustering or teacher distillation. An analysis of the predictor's per-frame entropy on held-out speech reveals a bimodal distribution with a substantial minority of frames near the entropy of a perfect two-cluster tie, providing direct empirical evidence that the soft-target objective preserves the acoustic ambiguity that hard targets would collapse. Code is available at https://github.com/gioannides/s-jepa.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces S-JEPA, a JEPA-style self-supervised speech encoder trained to predict soft GMM posteriors at masked positions via KL divergence rather than hard cluster IDs. Training proceeds in one continuous trajectory using a fixed MFCC GMM followed by an online GMM on encoder features, with adaptive label-free layer selection; this removes offline re-clustering and hand-tuned layer choice. Under SUPERB, the model reports the lowest WER among SSL methods below 90M parameters and matches HuBERT-Base on emotion recognition at roughly half the parameter count, supported by an entropy analysis showing preserved acoustic ambiguity.
Significance. If the central claims hold, the work offers a simpler, more efficient SSL recipe for speech that preserves boundary ambiguity without re-clustering or distillation, potentially improving the Pareto frontier for models under 90M parameters. The public code release is a clear strength for reproducibility.
major comments (3)
- [Method (two-phase GMM and online phase)] Method section on two-phase GMM: the headline SUPERB claims (lowest WER below 90M params, matching HuBERT-Base on emotion) rest on the online GMM phase producing stable, non-collapsed soft posteriors that differ from hard assignments; no convergence diagnostics, initialization sensitivity, or data-order ablation is reported to substantiate this.
- [Method (adaptive layer selection)] Adaptive layer selection paragraph: the label-free signal used to choose the input layer for the GMM is described at high level only; without evidence that the selected posteriors remain non-degenerate across acoustic conditions, the KL objective risks reducing to standard hard clustering and the claimed removal of hand-tuning yields no advantage.
- [Experiments (SUPERB evaluation)] Results section (SUPERB tables): the Pareto-frontier claim requires variance estimates or statistical tests across runs; single-point WER and emotion scores without these cannot reliably establish superiority over baselines under 90M parameters.
minor comments (2)
- [Abstract and entropy analysis] Abstract and §4: the entropy analysis is presented as direct evidence of ambiguity preservation, but the precise definition of the 'perfect two-cluster tie' baseline entropy should be stated explicitly for reproducibility.
- [Method equations] Notation: the distinction between the fixed MFCC GMM and the online encoder GMM should be denoted with distinct symbols to avoid reader confusion in the equations.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We respond point-by-point to the major comments below.
read point-by-point responses
-
Referee: [Method (two-phase GMM and online phase)] Method section on two-phase GMM: the headline SUPERB claims (lowest WER below 90M params, matching HuBERT-Base on emotion) rest on the online GMM phase producing stable, non-collapsed soft posteriors that differ from hard assignments; no convergence diagnostics, initialization sensitivity, or data-order ablation is reported to substantiate this.
Authors: We agree that convergence diagnostics would strengthen the claims regarding the online GMM. In the revised manuscript we will add plots of GMM log-likelihood and posterior entropy over training steps to demonstrate stability. Initialization sensitivity and data-order ablation were not performed owing to compute limits; we will note this limitation explicitly. revision: partial
-
Referee: [Method (adaptive layer selection)] Adaptive layer selection paragraph: the label-free signal used to choose the input layer for the GMM is described at high level only; without evidence that the selected posteriors remain non-degenerate across acoustic conditions, the KL objective risks reducing to standard hard clustering and the claimed removal of hand-tuning yields no advantage.
Authors: We will expand the description of the label-free selection criterion with additional implementation details. We will also add an appendix analysis of posterior entropy on held-out data from varied acoustic conditions to confirm the selected posteriors remain non-degenerate. revision: yes
-
Referee: [Experiments (SUPERB evaluation)] Results section (SUPERB tables): the Pareto-frontier claim requires variance estimates or statistical tests across runs; single-point WER and emotion scores without these cannot reliably establish superiority over baselines under 90M parameters.
Authors: Single-run reporting follows the established practice in the SSL speech literature due to training cost. We will revise the text to acknowledge this limitation and refrain from claiming statistical superiority. revision: partial
- Variance estimates or statistical tests across multiple independent runs, which would require new full-scale training experiments not performed in the original work.
Circularity Check
No significant circularity; performance claims rest on external SUPERB benchmarks
full rationale
The paper introduces S-JEPA as a JEPA-style model trained via KL divergence to soft GMM posteriors in two phases (fixed MFCC then online encoder features) with adaptive layer selection. Its headline results (lowest WER below 90M params, matching HuBERT-Base on emotion at half size) are measured directly against the independent SUPERB protocol using standard downstream metrics. No equations, fitted parameters, or self-citations are shown to reduce the reported performance numbers to quantities defined solely by the method's own inputs or prior author work. The per-frame entropy analysis on held-out data is presented as separate empirical evidence. This is the common case of an empirical method whose central claims remain falsifiable against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- GMM component count
axioms (2)
- standard math KL divergence is a suitable objective for matching soft cluster distributions
- domain assumption Online GMM updates on encoder features remain stable without periodic resets
Reference graph
Works this paper leans on
-
[1]
Self-supervised learn- ing from images with a joint-embedding predictive architecture
Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael Rabbat, Yann LeCun, and Nicolas Ballas. Self-supervised learn- ing from images with a joint-embedding predictive architecture. InCVPR, 2023
2023
-
[2]
vq-wav2vec: Self-supervised learning of discrete speech representations
Alexei Baevski, Steffen Schneider, and Michael Auli. vq-wav2vec: Self-supervised learning of discrete speech representations. InICLR, 2020
2020
-
[3]
wav2vec 2.0: A framework for self-supervised learning of speech representations
Alexei Baevski, Yuhao Zhou, Abdelrahman Mo- hamed, and Michael Auli. wav2vec 2.0: A framework for self-supervised learning of speech representations. InNeurIPS, 2020
2020
-
[4]
data2vec: A gen- eral framework for self-supervised learning in speech, vision and language
Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, and Michael Auli. data2vec: A gen- eral framework for self-supervised learning in speech, vision and language. InICML, 2022
2022
-
[5]
Randall Balestriero and Yann LeCun. Lejepa: Prov- able and scalable self-supervised learning without the heuristics.arXiv preprint arXiv:2511.08544, 2025
Pith/arXiv arXiv 2025
-
[6]
Springer, 2006
Christopher M Bishop.Pattern Recognition and Ma- chine Learning. Springer, 2006
2006
-
[7]
Emerging properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. InICCV, 2021
2021
-
[8]
Distilhubert: Speech representation learning by layer- wise distillation of hidden-unit bert
Heng-Jui Chang, Shu-wen Yang, and Hung-yi Lee. Distilhubert: Speech representation learning by layer- wise distillation of hidden-unit bert. InICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 7087–
2022
-
[9]
Wavlm: Large-scale self-supervised pre-training for full stack speech processing
Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, et al. Wavlm: Large-scale self-supervised pre-training for full stack speech processing. InIEEE JSTSP, 2022
2022
-
[10]
Self-supervised learning with random-projection quantizer for speech recognition
Chung-Cheng Chiu, James Qin, Yu Zhang, Jiahui Yu, and Yonghui Wu. Self-supervised learning with random-projection quantizer for speech recognition. InICML, 2022
2022
-
[11]
An unsupervised autoregressive model for speech representation learning
Yu-An Chung, Wei-Ning Hsu, Hao Tang, and James Glass. An unsupervised autoregressive model for speech representation learning. InINTERSPEECH, 2019
2019
-
[12]
Vector- quantized autoregressive predictive coding
Yu-An Chung, Hao Tang, and James Glass. Vector- quantized autoregressive predictive coding. InIN- TERSPEECH, 2020
2020
-
[13]
w2v-bert: Combining contrastive learning and masked language modeling for self-supervised speech pre-training
Yu-An Chung, Yu Zhang, Wei Han, Chung-Cheng Chiu, James Qin, Ruoming Pang, and Yonghui Wu. w2v-bert: Combining contrastive learning and masked language modeling for self-supervised speech pre-training. InASRU, 2021
2021
-
[14]
Maximum likelihood from incomplete data via the em algorithm.Journal of the Royal Statistical Society: Series B, 1977
Arthur P Dempster, Nan M Laird, and Donald B Rubin. Maximum likelihood from incomplete data via the em algorithm.Journal of the Royal Statistical Society: Series B, 1977
1977
-
[15]
A-jepa: Joint-embedding predictive architecture can listen
Zhengcong Fei, Mingyuan Fan, and Junshi Huang. A-jepa: Joint-embedding predictive architecture can listen. 2024. URL https://arxiv.org/abs/2311. 15830. 8
2024
-
[16]
Rankme: Assessing the down- stream performance of pretrained self-supervised representations by their rank
Quentin Garrido, Randall Balestriero, Laurent Naj- man, and Yann Lecun. Rankme: Assessing the down- stream performance of pretrained self-supervised representations by their rank. InInternational con- ference on machine learning, pages 10929–10974. PMLR, 2023
2023
-
[17]
Judah Goldfeder, Philippe Wyder, Yann LeCun, and Ravid Shwartz Ziv. Ai must embrace specialization via superhuman adaptable intelligence.arXiv preprint arXiv:2602.23643, 2026
arXiv 2026
-
[18]
Bootstrap your own latent: A new approach to self-supervised learning
Jean-Bastien Grill, Florian Strub, Florent Altché, Corentin Tallec, Pierre Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Guo, Mohammad Gheshlaghi Azar, et al. Bootstrap your own latent: A new approach to self-supervised learning. InNeurIPS, 2020
2020
-
[19]
Distill- ing the knowledge in a neural network.arXiv preprint arXiv:1503.02531, 2015
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distill- ing the knowledge in a neural network.arXiv preprint arXiv:1503.02531, 2015
Pith/arXiv arXiv 2015
-
[20]
Hubert: Self-supervised speech representation learning by masked prediction of hidden units
Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, and Abdelrahman Mohamed. Hubert: Self-supervised speech representation learning by masked prediction of hidden units. InIEEE/ACM TASLP, 2021
2021
-
[21]
Georgios Ioannides, Adrian Kieback, Judah Goldfeder, Linsey Pang, Aman Chadha, Aaron Elkins, Yann LeCun, and Ravid Shwartz-Ziv. Soft clustering anchors for self-supervised speech rep- resentation learning in joint embedding prediction architectures.arXiv preprint arXiv:2602.09040, 2026
arXiv 2026
-
[22]
Libri-light: A benchmark for asr with limited or no supervision
Jacob Kahn, Morgane Rivière, Weiyi Zheng, Eugene Kharitonov, Qiantong Xu, Pierre-Emmanuel Mazaré, Julien Karadayi, Vitaliy Lber, Steffen Schneider, Em- manuel Dupoux, and Gabriel Synnaeve. Libri-light: A benchmark for asr with limited or no supervision. InICASSP, 2020
2020
-
[23]
Gra- nary: Speech recognition and translation dataset in 25 european languages, 2025
Nithin Rao Koluguri, Monica Sekoyan, George Ze- lenfroynd, Sasha Meister, Shuoyang Ding, Sofia Ko- standian, He Huang, Nikolay Karpov, Jagadeesh Balam, Vitaly Lavrukhin, Yifan Peng, Sara Papi, Marco Gaido, Alessio Brutti, and Boris Ginsburg. Gra- nary: Speech recognition and translation dataset in 25 european languages, 2025. URL https://arxiv. org/abs/2505.13404
arXiv 2025
-
[24]
Cengage Learning, 7th edition, 2014
Peter Ladefoged and Keith Johnson.A Course in Pho- netics. Cengage Learning, 7th edition, 2014
2014
-
[25]
A path towards autonomous machine intelligence.OpenReview, 2022
Yann LeCun. A path towards autonomous machine intelligence.OpenReview, 2022
2022
-
[26]
Shaoshi Ling and Yuzong Liu. Decoar 2.0: Deep contextualized acoustic representations with vector quantization.arXiv preprint arXiv:2012.06659, 2020
arXiv 2012
-
[27]
Liu, Yu-An Chung, and James Glass
Alexander H. Liu, Yu-An Chung, and James Glass. Non-autoregressive predictive coding for learning speech representations from local dependencies. 2020. URLhttps://arxiv.org/abs/2011.00406
arXiv 2020
-
[28]
Liu, Shang-Wen Yang, Po-Han Chi, Po-Chun Hsu, and Hung-yi Lee
Andy T. Liu, Shang-Wen Yang, Po-Han Chi, Po-Chun Hsu, and Hung-yi Lee. Mockingjay: Unsupervised speech representation learning with deep bidirec- tional transformer encoders. InICASSP, 2020
2020
-
[29]
Liu et al
Andy T. Liu et al. Tera: Self-supervised learning of transformer encoder representation for speech. IEEE/ACM TASLP, 2021
2021
-
[30]
Decoupled weight decay regularization.ICLR, 2019
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.ICLR, 2019
2019
-
[31]
Some methods for classification and analysis of multivariate observations
James MacQueen. Some methods for classification and analysis of multivariate observations. InProceed- ings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, 1967
1967
-
[32]
Librispeech: An asr corpus based on public domain audio books
Vassil Panayotov, Guoguo Chen, Daniel Povey, and Sanjeev Khudanpur. Librispeech: An asr corpus based on public domain audio books. InICASSP, 2015
2015
-
[33]
Learning problem-agnostic speech representations from multi- ple self-supervised tasks
Santiago Pascual, Mirco Ravanelli, Joan Serra, An- tonio Bonafonte, and Yoshua Bengio. Learning problem-agnostic speech representations from multi- ple self-supervised tasks. InINTERSPEECH, 2019
2019
-
[34]
Robust speech recognition via large-scale weak supervision,
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brock- man, Christine McLeavey, and Ilya Sutskever. Robust speech recognition via large-scale weak supervision,
-
[35]
URLhttps://arxiv.org/abs/2212.04356
-
[36]
wav2vec: Unsupervised pre- training for speech recognition
Steffen Schneider, Alexei Baevski, Ronan Collobert, and Michael Auli. wav2vec: Unsupervised pre- training for speech recognition. InInterspeech, 2019
2019
-
[37]
Oscar Skean, Md Rifat Arefin, Dan Zhao, Niket Patel, Jalal Naghiyev, Yann LeCun, and Ravid Shwartz-Ziv. Layer by layer: Uncovering hidden representations in language models.arXiv preprint arXiv:2502.02013, 2025
Pith/arXiv arXiv 2025
-
[38]
Stevens.Acoustic Phonetics
Kenneth N. Stevens.Acoustic Phonetics. MIT Press, 1998
1998
-
[39]
The information bottleneck method.arXiv preprint physics/0004057, 2000
Naftali Tishby, Fernando C Pereira, and William Bialek. The information bottleneck method.arXiv preprint physics/0004057, 2000
Pith/arXiv arXiv 2000
-
[40]
Representation learning with contrastive predictive coding
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding. InarXiv preprint arXiv:1807.03748, 2018
Pith/arXiv arXiv 2018
-
[41]
Attention is all you need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. InNeurIPS, 2017. 9
2017
-
[42]
Jeffrey S. Vitter. Random sampling with a reservoir. ACM Transactions on Mathematical Software, 11(1):37– 57, 1985
1985
-
[43]
Shu wen Yang, Po-Han Chi, Yung-Sung Chuang, Cheng-I Jeff Lai, Kushal Lakhotia, Yist Y. Lin, Andy T. Liu, Jiatong Shi, Xuankai Chang, Guan-Ting Lin, Tzu-Hsien Huang, Wei-Cheng Tseng, Ko tik Lee, Da-Rong Liu, Zili Huang, Shuyan Dong, Shang- Wen Li, Shinji Watanabe, Abdelrahman Mohamed, and Hung yi Lee. Superb: Speech processing uni- versal performance bench...
arXiv 2021
-
[44]
Dropping the visible-position term (S=M ) is consistent with the masked-only configuration used by data2vec [4], wav2vec 2.0 [3], and HuBERT [20]
Dropping the visible-position loss.Visible-position cluster predictions are an easier prediction problem (the encoder sees the input directly there) and may supply gradients that are largely redundant with what the masked- position loss already provides. Dropping the visible-position term (S=M ) is consistent with the masked-only configuration used by dat...
-
[45]
Disabling augmentation.We set pnoise =p mix = 0, so the encoder sees the same clean waveform that the EMA encoder feeds to the GMM. This is in tension with WavLM’s [9] finding that denoising augmentation is helpful, and likely reflects an interaction specific to our setup: if the GMM target is computed from clean audio while the encoder sees augmented aud...
2000
-
[46]
Sample mix lengthL mix as a random fraction of the primary length
-
[47]
Sample start positionst 1,t 2 in the primary and secondary signals
-
[48]
Extract regionsr 1 ←x 1[t1 :t 1 +L],r 2 ←x 2[t2 :t 2 +L]and compute energiesE 1,E 2
-
[49]
Sample energy ratioρ∼Uniform over a fixed dB range
-
[50]
J SUPERB Evaluation Protocol We follow the standard SUPERB [42] protocol: the pre-trained encoder is frozen and small task-specific heads are trained on top
Computeβand mixx 1[t1 :t 1 +L]←r 1 +β·r 2. J SUPERB Evaluation Protocol We follow the standard SUPERB [42] protocol: the pre-trained encoder is frozen and small task-specific heads are trained on top. Across tasks, the encoder receives raw waveform input and the task-specific head consumes its frame-level outputs (or a learned weighted combination across ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.