MonaVec: A Training-Free Embedded Vector Search Kernel for Edge and Offline AI Systems
Pith reviewed 2026-06-26 19:04 UTC · model grok-4.3
The pith
A randomized Hadamard transform enables training-free 4-bit quantization for deterministic vector search on edge devices.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
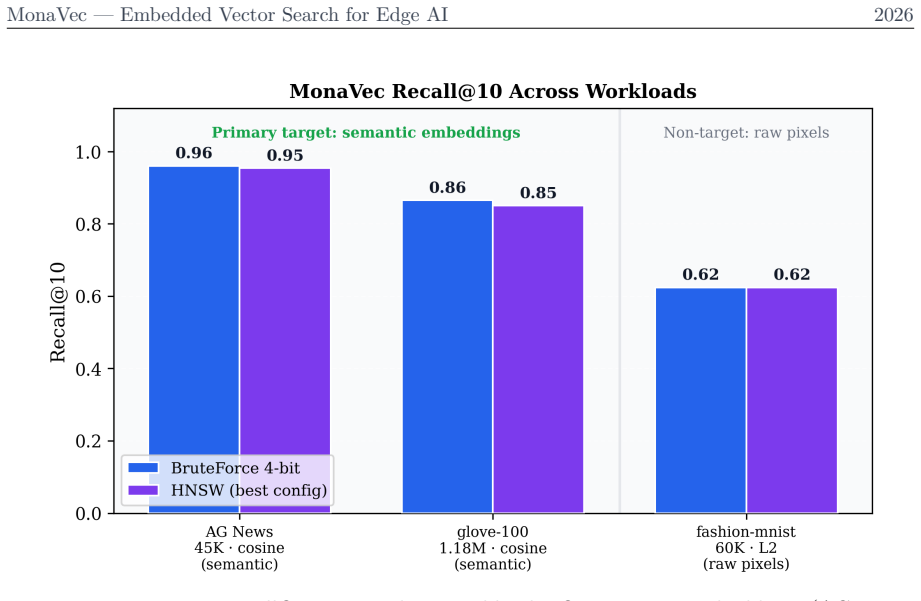
MonaVec shows that a Randomized Hadamard Transform followed by precomputed 4-bit Lloyd-Max quantization produces an embedded vector index that requires no training pass and persists as a single deterministic file, reaching 0.960 Recall@10 on semantic embeddings while using 27 MB of storage.
What carries the argument
The Randomized Hadamard Transform, which rotates and scales input embeddings to approximate a standard normal distribution for use with fixed quantization tables.
Load-bearing premise
The Randomized Hadamard Transform makes arbitrary embedding distributions sufficiently close to normal for precomputed quantization tables to work without any per-dataset adjustment.
What would settle it
Measure recall on a dataset of embeddings whose distribution resists normalization by the Hadamard transform, such as those with heavy tails or strong correlations, and check if it falls below that of trained quantizers.
Figures

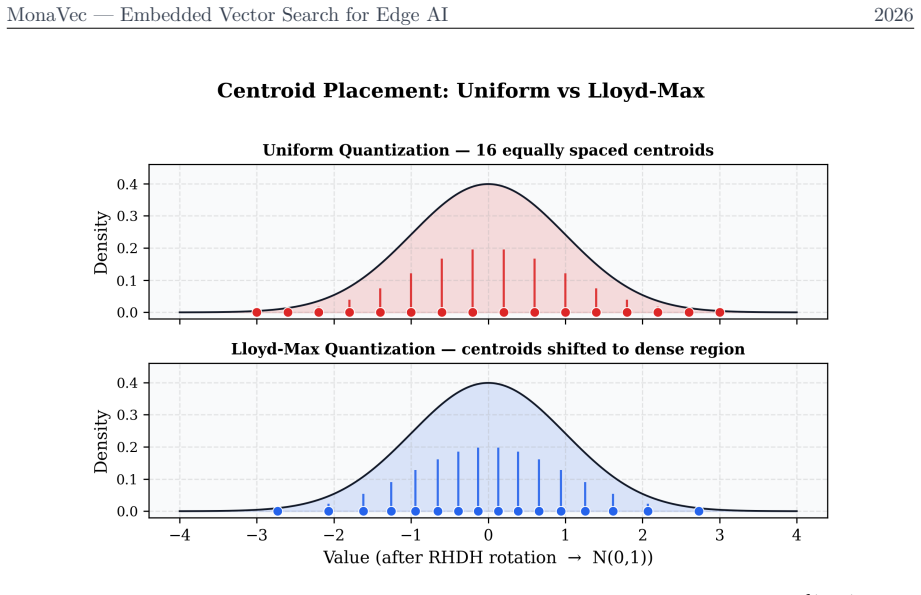
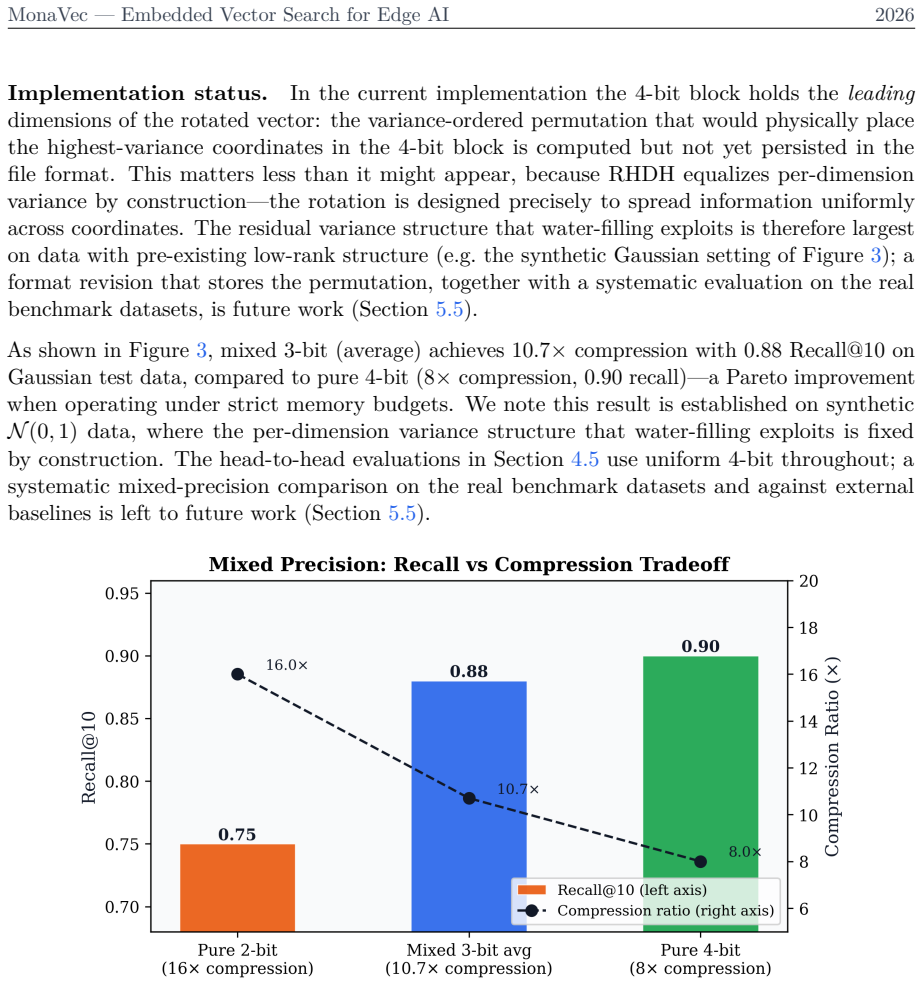
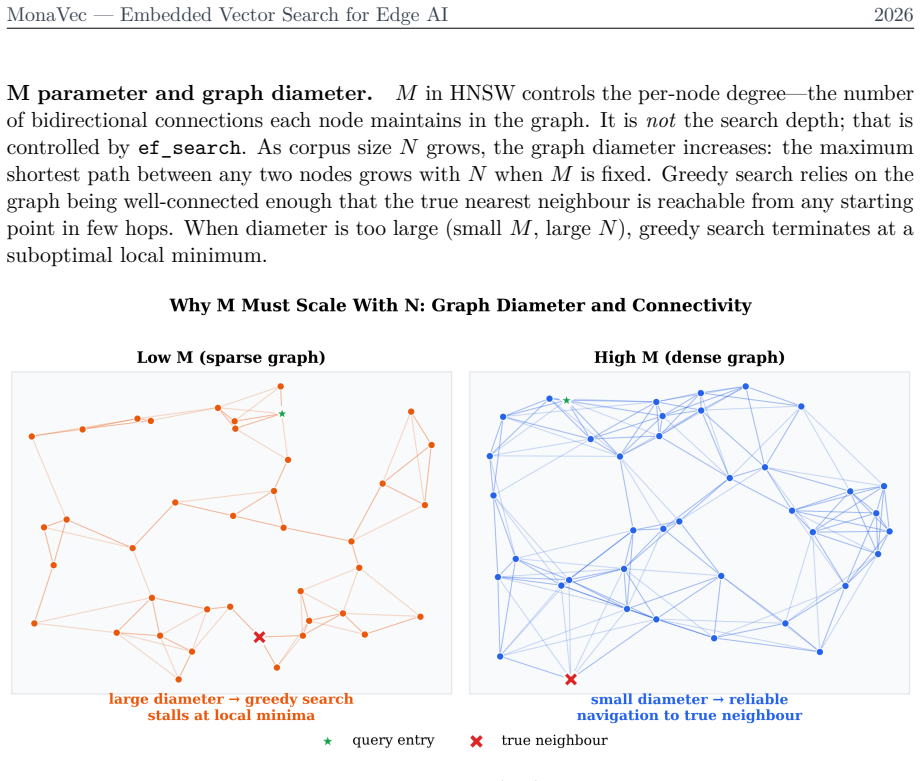
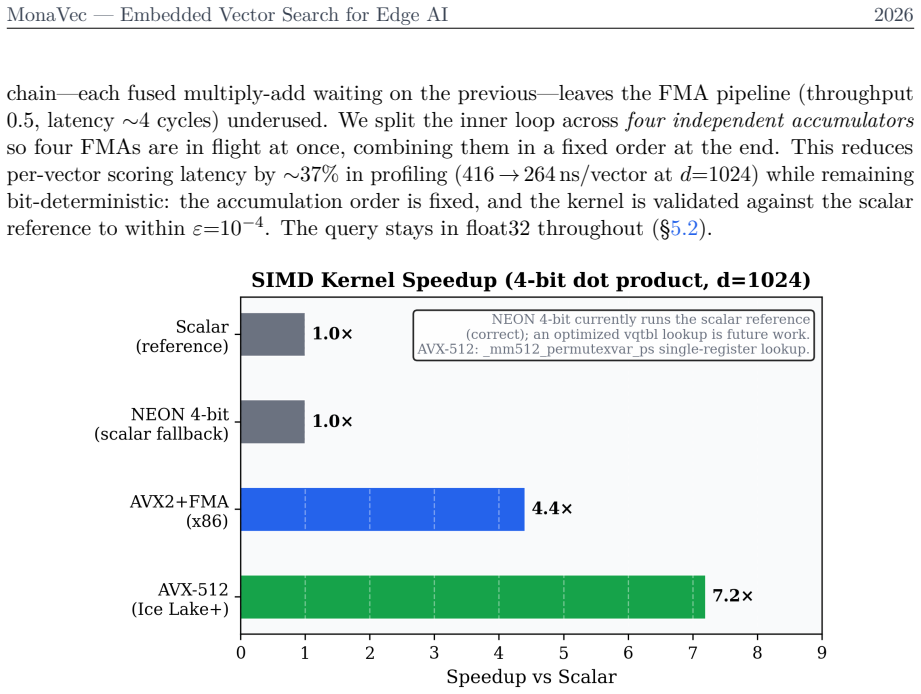
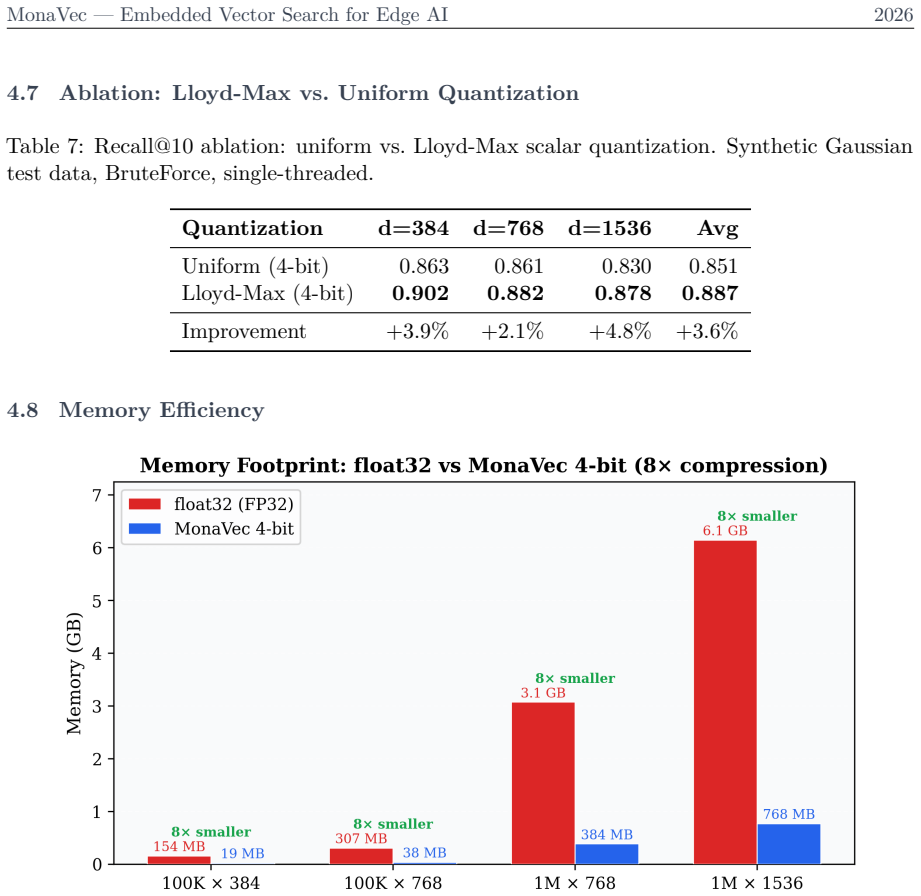
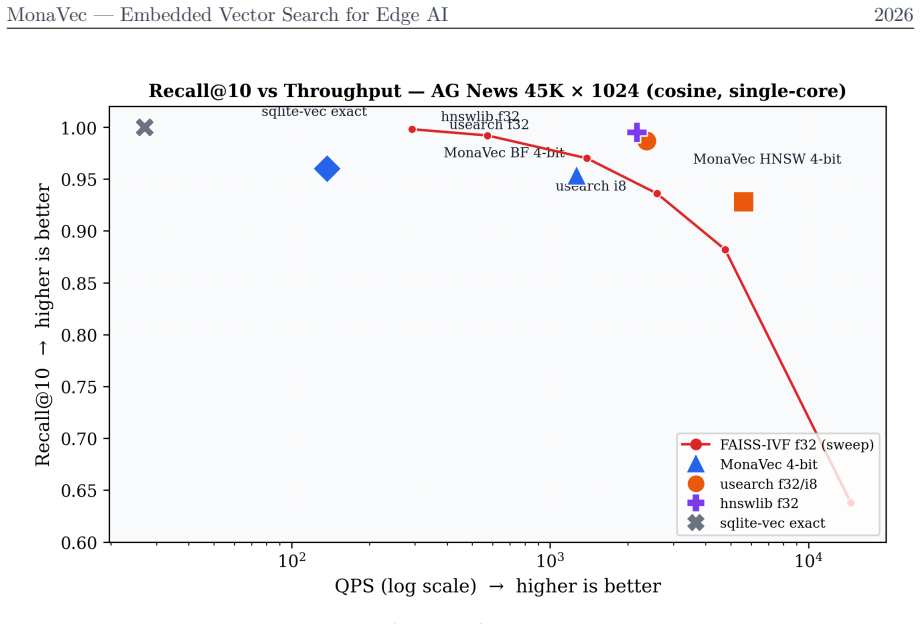
read the original abstract
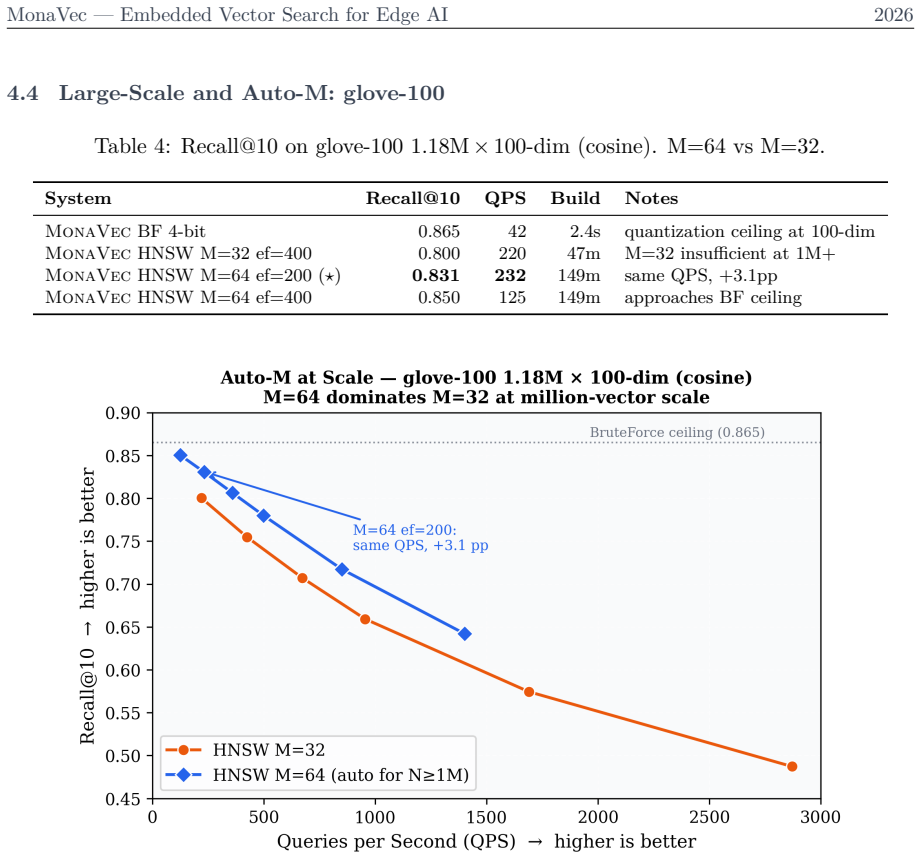
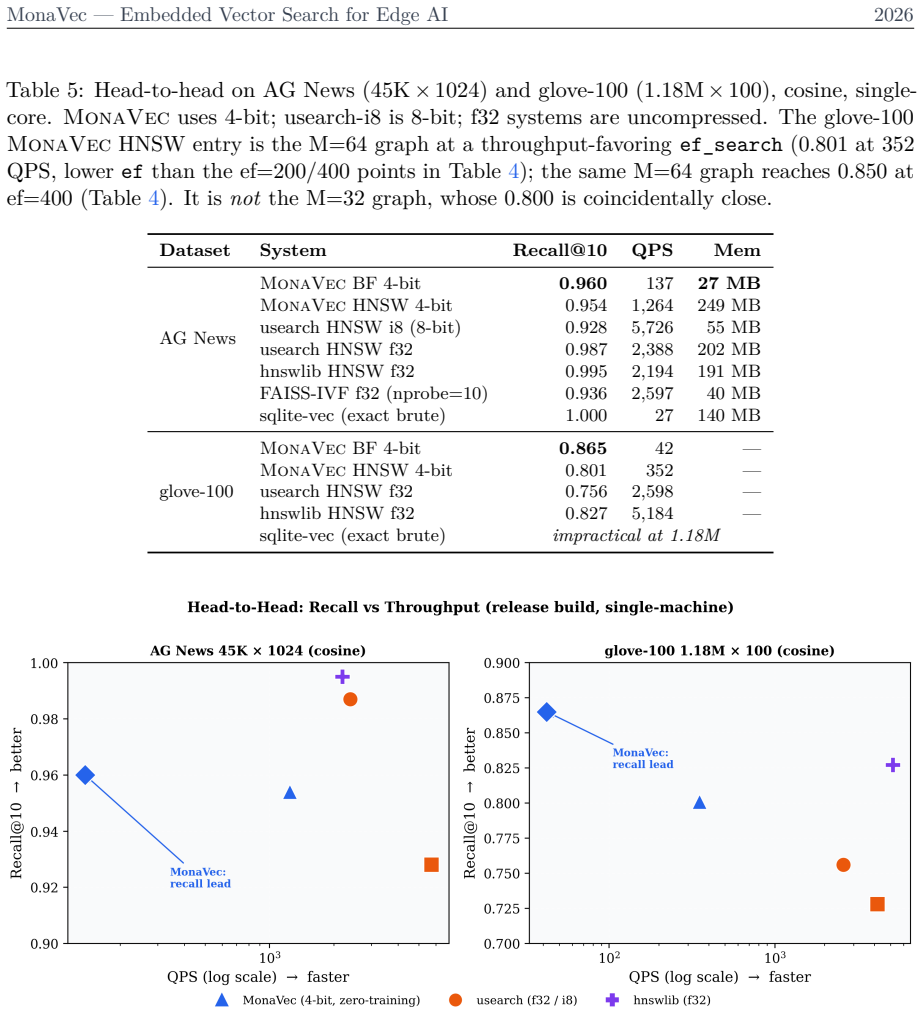
We present MonaVec, a deterministic, embedded vector-search kernel for edge and offline AI -- settings where server infrastructure, network connectivity, and training data are all unavailable. Existing vector-search systems assume a persistent server, gigabytes of RAM, or a training pass over the corpus; MonaVec instead targets the deployment profile of SQLite: one file, one function call, runs anywhere. Its quantization core is training-free by default and data-oblivious: a Randomized Hadamard Transform (RHDH) conditions any input distribution toward N(0,1), so precomputed Lloyd-Max tables quantize to 4 bits (8x smaller) with no learned codebook and no data pass. The index persists as a single .mvec file whose embedded ChaCha20 rotation seed makes results reproducible across architectures and byte-identical within a build -- a determinism guarantee that parallel-build graph libraries cannot offer. On semantic embeddings (AG News, 45K x 1024-dim BGE-M3, cosine), MonaVec 4-bit BruteForce reaches 0.960 Recall@10 in 27 MB -- leading float32 FAISS-IVF and 8-bit usearch on recall -- while trading peak throughput for byte-identical determinism. A single-pass global standardization (fit()) extends the same data-oblivious pipeline to magnitude-sensitive L2 data, and optional IvfFlat and HNSW backends carry it to million-vector corpora. MonaVec is implemented in pure Rust with Python bindings and runtime SIMD dispatch (AVX-512/AVX2/NEON/scalar). It targets on-device RAG, offline agents, and embedded retrieval -- the niche SQLite occupies for relational data: one file, one call, runs anywhere.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents MonaVec, a deterministic embedded vector-search kernel for edge and offline AI. It uses a Randomized Hadamard Transform (RHDH) to condition input embeddings toward N(0,1), enabling precomputed Lloyd-Max tables for training-free 4-bit quantization. On AG News (45K × 1024-dim BGE-M3, cosine), the 4-bit BruteForce variant reports 0.960 Recall@10 in 27 MB while outperforming float32 FAISS-IVF and 8-bit usearch on recall; optional IVF/HNSW backends and a single-pass standardization extend it to larger or L2 corpora. The index is a single .mvec file with embedded ChaCha20 seed for byte-identical reproducibility.
Significance. If the central claims hold, the work addresses a practical niche in cs.IR for on-device retrieval by delivering a training-free, single-file, architecture-portable kernel with strong determinism guarantees. The emphasis on data-oblivious quantization and embedded reproducibility is a clear strength for offline RAG and embedded agents; the pure-Rust implementation with SIMD dispatch further supports deployability.
major comments (2)
- [Abstract] Abstract: the reported 0.960 Recall@10 (and all other numeric claims) is presented with no experimental details, error bars, full baseline configurations, or verification of the distribution-conditioning claim, so the numbers cannot be assessed from the given text.
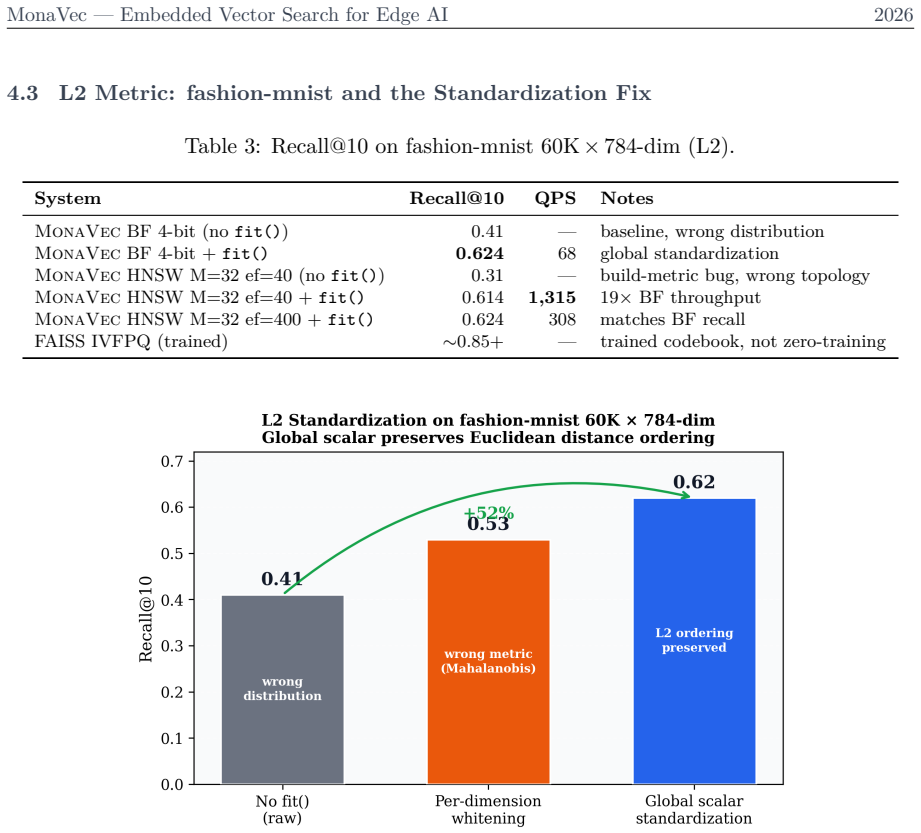
- [Quantization pipeline description] Quantization pipeline description: the claim that a single RHDH produces marginals sufficiently close to N(0,1) for precomputed Lloyd-Max tables to incur negligible extra error is load-bearing for both the recall figure and the training-free guarantee, yet no Kolmogorov-Smirnov distances, tail quantiles, or post-transform distribution statistics are provided on the AG News BGE-M3 corpus.
minor comments (1)
- [Abstract] The interaction between the optional single-pass global standardization (fit()) and the data-oblivious claim for magnitude-sensitive L2 data is stated but not formalized.
Simulated Author's Rebuttal
We appreciate the referee's constructive feedback on our manuscript. Below we provide point-by-point responses to the major comments. We agree with the need for greater transparency in the abstract and additional empirical support for the core technical claim, and we will incorporate revisions to address these points.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported 0.960 Recall@10 (and all other numeric claims) is presented with no experimental details, error bars, full baseline configurations, or verification of the distribution-conditioning claim, so the numbers cannot be assessed from the given text.
Authors: We acknowledge that the abstract, due to its brevity, does not include the full experimental details. The manuscript's Experiments section provides the complete setup: AG News corpus (45K documents), 1024-dimensional BGE-M3 embeddings, cosine similarity metric, and comparisons against float32 FAISS-IVF and 8-bit usearch. The method's determinism via fixed ChaCha20 seed means there is no run-to-run variance, rendering error bars inapplicable. To improve the abstract, we will add a concise description of the evaluation protocol and note the location of detailed results in the paper. The distribution-conditioning verification is addressed in our response to the second comment. revision: yes
-
Referee: [Quantization pipeline description] Quantization pipeline description: the claim that a single RHDH produces marginals sufficiently close to N(0,1) for precomputed Lloyd-Max tables to incur negligible extra error is load-bearing for both the recall figure and the training-free guarantee, yet no Kolmogorov-Smirnov distances, tail quantiles, or post-transform distribution statistics are provided on the AG News BGE-M3 corpus.
Authors: The referee is correct that explicit empirical validation of the post-RHDH marginal distributions would strengthen the presentation. Although the use of RHDH for approximate Gaussianization draws on established theoretical results, we will add to the revised manuscript a dedicated subsection or appendix with the requested statistics. This will include Kolmogorov-Smirnov test distances to N(0,1), comparisons of tail quantiles, and summary statistics for the transformed embeddings from the AG News BGE-M3 corpus. These additions will confirm that the approximation error is negligible for the 4-bit quantization. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents a data-oblivious pipeline consisting of a fixed Randomized Hadamard Transform followed by precomputed Lloyd-Max quantization tables, with results on the AG News corpus reported as empirical outcomes rather than quantities derived by construction from the evaluation set. No equations or steps reduce the claimed recall to a fitted parameter or self-referential definition, and the manuscript contains no self-citations, uniqueness theorems, or ansatzes that would create load-bearing circularity. The derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Randomized Hadamard Transform conditions any input distribution toward N(0,1)
Reference graph
Works this paper leans on
-
[1]
Gerganov et al
G. Gerganov et al. llama.cpp: Inference of LLaMA model in pure C/C++. https: //github.com/ggerganov/llama.cpp, 2023
2023
-
[2]
T. Chen, L. Zheng, Z. Shen, et al. MLC-LLM.https://github.com/mlc-ai/mlc-llm, 2023
2023
-
[3]
Lewis, E
P. Lewis, E. Perez, A. Piktus, et al. Retrieval-augmented generation for knowledge-intensive NLP tasks. InAdvances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[4]
Qdrant: Vector Search Engine.https://qdrant.tech, 2021
Qdrant Team. Qdrant: Vector Search Engine.https://qdrant.tech, 2021
2021
-
[5]
Weaviate: Open source vector database.https://weaviate.io, 2021
Weaviate Team. Weaviate: Open source vector database.https://weaviate.io, 2021
2021
-
[6]
Johnson, M
J. Johnson, M. Douze, and H. Jégou. Billion-scale similarity search with GPUs.IEEE Transactions on Big Data, 7(3):535–547, 2021
2021
-
[7]
R. Hipp. SQLite.https://www.sqlite.org, 2000
2000
-
[8]
S. P. Lloyd. Least squares quantization in PCM.IEEE Transactions on Information Theory, 28(2):129–137, 1982
1982
-
[9]
J. Max. Quantizing for minimum distortion.IRE Transactions on Information Theory, 6(1):7–12, 1960
1960
-
[10]
Ailon and B
N. Ailon and B. Chazelle. The fast Johnson–Lindenstrauss transform and approximate nearest neighbors.SIAM Journal on Computing, 39(1):302–322, 2009
2009
-
[11]
S. S. Vempala.The Random Projection Method, volume 65 ofDIMACS Series in Discrete Mathematics and Theoretical Computer Science. American Mathematical Society, 2004
2004
-
[12]
IEEE Standard for Floating-Point Arithmetic.IEEE Std 754-2019, 2019
IEEE. IEEE Standard for Floating-Point Arithmetic.IEEE Std 754-2019, 2019
2019
-
[13]
Goldberg
D. Goldberg. What every computer scientist should know about floating-point arithmetic. ACM Computing Surveys, 23(1):5–48, 1991
1991
-
[14]
D. J. Bernstein. ChaCha, a variant of Salsa20. InWorkshop Record of SASC, 2008
2008
-
[15]
S. Ashkboos, A. Mohtashami, M. L. Croci, B. Li, M. Jaggi, D. Alistarh, T. Hoefler, and J. Hensman. QuaRot: Outlier-Free 4-Bit Inference in Rotated LLMs. InAdvances in Neural Information Processing Systems (NeurIPS), 2024. arXiv:2404.00456
-
[16]
Z. Liu, C. Zhao, I. Fedorov, B. Soran, D. Choudhary, R. Krishnamoorthi, V. Chandra, Y. Tian, and T. Blankevoort. SpinQuant: LLM quantization with learned rotations. In International Conference on Learning Representations (ICLR), 2025. arXiv:2405.16406. 26 MonaVec — Embedded Vector Search for Edge AI 2026
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
TurboQuant: Online Vector Quantization with Near-optimal Distortion Rate
A. Zandieh, M. Daliri, M. Hadian, and V. Mirrokni. TurboQuant: Online vector quantization with near-optimal distortion rate. InInternational Conference on Learning Representations (ICLR), 2026. arXiv:2504.19874
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
T. M. Cover and J. A. Thomas.Elements of Information Theory, 2nd ed. Wiley, 2006
2006
-
[19]
Gao and C
J. Gao and C. Long. RaBitQ: Quantizing High-Dimensional Vectors with a Theoretical Error Bound for Approximate Nearest Neighbor Search.Proceedings of the ACM on Management of Data (SIGMOD), 2(3):Article 167, 2024
2024
-
[20]
Y. A. Malkov and D. A. Yashunin. Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs.IEEE TPAMI, 42(4):824–836, 2020
2020
-
[21]
G. V. Cormack, C. L. Clarke, and S. Buettcher. Reciprocal rank fusion outperforms condorcet and individual rank learning methods. InProceedings of SIGIR, 2009
2009
-
[22]
Formal, B
T. Formal, B. Piwowarski, and S. Clinchant. SPLADE: Sparse Lexical and Expansion Model for First Stage Ranking. InProceedings of SIGIR, 2021
2021
-
[23]
J. Chen, S. Xiao, P. Zhang, K. Luo, D. Lian, and Z. Liu. M3-Embedding: Multi-Linguality, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distil- lation. InFindings of the Association for Computational Linguistics: ACL 2024, pages 2318–2335, 2024. arXiv:2402.03216
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Vardanian (Unum)
A. Vardanian (Unum). USearch: Smaller & faster single-file vector search engine.https: //github.com/unum-cloud/usearch, 2023
2023
-
[25]
Y. A. Malkov and D. A. Yashunin. hnswlib – fast approximate nearest neighbor search. https://github.com/nmslib/hnswlib, 2018
2018
-
[26]
A. Garcia. sqlite-vec: A vector search SQLite extension that runs anywhere. https: //github.com/asg017/sqlite-vec, 2024
2024
-
[27]
Jégou, M
H. Jégou, M. Douze, and C. Schmid. Product quantization for nearest neighbor search. IEEE TPAMI, 33(1):117–128, 2011
2011
-
[28]
T. Ge, K. He, Q. Ke, and J. Sun. Optimized product quantization.IEEE TPAMI, 36(4):744– 755, 2014
2014
-
[29]
R. Guo, P. Sun, E. Lindgren, Q. Geng, D. Simcha, F. Chern, and S. Kumar. Accelerating large-scale inference with anisotropic vector quantization. InProceedings of ICML, 2020
2020
-
[30]
Khattab and M
O. Khattab and M. Zaharia. ColBERT: Efficient and Effective Passage Search via Contex- tualized Late Interaction over BERT. InProceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 39–48, 2020
2020
-
[31]
ColPali: Efficient Document Retrieval with Vision Language Models
M. Faysse, H. Sibille, T. Wu, B. Omrani, G. Viaud, C. Hudelot, and P. Colombo. ColPali: Efficient Document Retrieval with Vision Language Models.arXiv preprint arXiv:2407.01449, 2024. 27
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.