Personalized Keyword Spotting for User-Defined Keywords Leveraging Text-Independent Speaker Verification
Pith reviewed 2026-06-26 15:44 UTC · model grok-4.3
The pith
ZP-KWS fuses phoneme audio encoding with a compact speaker encoder via multiplicative late fusion to reject impostors in zero-shot user-defined keyword spotting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
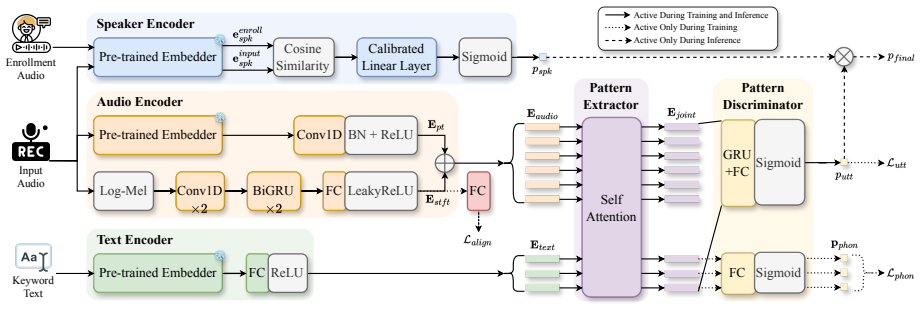
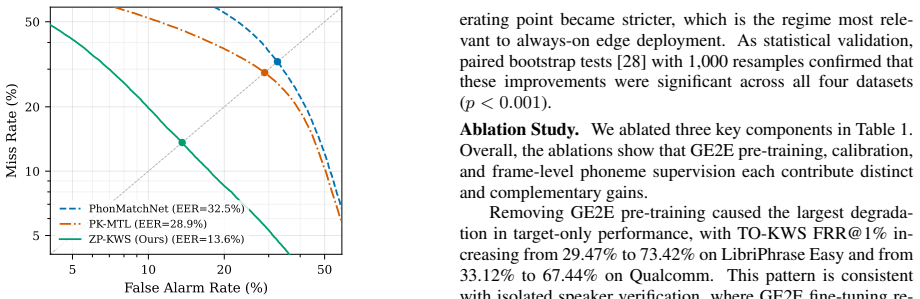
The central claim is that multiplicative late fusion of a phoneme-supervised audio encoder and a 0.9-million-parameter GE2E speaker encoder grants each branch independent veto power. The resulting system performs zero-shot user-defined keyword spotting that can also enforce speaker identity, delivering up to 60 percent relative reduction in target-only false-rejection rate at 1 percent false-alarm rate on three public datasets while fitting inside a 1.55-million-parameter budget suitable for edge devices.
What carries the argument
Multiplicative late fusion at inference between a phoneme-supervised audio encoder and a compact GE2E-pretrained speaker encoder, supplying each branch with independent veto power over the final score.
If this is right
- Supports conventional keyword detection, strict speaker-gated activation, and intermediate modes without retraining.
- Achieves up to 60 percent relative reduction in target-only FRR at 1 percent FAR while keeping keyword detection competitive.
- Fits the entire pipeline inside a 1.55 million parameter budget for edge deployment.
- Operates on unseen keywords and unseen speakers simultaneously.
Where Pith is reading between the lines
- The independent-veto design could be reused to add further constraints such as language or emotion checks by inserting additional branches.
- Because the speaker encoder is frozen and pretrained, the method may allow rapid personalization on new devices with minimal on-device data.
- The same fusion pattern might transfer to other audio tasks that require simultaneous content and identity verification.
- Performance on noisy or accented speech remains untested and would constitute a natural next measurement.
Load-bearing premise
That multiplying the two branch scores at inference time gives each encoder an independent veto over whether a detection is accepted.
What would settle it
A controlled experiment on LibriPhrase in which the fused system fails to reduce target-only false-rejection rate at 1 percent false-alarm rate below the strongest single-branch baseline.
Figures
read the original abstract
User-defined keyword spotting (UD-KWS) enables zero-shot wake-word detection from text, but existing systems learn speaker-invariant representations that cannot reject impostors uttering the correct keyword. We address this dual zero-shot setting -- unseen keywords and unseen speakers -- with ZP-KWS, a lightweight framework combining a phoneme-supervised audio encoder with a GE2E-pretrained compact speaker encoder (about 0.9M parameters). Multiplicative late fusion at inference grants each branch independent veto power, supporting modes from conventional detection to strict speaker-gated activation without retraining. On LibriPhrase, Google Speech Commands, and Qualcomm datasets, ZP-KWS reduces target-only FRR at 1% FAR by up to 60% relative to the strongest baseline while maintaining competitive keyword detection, all within a 1.55M parameter budget for edge deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents ZP-KWS, a lightweight framework for user-defined keyword spotting (UD-KWS) in the dual zero-shot setting of unseen keywords and unseen speakers. It combines a phoneme-supervised audio encoder with a compact GE2E-pretrained speaker encoder (~0.9M parameters) and applies multiplicative late fusion of the two branch scores at inference. The system is claimed to support modes from standard detection to strict speaker-gated activation without retraining. On LibriPhrase, Google Speech Commands, and Qualcomm datasets, ZP-KWS is reported to reduce target-only FRR at 1% FAR by up to 60% relative to the strongest baseline while remaining competitive on keyword detection, all within a 1.55M parameter budget suitable for edge deployment.
Significance. If the empirical claims hold, the work supplies a practical, low-parameter approach to speaker-personalized KWS that addresses the inability of prior UD-KWS systems to reject impostors uttering the target keyword. The explicit use of pre-trained components and inference-time fusion without retraining is a concrete engineering strength for deployment.
major comments (2)
- [Abstract] Abstract: the central performance claim (up to 60% relative FRR reduction at 1% FAR) and the dual zero-shot property both rest on multiplicative late fusion granting each branch independent veto power. No normalization procedure, score calibration details, or correlation measurements between the phoneme-encoder and speaker-encoder scores (especially on short utterances) are supplied; without these, it is impossible to verify that the product implements true independent gating rather than an uncalibrated combination whose gains may derive from the phoneme branch alone or from post-hoc dataset choices.
- [Abstract] Abstract and evaluation description: the manuscript states clear numerical improvements on named public datasets yet provides neither error bars, ablation tables on fusion operators (product vs. other combiners), nor full training hyper-parameters and data splits. These omissions directly affect the ability to assess whether the reported 60% relative reduction is reproducible and attributable to the proposed fusion mechanism.
minor comments (1)
- [Abstract] Abstract: the phrase 'target-only FRR' should be defined on first use to avoid ambiguity with standard KWS metrics.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point-by-point below and commit to revisions that directly resolve the concerns about verification of the fusion mechanism and reproducibility.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance claim (up to 60% relative FRR reduction at 1% FAR) and the dual zero-shot property both rest on multiplicative late fusion granting each branch independent veto power. No normalization procedure, score calibration details, or correlation measurements between the phoneme-encoder and speaker-encoder scores (especially on short utterances) are supplied; without these, it is impossible to verify that the product implements true independent gating rather than an uncalibrated combination whose gains may derive from the phoneme branch alone or from post-hoc dataset choices.
Authors: The multiplicative fusion is motivated by the independent training objectives and datasets of the two encoders (phoneme-supervised vs. GE2E speaker verification), which inherently limits score correlation and enables veto behavior. Nevertheless, we agree that explicit verification is needed. In the revision we will add: (i) the exact normalization applied to each branch score before multiplication, (ii) any calibration steps, and (iii) Pearson correlation values between branches on all evaluation sets with a dedicated short-utterance subset analysis. These additions will confirm that performance gains are not attributable to a single branch or post-hoc tuning. revision: yes
-
Referee: [Abstract] Abstract and evaluation description: the manuscript states clear numerical improvements on named public datasets yet provides neither error bars, ablation tables on fusion operators (product vs. other combiners), nor full training hyper-parameters and data splits. These omissions directly affect the ability to assess whether the reported 60% relative reduction is reproducible and attributable to the proposed fusion mechanism.
Authors: We concur that these elements are essential for reproducibility. While the manuscript already details the training hyperparameters and data splits in the experimental section, we will augment the revision with: error bars (mean and standard deviation across multiple random seeds), a new ablation table comparing the product operator against sum, max, and learned combiners, and explicit confirmation of all dataset splits. This will allow direct assessment of whether the reported gains are attributable to the proposed fusion. revision: yes
Circularity Check
No circularity; empirical system evaluation on public datasets
full rationale
The paper describes an engineering framework (phoneme encoder + GE2E speaker encoder + multiplicative late fusion) and reports relative FRR reductions on LibriPhrase, Google Speech Commands, and Qualcomm datasets against baselines. No derivation chain, equations, or self-citation is presented that reduces a claimed result to a fitted input or prior author result by construction. The fusion is introduced as an inference-time design choice; performance numbers are measured externally on held-out data. This matches the default case of a self-contained empirical paper.
Axiom & Free-Parameter Ledger
free parameters (2)
- speaker encoder parameters =
0.9M
- total model size =
1.55M
axioms (1)
- domain assumption GE2E-pretrained speaker encoder transfers to the keyword-spotting task without retraining
Reference graph
Works this paper leans on
-
[1]
Conventional KWS has long focused on compact on-device models [1]
Introduction V oice user interfaces require activation mechanisms that are ef- ficient, secure, and personalized. Conventional KWS has long focused on compact on-device models [1]. User-defined key- word spotting (UD-KWS) extends this line by enabling zero- shot wake-word detection from arbitrary text inputs, eliminat- ing retraining for new keywords [2–8...
-
[2]
Proposed Method 2.1. Framework Overview To address the dual zero-shot challenge while minimizing task interference, ZP-KWS uses two functionally separated branches: a TI-SV branch for speaker identity and a phoneme- supervised branch for keyword content. The core design choice is inference-time late fusion (dashed path in Figure 1). Instead of additive sc...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Experimental Setup Datasets.We evaluated ZP-KWS on LibriPhrase [9] (Easy and Hard splits) as the in-domain benchmark
Experiments 3.1. Experimental Setup Datasets.We evaluated ZP-KWS on LibriPhrase [9] (Easy and Hard splits) as the in-domain benchmark. To test out-of-domain generalization, we additionally used Google Speech Commands (GSC) [26] and Qualcomm Keyword Speech [27], which intro- duce different acoustic conditions and vocabularies. In all eval- uations, both ta...
2048
-
[4]
Conclusion and Future Work This work demonstrates that user-defined keyword spotting can incorporate biometric security without sacrificing zero- shot keyword generalization. Our central finding is that text- independent speaker verification becomes practical for short- utterance UD-KWS when the architecture is functionally de- coupled: i) a GE2E-pretrain...
-
[5]
Gemini 3 Pro, ChatGPT, and Prism were used only for language refinement and editorial pol- ishing
Generative AI Use Disclosure Claude Opus 4.5 was used only for limited coding assistance (e.g., debugging suggestions). Gemini 3 Pro, ChatGPT, and Prism were used only for language refinement and editorial pol- ishing. All study design, implementation, experiments, and fi- nal scientific decisions were performed and verified by the au- thors
-
[6]
Any findings and implications in the paper do not necessarily reflect those of the sponsors
Acknowledgment This work was supported in part by Realtek Semiconductor Cor- poration under Grant Numbers 113KK01103 and 114KK01005. Any findings and implications in the paper do not necessarily reflect those of the sponsors
-
[7]
Small-footprint keyword spotting using deep neural networks,
G. Chen, C. Parada, and G. Heigold, “Small-footprint keyword spotting using deep neural networks,” inProc. ICASSP, 2014
2014
-
[8]
Metric learning for user-defined keyword spotting,
J. Jung, Y . Kim, J. Park, Y . Lim, B.-Y . Kim, Y . Jang, and J. S. Chung, “Metric learning for user-defined keyword spotting,” in Proc. ICASSP, 2023
2023
-
[9]
Open- vocabulary keyword-spotting with adaptive instance normaliza- tion,
A. Navon, A. Shamsian, N. Glazer, G. Hetz, and J. Keshet, “Open- vocabulary keyword-spotting with adaptive instance normaliza- tion,” inProc. ICASSP, 2024
2024
-
[10]
Flexible keyword spotting based on homogeneous audio-text embedding,
K. Nishu, M. Cho, P. Dixon, and D. Naik, “Flexible keyword spotting based on homogeneous audio-text embedding,” inProc. ICASSP, 2024
2024
-
[11]
Contrastive learning with audio discrimination for customizable keyword spotting in continuous speech,
Y . Xi, B. Yang, H. Li, J. Guo, and K. Yu, “Contrastive learning with audio discrimination for customizable keyword spotting in continuous speech,” inProc. ICASSP, 2024
2024
-
[12]
Adversarial deep metric learning for cross-modal audio-text alignment in open-vocabulary keyword spotting,
Y . Jung, Y .-H. Lee, M. Jung, J. Roh, C. W. Han, and H.-Y . Cho, “Adversarial deep metric learning for cross-modal audio-text alignment in open-vocabulary keyword spotting,” inProc. Inter- speech, 2025
2025
-
[13]
Dual data scaling for robust two-stage user-defined keyword spotting,
Z. Ai, H. Cheng, Y . Wang, S. Mu, Y . Zhou, and S. Xu, “Dual data scaling for robust two-stage user-defined keyword spotting,” inProc. ICASSP, 2026
2026
-
[14]
MATE: Matryoshka audio-text embeddings for open-vocabulary keyword spotting,
Y . Jung, M. Jung, J.-Y . Yang, Y .-H. Lee, J. Roh, and H.-Y . Cho, “MATE: Matryoshka audio-text embeddings for open-vocabulary keyword spotting,” inProc. ICASSP, 2026
2026
-
[15]
Learning audio-text agreement for open-vocabulary keyword spotting,
H.-K. Shin, H. Han, D. Kim, S.-W. Chung, and H.-G. Kang, “Learning audio-text agreement for open-vocabulary keyword spotting,” inProc. Interspeech, 2022
2022
-
[16]
PhonMatchNet: Phoneme-guided zero- shot keyword spotting for user-defined keywords,
Y .-H. Lee and N. Cho, “PhonMatchNet: Phoneme-guided zero- shot keyword spotting for user-defined keywords,” inProc. Inter- speech, 2023
2023
-
[17]
MM-KWS: Multi-modal prompts for multilingual user-defined keyword spotting,
Z. Ai, Z. Chen, and S. Xu, “MM-KWS: Multi-modal prompts for multilingual user-defined keyword spotting,” inProc. Interspeech, 2024
2024
-
[18]
Personalized keyword spotting through multi-task learning,
S. Yang, B. Kim, I. Chung, and S. Chang, “Personalized keyword spotting through multi-task learning,” inProc. Interspeech, 2022
2022
-
[19]
X-vectors: Robust DNN embeddings for speaker recogni- tion,
D. Snyder, D. Garcia-Romero, G. Sell, D. Povey, and S. Khudan- pur, “X-vectors: Robust DNN embeddings for speaker recogni- tion,” inProc. ICASSP, 2018
2018
-
[20]
ECAPA- TDNN: Emphasized channel attention, propagation and aggrega- tion in TDNN based speaker verification,
B. Desplanques, J. Thienpondt, and K. Demuynck, “ECAPA- TDNN: Emphasized channel attention, propagation and aggrega- tion in TDNN based speaker verification,” inProc. Interspeech, 2020
2020
-
[21]
MFA: TDNN with multi- scale frequency-channel attention for text-independent speaker verification with short utterances,
T. Liu, R. K. Das, K. A. Lee, and H. Li, “MFA: TDNN with multi- scale frequency-channel attention for text-independent speaker verification with short utterances,” inProc. ICASSP, 2022
2022
-
[22]
CAM++: A fast and efficient network for speaker verification using context- aware masking,
H. Wang, S. Zheng, Y . Chen, L. Cheng, and Q. Chen, “CAM++: A fast and efficient network for speaker verification using context- aware masking,” inProc. Interspeech, 2023
2023
-
[23]
ERes2NetV2: Boosting short-duration speaker verification performance with computational efficiency,
Y . Chen, S. Zheng, H. Wang, L. Cheng, Q. Chen, S. Zhang, and J. Li, “ERes2NetV2: Boosting short-duration speaker verification performance with computational efficiency,” inProc. Interspeech, 2024
2024
-
[24]
Towards supervised per- formance on speaker verification with self-supervised learning by leveraging large-scale ASR models,
V . Miara, T. Lepage, and R. Dehak, “Towards supervised per- formance on speaker verification with self-supervised learning by leveraging large-scale ASR models,” inProc. Interspeech, 2024
2024
-
[25]
Ef- ficientTDNN: Efficient architecture search for speaker recogni- tion,
R. Wang, Z. Wei, H. Duan, S. Ji, Y . Long, and Z. Hong, “Ef- ficientTDNN: Efficient architecture search for speaker recogni- tion,”IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 30, 2022
2022
-
[26]
Generalized end- to-end loss for speaker verification,
L. Wan, Q. Wang, A. Papir, and I. L. Moreno, “Generalized end- to-end loss for speaker verification,” inProc. ICASSP, 2018
2018
-
[27]
V oxCeleb2: Deep speaker recognition,
J. S. Chung, A. Nagrani, and A. Zisserman, “V oxCeleb2: Deep speaker recognition,” inProc. Interspeech, 2018
2018
-
[28]
Training key- word spotters with limited and synthesized speech data,
J. Lin, K. Kilgour, D. Roblek, and M. Sharifi, “Training key- word spotters with limited and synthesized speech data,” inProc. ICASSP, 2020
2020
-
[29]
J. L. Ba, J. R. Kiros, and G. E. Hinton, “Layer normalization,” arXiv preprint arXiv:1607.06450, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[30]
Montreal forced aligner: Trainable text-speech align- ment using Kaldi,
M. McAuliffe, M. Socolof, S. Mihuc, M. Wagner, and M. Son- deregger, “Montreal forced aligner: Trainable text-speech align- ment using Kaldi,” inProc. Interspeech, 2017
2017
-
[31]
Re- thinking the inception architecture for computer vision,
C. Szegedy, V . Vanhoucke, S. Ioffe, J. Shlens, and Z. Wojna, “Re- thinking the inception architecture for computer vision,” inProc. CVPR, 2016
2016
-
[32]
Speech Commands: A Dataset for Limited-Vocabulary Speech Recognition
P. Warden, “Speech commands: A dataset for limited-vocabulary speech recognition,” arXiv preprint arXiv:1804.03209, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[33]
Query-by- example on-device keyword spotting,
B. Kim, M. Lee, J. Lee, Y . Kim, and K. Hwang, “Query-by- example on-device keyword spotting,” inProc. ASRU, 2019
2019
-
[34]
Bootstrap estimates for confidence inter- vals in ASR performance evaluation,
M. Bisani and H. Ney, “Bootstrap estimates for confidence inter- vals in ASR performance evaluation,” inProc. ICASSP, 2004
2004
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.