Zero-VC: Zero-Lookahead Streaming Voice Conversion via Speaker Anonymization
Pith reviewed 2026-06-26 15:47 UTC · model grok-4.3
The pith
Speaker anonymization enables a strictly causal zero-lookahead network for streaming voice conversion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the inherent objective of Speaker Anonymization aligns with the timbre-leakage versus utility-preservation trade-off overlooked by prior perturbation methods. SA therefore acts as a perturbation that explicitly mitigates timbre leakage while retaining prosodic utility. Because SA produces robust representations, the generator no longer needs future context, which directly enables a strictly causal, zero-lookahead streaming voice-conversion network.
What carries the argument
Speaker Anonymization used as a perturbation mechanism that balances timbre leakage against prosodic-utility preservation.
If this is right
- The conversion network operates with zero algorithmic latency because no future frames are buffered.
- Prosody is retained without explicit injection of features such as fundamental frequency.
- Timbre leakage is reduced while utility is kept at a level suitable for zero-shot conversion.
- The system remains strictly causal at every stage of processing.
Where Pith is reading between the lines
- The same SA perturbation could be tested in other real-time speech tasks that require disentanglement without lookahead.
- Privacy techniques originally designed for anonymization may turn out to be useful for utility-preserving streaming applications in general.
- An implementation that combines SA with existing causal vocoders would provide a concrete way to measure end-to-end latency gains.
Load-bearing premise
Speaker anonymization's objective inherently supplies the right balance between timbre leakage reduction and prosodic utility preservation that earlier perturbation techniques missed.
What would settle it
A direct test showing that SA-derived representations still force the generator to buffer future frames or cause measurable loss of prosody would falsify the zero-lookahead claim.
Figures

read the original abstract
Streaming zero-shot voice conversion struggles to disentangle timbre from linguistic content without degrading utility or inflating latency. Current methods rely on information bottleneck (IB) or speaker perturbation. While IB filters out timbre, it discards prosody, forcing models to explicitly inject features like fundamental frequency. This often requires buffering future frames, creating algorithmic lookahead latency. On the other hand, existing perturbation methods largely overlook the crucial trade-off between timbre leakage and utility preservation. Recognizing this neglected trade-off, we find that the inherent objective of Speaker Anonymization (SA) aligns well with balancing these factors. Thus, we introduce SA as a novel perturbation mechanism to explicitly mitigate timbre leakage while retaining prosodic utility. Crucially, SA's robust representations significantly alleviate the generator's reliance on future context, enabling our strictly causal, zero-lookahead network. Audio samples are available at https://amphionteam.github.io/Zero-VC-demo/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Zero-VC, a streaming zero-shot voice conversion architecture that replaces information-bottleneck or conventional perturbation modules with speaker anonymization (SA) representations. It claims that SA's inherent objective naturally balances timbre leakage against prosodic utility, thereby removing the generator's need for future-frame buffering and enabling a strictly causal, zero-lookahead network.
Significance. If the central claim is substantiated, the work would offer a practical route to zero algorithmic latency in real-time voice conversion while preserving utility, a combination that prior IB and perturbation approaches have not simultaneously achieved. The positioning of SA as an off-the-shelf mechanism that already encodes the desired trade-off is a concise conceptual contribution.
major comments (2)
- [Abstract] Abstract: the claim that 'SA's robust representations significantly alleviate the generator's reliance on future context' is asserted without any equations, architectural diagrams, ablation tables, or quantitative latency/quality metrics in the supplied text; the description alone does not demonstrate that the math or results back the stated outcome.
- [Abstract] Abstract: the assertion that 'the inherent objective of Speaker Anonymization (SA) aligns well with balancing the timbre leakage versus utility preservation trade-off' is presented as a discovery but is not accompanied by a formal comparison (e.g., mutual-information bounds or empirical leakage-utility curves) that would distinguish it from prior perturbation methods.
Simulated Author's Rebuttal
We thank the referee for the comments on the abstract. The full manuscript provides the supporting architecture, ablations, and metrics; we address each point below and indicate where revisions can strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'SA's robust representations significantly alleviate the generator's reliance on future context' is asserted without any equations, architectural diagrams, ablation tables, or quantitative latency/quality metrics in the supplied text; the description alone does not demonstrate that the math or results back the stated outcome.
Authors: The abstract summarizes the core contribution. Section 3 details the SA perturbation equations and the strictly causal generator architecture (with diagrams), while Section 4 and the associated tables provide ablations on context reliance and quantitative results demonstrating zero-lookahead operation with preserved quality. These elements substantiate the claim relative to IB baselines. We will revise the abstract to reference the experimental validation more explicitly. revision: yes
-
Referee: [Abstract] Abstract: the assertion that 'the inherent objective of Speaker Anonymization (SA) aligns well with balancing the timbre leakage versus utility preservation trade-off' is presented as a discovery but is not accompanied by a formal comparison (e.g., mutual-information bounds or empirical leakage-utility curves) that would distinguish it from prior perturbation methods.
Authors: The manuscript motivates the alignment from SA's objective of removing timbre while retaining prosodic and linguistic utility, with empirical comparisons to prior perturbation approaches shown in the experiments (including leakage-utility analysis). No mutual-information bounds are derived. We can add a sentence to the abstract noting the empirical distinction if helpful, but the primary contribution remains the application to zero-lookahead streaming VC. revision: partial
Circularity Check
No significant circularity detected
full rationale
The abstract and positioning present SA as an external mechanism whose objectives are asserted to align with the timbre-utility trade-off, enabling causal operation. No equations, fitted parameters renamed as predictions, self-citations used as load-bearing uniqueness theorems, or self-definitional reductions appear in the supplied text. The derivation chain remains self-contained against external benchmarks and does not reduce any claimed result to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Speaker Anonymization objective aligns with balancing timbre leakage and prosodic utility preservation
Reference graph
Works this paper leans on
-
[1]
Introduction Zero-shot V oice Conversion (VC) aims to convert a source speaker’s voice to an unseen target speaker’s voice using only a brief reference utterance [1]. In recent years, driven by ad- vances in deep learning, zero-shot VC has achieved remarkable success [2, 3, 4, 5, 6, 7, 8, 9] and has been widely adopted in var- ious real-world scenarios. H...
Pith/arXiv arXiv 2026
-
[2]
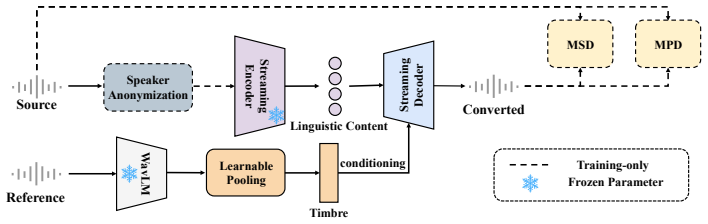
Method The overall framework of Zero-VC is illustrated in Fig. 1. Our model adopts a strictly causal, zero-lookahead architecture, consisting of a pretrained streaming encoder module (e.g., a distilled streaming w2v-bert-2.0 [14]), a timbre encoding mod- ule, and a streaming decoder. The speaker anonymization (SA) module and two discriminators (i.e., MPD ...
-
[3]
Experimental Setup 3.1.1
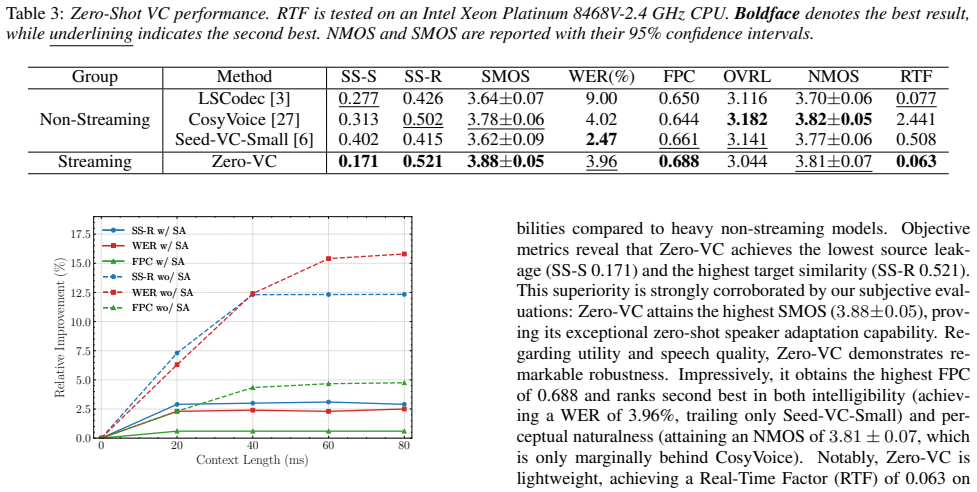
Experiments 3.1. Experimental Setup 3.1.1. Datasets Our model is trained on LibriTTS [19], which is an English corpus with 585 hours of speech data. We discard utterances shorter than 4 seconds and resample all audio to 16 kHz, result- ing in approximately 460 hours of training data. For evaluation, we utilize the English subset of the seed-tts-eval datas...
-
[4]
Depending on the SA module’s specific implemen- tation, this pre-processing step may introduce its own training overhead
Limitations and Future Work While Zero-VC achieves superior zero-lookahead latency for the core VC generator, the current training pipeline relies on an off-the-shelf SA module to preprocess source audio during training. Depending on the SA module’s specific implemen- tation, this pre-processing step may introduce its own training overhead. Future work wi...
-
[5]
By identifying the critical trade-off between timbre leakage and utility preser- vation, we introduce Speaker Anonymization as an innovative perturbation mechanism
Conclusion In this paper, we present Zero-VC, a novel strictly causal, zero- lookahead streaming voice conversion system. By identifying the critical trade-off between timbre leakage and utility preser- vation, we introduce Speaker Anonymization as an innovative perturbation mechanism. This effective feature disentangle- ment significantly alleviates the ...
-
[6]
T00120230002) and the Program for Guangdong In- troducing Innovative and Enterpreneurial Teams (Grant No
Acknowledgments This work is partially supported by the Internal Project Fund from Shenzhen Research Institute of Big Data (Grant No. T00120230002) and the Program for Guangdong In- troducing Innovative and Enterpreneurial Teams (Grant No. 2023ZT10X044). We thank the anonymous reviewers for their insightful comments and suggestions. We appreciate the effo...
-
[7]
After polishing, the manuscript was re- vised, and the authors take full responsibility for the originality and final content of the publication
Generative AI Use Disclosure The authors used Google Gemini for language polishing and grammar checking. After polishing, the manuscript was re- vised, and the authors take full responsibility for the originality and final content of the publication
-
[8]
An overview of voice conversion and its challenges: From statistical modeling to deep learning,
B. Sisman, J. Yamagishi, S. King, and H. Li, “An overview of voice conversion and its challenges: From statistical modeling to deep learning,”IEEE/ACM transactions on audio, speech, and language processing, vol. 29, pp. 132–157, 2020
2020
-
[9]
Vevo: Controllable zero-shot voice imitation with self-supervised disentanglement,
X. Zhang, X. Zhang, K. Peng, Z. Tang, V . Manohar, Y . Liu, J. Hwang, D. Li, Y . Wang, J. Chanet al., “Vevo: Controllable zero-shot voice imitation with self-supervised disentanglement,” inThe Thirteenth International Conference on Learning Repre- sentations
-
[10]
Lscodec: Low-bitrate and speaker-decoupled discrete speech codec,
Y . Guo, Z. Li, C. Du, H. Wang, X. Chen, and K. Yu, “Lscodec: Low-bitrate and speaker-decoupled discrete speech codec,” in Proc. Interspeech 2025, 2025, pp. 5018–5022
2025
-
[11]
Naturalspeech 3: zero-shot speech syn- thesis with factorized codec and diffusion models,
Z. Ju, Y . Wang, K. Shen, X. Tan, D. Xin, D. Yang, Y . Liu, Y . Leng, K. Song, S. Tanget al., “Naturalspeech 3: zero-shot speech syn- thesis with factorized codec and diffusion models,” inProceed- ings of the 41st International Conference on Machine Learning, 2024, pp. 22 605–22 623
2024
-
[12]
Streamvc: Real-time low-latency voice conver- sion,
Y . Yang, Y . Kartynnik, Y . Li, J. Tang, X. Li, G. Sung, and M. Grundmann, “Streamvc: Real-time low-latency voice conver- sion,” inICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 11 016–11 020
2024
-
[13]
Zero-shot voice conversion with diffusion transformers,
S. Liu, “Zero-shot voice conversion with diffusion transformers,” arXiv preprint arXiv:2411.09943, 2024
arXiv 2024
-
[14]
Vevo2: Bridging controllable speech and singing voice generation via unified prosody learning,
X. Zhang, J. Zhang, Y . Wang, C. Wang, Y . Chen, D. Jia, Z. Chen, and Z. Wu, “Vevo2: Bridging controllable speech and singing voice generation via unified prosody learning,”arXiv e-prints, pp. arXiv–2508, 2025
2025
-
[15]
Noro: Noise-robust one-shot voice con- version with hidden speaker representation learning,
H. He, Y . Song, Y . Wang, H. Li, X. Zhang, L. Wang, G. Huang, E. S. Chng, and Z. Wu, “Noro: Noise-robust one-shot voice con- version with hidden speaker representation learning,” in2025 Asia Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC). IEEE, 2025, pp. 2247– 2251
2025
-
[16]
Leveraging diverse semantic-based audio pretrained models for singing voice conversion,
X. Zhang, Z. Fang, Y . Gu, H. Chen, L. Zou, J. Zhang, L. Xue, and Z. Wu, “Leveraging diverse semantic-based audio pretrained models for singing voice conversion,” in2024 IEEE Spoken Lan- guage Technology Workshop (SLT). IEEE, 2024, pp. 758–765
2024
-
[17]
Rt- vc: Real-time zero-shot voice conversion with speech articulatory coding,
Y . Liu, C. Wang, H. Kim, R. Khan, and G. Anumanchipalli, “Rt- vc: Real-time zero-shot voice conversion with speech articulatory coding,” inProceedings of the 63rd Annual Meeting of the Asso- ciation for Computational Linguistics (Volume 3: System Demon- strations), 2025, pp. 385–393
2025
-
[18]
Openvoice: Versatile instant voice cloning,
Z. Qin, W. Zhao, X. Yu, and X. Sun, “Openvoice: Versatile instant voice cloning,”arXiv preprint arXiv:2312.01479, 2023
arXiv 2023
-
[19]
The voiceprivacy 2022 challenge: Progress and perspec- tives in voice anonymisation,
M. Panariello, N. Tomashenko, X. Wang, X. Miao, P. Champion, H. Nourtel, M. Todisco, N. Evans, E. Vincent, and J. Yamag- ishi, “The voiceprivacy 2022 challenge: Progress and perspec- tives in voice anonymisation,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 32, pp. 3477–3491, 2024
2022
-
[20]
Hifi-gan: Generative adversarial net- works for efficient and high fidelity speech synthesis,
J. Kong, J. Kim, and J. Bae, “Hifi-gan: Generative adversarial net- works for efficient and high fidelity speech synthesis,”Advances in neural information processing systems, vol. 33, pp. 17 022– 17 033, 2020
2020
-
[21]
Seamless: Multilingual expressive and streaming speech translation,
L. Barrault, Y .-A. Chung, M. C. Meglioli, D. Dale, N. Dong, M. Duppenthaler, P.-A. Duquenne, B. Ellis, H. Elsahar, J. Haa- heimet al., “Seamless: Multilingual expressive and streaming speech translation,”arXiv preprint arXiv:2312.05187, 2023
arXiv 2023
-
[22]
Probing the feasibility of mul- tilingual speaker anonymization,
S. Meyer, F. Lux, and N. T. Vu, “Probing the feasibility of mul- tilingual speaker anonymization,” inInterspeech 2024, 2024, pp. 4448–4452
2024
-
[23]
Wavlm: Large-scale self- supervised pre-training for full stack speech processing,
S. Chen, C. Wang, Z. Chen, Y . Wu, S. Liu, Z. Chen, J. Li, N. Kanda, T. Yoshioka, X. Xiaoet al., “Wavlm: Large-scale self- supervised pre-training for full stack speech processing,”IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1505–1518, 2022
2022
-
[24]
Superb: Speech processing universal performance benchmark,
S.-w. Yang, P.-H. Chi, Y .-S. Chuang, C.-I. J. Lai, K. Lakhotia, Y . Y . Lin, A. T. Liu, J. Shi, X. Chang, G.-T. Linet al., “Superb: Speech processing universal performance benchmark,” inProc. Interspeech 2021, 2021, pp. 1194–1198
2021
-
[25]
Hifi-vc: High quality asr-based voice conversion,
“Hifi-vc: High quality asr-based voice conversion,”arXiv preprint arXiv:2203.16937, 2022
arXiv 2022
-
[26]
Libritts: A corpus derived from librispeech for text- to-speech,
H. Zen, V . Dang, R. Clark, Y . Zhang, R. J. Weiss, Y . Jia, Z. Chen, and Y . Wu, “Libritts: A corpus derived from librispeech for text- to-speech,” inProc. Interspeech 2019, 2019, pp. 1526–1530
2019
-
[27]
Seed-tts: A family of high-quality versatile speech generation models,
P. Anastassiou, J. Chen, J. Chen, Y . Chen, Z. Chen, Z. Chen, J. Cong, L. Deng, C. Ding, L. Gaoet al., “Seed-tts: A family of high-quality versatile speech generation models,”arXiv preprint arXiv:2406.02430, 2024
Pith/arXiv arXiv 2024
-
[28]
Com- mon voice: A massively-multilingual speech corpus,
R. Ardila, M. Branson, K. Davis, M. Kohler, J. Meyer, M. Hen- retty, R. Morais, L. Saunders, F. Tyers, and G. Weber, “Com- mon voice: A massively-multilingual speech corpus,” inProceed- ings of the twelfth language resources and evaluation conference, 2020, pp. 4218–4222
2020
-
[29]
Large-scale self-supervised speech representation learning for automatic speaker verification,
Z. Chen, S. Chen, Y . Wu, Y . Qian, C. Wang, S. Liu, Y . Qian, and M. Zeng, “Large-scale self-supervised speech representation learning for automatic speaker verification,” inICASSP 2022- 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 6147–6151
2022
-
[30]
Robust speech recognition via large-scale weak supervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak supervision,” inInternational conference on machine learning. PMLR, 2023, pp. 28 492–28 518
2023
-
[31]
Dnsmos p. 835: A non-intrusive perceptual objective speech quality metric to evalu- ate noise suppressors,
C. K. Reddy, V . Gopal, and R. Cutler, “Dnsmos p. 835: A non-intrusive perceptual objective speech quality metric to evalu- ate noise suppressors,” inICASSP 2022-2022 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2022, pp. 886–890
2022
-
[32]
Decoupled weight decay regulariza- tion,
I. Loshchilov and F. Hutter, “Decoupled weight decay regulariza- tion,” inInternational Conference on Learning Representations
-
[33]
Sgdr: Stochastic gradient descent with warm restarts,
——, “Sgdr: Stochastic gradient descent with warm restarts,” in International Conference on Learning Representations, 2017
2017
-
[34]
Z. Du, Q. Chen, S. Zhang, K. Hu, H. Lu, Y . Yang, H. Hu, S. Zheng, Y . Gu, Z. Maet al., “Cosyvoice: A scalable multi- lingual zero-shot text-to-speech synthesizer based on supervised semantic tokens,”arXiv preprint arXiv:2407.05407, 2024
Pith/arXiv arXiv 2024
-
[35]
Dualvc 3: Leveraging language model generated pseudo context for end-to-end low latency streaming voice conversion,
Z. Ning, S. Wang, P. Zhu, Z. Wang, J. Yao, L. Xie, and M. Bi, “Dualvc 3: Leveraging language model generated pseudo context for end-to-end low latency streaming voice conversion,” inProc. Interspeech 2024, 2024, pp. 197–201
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.