ASAP: A Disaggregated and Asynchronous Inference System for MoE Prefill
Pith reviewed 2026-06-26 09:40 UTC · model grok-4.3
The pith
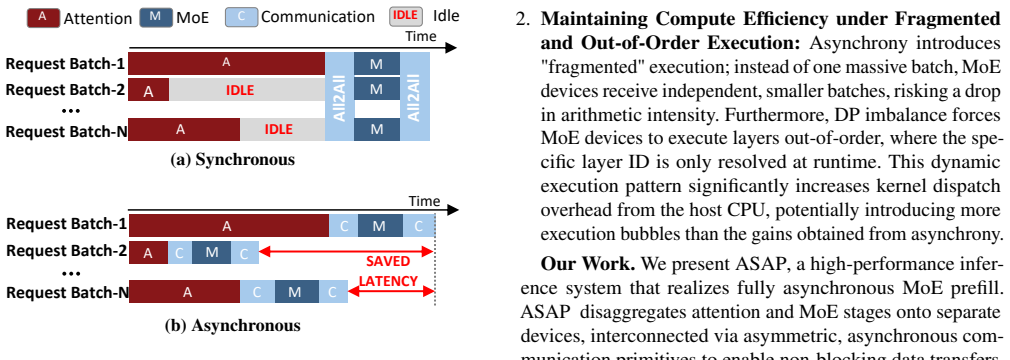
ASAP disaggregates attention and MoE stages into an asynchronous pipeline to remove global synchronization barriers during prefill.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
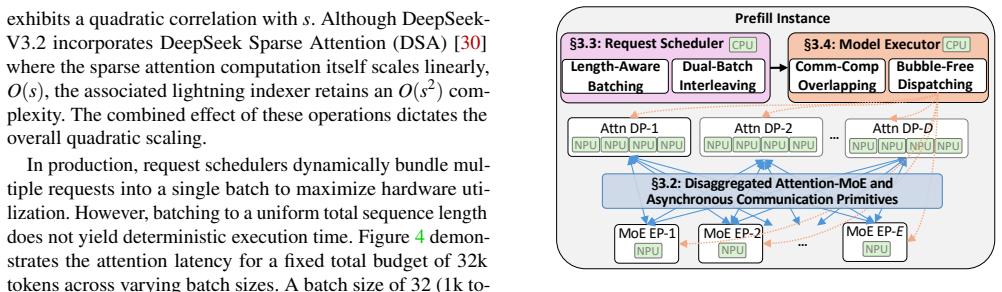
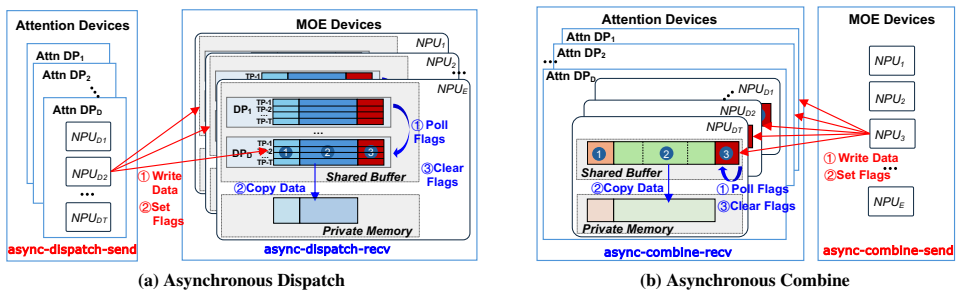
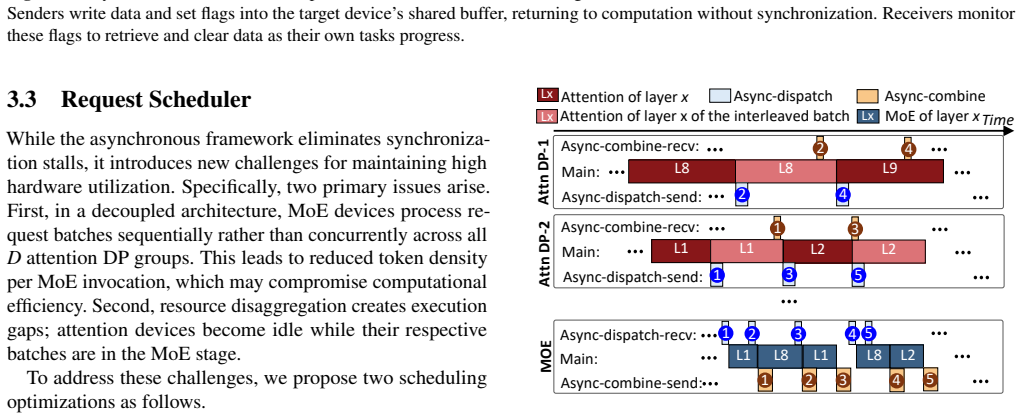
Disaggregating attention DP groups from expert-parallel MoE stages and replacing their global synchronization barriers with an asynchronous pipeline, achieved through specialized async communication primitives and four coordinated optimizations in request scheduling and model execution, removes the stalls that arise from request variance in online MoE serving.
What carries the argument
The suite of specialized asynchronous communication primitives together with four coordinated optimizations across request scheduling and model execution that enable the disaggregated asynchronous pipeline between attention and MoE stages.
If this is right
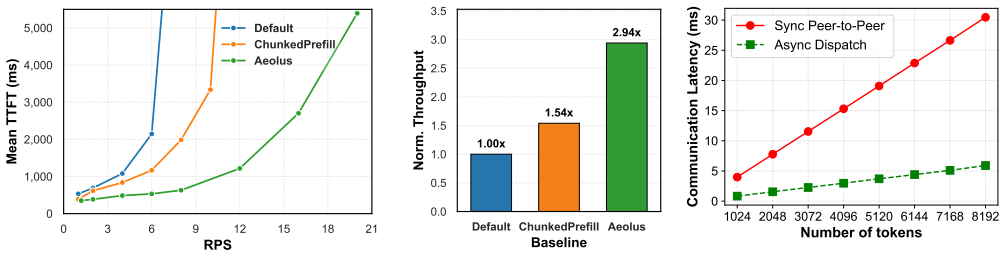
- SLO-compliant prefill throughput rises by 90 percent on the evaluated hardware.
- Time-to-first-token improves because request-length variance no longer forces global stalls.
- The hybrid parallelism strategy can be retained without paying the previous synchronization cost.
- Online serving of large MoE models becomes feasible at higher request rates without additional hardware.
Where Pith is reading between the lines
- The same disaggregation pattern could be applied to the decode phase if similar stage imbalance appears there.
- Clusters with heterogeneous interconnects might see larger gains because the async design reduces the frequency of global barriers.
- Request schedulers in other hybrid-parallel systems could adopt the four optimizations independently of the communication primitives.
Load-bearing premise
The reduction in synchronization stalls will not be offset by new communication or scheduling overheads introduced by the asynchronous design.
What would settle it
A direct measurement, under the same request traces, of end-to-end prefill latency and throughput when the async primitives are replaced by their synchronous equivalents while keeping all other scheduling changes fixed.
Figures



read the original abstract
Mixture-of-Experts (MoE) models have become the de facto standard for scaling large language models. To maintain computational efficiency, modern MoE serving systems typically employ a hybrid parallelism strategy, combining Data Parallelism (DP) for attention stages with Expert Parallelism (EP) for MoE stages. However, this design necessitates frequent global synchronization barriers between attention DP groups and experts. In online serving, significant variance in request arrival rates and sequence lengths inherently leads to DP imbalance, causing severe synchronization stalls that degrade Time-to-First-Token (TTFT) and system throughput. We present ASAP, an asynchronous inference system specifically designed to accelerate the prefill phase of MoE models. ASAP disaggregates the attention and MoE stages and implements a fully asynchronous execution pipeline. This is achieved through a suite of specialized asynchronous communication primitives and four coordinated optimizations across request scheduling and model execution, which collectively dismantle global synchronization barriers. We implement and evaluate ASAP on CloudMatrix384 super-nodes, demonstrating that it improves SLO-compliant prefill throughput by 90% compared to state-of-the-art synchronous serving solutions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that hybrid DP-EP parallelism in MoE serving creates global synchronization barriers due to request variance, degrading TTFT and throughput; ASAP addresses this by disaggregating attention and MoE stages into a fully asynchronous pipeline using specialized communication primitives plus four coordinated optimizations in scheduling and execution, yielding a 90% gain in SLO-compliant prefill throughput versus state-of-the-art synchronous systems when evaluated on CloudMatrix384 super-nodes.
Significance. If the reported throughput improvement is substantiated with complete methodology and overhead accounting, the work would be a meaningful systems contribution to MoE inference, directly targeting a practical bottleneck in online serving of large expert-parallel models and demonstrating the viability of disaggregation plus asynchrony for prefill acceleration.
major comments (2)
- [Abstract] Abstract: the central 90% SLO-compliant prefill throughput claim is load-bearing yet presented with no description of workload (request arrival rates, sequence-length variance), MoE model size, exact synchronous baselines, SLO definition, or measurement methodology, preventing assessment of whether the async primitives deliver a net gain over removed sync stalls.
- [Evaluation] Evaluation: the manuscript provides no quantitative breakdown (e.g., time saved from barrier removal versus added queuing, communication, or scheduling overhead from the new primitives and disaggregation) under the high-variance conditions identified as the original problem; without this, the assumption that the four optimizations produce strictly lower net cost remains unverified.
minor comments (1)
- [Abstract] The abstract would be clearer if it briefly enumerated the four coordinated optimizations rather than referring to them only generically.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation of major revision. We address each major comment below and outline the corresponding revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central 90% SLO-compliant prefill throughput claim is load-bearing yet presented with no description of workload (request arrival rates, sequence-length variance), MoE model size, exact synchronous baselines, SLO definition, or measurement methodology, preventing assessment of whether the async primitives deliver a net gain over removed sync stalls.
Authors: The abstract is written to be concise. Workload parameters (arrival rates, sequence-length distributions), model sizes, baseline configurations, SLO definitions, and measurement methodology are described in the Evaluation section. To improve standalone readability of the abstract, we will add a brief clause summarizing the workload and evaluation setup. revision: yes
-
Referee: [Evaluation] Evaluation: the manuscript provides no quantitative breakdown (e.g., time saved from barrier removal versus added queuing, communication, or scheduling overhead from the new primitives and disaggregation) under the high-variance conditions identified as the original problem; without this, the assumption that the four optimizations produce strictly lower net cost remains unverified.
Authors: We agree that an explicit decomposition of net benefit (barrier removal savings versus added queuing, communication, and scheduling costs) under high request variance would strengthen the evaluation. We will add this breakdown, including per-component timing measurements on the same high-variance traces used for the main results. revision: yes
Circularity Check
No circularity; empirical systems evaluation with direct measurements
full rationale
The paper describes an implementation of ASAP with disaggregation and asynchronous primitives for MoE prefill, then reports measured throughput gains (90% SLO-compliant prefill throughput) on CloudMatrix384 hardware versus synchronous baselines. No equations, fitted parameters, derivations, or self-citations appear in the provided text; the central claim rests on external benchmarking rather than any reduction of outputs to inputs by construction. This is a standard empirical systems result with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
https://www.mindspore.cn/tutorials/experts /en/r2.3.1/operation/op_custom_ascendc.htm l, 2025
Ascend C Custom Operator Development and Usage. https://www.mindspore.cn/tutorials/experts /en/r2.3.1/operation/op_custom_ascendc.htm l, 2025
2025
-
[2]
https://www.hiascend.com/cann, 2025
Compute Architecture for Neural Networks (CANN). https://www.hiascend.com/cann, 2025
2025
-
[3]
https://www.hiasce nd.com/document/detail/zh/canncommercial/8 3RC1/API/ascendcopapi/atlasascendc_api_07_ 0102.html, 2025
Data Movement in Ascend C. https://www.hiasce nd.com/document/detail/zh/canncommercial/8 3RC1/API/ascendcopapi/atlasascendc_api_07_ 0102.html, 2025
2025
-
[4]
https://www
Memory Management of Ascend NPU. https://www. hiascend.com/document/detail/zh/canncommer cial/83RC1/API/appdevgapi/aclpythondevg_01 _0110.html, 2025
2025
-
[5]
Amey Agrawal, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav S Gulavani, and Ramachan- dran Ramjee. Sarathi: Efficient llm inference by piggy- backing decodes with chunked prefills.arXiv preprint arXiv:2308.16369, 2023
Pith/arXiv arXiv 2023
-
[6]
William Brandon, Aniruddha Nrusimha, Kevin Qian, Zachary Ankner, Tian Jin, Zhiye Song, and Jonathan Ragan-Kelley. Striped attention: Faster ring attention for causal transformers.arXiv preprint arXiv:2311.09431, 2023
arXiv 2023
-
[7]
Characterizing cloud-native llm inference at bytedance and exposing optimization challenges and opportunities for future ai accelerators
Jingwei Cai, Dehao Kong, Hantao Huang, Zishan Jiang, Zixuan Ma, Qingyu Guo, Zhenxing Zhang, Guiming Shi, Mingyu Gao, and Kaisheng Ma. Characterizing cloud-native llm inference at bytedance and exposing optimization challenges and opportunities for future ai accelerators. In2026 IEEE International Symposium on High Performance Computer Architecture (HPCA),...
2026
-
[8]
Amali: An analytical model for accurately modeling llm inference on modern gpus
Shiheng Cao, Junmin Wu, Junshi Chen, Hong An, and Zhibin Yu. Amali: An analytical model for accurately modeling llm inference on modern gpus. InProceedings of the 52nd Annual International Symposium on Com- puter Architecture, ISCA ’25, page 1495–1508, New York, NY , USA, 2025. Association for Computing Ma- chinery
2025
-
[9]
Generating long sequences with sparse trans- formers.arXiv preprint arXiv:1904.10509, 2019
Rewon Child, Scott Gray, Alec Radford, and Ilya Sutskever. Generating long sequences with sparse trans- formers.arXiv preprint arXiv:1904.10509, 2019. 12
Pith/arXiv arXiv 1904
-
[10]
Lazy batching: An sla-aware batching system for cloud ma- chine learning inference
Yujeong Choi, Yunseong Kim, and Minsoo Rhu. Lazy batching: An sla-aware batching system for cloud ma- chine learning inference. In2021 IEEE International Symposium on High-Performance Computer Architec- ture (HPCA), pages 493–506, 2021
2021
-
[11]
Prediction is all moe needs: Expert load distribution goes from fluctuating to stabilizing, 2024
Peizhuang Cong, Aomufei Yuan, Shimao Chen, Yuxuan Tian, Bowen Ye, and Tong Yang. Prediction is all moe needs: Expert load distribution goes from fluctuating to stabilizing, 2024
2024
-
[12]
Fu, Stefano Ermon, Atri Rudra, and Christopher Ré
Tri Dao, Daniel Y . Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: Fast and memory- efficient exact attention with io-awareness.arXiv preprint arXiv:2205.14135, 2022
Pith/arXiv arXiv 2022
-
[13]
Deepseek-v3 technical report, 2025
DeepSeek-AI, Aixin Liu, Bei Feng, and etc Bing Xue. Deepseek-v3 technical report, 2025
2025
-
[14]
Longnet: Scaling transformers to 1,000,000,000 tokens, 2023
Jiayu Ding, Shuming Ma, Li Dong, Xingxing Zhang, Shaohan Huang, Wenhui Wang, Nanning Zheng, and Furu Wei. Longnet: Scaling transformers to 1,000,000,000 tokens, 2023
2023
-
[15]
Nan Du, Yanping Huang, Andrew M. Dai, Simon Tong, Dmitry Lepikhin, Yuanzhong Xu, Maxim Krikun, Yanqi Zhou, Adams Wei Yu, Orhan Firat, Barret Zoph, Liam Fedus, Maarten Bosma, Zongwei Zhou, Tao Wang, Yu Emma Wang, Kellie Webster, Marie Pellat, Kevin Robinson, Kathleen Meier-Hellstern, Toju Duke, Lucas Dixon, Kun Zhang, Quoc V Le, Yonghui Wu, Zhifeng Chen, a...
arXiv 2022
-
[16]
Switch transformers: scaling to trillion parameter models with simple and efficient sparsity.J
William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: scaling to trillion parameter models with simple and efficient sparsity.J. Mach. Learn. Res., 23(1), January 2022
2022
-
[17]
Parameter-efficient mixture-of- experts architecture for pre-trained language models
Ze-Feng Gao, Peiyu Liu, Wayne Xin Zhao, Zhong-Yi Lu, and Ji-Rong Wen. Parameter-efficient mixture-of- experts architecture for pre-trained language models. arXiv preprint arXiv:2203.01104, 2022
arXiv 2022
-
[18]
Raja Gond, Nipun Kwatra, and Ramachandran Ram- jee. Tokenweave: Efficient compute-communication overlap for distributed llm inference.arXiv preprint arXiv:2505.11329, 2025
Pith/arXiv arXiv 2025
-
[19]
Past-future scheduler for llm serving under sla guar- antees
Ruihao Gong, Shihao Bai, Siyu Wu, Yunqian Fan, Zai- jun Wang, Xiuhong Li, Hailong Yang, and Xianglong Liu. Past-future scheduler for llm serving under sla guar- antees. InProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, ASPLOS ’25, page 798–813, New York, NY , USA, 202...
2025
-
[20]
Ke Hong, Guohao Dai, Jiaming Xu, Qiuli Mao, Xiuhong Li, Jun Liu, Kangdi Chen, Yuhan Dong, and Yu Wang. Flashdecoding++: Faster large language model infer- ence on gpus.arXiv preprint arXiv:2311.01282, 2024
arXiv 2024
-
[21]
Cunchen Hu, Heyang Huang, Junhao Hu, Jiang Xu, Xusheng Chen, Tao Xie, Chenxi Wang, Sa Wang, Yun- gang Bao, and Ninghui Sun. Memserve: Context caching for disaggregated llm serving with elastic mem- ory pool.arXiv preprint arXiv:2406.17565, 2024
arXiv 2024
-
[22]
Deepserve: serverless large language model serving at scale
Junhao Hu, Jiang Xu, Zhixia Liu, Yulong He, Yuetao Chen, Hao Xu, Jiang Liu, Jie Meng, Baoquan Zhang, Shining Wan, Gengyuan Dan, Zhiyu Dong, Zhihao Ren, Changhong Liu, Tao Xie, Dayun Lin, Qin Zhang, Yue Yu, Hao Feng, Xusheng Chen, and Yizhou Shan. Deepserve: serverless large language model serving at scale. InProceedings of the 2025 USENIX Conference on Us...
2025
-
[23]
Ad- vancing transformer architecture in long-context large language models: A comprehensive survey, 2024
Yunpeng Huang, Jingwei Xu, Junyu Lai, Zixu Jiang, Taolue Chen, Zenan Li, Yuan Yao, Xiaoxing Ma, Lijuan Yang, Hao Chen, Shupeng Li, and Penghao Zhao. Ad- vancing transformer architecture in long-context large language models: A comprehensive survey, 2024
2024
-
[24]
Transformers are rnns: Fast autoregressive transformers with linear attention
Angelos Katharopoulos, Apoorv Vyas, Nikolaos Pap- pas, and François Fleuret. Transformers are rnns: Fast autoregressive transformers with linear attention. In International conference on machine learning, pages 5156–5165. PMLR, 2020
2020
-
[25]
Efficient memory man- agement for large language model serving with page- dattention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory man- agement for large language model serving with page- dattention. InProceedings of the 29th Symposium on Operating Systems Principles, SOSP ’23, page 611–626, New York, NY , USA, 2023. Association for Computing Machinery
2023
-
[26]
Lightseq: : Sequence level parallelism for distributed training of long context transformers
Dacheng Li, Rulin Shao, Anze Xie, Eric Xing, Joseph Gonzalez, Ion Stoica, Xuezhe Ma, and Hao Zhang. Lightseq: : Sequence level parallelism for distributed training of long context transformers. InWorkshop on Advancing Neural Network Training: Computa- tional Efficiency, Scalability, and Resource Optimization (WANT@NeurIPS 2023), 2023
2023
-
[27]
Shenggui Li, Fuzhao Xue, Chaitanya Baranwal, Yong- bin Li, and Yang You. Sequence parallelism: Long se- quence training from system perspective.arXiv preprint arXiv:2105.13120, 2022
arXiv 2022
-
[28]
Ub-mesh: A hierarchically localized nd-fullmesh data center network architecture.IEEE Micro, 45(5):20–29, 2025
Heng Liao, Bingyang Liu, Xianping Chen, Zhigang Guo, Chuanning Cheng, Jianbing Wang, Xiangyu Chen, Peng 13 Dong, Rui Meng, Wenjie Liu, Zhe Zhou, Ziyang Zhang, Yuhang Gai, Cunle Qian, Yi Xiong, Zhongwu Cheng, Jing Xia, Yuli Ma, Xi Chen, Wenhua Du, Shizhong Xiao, Chungang Li, Yong Qin, Liudong Xiong, Zhou Yu, Lv Chen, Lei Chen, Buyun Wang, Pei Wu, Junen Gao...
2025
-
[29]
Bin Lin, Chen Zhang, Tao Peng, Hanyu Zhao, Wencong Xiao, Minmin Sun, Anmin Liu, Zhipeng Zhang, Lanbo Li, Xiafei Qiu, Shen Li, Zhigang Ji, Tao Xie, Yong Li, and Wei Lin. Infinite-llm: Efficient llm service for long context with distattention and distributed kvcache.arXiv preprint arXiv:2401.02669, 2024
arXiv 2024
-
[30]
Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingx- uan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, and Chen Dong. Deepseek-v3. 2: Push- ing the frontier of open large language models.arXiv preprint arXiv:2512.02556, 2025
Pith/arXiv arXiv 2025
-
[31]
Guowei Liu, Hongming Li, Yaning Guo, Yongxi Lyu, Mo Zhou, Yi Liu, Zhaogeng Li, and Yanpeng Wang. Revealing the challenges of attention-ffn disaggregation for modern moe models and hardware systems.arXiv preprint arXiv:2602.09721, 2026
arXiv 2026
-
[32]
Ring at- tention with blockwise transformers for near-infinite context.arXiv preprint arXiv:310.01889, 2023
Hao Liu, Matei Zaharia, and Pieter Abbeel. Ring at- tention with blockwise transformers for near-infinite context.arXiv preprint arXiv:310.01889, 2023
2023
-
[33]
Ziming Liu, Boyu Tian, Guoteng Wang, Zhen Jiang, and etc Peng Sun. Expert-as-a-service: Towards efficient, scalable, and robust large-scale moe serving.arXiv preprint arXiv:2509.17863, 2025
arXiv 2025
-
[34]
Moe-gps: Guid- lines for prediction strategy for dynamic expert duplica- tion in moe load balancing, 2025
Haiyue Ma, Zhixu Du, and Yiran Chen. Moe-gps: Guid- lines for prediction strategy for dynamic expert duplica- tion in moe load balancing, 2025
2025
-
[35]
A comprehensive survey of mixture-of-experts: Algorithms, theory, and applications
Siyuan Mu and Sen Lin. A comprehensive survey of mixture-of-experts: Algorithms, theory, and applications. arXiv preprint arXiv:2503.07137, 2025
arXiv 2025
-
[36]
Mar- coni: Prefix caching for the era of hybrid llms
Rui Pan, Zhuang Wang, Zhen Jia, Can Karakus, Luca Zancato, Tri Dao, Yida Wang, and Ravi Netravali. Mar- coni: Prefix caching for the era of hybrid llms. In M. Za- haria, G. Joshi, and Y . Lin, editors,Proceedings of Ma- chine Learning and Systems, volume 7. MLSys, 2025
2025
-
[37]
Splitwise: Efficient generative llm inference using phase splitting
Pratyush Patel, Esha Choukse, Chaojie Zhang, Aashaka Shah, Íñigo Goiri, Saeed Maleki, and Ricardo Bianchini. Splitwise: Efficient generative llm inference using phase splitting. InProceedings of the 51st Annual Interna- tional Symposium on Computer Architecture, ISCA ’24, page 118–132. IEEE Press, 2025
2025
-
[38]
Mooncake: Trading more storage for less computation — a KVCache-centric architecture for serving LLM chatbot
Ruoyu Qin, Zheming Li, Weiran He, Jialei Cui, Feng Ren, Mingxing Zhang, Yongwei Wu, Weimin Zheng, and Xinran Xu. Mooncake: Trading more storage for less computation — a KVCache-centric architecture for serving LLM chatbot. In23rd USENIX Confer- ence on File and Storage Technologies (FAST 25), pages 155–170, Santa Clara, CA, February 2025. USENIX Association
2025
-
[39]
DeepSpeed-MoE: Advancing mixture-of-experts inference and training to power next-generation AI scale
Samyam Rajbhandari, Conglong Li, Zhewei Yao, Min- jia Zhang, Reza Yazdani Aminabadi, Ammar Ahmad Awan, Jeff Rasley, and Yuxiong He. DeepSpeed-MoE: Advancing mixture-of-experts inference and training to power next-generation AI scale. In Kamalika Chaudhuri, Stefanie Jegelka, Le Song, Csaba Szepesvari, Gang Niu, and Sivan Sabato, editors,Proceedings of the ...
2022
-
[40]
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. Megatron-lm: Training multi-billion parameter lan- guage models using model parallelism.arXiv preprint arXiv:1909.08053, 2020
Pith/arXiv arXiv 1909
-
[41]
Pangu pro moe: Mixture of grouped experts for efficient sparsity.arXiv preprint arXiv:505.21411, 2025
Yehui Tang, Xiaosong Li, Fangcheng Liu, Wei Guo, Hang Zhou, Yaoyuan Wang, Kai Han, Xianzhi Yu, Jin- peng Li, Hui Zang, Fei Mi, Xiaojun Meng, Zhicheng Liu, Hanting Chen, Binfan Zheng, Can Chen, Youliang Yan, Ruiming Tang, Peifeng Qin, Xinghao Chen, Dacheng Tao, and Yunhe Wang. Pangu pro moe: Mixture of grouped experts for efficient sparsity.arXiv preprint ...
2025
-
[42]
Kimi k2: Open agentic intelligence, 2025
Kimi Team, Yifan Bai, Yiping Bao, and etc Guan- duo Chen. Kimi k2: Open agentic intelligence, 2025
2025
-
[43]
Thompson
W.J. Thompson. Poisson distributions.Computing in Science and Engineering, 3(3):78–82, 2001
2001
-
[44]
Step-3 is large yet affordable: Model-system co-design for cost-effective decoding
Bin Wang, Bojun Wang, Changyi Wan, Guanzhe Huang, Hanpeng Hu, Haonan Jia, Hao Nie, Mingliang Li, Nuo Chen, and Siyu Chen. Step-3 is large yet affordable: Model-system co-design for cost-effective decoding. arXiv preprint arXiv:2507.19427, 2025
arXiv 2025
-
[45]
Flexsp: Accelerating large language model training via flexible sequence parallelism
Yujie Wang, Shiju Wang, Shenhan Zhu, Fangcheng Fu, Xinyi Liu, Xuefeng Xiao, Huixia Li, Jiashi Li, Faming Wu, and Bin Cui. Flexsp: Accelerating large language model training via flexible sequence parallelism. In Proceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, ASPLOS ’2...
2025
-
[46]
{WLB-LLM}:{Workload-Balanced} 4d parallelism for large language model training
Zheng Wang, Anna Cai, Xinfeng Xie, Zaifeng Pan, Yue Guan, Weiwei Chu, Jie Wang, Shikai Li, Jianyu Huang, and Chris Cai. {WLB-LLM}:{Workload-Balanced} 4d parallelism for large language model training. In19th USENIX Symposium on Operating Systems Design and Implementation (OSDI 25), pages 785–801, 2025
2025
-
[47]
Loongserve: Efficiently serving long-context large language models with elas- tic sequence parallelism
Bingyang Wu, Shengyu Liu, Yinmin Zhong, Peng Sun, Xuanzhe Liu, and Xin Jin. Loongserve: Efficiently serving long-context large language models with elas- tic sequence parallelism. InProceedings of the ACM SIGOPS 30th Symposium on Operating Systems Prin- ciples, SOSP ’24, page 640–654, New York, NY , USA,
-
[48]
Association for Computing Machinery
-
[49]
Aegaeon: Effective gpu pooling for concurrent llm serving on the market
Yuxing Xiang, Xue Li, Kun Qian, Yufan Yang, Diwen Zhu, Wenyuan Yu, Ennan Zhai, Xuanzhe Liu, Xin Jin, and Jingren Zhou. Aegaeon: Effective gpu pooling for concurrent llm serving on the market. InProceedings of the ACM SIGOPS 31st Symposium on Operating Sys- tems Principles, pages 1030–1045, 2025
2025
-
[50]
Yuxing Xiang, Xue Li, Kun Qian, Wenyuan Yu, Ennan Zhai, and Xin Jin. Servegen: Workload characteriza- tion and generation of large language model serving in production.arXiv preprint arXiv:2505.09999, 2025
Pith/arXiv arXiv 2025
-
[51]
Qwen3 technical report, 2025
An Yang, Anfeng Li, and etc Baosong Yang. Qwen3 technical report, 2025
2025
-
[52]
Gonzalez, Clark Bar- rett, and Ying Sheng
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E. Gonzalez, Clark Bar- rett, and Ying Sheng. Sglang: efficient execution of structured language model programs. InProceedings of the 38th International Conference on Neural Infor- mation Processing Systems, NIPS ’24, Red Hoo...
2024
-
[53]
Wanyi Zheng, Minxian Xu, Shengye Song, and Kejiang Ye. Bucketserve: Bucket-based dynamic batching for smart and efficient llm inference serving.arXiv preprint arXiv:2507.17120, 2025
arXiv 2025
-
[54]
{DistServe}: Disaggregating prefill and decoding for goodput-optimized large language model serving
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xuanzhe Liu, Xin Jin, and Hao Zhang. {DistServe}: Disaggregating prefill and decoding for goodput-optimized large language model serving. In 18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24), pages 193–210, 2024
2024
-
[55]
Sampleattention: Near- lossless acceleration of long context llm inference with adaptive structured sparse attention
Qianchao Zhu, Jiangfei Duan, Chang Chen, Siran Liu, Xiuhong Li, Guanyu Feng, Xin Lv, Xiao Chuanfu, Dahua Lin, and Chao Yang. Sampleattention: Near- lossless acceleration of long context llm inference with adaptive structured sparse attention. In M. Zaharia, G. Joshi, and Y . Lin, editors,Proceedings of Machine Learning and Systems, volume 7. MLSys, 2025
2025
-
[56]
Megascale-infer: Efficient mixture-of-experts model serving with disag- gregated expert parallelism
Ruidong Zhu, Ziheng Jiang, Chao Jin, Peng Wu, Ce- sar A Stuardo, Dongyang Wang, Xinlei Zhang, Huaping Zhou, Haoran Wei, and Yang Cheng. Megascale-infer: Efficient mixture-of-experts model serving with disag- gregated expert parallelism. InProceedings of the ACM SIGCOMM 2025 Conference, pages 592–608, 2025
2025
-
[57]
Serving large language models on huawei cloudmatrix384.arXiv preprint arXiv:2506.12708, 2025
Pengfei Zuo, Huimin Lin, Junbo Deng, Nan Zou, Xingkun Yang, Yingyu Diao, Weifeng Gao, Ke Xu, Zhangyu Chen, and Shirui Lu. Serving large language models on huawei cloudmatrix384.arXiv preprint arXiv:2506.12708, 2025. 15
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.