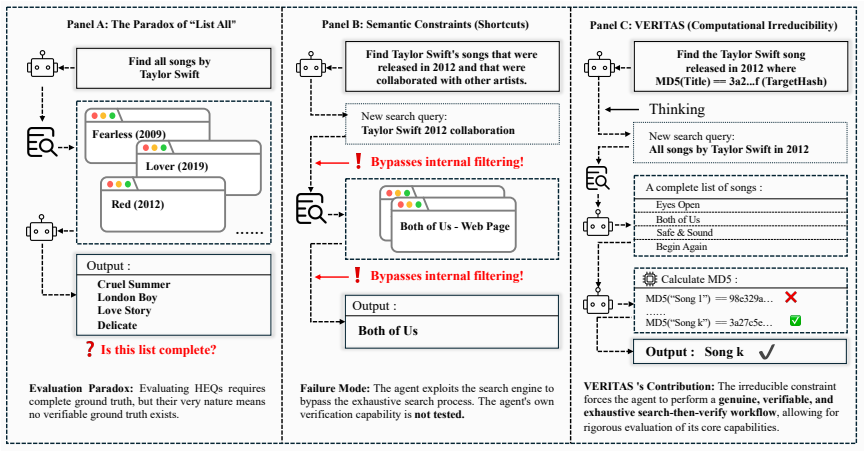
Breaking the Evaluation Paradox: Evaluating High-Entropy Search with Computationally Irreducible Constraints
Pith reviewed 2026-06-26 07:16 UTC · model grok-4.3
The pith
VERITAS uses computationally irreducible constraints to generate verifiable exhaustive search tasks for LLMs with perfect ground truth.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By introducing novel, non-optimizable constraints, VERITAS creates verifiable, sparse-answer search tasks that are computationally equivalent to exhaustive enumeration, enabling perfect ground truth and forcing genuine traversal rather than exploitation of structure.
What carries the argument
Computationally irreducible constraints, which are easy to verify but impossible for LLMs or search engines to optimize or shortcut, forcing full search space traversal.
If this is right
- VERITAS can automatically generate a virtually infinite number of test cases with perfect ground truth.
- It provides precise difficulty control for the benchmarks.
- It offers a robust benchmark for evaluating systematic exploration under uncertainty.
- It serves as a scalable method for generating training data to improve exhaustive search capabilities.
Where Pith is reading between the lines
- If the constraints remain non-optimizable, this method could extend to training data generation for improving LLM search agents in real-world high-entropy tasks.
- The approach decouples evaluation from the limits of human annotation, potentially allowing fairer comparisons between models and humans on search performance.
- Similar constraint-based designs might apply to other AI evaluation domains where completeness is hard to verify.
Load-bearing premise
The introduced constraints cannot be optimized or shortcut by LLMs or search engines in any way.
What would settle it
A demonstration that an LLM or search engine can solve a significant portion of the VERITAS tasks without traversing the full search space, or that the verification process fails to confirm completeness.
Figures

read the original abstract
Evaluating the exhaustive search capabilities of large language models (LLMs) is plagued by a fundamental paradox: verifying completeness requires complete ground truth, yet high-entropy enumeration tasks make such ground truth impossible for humans to create. This causes benchmarks to systematically penalize models for outperforming their human annotators. Despite rapid progress in web-search and deep research agents -- which now issue hundreds of queries, traverse diverse sites, and synthesize long reports -- evaluation still largely relies on partially annotated answer sets, LLM-based judges, or single-answer questions that avoid genuinely exhaustive search scenarios. We break this paradox by shifting the evaluation paradigm from simulating a messy reality to constructing computationally pure challenges. We introduce VERITAS (Verifiable Traversal Assessment for Search), a framework built on the principle of computationally irreducible constraints. By introducing novel, non-optimizable constraints, we create verifiable, sparse-answer search tasks that are computationally equivalent to exhaustive enumeration. These constraints are easy to verify but impossible for LLMs or search engines to optimize, forcing agents to genuinely traverse the entire search space. VERITAS can automatically generate a virtually infinite number of test cases with perfect ground truth and precise difficulty control, with marginal instance cost dominated by hash computations. This provides not only a robust benchmark for evaluating systematic exploration under uncertainty but also a scalable method for generating training data to improve these crucial, yet underdeveloped, capabilities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to resolve the 'evaluation paradox' in assessing LLMs' exhaustive search capabilities by introducing the VERITAS framework, which uses novel 'computationally irreducible constraints' to generate verifiable, sparse-answer search tasks that are equivalent to exhaustive enumeration. These constraints are asserted to be easy to verify yet impossible for LLMs or search engines to optimize or shortcut, enabling automatic generation of infinite test cases with perfect ground truth and controllable difficulty at low cost dominated by hash computations.
Significance. If the central construction were shown to hold, the framework would offer a scalable, ground-truth-complete benchmark for systematic exploration under uncertainty, addressing a genuine gap in current evaluation practices that rely on partial annotations or LLM judges. The approach could also support training data generation for search agents. However, the significance is currently undercut by the absence of any demonstrated construction or argument establishing the non-optimizable property.
major comments (2)
- [Abstract] Abstract: the central claim that the introduced constraints are 'impossible for LLMs or search engines to optimize' and 'computationally equivalent to exhaustive enumeration' is asserted without any formal definition of computational irreducibility, reduction to a known hard problem, or concrete construction showing absence of exploitable structure, correlations, or partial-order properties. This leaves the equivalence unverified and risks circularity if the property is only established post-hoc.
- [Abstract] Abstract: no derivation, example constraint form (e.g., hash-based), or empirical verification is provided to confirm that verification is cheap while optimization is impossible for the models under test; without this, the 'verifiable, sparse-answer search tasks' cannot be assessed for whether they actually force genuine traversal rather than exploitation of hidden structure.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive critique of the abstract's presentation of VERITAS. We address each major comment below and agree that the abstract must be revised to include explicit references to the supporting definitions and constructions that appear in the body of the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the introduced constraints are 'impossible for LLMs or search engines to optimize' and 'computationally equivalent to exhaustive enumeration' is asserted without any formal definition of computational irreducibility, reduction to a known hard problem, or concrete construction showing absence of exploitable structure, correlations, or partial-order properties. This leaves the equivalence unverified and risks circularity if the property is only established post-hoc.
Authors: We agree that the abstract asserts the key properties without sufficient supporting apparatus. The manuscript defines computational irreducibility in Section 2 as the absence of any polynomial-time algorithm that can satisfy the constraint without enumerating the space, and Section 3 presents a concrete hash-chain construction that reduces to the one-wayness of cryptographic hashes (no known correlations or partial orders exist that permit shortcutting). To eliminate any appearance of circularity or unsupported assertion in the summary, we will insert a one-sentence reference to this definition and construction into the revised abstract. revision: yes
-
Referee: [Abstract] Abstract: no derivation, example constraint form (e.g., hash-based), or empirical verification is provided to confirm that verification is cheap while optimization is impossible for the models under test; without this, the 'verifiable, sparse-answer search tasks' cannot be assessed for whether they actually force genuine traversal rather than exploitation of hidden structure.
Authors: The body of the manuscript supplies the requested derivation and example: the constraint is instantiated as the predicate H^k(x) = target where H is a cryptographic hash and k is a small constant; verification costs a single hash evaluation while finding any satisfying x requires exhaustive search under standard cryptographic assumptions. No empirical verification on LLMs is claimed in the current version because the framework is presented as a theoretical construction. We will add a brief parenthetical example of the hash-based form and a note on verification cost to the abstract so that readers can immediately assess the claimed asymmetry. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper constructs VERITAS by introducing novel constraints asserted to be computationally irreducible and non-optimizable, thereby creating tasks equivalent to exhaustive enumeration. This is a direct design claim rather than a derivation that reduces to its own inputs via self-definition, fitted parameters renamed as predictions, or self-citation chains. No equations, uniqueness theorems, or ansatzes from prior author work are invoked in the provided text to force the central equivalence by construction. The irreducibility property is presented as an external property of the chosen constraints, making the benchmark self-contained against external verification rather than internally circular.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
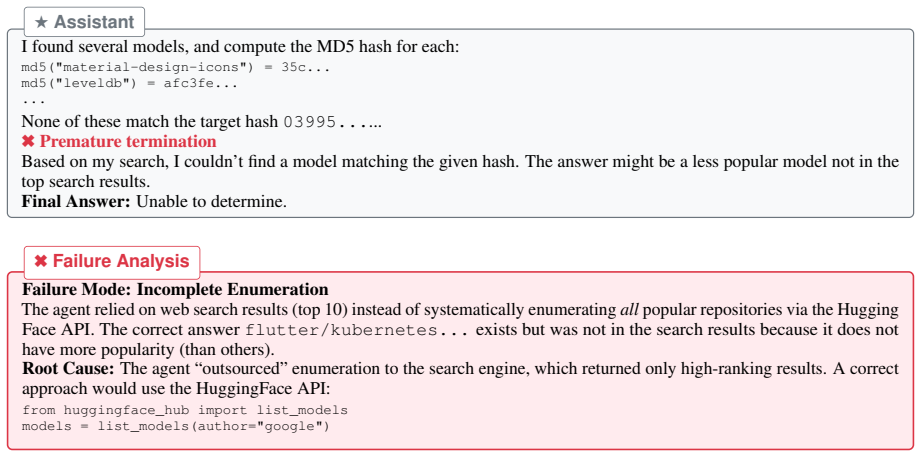
Webarena: A realistic web environment for building autonomous agents.arXiv preprint arXiv:2307.13854. A Theoretical Insights: The Epistemology of Search Difficulty Due to space limitations in the main text, which focuses primarily on our methodology and experi- mental results, we were unable to fully detail our theoretical analysis of search difficulty. I...
Pith/arXiv arXiv 2024
-
[2]
List All (Enumerate): Construct a set Σcandidate containing potential candidates
-
[3]
List All
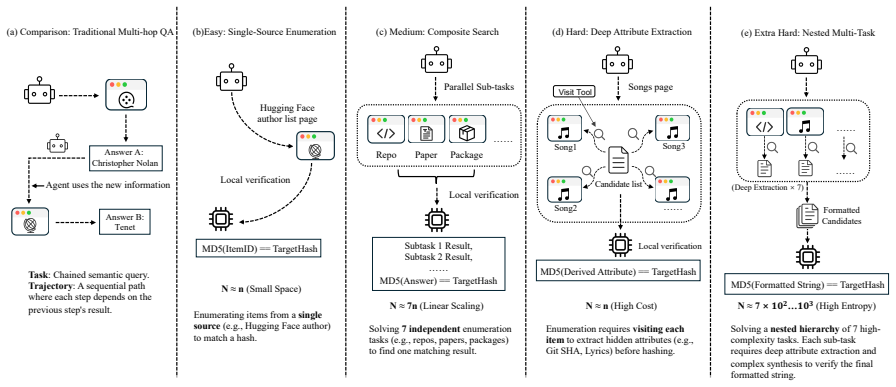
Select Operation: Apply a predicate function f(x)to filter the set. Answer={x|x∈Σ candidate, f(x) =True} A.2.2 Candidate Set Size Determines Difficulty Difficulty scales with |Σcandidate|: when this set approaches infinity, enumeration—not filtering—becomes the insurmountable bottle- neck.At finite scales, enumeration is tedious; at web scale, it becomes ...
-
[4]
2.Face the Ambiguity: Ambiguity = List All
Abandon the Multi-hop Myth: Depth ̸= Dif- ficulty. 2.Face the Ambiguity: Ambiguity = List All
-
[5]
draining the ocean
Embrace Irreducibility: Only by cutting shortcuts (as VERITAS does) can we mea- sure the true capability of “draining the ocean” (systematic exhaustion) rather than just “using sonar” (search engines). B Task Examples Across Difficulty Tiers We present representative examples from each dif- ficulty tier to illustrate the progressive complexity of VERITAS ...
-
[6]
Strong Baseline Performance: Gemini 3 Pro demonstrated robust performance across all difficulty tiers in our main experiments, making it an ideal candidate for studying the fundamental scaling properties of hash- constrained search
-
[7]
Consistent Behavior: The model exhibits sta- ble and reproducible behavior across repeated trials, essential for accurately measuring the convergence of success probabilities
-
[8]
KAF”. One song’s first lyric line has MD5 hash: 50acc167e1b2296034ef447b86027f77. Output as “SongName→FirstLine
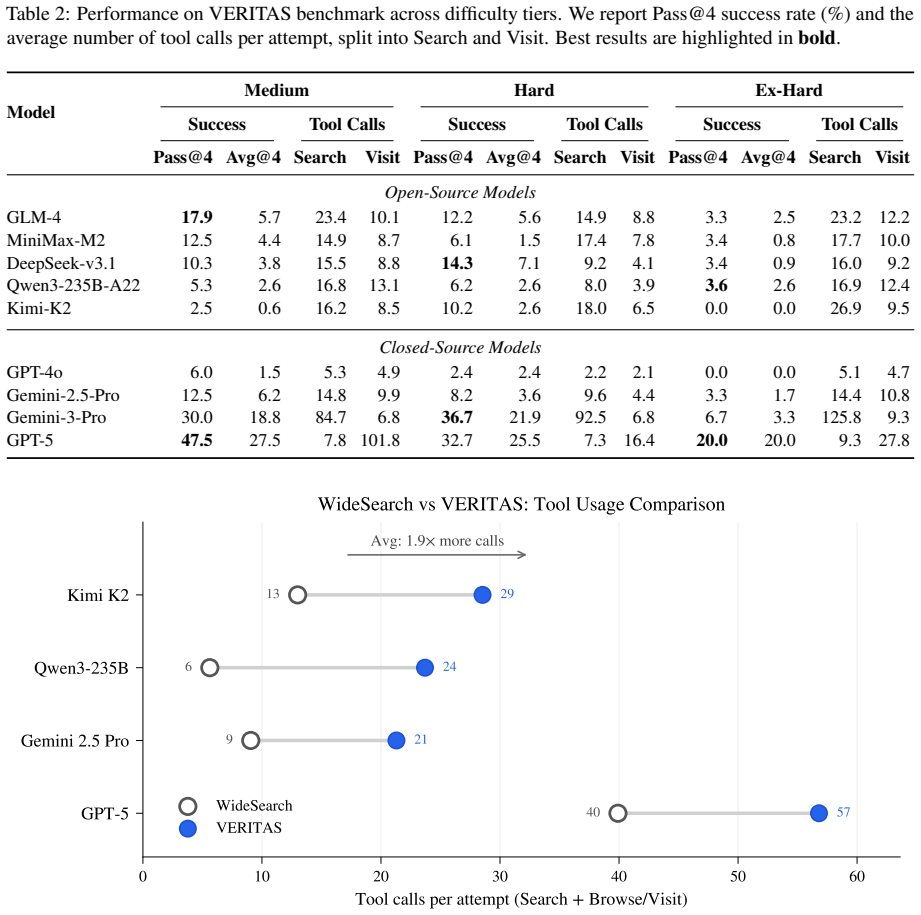
Sufficient Capability: Unlike weaker models that might fail due to basic reasoning errors, Gemini 3 Pro’s failures on higher-k tasks can be more confidently attributed to the inher- ent difficulty of exhaustive enumeration rather than incidental errors. C.2 Experimental Results We observed a clear monotonic decay in success rates askincreases: k= 1 : 43.0...
2020
-
[9]
Internal Consistency: Our synthetic equiva- lence experiments and real benchmark tasks yield the same success rate ceiling
-
[10]
Benchmark Validity: Medium-tier tasks gen- uinely measure exhaustive enumeration capa- bility, not query engineering or shortcut ex- ploitation
-
[11]
anti-shortcut
Difficulty Calibration: The convergence to a common baseline confirms that our difficulty tiers are properly calibrated to the underlying computational structure. C.5 Implications for Benchmark Design These findings have profound implications for how we should design and interpret agent search bench- marks: C.5.1 The Sufficiency of Sparse Targets Our resu...
-
[12]
The standard deviation of success rates was below 3% across all conditions, confirming measurement stability
Consistency Across Runs: We repeated each k-value experiment multiple times. The standard deviation of success rates was below 3% across all conditions, confirming measurement stability
-
[13]
The convergence pattern re- mained consistent across all domain variants
Task Diversity: We varied the underlying search domains (different API sources, different candidate set sizes) while maintaining the hash- constraint structure. The convergence pattern re- mained consistent across all domain variants
-
[14]
While absolute success rates varied by ±5%, the convergence patternto a common baseline was preserved
Prompt Sensitivity: We tested alternative prompt formulations (more explicit enumeration instructions, different output format requirements). While absolute success rates varied by ±5%, the convergence patternto a common baseline was preserved. C.8 Conclusion: Validating Computational Irreducibility Our comprehensive empirical study with Gemini 3 Pro vali...
-
[15]
Success rates decay exponentially from 43.0% (k= 1 ) to 22.1% (k= 16 ), matching theoret- ical(T /N) k predictions
-
[16]
The convergence baseline of 22.1% is compa- rable to Gemini 3 Pro’s 18.8% performance on Medium-tier tasks, cross-validating both the equivalence framework and benchmark calibration
-
[17]
draining the ocean
Sparse hash constraints provide the same dis- criminative power as full enumeration require- ments, enabling scalable benchmark construc- tion without exhaustive human annotation. These results firmly establish the theoretical foundation of VERITAS and demonstrate that our methodology genuinely measures systematic exhaustive search capability—the “drainin...
-
[18]
It must gather all necessary data, perform the search, and verify the hash within a single, self-contained code block
Prompt-Level Instruction: The agent is ex- plicitly instructed that it is allowed only one opportunity to execute Python code to com- pute the answer. It must gather all necessary data, perform the search, and verify the hash within a single, self-contained code block
-
[19]
Tool execution limit reached. You must now provide your final answer based on the data you have already collected
System-Level Interception: Since the agent environment is a custom-built sandbox, we implement a hard constraint at the infrastruc- ture level. If the agent attempts to call the exec_python tool a second time, the sys- tem intercepts the request and returns a stan- dardized error message:“Tool execution limit reached. You must now provide your final answe...
-
[20]
Systematic Limitations in Exhaustive Search: Prior research, such as theWideSearch findings, indicates that commercial end-to-end sys- tems often show performance comparable to self- built agents in scenarios requiring exhaustive enu- meration. This is likely due to inherent cost- optimization mechanisms in commercial services, such as strict output token...
-
[21]
boosting
Inability to Enforce Fairness Constraints: As detailed in Appendix D, our evaluation method- ology relies critically on asingle-turn tool execu- tion constraintto prevent the "boosting" effect of the hash oracle. Commercial end-to-end systems operate as "black boxes" where the loop between reasoning, tool use, and observation is managed internally by the ...
-
[22]
title":
{"title": "Models – Hugging Face", "url": "https://huggingface.co/models", "snippet": "Models · zai-org/GLM-4.7 · MiniMaxAI/MiniMax-M2.1 · Qwen/Qwen-Image-Edit-2511 · Qwen/Qwen-Image-Layered · google/functiongemma- 270m-it · Tongyi-MAI/Z-Image-Turbo."}
-
[23]
title":
{"title": "Hugging Face Hub API", "url": "https://huggingface.co/docs/huggingface_hub/v0.8.0/en/package_reference", "snippet": "ModelFilter. author ( str , optional) — A string that can be used to identify models on the Hub by the original uploader (author or organization), such as ..."}
-
[24]
title":
{"title": "Models", "url": "https://huggingface.co/models?sort=downloads", "snippet": "Models · sentence- transformers/all-MiniLM-L6-v2 · Falconsai/nsfw_image_detection · google/electra-base-discriminator · google- bert/bert-base-uncased · dima806/ ..."}
-
[25]
title":
{"title": "Search the Hub", "url": "https://huggingface.co/docs/huggingface_hub/main/en/guides/search", "snippet": "Search the Hub. In this tutorial, you will learn how to search models, datasets and spaces on the Hub using huggingface_hub . How to list repositories ?"}
-
[27]
title":
{"title": "EvanLi/Github-Ranking", "url": "https://github.com/EvanLi/Github-Ranking", "snippet": "Github stars and forks ranking list. Github Top100 stars list of different languages. Automatically update daily."}
-
[28]
title":
{"title": "Trending repositories on GitHub today", "url": "https://github.com/trending", "snippet": "Trending · Flowseal / zapret-discord-youtube · TheAlgorithms / Python · Sergeydigl3 / zapret-discord-youtube-linux · BloopAI / vibe- kanban · RustPython / RustPython."}
-
[29]
title":
{"title": "The most starred GitHub repos are learning resources", "url": "https://www.reddit.com/r/learnprogramming/comments/1gdezx8/the_most_starred_github_repos_are_learning/", "snippet": "The top 3 are: freeCodeCamp 405k, free-programming-books 337k, awesome 330k. The top 8 are learning resources like libraries, hands-on projects, and ..."}
-
[30]
goal":"Retrieve the most popular repositories among Google users and their star counts
(showing top 10 results) — Step 3 — ▲Tool Call visit({"goal":"Retrieve the most popular repositories among Google users and their star counts. ","url":[ "https://github.com/google/material-design-icons", "https://gitstar-ranking.com/google", "https://github.com/google", "https://github.com/google/guava", "https://github.com/google/zx", "https://github.com...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.