Causal Reward World Models: Zero-shot Reward Design for Automated Skill Generation
Pith reviewed 2026-06-26 08:16 UTC · model grok-4.3
The pith
Causal relationships learned from offline robot data let LLMs generate executable rewards for new tasks without any feedback or refinement.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
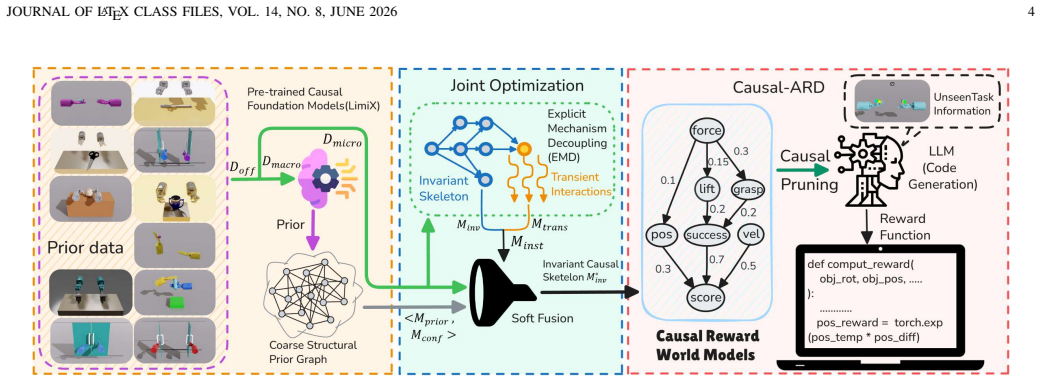
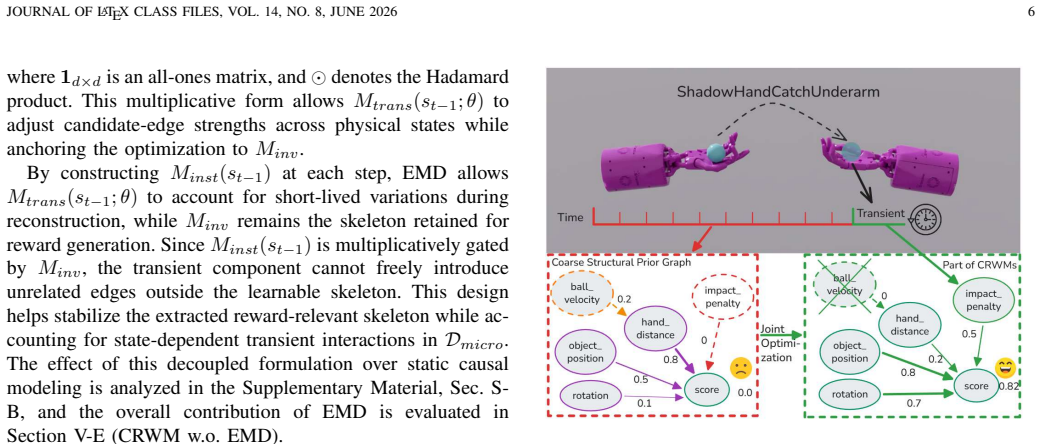
CRWM pre-trains on multi-task offline trajectories to build a coarse-to-fine causal skeleton via Explicit Mechanism Decoupling and Confidence-Aware Soft Fusion; at inference time, LLMs use this skeleton as a task-irrelevant prior to constrain reward synthesis, producing executable functions that require no further environmental feedback.
What carries the argument
The Causal Reward World Model (CRWM), a pre-trained structure that encodes causal topological relationships between candidate reward terms and task-relevant physical variables.
If this is right
- Reward design latency drops because no iterative feedback loop is needed after the initial offline pre-training.
- The same causal skeleton supports reward generation across multiple unseen tasks and different robot platforms.
- LLM-generated rewards become more interpretable because each component is constrained by an explicit causal graph rather than semantic plausibility alone.
- Skill acquisition pipelines can separate the one-time cost of building the world model from the per-task cost of reward creation.
Where Pith is reading between the lines
- If the causal prior generalizes across embodiments, the same pre-trained model could support reward design for entirely new hardware families without retraining.
- The white-box causal constraint may reduce the rate at which LLMs propose physically impossible reward terms compared with purely language-driven methods.
- Extending the offline pre-training corpus to include more diverse dynamics could further widen the set of tasks that require zero feedback.
Load-bearing premise
Causal links learned once from offline multi-task data stay valid and sufficient for generating rewards on entirely new tasks without any task-specific adjustment or feedback.
What would settle it
Generate CRWM rewards for a held-out continuous-control task and robot embodiment, then measure whether the resulting policy reaches target performance in a single training run with no reward editing or environmental interaction during reward creation.
Figures




read the original abstract
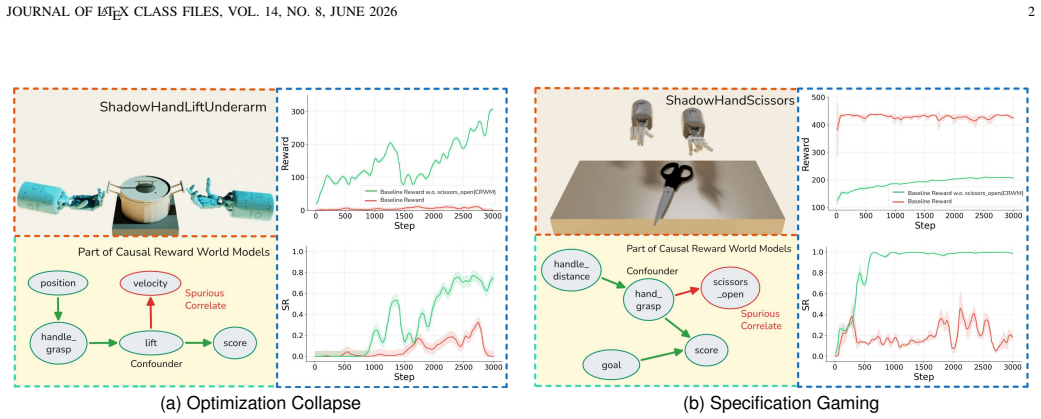
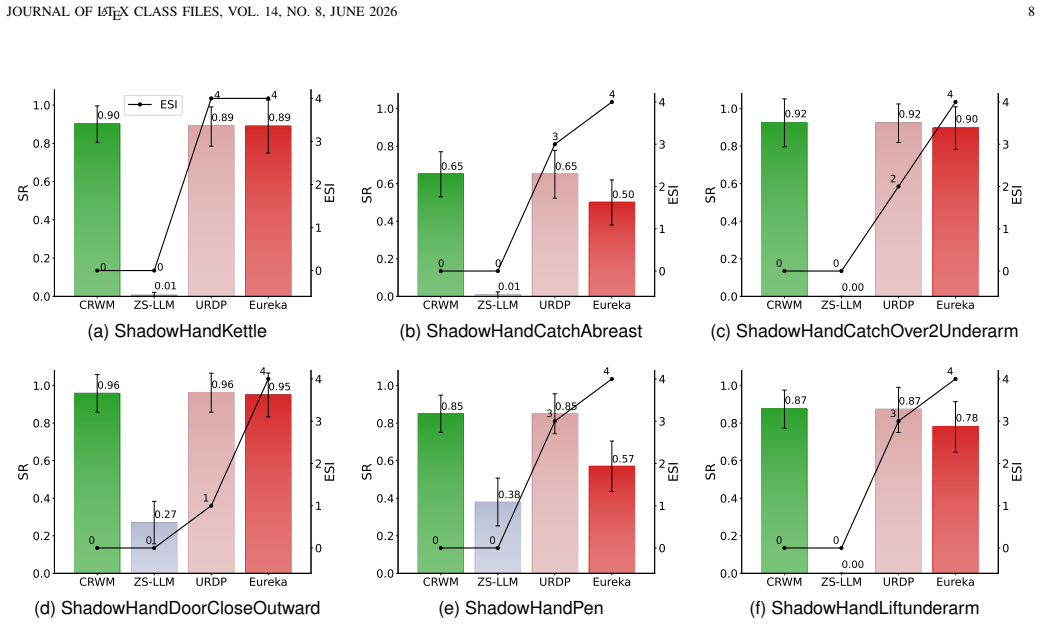
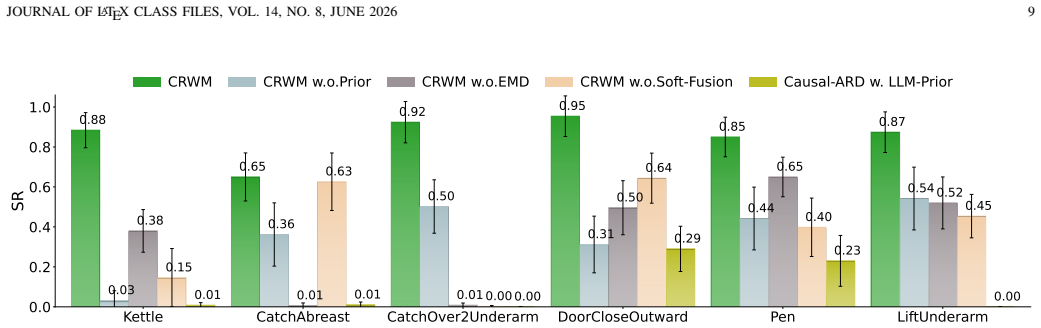
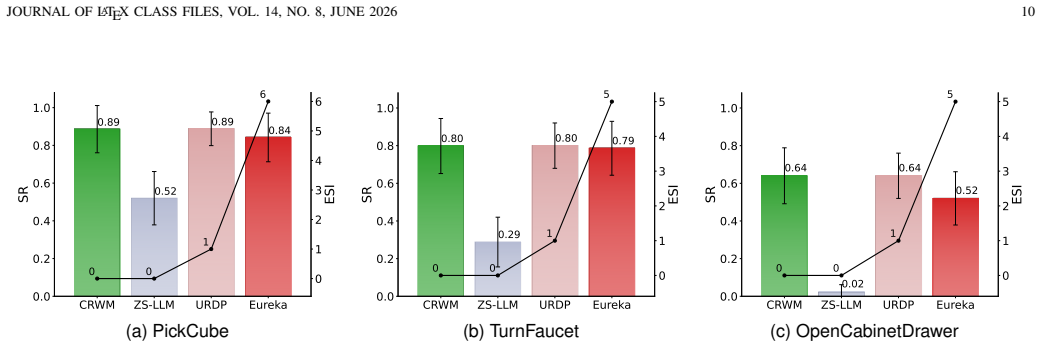
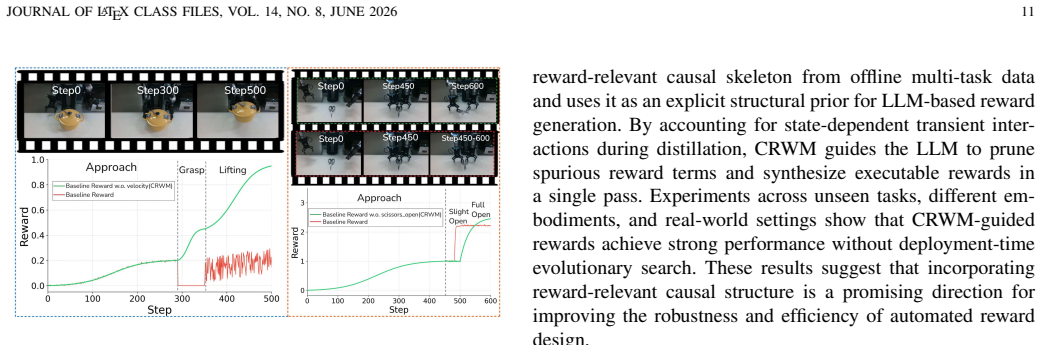
Automated Reward Design (ARD) aims to replace manual reward engineering in reinforcement learning with language-driven reward function synthesis. However, existing approaches based on large language models (LLMs) remain inherently correlation-driven, relying on iterative environmental feedback to refine reward hypotheses for each specific task. This paradigm not only results in inefficient reasoning but also makes LLMs susceptible to semantically plausible yet causally spurious reward components, leading to ineffective optimization. To address these limitations, we propose the Causal Reward World Model (CRWM), which explicitly models the causal topological relationships between candidate reward components and task-targeted physical variables through offline pre-training on multi-task interaction data. Based on a coarse-to-fine pre-training strategy, we introduce a joint optimization module that integrates Explicit Mechanism Decoupling with Confidence-Aware Soft Fusion to refine coarse structural priors using micro-level trajectories, thereby constructing a robust and interpretable causal skeleton. During inference, LLMs leverage CRWM as a task-irrelevant causal prior to constrain the reward generation, enabling zero-shot reward function design. Our work opens up a new white-box paradigm for the ARD problem. Extensive experiments on complex continuous control benchmarks demonstrate that CRWM generates executable reward functions without feedback-driven reward refinement, significantly reducing the design latency for acquiring new robotic skills while matching or surpassing state-of-the-art performance, and further exhibits strong generalization capabilities across unseen tasks and diverse robotic embodiments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Causal Reward World Model (CRWM) to address limitations in automated reward design (ARD) for reinforcement learning. It pre-trains a causal model on offline multi-task interaction data using a coarse-to-fine strategy that combines Explicit Mechanism Decoupling with Confidence-Aware Soft Fusion, yielding a task-irrelevant causal skeleton. LLMs then use this skeleton as a prior to synthesize executable reward functions in a zero-shot manner, without iterative environmental feedback or reward refinement. Experiments on continuous control benchmarks are claimed to demonstrate performance matching or exceeding state-of-the-art methods, with strong generalization to unseen tasks and diverse robotic embodiments.
Significance. If the central claim holds—that the learned causal topological prior is both necessary and sufficient for zero-shot reward synthesis across new tasks and embodiments—this would constitute a meaningful advance in ARD by shifting from correlation-driven LLM reasoning to a white-box causal constraint. The reduction in design latency and the reported generalization would be practically significant for robotic skill acquisition if the invariance of the prior is rigorously established.
major comments (3)
- [Abstract, §3] Abstract and §3 (pre-training description): the zero-shot claim requires that the causal skeleton extracted via Explicit Mechanism Decoupling and Confidence-Aware Soft Fusion on multi-task trajectories remains invariant and complete for held-out tasks; no formal argument, coverage analysis, or counter-example test is supplied showing that the offline distribution necessarily includes the physical variable dependencies of unseen tasks or embodiments.
- [Experiments] Experiments section: the reported matching or surpassing of SOTA performance on continuous control benchmarks is presented without ablations that isolate the contribution of the causal prior versus the LLM alone, nor error analysis or failure cases on tasks that introduce new causal mechanisms absent from pre-training data.
- [§4] §4 (inference procedure): the claim that CRWM constrains LLM reward generation to avoid semantically plausible yet causally spurious components is not supported by a quantitative comparison of reward-component selection with versus without the causal skeleton on the same held-out tasks.
minor comments (2)
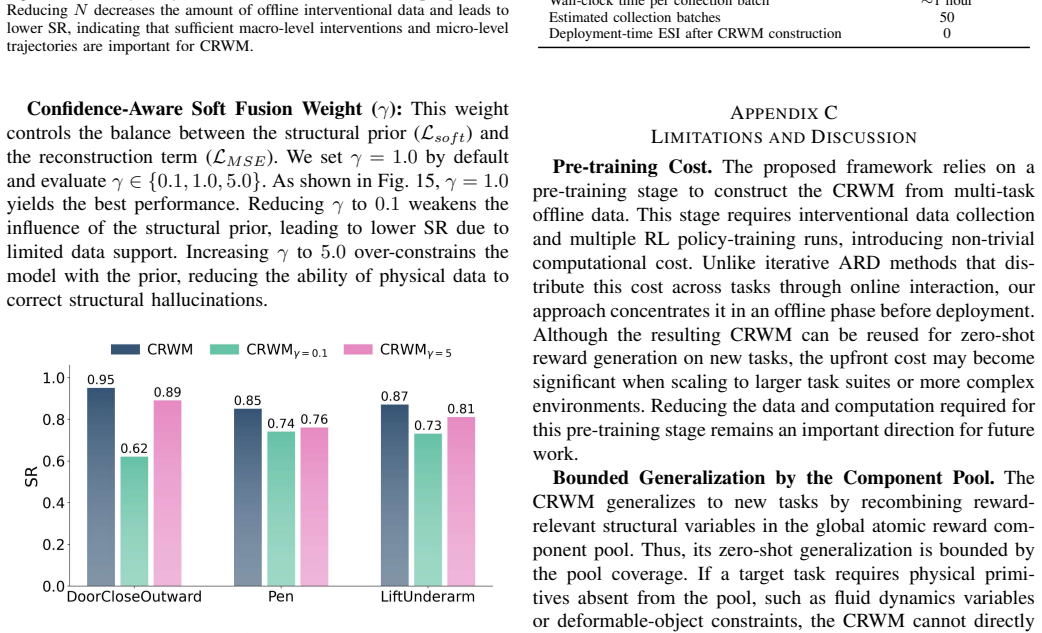
- [§3] Notation for the joint optimization module and the soft-fusion step is introduced without an accompanying equation or pseudocode block, making the coarse-to-fine procedure difficult to reproduce from the text alone.
- [Abstract, Experiments] The abstract states 'extensive experiments' but the manuscript would benefit from an explicit table listing the benchmark environments, number of tasks, and embodiment variations used for the generalization claims.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will incorporate revisions to strengthen the empirical support and discussion of assumptions in the manuscript.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (pre-training description): the zero-shot claim requires that the causal skeleton extracted via Explicit Mechanism Decoupling and Confidence-Aware Soft Fusion on multi-task trajectories remains invariant and complete for held-out tasks; no formal argument, coverage analysis, or counter-example test is supplied showing that the offline distribution necessarily includes the physical variable dependencies of unseen tasks or embodiments.
Authors: We acknowledge the absence of a formal mathematical argument or exhaustive coverage proof for invariance. Our claims rest on empirical generalization results across held-out tasks and embodiments. In revision we will add to §3 a dedicated discussion of the assumptions underlying the coarse-to-fine pre-training strategy, a coverage analysis comparing variable dependencies in the multi-task offline data versus test distributions, and explicit mention of potential counter-examples where the prior may be incomplete. revision: yes
-
Referee: [Experiments] Experiments section: the reported matching or surpassing of SOTA performance on continuous control benchmarks is presented without ablations that isolate the contribution of the causal prior versus the LLM alone, nor error analysis or failure cases on tasks that introduce new causal mechanisms absent from pre-training data.
Authors: We agree that isolating the causal prior's contribution and characterizing failure modes are necessary. The revised manuscript will include new ablation experiments comparing full CRWM against an LLM-only baseline (no causal skeleton) on the same benchmarks, plus an error-analysis subsection that reports performance drops and qualitative failure cases on tasks introducing causal mechanisms absent from pre-training. revision: yes
-
Referee: [§4] §4 (inference procedure): the claim that CRWM constrains LLM reward generation to avoid semantically plausible yet causally spurious components is not supported by a quantitative comparison of reward-component selection with versus without the causal skeleton on the same held-out tasks.
Authors: We accept this critique. We will extend §4 with a quantitative comparison on held-out tasks, reporting metrics such as the fraction of causally spurious components selected by the LLM with versus without the skeleton, and the alignment of selected components with the extracted causal dependencies. revision: yes
Circularity Check
No circularity; derivation self-contained against external benchmarks
full rationale
The abstract and described method pre-train a causal topological model on multi-task offline trajectories via coarse-to-fine optimization (Explicit Mechanism Decoupling + Confidence-Aware Soft Fusion), then apply the resulting skeleton as a task-irrelevant prior to constrain LLM reward synthesis on held-out tasks and embodiments. No equations, self-citations, or fitted-input-as-prediction steps are quoted that reduce the zero-shot claim to the pre-training inputs by construction. Generalization performance is reported on unseen tasks, satisfying the requirement for independent external validation rather than internal re-use of the same data.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Causal topological relationships between reward components and task-targeted physical variables can be reliably recovered from offline multi-task interaction data.
- domain assumption The learned causal skeleton remains valid and sufficient when used as a task-irrelevant prior for new, unseen tasks and embodiments.
invented entities (1)
-
Causal Reward World Model (CRWM)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Concrete problems in ai safety,
D. Amodei, C. Olah, J. Steinhardt, P. F. Christiano, J. Schulman, and D. Man´e, “Concrete problems in ai safety,”ArXiv, vol. abs/1606.06565, 2016
Pith/arXiv arXiv 2016
-
[2]
Language to rewards for robotic skill synthesis,
W. Yu, N. Gileadi, C. Fu, S. Kirmani, K.-H. Lee, M. G. Arenas, H.- T. L. Chiang, T. Erez, L. Hasenclever, J. Humplik, B. Ichter, T. Xiao, P. Xu, A. Zeng, T. Zhang, N. Heess, D. Sadigh, J. Tan, Y . Tassa, and F. Xia, “Language to rewards for robotic skill synthesis,” inProceedings of The 7th Conference on Robot Learning, vol. 229, 06–09 Nov 2023, pp. 374–404
2023
-
[3]
Eureka: Human-level reward design via coding large language models,
Y . J. Ma, W. Liang, G. Wang, D.-A. Huang, O. Bastani, D. Jayaraman, Y . Zhu, L. Fan, and A. Anandkumar, “Eureka: Human-level reward design via coding large language models,” inInternational Conference on Learning Representations, 2023
2023
-
[4]
Text2reward: Reward shaping with language models for reinforcement learning,
T. Xie, S. Zhao, C. H. Wu, Y . Liu, Q. Luo, V . Zhong, Y . Yang, and T. Yu, “Text2reward: Reward shaping with language models for reinforcement learning,” inInternational Conference on Learning Representations, 2023
2023
-
[5]
Survey on large language model-enhanced reinforce- ment learning: Concept, taxonomy, and methods,
Y . Cao, H. Zhao, Y . Cheng, T. Shu, Y . Chen, G. Liu, G. Liang, J. Zhao, J. Yan, and Y . Li, “Survey on large language model-enhanced reinforce- ment learning: Concept, taxonomy, and methods,”IEEE Transactions on Neural Networks and Learning Systems, vol. 36, no. 6, pp. 9737–9757, 2024
2024
-
[6]
Inner monologue: Embodied reasoning through planning with language mod- els,
W. Huang, F. Xia, T. Xiao, H. Chan, J. Liang, P. Florence, A. Zeng, J. Tompson, I. Mordatch, Y . Chebotar, P. Sermanet, T. Jackson, N. Brown, L. Luu, S. Levine, K. Hausman, and brian ichter, “Inner monologue: Embodied reasoning through planning with language mod- els,” in6th Annual Conference on Robot Learning, 2022
2022
-
[7]
Cipl: counterfactual interactive policy learning to eliminate popularity bias for online rec- ommendation,
Y . Zheng, J. Qin, P. Wei, Z. Chen, and L. Lin, “Cipl: counterfactual interactive policy learning to eliminate popularity bias for online rec- ommendation,”IEEE Transactions on Neural Networks and Learning Systems, vol. 35, no. 12, pp. 17 123–17 136, 2023
2023
-
[8]
Causal reasoning and large language models: Opening a new frontier for causality,
E. Kiciman, R. Ness, A. Sharma, and C. Tan, “Causal reasoning and large language models: Opening a new frontier for causality,” Transactions on Machine Learning Research, 2023
2023
-
[9]
Defining and characterizing reward gaming,
J. Skalse, N. Howe, D. Krasheninnikov, and D. Krueger, “Defining and characterizing reward gaming,”Advances in Neural Information Processing Systems, vol. 35, pp. 9460–9471, 2022
2022
-
[10]
The effects of reward misspeci- fication: Mapping and mitigating misaligned models,
A. Pan, K. Bhatia, and J. Steinhardt, “The effects of reward misspeci- fication: Mapping and mitigating misaligned models,” inInternational Conference on Learning Representations, 2022
2022
-
[11]
Can large language models infer causation from correlation?
Z. Jin, J. Liu, Z. LYU, S. Poff, M. Sachan, R. Mihalcea, M. T. Diab, and B. Sch ¨olkopf, “Can large language models infer causation from correlation?” inThe Twelfth International Conference on Learning Representations, 2024
2024
-
[12]
Toward causal representation learning,
B. Sch ¨olkopf, F. Locatello, S. Bauer, N. R. Ke, N. Kalchbrenner, A. Goyal, and Y . Bengio, “Toward causal representation learning,” Proceedings of the IEEE, vol. 109, no. 5, pp. 612–634, 2021
2021
-
[13]
Successor features for transfer in reinforcement learning,
A. Barreto, W. Dabney, R. Munos, J. J. Hunt, T. Schaul, H. P. Van Has- selt, and D. Silver, “Successor features for transfer in reinforcement learning,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[14]
Interpretable reward redistribution in reinforcement learning: A causal approach,
Y . Zhang, Y . Du, B. Huang, Z. Wang, J. Wang, M. Fang, and M. Pech- enizkiy, “Interpretable reward redistribution in reinforcement learning: A causal approach,”Advances in Neural Information Processing Systems, vol. 36, pp. 20 208–20 229, 2023
2023
-
[15]
Robust agents learn causal world models,
J. Richens and T. Everitt, “Robust agents learn causal world models,” inThe Twelfth International Conference on Learning Representations, 2024. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, JUNE 2026 12
2024
-
[16]
Interventional sum-product networks: Causal inference with tractable probabilistic models,
M. Ze ˇcevi´c, D. Dhami, A. Karanam, S. Natarajan, and K. Kersting, “Interventional sum-product networks: Causal inference with tractable probabilistic models,”Advances in neural information processing sys- tems, vol. 34, pp. 15 019–15 031, 2021
2021
-
[17]
Reasoning with language model is planning with world model,
S. Hao, Y . Gu, H. Ma, J. Hong, Z. Wang, D. Wang, and Z. Hu, “Reasoning with language model is planning with world model,” in Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 2023, pp. 8154–8173
2023
-
[18]
The perils of trial-and-error reward design: misdesign through overfitting and invalid task specifications,
S. Booth, W. B. Knox, J. Shah, S. Niekum, P. Stone, and A. Allievi, “The perils of trial-and-error reward design: misdesign through overfitting and invalid task specifications,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 37, no. 5, 2023, pp. 5920–5929
2023
-
[19]
Reward (mis) design for autonomous driving,
W. B. Knox, A. Allievi, H. Banzhaf, F. Schmitt, and P. Stone, “Reward (mis) design for autonomous driving,”Artificial Intelligence, vol. 316, p. 103829, 2023
2023
-
[20]
A survey of inverse reinforcement learning: Challenges, methods and progress,
S. Arora and P. Doshi, “A survey of inverse reinforcement learning: Challenges, methods and progress,”Artificial Intelligence, vol. 297, p. 103500, 2021
2021
-
[21]
Reward design with language models,
M. Kwon, S. M. Xie, K. Bullard, and D. Sadigh, “Reward design with language models,” inThe Eleventh International Conference on Learning Representations, 2023
2023
-
[22]
Chatpcg: Large language model-driven reward design for procedural content generation,
I.-C. Baek, T.-H. Park, J.-H. Noh, C.-M. Bae, and K.-J. Kim, “Chatpcg: Large language model-driven reward design for procedural content generation,” in2024 IEEE Conference on Games (CoG). IEEE, 2024, pp. 1–4
2024
-
[23]
Uncertainty-aware reward design process,
Y . yang, X. Zhou, B. Ding, and M. Xin, “Uncertainty-aware reward design process,”Transactions on Machine Learning Research, 2025
2025
-
[24]
R*: Efficient reward design via reward structure evolution and parameter alignment optimization with large language models,
P. Li, H. Jianye, H. Tang, Y . Yuan, J. Qiao, Z. Dong, and Y . Zheng, “R*: Efficient reward design via reward structure evolution and parameter alignment optimization with large language models,” inForty-second International Conference on Machine Learning, 2025
2025
-
[25]
Dags with no tears: Continuous optimization for structure learning,
X. Zheng, B. Aragam, P. K. Ravikumar, and E. P. Xing, “Dags with no tears: Continuous optimization for structure learning,”Advances in neural information processing systems, vol. 31, 2018
2018
-
[26]
Constraint- free structure learning with smooth acyclic orientations,
R. Massidda, F. Landolfi, M. Cinquini, and D. Bacciu, “Constraint- free structure learning with smooth acyclic orientations,” inThe Twelfth International Conference on Learning Representations, 2024
2024
-
[27]
Causal representation learning made identifiable by grouping of observational variables,
H. Morioka and A. Hyv ¨arinen, “Causal representation learning made identifiable by grouping of observational variables,” inInternational Conference on Machine Learning, 2023
2023
-
[28]
Causal discovery for rolling bearing fault under missing data: from the perspective of causal effect and information flow,
X. Ding, H. Wu, J. Wang, J. Xu, and M. Xin, “Causal discovery for rolling bearing fault under missing data: from the perspective of causal effect and information flow,”IEEE Transactions on Instrumentation and Measurement, vol. 74, pp. 1–17, 2024
2024
-
[29]
Dynotears: Structure learning from time-series data,
R. Pamfil, N. Sriwattanaworachai, S. Desai, P. Pilgerstorfer, K. Geor- gatzis, P. Beaumont, and B. Aragam, “Dynotears: Structure learning from time-series data,” inInternational conference on artificial intelli- gence and statistics. Pmlr, 2020, pp. 1595–1605
2020
-
[30]
Causal modelling agents: Causal graph discovery through synergising metadata-and data-driven reasoning,
A. Abdulaal, N. Montana-Brown, T. He, A. Ijishakin, I. Drobnjak, D. C. Castro, D. C. Alexanderet al., “Causal modelling agents: Causal graph discovery through synergising metadata-and data-driven reasoning,” in The Twelfth International Conference on Learning Representations, 2023
2023
-
[31]
D. Ha and J. Schmidhuber, “World models,”arXiv preprint arXiv:1803.10122, vol. 2, no. 3, p. 440, 2018
Pith/arXiv arXiv 2018
-
[32]
Mastering atari with discrete world models,
D. Hafner, T. P. Lillicrap, M. Norouzi, and J. Ba, “Mastering atari with discrete world models,” inInternational Conference on Learning Representations, 2021
2021
-
[33]
Mastering diverse control tasks through world models,
D. Hafner, J. Pasukonis, J. Ba, and T. Lillicrap, “Mastering diverse control tasks through world models,”Nature, pp. 1–7, 2025
2025
-
[34]
Better decisions through the right causal world model,
E. Dillies, Q. Delfosse, J. Bl ¨uml, R. Emunds, F. P. Busch, and K. Ker- sting, “Better decisions through the right causal world model,”arXiv preprint arXiv:2504.07257, 2025
arXiv 2025
-
[35]
Preference learning for AI align- ment: a causal perspective,
K. Kobalczyk and M. Van Der Schaar, “Preference learning for AI align- ment: a causal perspective,” inProceedings of the 42nd International Conference on Machine Learning, vol. 267. PMLR, 13–19 Jul 2025, pp. 31 063–31 083
2025
-
[36]
Causal information prioritization for efficient reinforcement learning,
H. Cao, F. Feng, T. Yang, J. Huo, and Y . Gao, “Causal information prioritization for efficient reinforcement learning,” inInternational Con- ference on Learning Representations, Y . Yue, A. Garg, N. Peng, F. Sha, and R. Yu, Eds., vol. 2025, 2025, pp. 75 061–75 097
2025
-
[37]
Peters, D
J. Peters, D. Janzing, and B. Sch ¨olkopf,Elements of causal inference: foundations and learning algorithms. The MIT Press, 2017
2017
-
[38]
Pearl,Causality: Models, Reasoning, and Inference, 2nd ed
J. Pearl,Causality: Models, Reasoning, and Inference, 2nd ed. Cam- bridge University Press, 2009
2009
-
[39]
Limix: Unleashing structured-data modeling capability for generalist intelligence,
X. Zhang, G. Ren, H. Yu, H. Yuan, H. Wang, J. Li, J. Wu, L. Mo, L. Mao, M. Haoet al., “Limix: Unleashing structured-data modeling capability for generalist intelligence,”arXiv preprint arXiv:2509.03505, 2025
arXiv 2025
-
[40]
Dagma: Learning dags via m- matrices and a log-determinant acyclicity characterization,
K. Bello, B. Aragam, and P. Ravikumar, “Dagma: Learning dags via m- matrices and a log-determinant acyclicity characterization,”Advances in Neural Information Processing Systems, vol. 35, pp. 8226–8239, 2022
2022
-
[41]
Multiplier and gradient methods,
M. R. Hestenes, “Multiplier and gradient methods,”Journal of optimiza- tion theory and applications, vol. 4, no. 5, pp. 303–320, 1969
1969
-
[42]
Can language models solve graph problems in natural language?
H. Wang, S. Feng, T. He, Z. Tan, X. Han, and Y . Tsvetkov, “Can language models solve graph problems in natural language?”Advances in Neural Information Processing Systems, vol. 36, pp. 30 840–30 861, 2023
2023
-
[43]
Talk like a graph: Encoding graphs for large language models,
B. Fatemi, J. Halcrow, and B. Perozzi, “Talk like a graph: Encoding graphs for large language models,” inThe Twelfth International Confer- ence on Learning Representations, 2024
2024
-
[44]
A. Liu, B. Feng, B. Xue, B. Wang, B. Wu, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruanet al., “Deepseek-v3 technical report,”arXiv preprint arXiv:2412.19437, 2024
Pith/arXiv arXiv 2024
-
[45]
Towards human-level bimanual dexterous ma- nipulation with reinforcement learning,
Y . Chen, T. Wu, S. Wang, X. Feng, J. Jiang, Z. Lu, S. McAleer, H. Dong, S.-C. Zhu, and Y . Yang, “Towards human-level bimanual dexterous ma- nipulation with reinforcement learning,”Advances in Neural Information Processing Systems, vol. 35, pp. 5150–5163, 2022
2022
-
[46]
Maniskill2: A unified benchmark for generalizable manipulation skills,
J. Gu, F. Xiang, X. Li, Z. Ling, X. Liu, T. Mu, Y . Tang, S. Tao, X. Wei, Y . Yao, X. Yuan, P. Xie, Z. Huang, R. Chen, and H. Su, “Maniskill2: A unified benchmark for generalizable manipulation skills,” inThe Eleventh International Conference on Learning Representations, 2023
2023
-
[47]
CASBOT W1: A versatile wheeled humanoid mobile manipulator,
Beijing Zhongke Huiling Robotics Technology Co., Ltd., “CASBOT W1: A versatile wheeled humanoid mobile manipulator,” https://casbot. tech/, 2024, accessed: 2026-04
2024
-
[48]
Quanti- fying differences in reward functions,
A. Gleave, M. D. Dennis, S. Legg, S. Russell, and J. Leike, “Quanti- fying differences in reward functions,” inInternational Conference on Learning Representations, 2021
2021
-
[49]
An introduction to roc analysis,
T. Fawcett, “An introduction to roc analysis,”Pattern recognition letters, vol. 27, no. 8, pp. 861–874, 2006
2006
-
[50]
Qwen2.5 technical report,
Qwen, A. Yang, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Li, D. Liu, and F. Huang, “Qwen2.5 technical report,” 2024
2024
-
[51]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughanet al., “The llama 3 herd of models,”arXiv preprint arXiv:2407.21783, 2024
Pith/arXiv arXiv 2024
-
[52]
Amor- tized inference for causal structure learning,
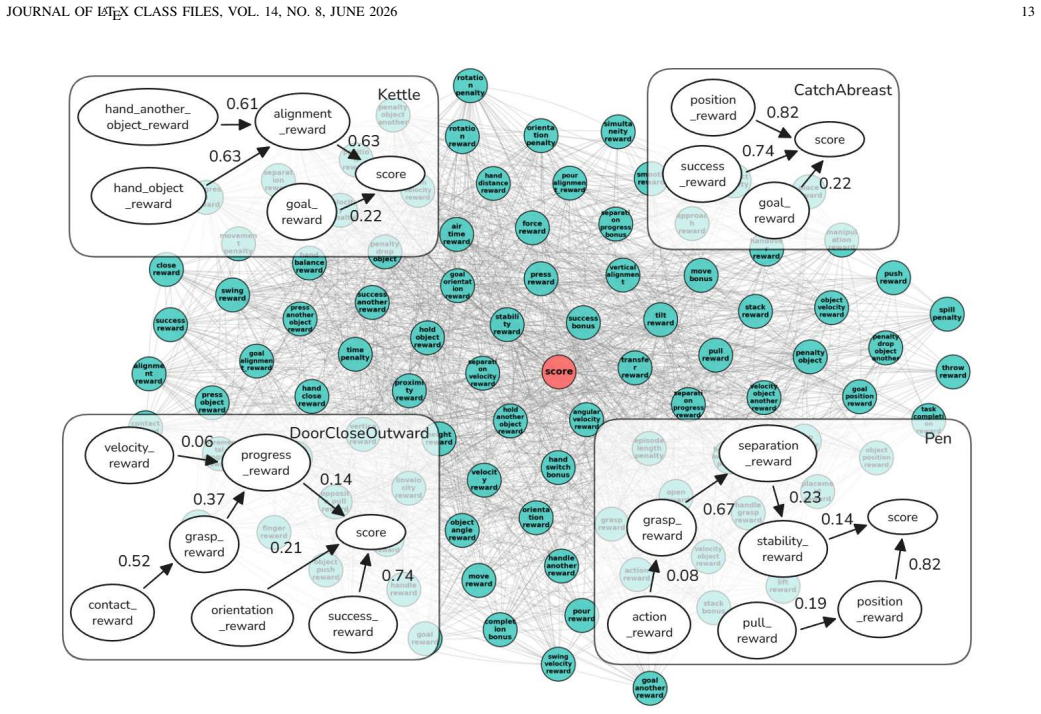
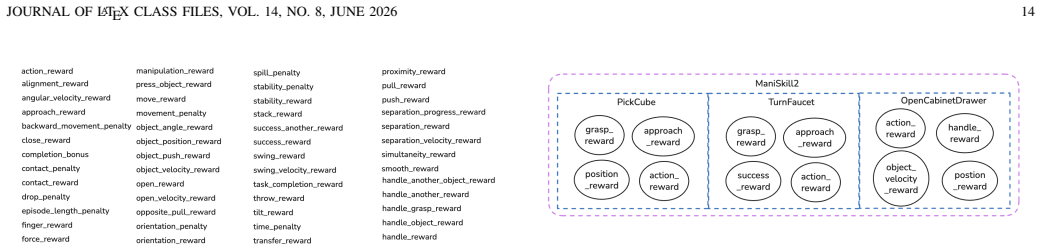
L. Lorch, S. Sussex, J. Rothfuss, A. Krause, and B. Sch ¨olkopf, “Amor- tized inference for causal structure learning,” inAdvances in Neural Information Processing Systems, A. H. Oh, A. Agarwal, D. Belgrave, and K. Cho, Eds., 2022. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, JUNE 2026 13 Fig. 11.Visualization of the CRWM.The background graph shows the t...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.