Learning to See While Learning to Act: Diffusion Models for Active Perception in Robot Imitation
Pith reviewed 2026-06-26 08:07 UTC · model grok-4.3
The pith
A diffusion model policy learns to infer informative viewpoints while predicting actions from demonstrations, improving manipulation under occlusion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
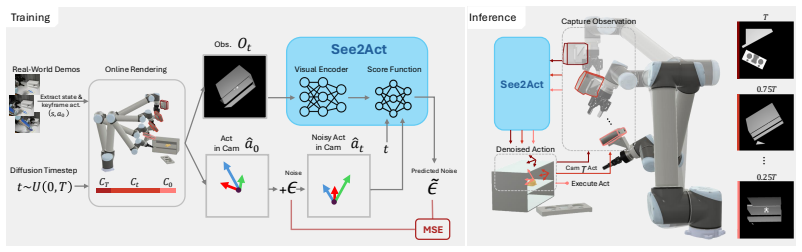
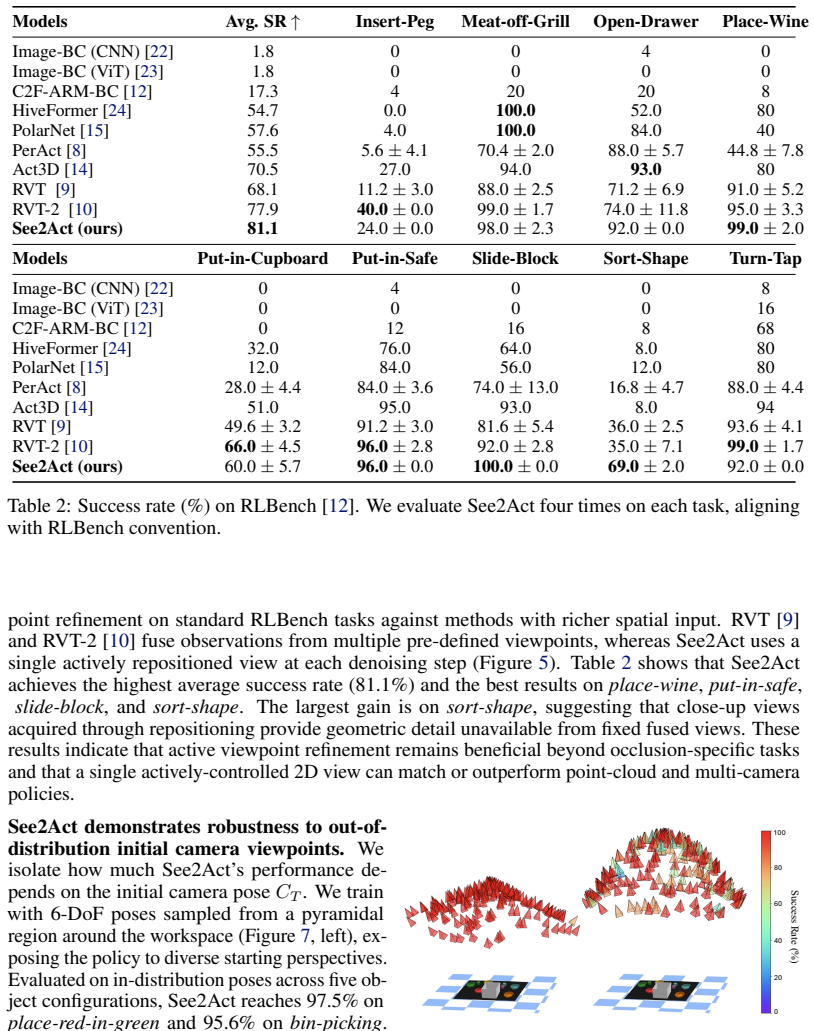
See2Act trains a diffusion policy that jointly denoises action sequences and viewpoint sequences, using camera poses anchored to keyframe actions from demonstrations. This enables the policy to recover informative viewpoints at test time under severe occlusions, leading to up to 34% better performance on RLBench tasks and successful zero-shot transfer to real pick-and-place with depth images after training on 50 digital-twin demonstrations.
What carries the argument
Coupling of action denoising with viewpoint refinement in the diffusion model, trained on keyframe-anchored camera poses.
If this is right
- The policy recovers informative viewpoints under severe occlusions.
- Performance on RLBench tasks improves by up to 34% compared to prior methods.
- Zero-shot sim-to-real transfer is achieved on pick-and-place tasks using only depth observations after collecting 50 demonstrations in a digital twin.
- The approach handles significant occlusions in real-world manipulation scenarios.
Where Pith is reading between the lines
- Active perception can be learned without explicit viewpoint labels by tying it to action learning.
- This method may extend to other forms of partial observability beyond visual occlusion, such as in dynamic scenes.
- Collecting demonstrations in simulation could become a standard way to bootstrap viewpoint reasoning for real robots.
Load-bearing premise
Camera poses anchored to keyframe actions from offline demonstrations are sufficient to enable implicit learning of informative viewpoints while learning actions.
What would settle it
An experiment where the policy is tested on tasks with occlusions but the selected viewpoints do not improve object visibility or task success rates compared to fixed camera baselines.
Figures






read the original abstract
Most imitation learning methods assume full observability in table-top settings. In practice, objects are often occluded, requiring robots to both search and act, and learning this coupled behavior from limited demonstrations remains challenging. We propose See2Act, an imitation learning approach that conditions action prediction on a sequence of actively-inferred viewpoints at test time, by coupling action denoising with viewpoint refinement. The policy is trained using camera poses anchored to keyframe actions from offline demonstrations, enabling implicit learning of where to see, while learning how to act. We empirically demonstrate that in Ravens the policy recovers informative viewpoints under severe occlusions, and on RLBench tasks it improves performance by up to 34% over prior methods. In the real world, we collect 50 demonstrations in a digital twin and achieve zero-shot sim-to-real transfer on pick-and-place tasks using depth observations. The policy handles significant occlusions, showing that learned viewpoint reasoning enables robust manipulation under partial observability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes See2Act, a diffusion-model-based imitation learning method that couples action denoising with viewpoint refinement. Camera poses are anchored to keyframe actions from offline demonstrations during training, allowing the policy to implicitly learn informative viewpoints at test time. The authors claim this enables recovery of informative views under severe occlusions, yielding up to 34% performance gains on RLBench tasks over prior methods, plus zero-shot sim-to-real transfer on pick-and-place using depth observations from 50 digital-twin demonstrations.
Significance. If the empirical claims hold after proper validation, the work would be significant for imitation learning under partial observability. Integrating active perception directly into a diffusion policy via coupled denoising is a novel framing, and successful zero-shot transfer on real hardware would strengthen the case for practical deployment in occluded manipulation settings.
major comments (2)
- [Method] Method section (training procedure): anchoring camera poses exclusively to demonstration keyframes risks the model learning to reproduce training trajectories rather than inferring novel informative viewpoints; without an ablation or metric showing test-time views differ meaningfully from demo poses on unseen occlusions, the active-perception claim lacks support.
- [Experiments] Experiments / Results: the reported 34% RLBench improvement and occlusion-handling claims are presented without baseline descriptions, statistical tests, ablation studies separating viewpoint refinement from action denoising, or quantitative metrics on viewpoint quality, so the data-to-claim link cannot be verified.
minor comments (2)
- [Abstract] Abstract and introduction would benefit from explicit statements of the diffusion coupling mechanism (e.g., how viewpoint noise is scheduled relative to action noise).
- [Experiments] Real-world evaluation mentions 50 demonstrations but provides no details on demonstration collection protocol or failure modes observed during zero-shot transfer.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and constructive feedback on our work. We address the major comments point by point below, and we plan to incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Method] Method section (training procedure): anchoring camera poses exclusively to demonstration keyframes risks the model learning to reproduce training trajectories rather than inferring novel informative viewpoints; without an ablation or metric showing test-time views differ meaningfully from demo poses on unseen occlusions, the active-perception claim lacks support.
Authors: We agree that demonstrating the distinction between learned test-time viewpoints and the anchored demonstration poses is important for supporting the active perception claim. In the current manuscript, we show qualitative recovery of informative views under occlusion in Ravens, but we acknowledge the need for a quantitative metric or ablation. We will add an analysis comparing the distribution of test-time camera poses to demonstration keyframes on unseen occlusion scenarios, along with an ablation removing the viewpoint refinement component. revision: yes
-
Referee: [Experiments] Experiments / Results: the reported 34% RLBench improvement and occlusion-handling claims are presented without baseline descriptions, statistical tests, ablation studies separating viewpoint refinement from action denoising, or quantitative metrics on viewpoint quality, so the data-to-claim link cannot be verified.
Authors: We appreciate this observation. The manuscript includes comparisons to prior methods on RLBench, but we will expand the experiments section to provide full baseline descriptions, report statistical significance (e.g., mean and standard deviation over multiple seeds), include ablations isolating the viewpoint refinement, and add quantitative metrics such as viewpoint entropy or success rate correlation with view quality to better support the claims. revision: yes
Circularity Check
No significant circularity; empirical claims rest on reported experiments
full rationale
The paper describes an imitation learning method that trains a diffusion policy by conditioning on camera poses taken from offline demonstration keyframes. No equations, derivations, or parameter-fitting steps are presented in the provided text that reduce a claimed prediction or result back to the same inputs by construction. Performance improvements (e.g., 34% on RLBench) and sim-to-real transfer are asserted via empirical evaluation rather than any self-referential mathematical structure. Standard imitation-learning use of demonstration data does not constitute circularity under the defined criteria when the central claims remain externally falsifiable through reported task success rates.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Diffusion models can be conditioned to jointly denoise action sequences and camera-pose sequences from demonstration data.
Reference graph
Works this paper leans on
-
[1]
Mandlekar, D
A. Mandlekar, D. Xu, J. Wong, S. Nasiriany, C. Wang, R. Kulkarni, L. Fei-Fei, S. Savarese, Y . Zhu, and R. Martín-Martín. What matters in learning from offline human demonstrations for robot manipulation. InConference on Robot Learning (CoRL), 2021
2021
-
[2]
V . Saxena, M. Bronars, N. R. Arachchige, K. Wang, W. C. Shin, S. Nasiriany, A. Mandlekar, and D. Xu. What matters in learning from large-scale datasets for robot manipulation. In The Thirteenth International Conference on Learning Representations, 2025. URL https: //arxiv.org/pdf/2506.13536
arXiv 2025
-
[3]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[4]
Y . Ze, G. Zhang, K. Zhang, C. Hu, M. Wang, and H. Xu. 3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations.arXiv preprint arXiv:2403.03954, 2024
Pith/arXiv arXiv 2024
-
[5]
D. Wang, S. Hart, D. Surovik, T. Kelestemur, H. Huang, H. Zhao, M. Yeatman, J. Wang, R. Walters, and R. Platt. Equivariant diffusion policy.arXiv preprint arXiv:2407.01812, 2024
arXiv 2024
-
[6]
H. Ryu, J. Kim, H. An, J. Chang, J. Seo, T. Kim, Y . Kim, C. Hwang, J. Choi, and R. Horowitz. Diffusion-edfs: Bi-equivariant denoising generative modeling on se (3) for visual robotic manipulation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18007–18018, 2024
2024
-
[7]
Saxena, Y
V . Saxena, Y . Koga, and D. Xu. C3DM: Constrained-Context Conditional Diffusion Models for Imitation Learning.Transactions on Machine Learning Research, 2024. ISSN 2835-8856. URLhttps://openreview.net/forum?id=jcleXdnRA1
2024
-
[8]
M. Shridhar, L. Manuelli, and D. Fox. Perceiver-actor: A multi-task transformer for robotic manipulation, 2022. URLhttps://arxiv.org/abs/2209.05451
arXiv 2022
-
[9]
Goyal, J
A. Goyal, J. Xu, Y . Guo, V . Blukis, Y .-W. Chao, and D. Fox. Rvt: Robotic view transformer for 3d object manipulation. InConference on Robot Learning, pages 694–710. PMLR, 2023
2023
- [10]
-
[11]
A. Zeng, P. Florence, J. Tompson, S. Welker, J. Chien, M. Attarian, T. Armstrong, I. Krasin, D. Duong, V . Sindhwani, et al. Transporter networks: Rearranging the visual world for robotic manipulation. InConference on Robot Learning, pages 726–747. PMLR, 2021
2021
-
[12]
James, Z
S. James, Z. Ma, D. R. Arrojo, and A. J. Davison. Rlbench: The robot learning benchmark & learning environment.IEEE Robotics and Automation Letters, 5(2):3019–3026, 2020
2020
-
[13]
M. Zawalski, W. Chen, K. Pertsch, O. Mees, C. Finn, and S. Levine. Robotic control via embodied chain-of-thought reasoning.arXiv preprint arXiv:2407.08693, 2024
Pith/arXiv arXiv 2024
- [14]
-
[15]
S. Chen, R. G. Pinel, C. Schmid, and I. Laptev. Polarnet: 3d point clouds for language- guided robotic manipulation. In J. Tan, M. Toussaint, and K. Darvish, editors,Proceedings of The 7th Conference on Robot Learning, volume 229 ofProceedings of Machine Learning Research, pages 1761–1781. PMLR, 06–09 Nov 2023. URL https://proceedings.mlr. press/v229/chen23b.html
2023
-
[16]
Guhur, S
P.-L. Guhur, S. Chen, R. G. Pinel, M. Tapaswi, I. Laptev, and C. Schmid. Instruction-driven history-aware policies for robotic manipulations. InConference on Robot Learning, pages 175–187. PMLR, 2023
2023
- [17]
-
[18]
J. Kerr, K. Hari, E. Weber, C. M. Kim, B. Yi, T. Bonnen, K. Goldberg, and A. Kanazawa. Eye, robot: Learning to look to act with a bc-rl perception-action loop.arXiv preprint arXiv:2506.10968, 2025
arXiv 2025
-
[19]
A. Zhou, M. J. Kim, L. Wang, P. Florence, and C. Finn. Nerf in the palm of your hand: Corrective augmentation for robotics via novel-view synthesis. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17907–17917, 2023
2023
-
[20]
J. Ho, A. Jain, and P. Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[21]
A. Zeng, P. Florence, J. Tompson, S. Welker, J. Chien, M. Attarian, T. Armstrong, I. Krasin, D. Duong, V . Sindhwani, et al. Transporter networks: Rearranging the visual world for robotic manipulation.arXiv preprint arXiv:2010.14406, 2020
arXiv 2010
-
[22]
E. Jang, A. Irpan, M. Khansari, D. Kappler, F. Ebert, C. Lynch, S. Levine, and C. Finn. Bc-z: Zero-shot task generalization with robotic imitation learning. InConference on Robot Learning, pages 991–1002. PMLR, 2022
2022
-
[23]
Shridhar, L
M. Shridhar, L. Manuelli, and D. Fox. Perceiver-actor: A multi-task transformer for robotic manipulation. InConference on Robot Learning, pages 785–799. PMLR, 2023
2023
-
[24]
Guhur, S
P.-L. Guhur, S. Chen, R. G. Pinel, M. Tapaswi, I. Laptev, and C. Schmid. Instruction-driven history-aware policies for robotic manipulations. In K. Liu, D. Kulic, and J. Ichnowski, editors, Proceedings of The 6th Conference on Robot Learning, volume 205 ofProceedings of Machine Learning Research, pages 175–187. PMLR, 14–18 Dec 2023. URL https://proceeding...
2023
-
[25]
K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770– 778, 2016
2016
-
[26]
Perez, F
E. Perez, F. Strub, H. De Vries, V . Dumoulin, and A. Courville. Film: Visual reasoning with a general conditioning layer. InProceedings of the AAAI conference on artificial intelligence, volume 32, 2018
2018
-
[27]
A. F. Agarap. Deep learning using rectified linear units (relu).arXiv preprint arXiv:1803.08375, 2018
Pith/arXiv arXiv 2018
-
[28]
D. P. Kingma and J. Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014. 11 A Algorithms Algorithm 1See2Act – Training Require:D={(s (i), a(i) 0 )}N i=1,K, max_iters,C T ,d,T,¯α,e ϕ,ϵ ψ 1:forn_iter∈ {1, . . . ,max_iters}do 2:L ←0 3:fork∈ {1, . . . , K}do 4:fori∈ {1, . . . , N}do 5:t k ∼Unif(0, T)▷timestep 6:ϵ (i) k ∼ N(0,I)...
Pith/arXiv arXiv 2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.